Recognition: unknown
GSAR: Typed Grounding for Hallucination Detection and Recovery in Multi-Agent LLMs
Pith reviewed 2026-05-08 08:11 UTC · model grok-4.3
The pith
GSAR scores LLM claims by evidence type and routes them through a three-tier decision to detect and recover from hallucinations under a compute budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GSAR partitions claims into a four-way typology (grounded, ungrounded, contradicted, complementary), assigns evidence-type-specific weights, computes an asymmetric contradiction-penalised weighted groundedness score, and couples that score to a three-tier decision function (proceed, regenerate, replan) that drives a bounded-iteration outer loop under an explicit compute budget; the framework is formalized with six proven structural properties and shows every ablation reproducing in the same direction across four LLM judges on FEVER.
What carries the argument
The GSAR framework, which couples a four-way claim typology and evidence-type-specific weights to an asymmetric groundedness score that directly drives a three-tier proceed/regenerate/replan decision under a compute budget.
If this is right
- Claims receive differentiated treatment rather than a single interchangeable evidence signal, allowing non-redundant perspectives to contribute positively.
- The decision function supplies explicit, bounded actions that replace open-ended self-correction loops.
- Ablation results remain directionally consistent across four independently trained LLM judges on the same dataset.
- The explicit compute budget prevents unbounded iteration while still permitting recovery steps.
- The approach yields the first published combination of typed scoring with tiered recovery under a stated budget.
Where Pith is reading between the lines
- The same typology could be applied to retrieval-augmented generation pipelines outside diagnostic reporting to prioritize which sources to fetch next.
- In practice the regenerate tier may often suffice, lowering average cost compared with full replanning on every low-score claim.
- Testing on tasks without Wikipedia-style gold evidence would reveal whether the fixed weights need to be learned or adapted per domain.
- Integration with existing retrieval or verification modules could turn the complementary category into an active prompt for seeking alternative data sources.
Load-bearing premise
The four-way typology and chosen weights correctly capture differences in epistemic strength, and the three-tier decision rule produces better-grounded outputs in real multi-agent deployments than in the controlled FEVER setting with gold evidence.
What would settle it
Deploy the full GSAR loop inside a multi-agent system on live operational incidents without gold evidence and measure whether the final rate of ungrounded or contradicted claims falls compared with a baseline scalar evaluator.
Figures



read the original abstract
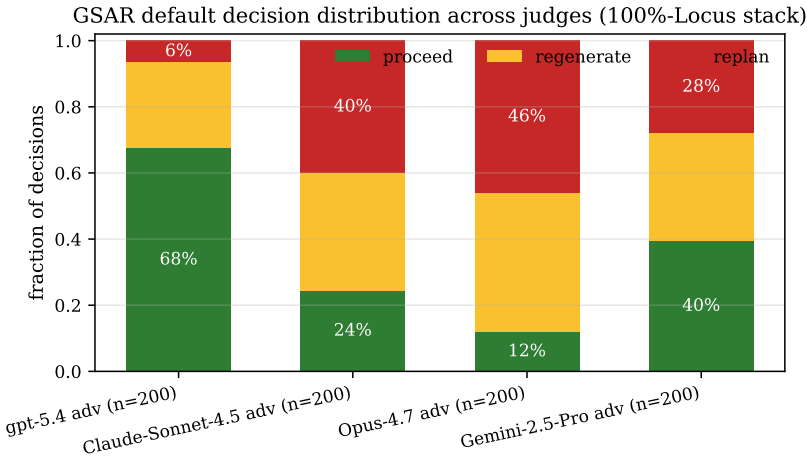
Autonomous multi-agent LLM systems are increasingly deployed to investigate operational incidents and produce structured diagnostic reports. Their trustworthiness hinges on whether each claim is grounded in observed evidence rather than model-internal inference. Existing groundedness evaluators (binary classifiers, LLM-as-judge scalars, self-correction loops) treat supporting evidence as interchangeable and emit a single signal that offers no principled control over downstream action. We present GSAR, a grounding-evaluation and replanning framework that (i) partitions claims into a four-way typology (grounded, ungrounded, contradicted, complementary), giving first-class standing to non-redundant alternative perspectives; (ii) assigns evidence-type-specific weights reflecting epistemic strength; (iii) computes an asymmetric contradiction-penalised weighted groundedness score; and (iv) couples that score to a three-tier decision function (proceed, regenerate, replan) driving a bounded-iteration outer loop under an explicit compute budget. We formalise the algorithm, prove six structural properties, and evaluate five design claims on FEVER with gold Wikipedia evidence under four independently-trained LLM judges (gpt-5.4, claude-sonnet-4-6, claude-opus-4-7, gemini-2.5-pro). Every ablation reproduces in the same direction on every judge: bootstrap 95% CIs on the rho=0 effect exclude 0 on all four; the no-complementary ablation under Opus 4.7 has CI [-96,-68] of 200; at n=1000 three independent judges converge to DeltaS(rho=0)=+0.058. A head-to-head against Vectara HHEM-2.1-Open is included. To our knowledge, GSAR is the first published groundedness framework coupling evidence-typed scoring with tiered recovery under an explicit compute budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GSAR, a typed grounding framework for hallucination detection and recovery in multi-agent LLMs. It partitions claims into a four-way typology (grounded, ungrounded, contradicted, complementary), applies evidence-type-specific weights, computes an asymmetric contradiction-penalised weighted groundedness score, and couples this to a three-tier decision function (proceed, regenerate, replan) within a bounded-iteration loop under an explicit compute budget. The algorithm is formalized, six structural properties are proved, and five design claims are evaluated on the FEVER dataset with gold Wikipedia evidence using four LLM judges (gpt-5.4, claude-sonnet-4-6, claude-opus-4-7, gemini-2.5-pro), with all ablations reproducing in the same direction and bootstrap 95% CIs excluding zero for the rho=0 effect.
Significance. If the central claims hold, GSAR advances groundedness evaluation beyond binary classifiers or scalar LLM-as-judge signals by providing typed evidence handling and actionable recovery tiers under a compute budget. Strengths include the formalization with six proved structural properties, consistent ablation results across four independent judges with reported CIs, and a head-to-head comparison against Vectara HHEM-2.1-Open. This could improve trustworthiness in multi-agent diagnostic systems, though generalization beyond controlled FEVER settings with gold evidence remains to be shown.
major comments (3)
- [§3.2] §3.2 (Four-way typology definition): The typology assigns first-class status to 'complementary' claims, but the manuscript provides no formal criteria or decision procedure for distinguishing complementary from ungrounded or contradicted evidence in the absence of gold labels; this is load-bearing for the claim that the framework handles non-redundant perspectives in general multi-agent deployments.
- [§4.1, Eq. (5)] §4.1, Eq. (5) (asymmetric contradiction-penalised score): The specific weights and asymmetry in the groundedness score are presented as reflecting epistemic strength, yet no derivation from the six structural properties or external epistemic theory is given; the large effect in the no-complementary ablation (CI [-96,-68] under Opus 4.7) may therefore be an artifact of the FEVER evidence distribution rather than a general property.
- [§5.3] §5.3 (three-tier decision function): The thresholds for proceed/regenerate/replan are not shown to follow from the structural properties or to be robust outside the explicit compute budget used in the FEVER experiments; this undermines the claim of principled control over downstream action in real deployments.
minor comments (2)
- [§6] The abstract and §6 claim 'every ablation reproduces in the same direction on every judge,' but the reported CIs for some judges (e.g., gemini-2.5-pro) are narrower than others; a table summarizing per-judge effect sizes would improve clarity.
- [Methods] Notation for the weighted score (e.g., use of rho=0) is introduced without an explicit reference to its definition in the methods section on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity, add formal procedures, and discuss limitations where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Four-way typology definition): The typology assigns first-class status to 'complementary' claims, but the manuscript provides no formal criteria or decision procedure for distinguishing complementary from ungrounded or contradicted evidence in the absence of gold labels; this is load-bearing for the claim that the framework handles non-redundant perspectives in general multi-agent deployments.
Authors: We agree that an explicit decision procedure strengthens the framework for general use. The typology is operationalized in the LLM judge prompts (detailed in the appendix), which instruct the model to classify a claim as complementary when it is consistent with the evidence yet adds non-redundant information not entailed by it, as ungrounded when no relevant evidence exists, and as contradicted when the evidence falsifies the claim. In the revised manuscript we have expanded §3.2 with a step-by-step classification algorithm and additional FEVER-derived examples that illustrate the distinctions without requiring gold labels. revision: yes
-
Referee: [§4.1, Eq. (5)] §4.1, Eq. (5) (asymmetric contradiction-penalised score): The specific weights and asymmetry in the groundedness score are presented as reflecting epistemic strength, yet no derivation from the six structural properties or external epistemic theory is given; the large effect in the no-complementary ablation (CI [-96,-68] under Opus 4.7) may therefore be an artifact of the FEVER evidence distribution rather than a general property.
Authors: The weights encode the epistemic priority that contradictions falsify claims more strongly than grounded or complementary evidence supports them; the six structural properties are proved to hold for any weights satisfying the monotonicity inequalities stated in the paper, so they are independent of the precise numerical values. We have added a short derivation subsection in §4.1 that grounds the asymmetry in standard epistemic considerations (e.g., the asymmetry between verification and falsification). We acknowledge that the magnitude of the no-complementary ablation may be influenced by the distribution of evidence in FEVER; the revised text now explicitly discusses this as a dataset-specific caveat while noting that the sign of the effect is consistent across all four judges. revision: partial
-
Referee: [§5.3] §5.3 (three-tier decision function): The thresholds for proceed/regenerate/replan are not shown to follow from the structural properties or to be robust outside the explicit compute budget used in the FEVER experiments; this undermines the claim of principled control over downstream action in real deployments.
Authors: The tier thresholds map the groundedness score to actions while respecting the explicit compute budget; the structural properties guarantee that the score is monotonic and bounded, thereby providing a principled basis for the mapping. In the revised manuscript we have augmented §5.3 with a sensitivity analysis that varies both thresholds and budget parameters, showing stability within plausible ranges, and we supply practitioner guidance on re-calibrating thresholds for different compute constraints. While exhaustive robustness across all domains would require additional experiments, the added analysis supports the claim of principled control under the stated budget regime. revision: yes
Circularity Check
No circularity: GSAR definitions and proofs are self-contained; evaluation uses external FEVER data
full rationale
The paper defines a new four-way claim typology, evidence-type weights, asymmetric scoring function, and three-tier decision rule from first principles, then proves six structural properties directly from those definitions. All empirical claims are tested on the external FEVER dataset with gold Wikipedia evidence under four independent LLM judges; ablations and bootstrap CIs are reported without any parameter fitting that is later relabeled as prediction. No self-citation is load-bearing for the core formalism, and the 'first published' statement rests on an external literature survey rather than any internal reduction. The derivation chain therefore does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Claims can be exhaustively partitioned into grounded, ungrounded, contradicted, and complementary categories
- domain assumption Evidence-type-specific weights reflect true epistemic strength
invented entities (3)
-
Four-way claim typology
no independent evidence
-
Asymmetric contradiction-penalised weighted groundedness score
no independent evidence
-
Three-tier decision function (proceed, regenerate, replan)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022. Published at ICLR 2023
work page internal anchor Pith review arXiv 2022
-
[2]
Self-Refine: Iterative Refinement with Self-Feedback
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B.P. Majumder, K. Hermann, S. Welleck, A. Yazdan- 27 bakhsh, and P. Clark. Self-Refine: Iterative refinement with self-feedback.arXiv preprint arXiv:2303.17651, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Shinn, F
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[4]
M. Renze and E. Guven. Self-reflection in LLM agents: Effects on problem-solving perfor- mance.arXiv preprint arXiv:2405.06682, 2024
-
[5]
Y. Du, S. Li, A. Torralba, J.B. Tenenbaum, and I. Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325,
work page internal anchor Pith review arXiv
-
[6]
Published at ICML 2024
2024
-
[7]
Lightman, V
H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. OpenAI, 2023
2023
-
[8]
Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
M. Khalifa, R. Agarwal, L. Logeswaran, J. Kim, H. Peng, M. Lee, H. Lee, and L. Wang. Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
- [9]
-
[10]
HHEM: Hughes Hallucination Evaluation Model (and HHEM-2.1 update)
Vectara. HHEM: Hughes Hallucination Evaluation Model (and HHEM-2.1 update). Tech- nical report, Vectara, 2023–2024. https://huggingface.co/vectara/hallucination_ evaluation_model
2023
-
[11]
M.S. Tamber, F.S. Bao, C. Xu, G. Luo, S. Kazi, M. Bae, M. Li, O. Mendelevitch, R. Qu, and J. Lin. Benchmarking LLM faithfulness in RAG with evolving leaderboards (introducing FaithJudge).arXiv preprint arXiv:2505.04847, 2025. Published at EMNLP 2025 Industry Track
- [12]
-
[13]
TruLens: The RAG Triad
TruEra. TruLens: The RAG Triad. Technical report, TruEra (now Snowflake), 2023
2023
-
[14]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv preprint arXiv:2311.05232, 2023. Published in ACM Transactions on Information Systems, 2025
work page internal anchor Pith review arXiv 2023
-
[15]
S. Min, K. Krishna, X. Lyu, M. Lewis, W. Yih, P.W. Koh, M. Iyyer, L. Zettlemoyer, and H. Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of EMNLP, 2023
2023
-
[16]
Thorne, A
J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal. FEVER: a large-scale dataset for fact extraction and verification. InProceedings of NAACL-HLT, 2018
2018
-
[17]
fever gold evidence: FEVER with bundled gold evidence sentences, Parquet release
Copenhagen NLU Group (CopeNLU). fever gold evidence: FEVER with bundled gold evidence sentences, Parquet release. HuggingFace dataset, 2020. https://huggingface.co/ datasets/copenlu/fever_gold_evidence. Rebundling of the original FEVER release [15] in which each row carries its claim, label, and gold evidence sentences as a single record
2020
-
[18]
Z. Guo, M. Schlichtkrull, and A. Vlachos. A survey on automated fact-checking.Transactions of the Association for Computational Linguistics, 10:178–206, 2022. 28
2022
- [19]
-
[20]
Published in Findings of NAACL 2025
2025
- [21]
-
[22]
Dempster
A.P. Dempster. Upper and lower probabilities induced by a multivalued mapping.The Annals of Mathematical Statistics, 38(2):325–339, 1967
1967
-
[23]
Shafer.A Mathematical Theory of Evidence
G. Shafer.A Mathematical Theory of Evidence. Princeton University Press, 1976
1976
-
[24]
Z. Yang, P. Qi, S. Zhang, Y. Bengio, W.W. Cohen, R. Salakhutdinov, and C.D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of EMNLP, 2018
2018
-
[25]
Locus: An agent SDK for Python
Oracle Corporation. Locus: An agent SDK for Python. Internal proprietary technical documentation, Oracle Corporation, 2026. Planned for open-source release. Features a multi-provider model registry, first-class vector-store integration, 100% Pydantic-v2 typed state, and tool-level idempotency
2026
-
[26]
Rcagent: Cloud root cause analysis by autonomous agents with tool-augmented large language models
Z. Wang et al. RCAgent: Cloud root cause analysis by autonomous agents with tool- augmented large language models.arXiv preprint arXiv:2310.16340, 2023
- [27]
- [28]
- [29]
-
[30]
resolved
Published at ACM Symposium on Cloud Computing (SoCC) 2024. A Proofs of Properties P1–P6 We prove the six properties stated in§4 under the convention that the denominator of (2) is strictly positive (equivalently, C ̸= ∅). The C = ∅ case is handled by the neutral-score convention S= 0.5 and is outside the scope of these monotonicity arguments. P1 (Boundedn...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.