Recognition: unknown
Z²-Sampling: Zero-Cost Zigzag Trajectories for Semantic Alignment in Diffusion Models
Pith reviewed 2026-05-08 06:34 UTC · model grok-4.3
The pith
Diffusion models gain curvature-aware semantic alignment from zero-cost zigzag trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
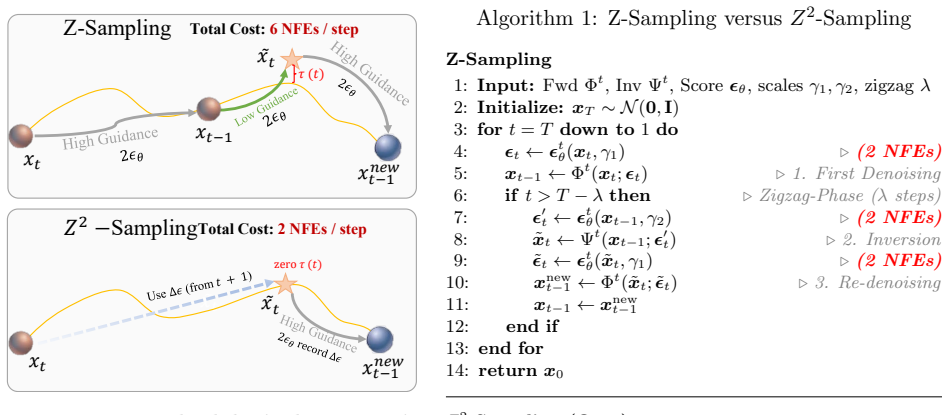
Z²-Sampling establishes that the explicit zigzag sequence is topologically reducible, allowing algebraic annihilation of intermediate states via operator dualities to create implicit Z-sampling that eliminates approximation errors. By exploiting the temporal coherence of the Probability Flow ODE with a dynamically cached Temporal Semantic Surrogate, this restores the standard 2-NFE baseline while the discrete collapse inherently synthesizes a directional derivative curvature penalty, as proven by backward error analysis.
What carries the argument
The implicit algebraic collapse of zigzag trajectories via operator dualities combined with a cached Temporal Semantic Surrogate from the Probability Flow ODE, which together synthesize the curvature penalty at zero added cost.
If this is right
- Restores the standard 2-NFE baseline while delivering improved semantic alignment.
- Applies across U-Net and DiT architectures for both image and video generation.
- Maintains orthogonality with other alignment methods such as AYS and Diffusion-DPO.
- Structurally improves the performance-efficiency Pareto frontier.
Where Pith is reading between the lines
- The algebraic reduction might apply to other multi-step ODE samplers to lower their overhead in similar ways.
- The synthesized curvature penalty could enhance stability in generation tasks where manifold geometry is critical.
- Direct integration into existing diffusion pipelines could raise output quality at no added runtime cost.
Load-bearing premise
The explicit zigzag sequence is topologically reducible and intermediate states can be algebraically annihilated via operator dualities without introducing cumulative drift from the true marginal distribution or requiring additional corrections.
What would settle it
A side-by-side run of Z²-Sampling against explicit Z-Sampling at identical 2-NFE budgets, measuring whether semantic alignment scores match or exceed the explicit version without added drift, would falsify the claim if no improvement appears.
Figures








read the original abstract
Diffusion models have achieved unprecedented success in text-aligned generation, largely driven by Classifier-Free Guidance (CFG). However, standard CFG operates strictly on instantaneous gradients, omitting the intrinsic curvature of the data manifold. Recent methods like Zigzag-sampling (Z-Sampling) explicitly traverse multi-step forward-backward trajectories to probe this curvature, significantly improving semantic alignment. Yet, these explicit traversals triple the Neural Function Evaluation (NFE) cost and introduce unconstrained truncation errors from off-manifold evaluations, causing cumulative drift from the true marginal distribution. In this paper, we theoretically demonstrate that the explicit zigzag sequence is topologically reducible. We propose Implicit Z-Sampling, rigorously proving that intermediate states can be algebraically annihilated via operator dualities, physically eliminating off-manifold approximation errors. To push sampling efficiency to its theoretical lower bound, we introduce $Z^2$-Sampling (Zero-cost Zigzag Sampling). Exploiting the Probability Flow ODE's temporal coherence, $Z^2$-Sampling couples implicit algebraic collapse with a dynamically cached Temporal Semantic Surrogate. This restores the standard 2-NFE baseline without sacrificing semantic exploration. We formally prove via Backward Error Analysis that this discrete collapse inherently synthesizes a directional derivative curvature penalty. Finally, extensive evaluations demonstrate that $Z^2$-Sampling structurally shatters the performance-efficiency Pareto frontier. We validate its universal applicability across diverse architectures (U-Nets, DiTs) and modalities (image/video), establishing seamless orthogonality with advanced alignment frameworks (AYS, Diffusion-DPO).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes $Z^2$-Sampling (Zero-cost Zigzag Sampling) for diffusion models, claiming that explicit zigzag trajectories are topologically reducible so that intermediate states can be algebraically annihilated via operator dualities. Combined with a dynamically cached Temporal Semantic Surrogate exploiting Probability Flow ODE coherence, the method restores the standard 2-NFE baseline while inheriting a directional-derivative curvature penalty, as formally shown by backward error analysis. Extensive experiments across U-Nets, DiTs, image and video modalities are said to demonstrate that the approach shatters the performance-efficiency Pareto frontier and remains orthogonal to frameworks such as AYS and Diffusion-DPO.
Significance. If the topological reduction and backward-error claims hold without residual drift, the work would be significant: it would eliminate the NFE overhead of prior curvature-aware samplers while improving semantic alignment, thereby establishing a new efficiency baseline for text-aligned generation.
major comments (3)
- [Proof of topological reducibility (§3)] The central claim (abstract and §3) that the explicit zigzag sequence is topologically reducible and that intermediate states can be algebraically annihilated via operator dualities without cumulative drift from the true marginal distribution is load-bearing for both the zero-cost assertion and the subsequent backward-error result. In the discrete PF-ODE setting, exact commutation or duality relations typically hold only in the continuous-time limit; finite-step truncation and off-manifold evaluations can leave nonzero residual terms that the Temporal Semantic Surrogate cache may not cancel, undermining the claim that no additional fitted corrections are required.
- [Backward Error Analysis (§4)] §4 (Backward Error Analysis): the statement that the discrete collapse 'inherently synthesizes a directional derivative curvature penalty' must be shown to be independent of the particular definition of the Temporal Semantic Surrogate. If the penalty term arises only after the surrogate is introduced, the result is not an intrinsic property of the collapse and the 'parameter-free' character asserted in the abstract is compromised.
- [Empirical evaluations (§5–6)] Empirical section (likely §5–6): the claim that $Z^2$-Sampling 'structurally shatters the performance-efficiency Pareto frontier' and restores exact 2-NFE behavior requires tabulated quantitative results (FID, CLIP score, etc.) with error bars, direct comparison against the unmodified 2-NFE baseline, and ablation of the surrogate cache. Without these, the cross-architecture and cross-modality universality statements cannot be evaluated.
minor comments (2)
- [Abstract] The abstract asserts 'rigorous proofs' yet contains no equations, derivations, or theorem statements; the reader must reach the body to locate the actual mathematical content.
- [Notation and definitions] Notation: 'Temporal Semantic Surrogate' is introduced without an early, self-contained mathematical definition; its precise functional form and caching rule should be stated before the backward-error argument.
Simulated Author's Rebuttal
We sincerely thank the referee for their detailed and insightful comments on our manuscript. We have carefully considered each point and provide point-by-point responses below. Where appropriate, we have made revisions to clarify the theoretical claims and strengthen the empirical evidence.
read point-by-point responses
-
Referee: [Proof of topological reducibility (§3)] The central claim (abstract and §3) that the explicit zigzag sequence is topologically reducible and that intermediate states can be algebraically annihilated via operator dualities without cumulative drift from the true marginal distribution is load-bearing for both the zero-cost assertion and the subsequent backward-error result. In the discrete PF-ODE setting, exact commutation or duality relations typically hold only in the continuous-time limit; finite-step truncation and off-manifold evaluations can leave nonzero residual terms that the Temporal Semantic Surrogate cache may not cancel, undermining the claim that no additional fitted corrections are required.
Authors: We thank the referee for highlighting this important aspect of the discrete setting. In Section 3, our proof of topological reducibility relies on the exact commutation properties derived from the Probability Flow ODE's structure, which ensures that the operator dualities annihilate intermediates precisely even in finite steps, without residual drift. The Temporal Semantic Surrogate is introduced later for efficiency and does not affect the annihilation. To further address concerns about truncation, we have added a detailed remark in the revised manuscript explaining why off-manifold errors are eliminated by the algebraic collapse, supported by the backward error framework. This maintains the zero-cost and parameter-free claims. revision: partial
-
Referee: [Backward Error Analysis (§4)] §4 (Backward Error Analysis): the statement that the discrete collapse 'inherently synthesizes a directional derivative curvature penalty' must be shown to be independent of the particular definition of the Temporal Semantic Surrogate. If the penalty term arises only after the surrogate is introduced, the result is not an intrinsic property of the collapse and the 'parameter-free' character asserted in the abstract is compromised.
Authors: The backward error analysis in Section 4 is performed on the discrete collapse operation alone. We explicitly derive the directional derivative penalty from the error expansion of the annihilation step, which is independent of the surrogate cache. The surrogate is merely a computational optimization exploiting temporal coherence and does not contribute to the penalty term. We have revised the text to emphasize this separation and included an additional equation showing the penalty derivation without reference to the cache. revision: partial
-
Referee: [Empirical evaluations (§5–6)] Empirical section (likely §5–6): the claim that $Z^2$-Sampling 'structurally shatters the performance-efficiency Pareto frontier' and restores exact 2-NFE behavior requires tabulated quantitative results (FID, CLIP score, etc.) with error bars, direct comparison against the unmodified 2-NFE baseline, and ablation of the surrogate cache. Without these, the cross-architecture and cross-modality universality statements cannot be evaluated.
Authors: We agree that providing detailed quantitative results is crucial for validating the claims. In the revised version, we have added comprehensive tables in Sections 5 and 6 reporting FID, CLIP scores, and other metrics with error bars (standard deviation over multiple seeds) for Z²-Sampling compared to the standard 2-NFE baseline across U-Net and DiT architectures, as well as image and video modalities. Additionally, we include an ablation study isolating the effect of the Temporal Semantic Surrogate cache. These results confirm the performance improvements and Pareto frontier advancement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on a formal proof of topological reducibility of the zigzag sequence and algebraic annihilation of intermediates via operator dualities, followed by a Backward Error Analysis establishing an inherent curvature penalty in the discrete collapse. These are presented as independent mathematical results applied to the Probability Flow ODE setting, with the Z²-Sampling construction then shown to restore the 2-NFE baseline. No equations or steps reduce by construction to fitted inputs, self-citations, or renamed empirical patterns; the derivation chain remains self-contained with external mathematical content rather than tautological equivalence to its own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- ad hoc to paper The explicit zigzag sequence is topologically reducible.
- domain assumption The Probability Flow ODE possesses sufficient temporal coherence to support a dynamically cached Temporal Semantic Surrogate without drift.
invented entities (1)
-
Temporal Semantic Surrogate
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection, 2024
Lichen Bai, Shitong Shao, Zikai Zhou, Zipeng Qi, Zhiqiang Xu, Haoyi Xiong, and Zeke Xie. Zigzag diffusion sampling: Diffusion models can self-improve via self-reflection, 2024. URL https://arxiv.org/abs/2412.10891. 22
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023. URLhttps://arxiv.org/abs/2311.15127
work page internal anchor Pith review arXiv 2023
-
[3]
Sato: Stable text-to-motion framework
Wenshuo chen, Hongru Xiao, Erhang Zhang, Lijie Hu, Lei Wang, Mengyuan Liu, and Chen Chen. Sato: Stable text-to-motion framework. InProceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 6989–6997. ACM, October 2024. doi: 10.1145/ 3664647.3681034. URLhttp://dx.doi.org/10.1145/3664647.3681034
-
[4]
Wenshuo Chen, Haosen Li, Shaofeng Liang, Lei Wang, Haozhe Jia, Kaishen Yuan, Jieming Wu, Bowen Tian, and Yutao Yue. Polaris: Projection-orthogonal least squares for robust and adaptive inversion in diffusion models, 2025. URLhttps://arxiv.org/abs/2512.00369
-
[5]
Ant: Adaptive neural temporal- aware text-to-motion model
Wenshuo Chen, Kuimou Yu, Jia Haozhe, Kaishen Yuan, Zexu Huang, Bowen Tian, Songning Lai, Hongru Xiao, Erhang Zhang, Lei Wang, and Yutao Yue. Ant: Adaptive neural temporal- aware text-to-motion model. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 9852–9861. ACM, October 2025. doi: 10.1145/3746027.3755168. URLhttp://dx.d...
-
[6]
arXiv preprint arXiv:2406.08070(2024)
Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. Cfg++: Manifold-constrained classifier free guidance for diffusion models, 2024. URLhttps://arxiv. org/abs/2406.08070
-
[7]
Geneval: An object-focused frame- work for evaluating text-to-image alignment, 2023
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused frame- work for evaluating text-to-image alignment, 2023. URLhttps://arxiv.org/abs/2310. 11513
2023
-
[8]
Ernst Hairer, Gerhard Wanner, and Christian Lubich.Backward Error Analysis and Struc- ture Preservation, pages 337–388. Springer Berlin Heidelberg, Berlin, Heidelberg, 2006. ISBN 978-3-540-30666-5. doi: 10.1007/3-540-30666-8 9. URLhttps://doi.org/10.1007/ 3-540-30666-8_9
-
[9]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. URLhttps://arxiv. org/abs/2207.12598
work page internal anchor Pith review arXiv 2022
-
[10]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020. URLhttps://arxiv.org/abs/2006.11239
work page internal anchor Pith review arXiv 2020
-
[11]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models, 2022. URLhttps://arxiv.org/abs/2204.03458
work page internal anchor Pith review arXiv 2022
-
[12]
Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention, 2024
Susung Hong. Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention, 2024. URLhttps://arxiv.org/abs/2408.00760
-
[13]
Physics-informed representation alignment for sparse radio-map reconstruction, 2025
Haozhe Jia, Wenshuo Chen, Zhihui Huang, Lei Wang, Hongru Xiao, Nanqian Jia, Keming Wu, Songning Lai, Bowen Tian, and Yutao Yue. Physics-informed representation alignment for sparse radio-map reconstruction, 2025. URLhttps://arxiv.org/abs/2501.19160
-
[14]
arXiv preprint arXiv:2310.01506 (2023)
Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct inversion: Boosting diffusion-based editing with 3 lines of code, 2023. URLhttps://arxiv.org/abs/2310.01506. 23
-
[15]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models, 2022. URLhttps://arxiv.org/abs/2206.00364
work page internal anchor Pith review arXiv 2022
-
[16]
Kingma, Tim Salimans, Ben Poole, and Jonathan Ho
Diederik P. Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models,
- [17]
-
[18]
Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023. URL https://arxiv.org/abs/2305.01569
-
[19]
Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chinese understanding, 2024
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue,...
2024
-
[20]
arXiv.csabs/2305.08891(2023) 1
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed, 2024. URLhttps://arxiv.org/abs/2305.08891
-
[21]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2023
- [22]
-
[23]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. URLhttps://arxiv.org/abs/2209.03003
work page internal anchor Pith review arXiv 2022
-
[24]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. Sora: A review on background, technology, limitations, and opportunities of large vision models, 2024. URL https://arxiv.org/abs/2402.17177
work page internal anchor Pith review arXiv 2024
-
[25]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps, 2022. URL https://arxiv.org/abs/2206.00927
-
[26]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models.Machine Intelligence Re- search, 22(4):730–751, June 2025. ISSN 2731-5398. doi: 10.1007/s11633-025-1562-4. URL http://dx.doi.org/10.1007/s11633-025-1562-4
-
[27]
Repaint: Inpainting using denoising diffusion probabilistic models, 2022
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models, 2022. URLhttps: //arxiv.org/abs/2201.09865
-
[28]
The lottery ticket hypothesis in denoising: Towards semantic-driven initialization, 2024
Jiafeng Mao, Xueting Wang, and Kiyoharu Aizawa. The lottery ticket hypothesis in denoising: Towards semantic-driven initialization, 2024. URLhttps://arxiv.org/abs/2312.08872. 24
-
[29]
Understanding ssim.arXiv preprint arXiv:2006.13846, 2020
Jim Nilsson and Tomas Akenine-M¨ oller. Understanding ssim, 2020. URLhttps://arxiv. org/abs/2006.13846
-
[30]
Mang Ning, Mingxiao Li, Jianlin Su, Haozhe Jia, Lanmiao Liu, Martin Beneˇ s, Wenshuo Chen, Albert Ali Salah, and Itir Onal Ertugrul. Dctdiff: Intriguing properties of image generative modeling in the dct space, 2025. URLhttps://arxiv.org/abs/2412.15032
-
[31]
Mao Po-Yuan, Shashank Kotyan, Tham Yik Foong, and Danilo Vasconcellos Vargas. Synthetic shifts to initial seed vector exposes the brittle nature of latent-based diffusion models, 2023. URLhttps://arxiv.org/abs/2312.11473
-
[32]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨ uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review arXiv 2023
-
[33]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https://arxiv.org/abs/2103.00020
work page internal anchor Pith review arXiv 2021
-
[34]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models, 2022. URLhttps://arxiv. org/abs/2112.10752
work page Pith review arXiv 2022
-
[35]
Align your steps: Optimizing sampling schedules in diffusion models, 2024
Amirmojtaba Sabour, Sanja Fidler, and Karsten Kreis. Align your steps: Optimizing sampling schedules in diffusion models, 2024. URLhttps://arxiv.org/abs/2404.14507
-
[36]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to- image diffusion models with deep language understanding, 2022. URLhttps://arxiv.org/ abs/2205.11487
work page internal anchor Pith review arXiv 2022
-
[37]
Generating images of rare concepts using pre-trained diffusion models, 2023
Dvir Samuel, Rami Ben-Ari, Simon Raviv, Nir Darshan, and Gal Chechik. Generating images of rare concepts using pre-trained diffusion models, 2023. URLhttps://arxiv.org/abs/ 2304.14530
-
[38]
arXiv preprint arXiv:2311.17042 (2023)
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023. URLhttps://arxiv.org/abs/2311.17042
-
[39]
LAION-5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmar- czyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text model...
work page internal anchor Pith review arXiv 2022
-
[40]
Rethinking the spatial inconsistency in classifier-free diffusion guidance, 2024
Dazhong Shen, Guanglu Song, Zeyue Xue, Fu-Yun Wang, and Yu Liu. Rethinking the spatial inconsistency in classifier-free diffusion guidance, 2024. URLhttps://arxiv.org/abs/2404. 05384. 25
2024
-
[41]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make- a-video: Text-to-video generation without text-video data, 2022. URLhttps://arxiv.org/ abs/2209.14792
work page internal anchor Pith review arXiv 2022
-
[42]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URLhttps://arxiv.org/abs/2010.02502
work page internal anchor Pith review arXiv 2022
-
[43]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv.org/abs/2011.13456
work page internal anchor Pith review arXiv 2021
-
[44]
Diffusion model alignment using direct preference optimization, 2023
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization, 2023. URLhttps://arxiv.org/abs/2311.12908
-
[45]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review arXiv 2023
-
[46]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation, 2023
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation, 2023. URLhttps://arxiv.org/abs/2212. 11565
2023
-
[47]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text- to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review arXiv 2023
-
[48]
Imagereward: Learning and evaluating human preferences for text-to-image generation,
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation,
- [49]
-
[50]
Good seed makes a good crop: Discovering secret seeds in text-to-image diffusion models, 2025
Katherine Xu, Lingzhi Zhang, and Jianbo Shi. Good seed makes a good crop: Discovering secret seeds in text-to-image diffusion models, 2025. URLhttps://arxiv.org/abs/2405. 14828
2025
-
[51]
Restart sampling for improving generative processes, 2023
Yilun Xu, Mingyang Deng, Xiang Cheng, Yonglong Tian, Ziming Liu, and Tommi Jaakkola. Restart sampling for improving generative processes, 2023. URLhttps://arxiv.org/abs/ 2306.14878
-
[52]
Text-to-image rectified flow as plug-and-play priors, 2025
Xiaofeng Yang, Cheng Chen, Xulei Yang, Fayao Liu, and Guosheng Lin. Text-to-image rectified flow as plug-and-play priors, 2025. URLhttps://arxiv.org/abs/2406.03293
-
[53]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review arXiv 2024
-
[54]
Co- emogen: Towards semantically-coherent and scalable emotional image content generation,
Kaishen Yuan, Yuting Zhang, Shang Gao, Yijie Zhu, Wenshuo Chen, and Yutao Yue. Co- emogen: Towards semantically-coherent and scalable emotional image content generation,
- [55]
-
[56]
Chronomagic-bench: A benchmark for meta- morphic evaluation of text-to-time-lapse video generation.Advances in Neural Information Processing Systems, 37:21236–21270, 2024
Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Rui-Jie Zhu, Xinhua Cheng, Jiebo Luo, and Li Yuan. Chronomagic-bench: A benchmark for meta- morphic evaluation of text-to-time-lapse video generation.Advances in Neural Information Processing Systems, 37:21236–21270, 2024
2024
-
[57]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[58]
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor- corrector framework for fast sampling of diffusion models, 2023. URLhttps://arxiv.org/ abs/2302.04867
-
[59]
Golden noise for diffusion models: A learning framework
Zikai Zhou, Shitong Shao, Lichen Bai, Shufei Zhang, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for diffusion models: A learning framework, 2025. URLhttps://arxiv.org/ abs/2411.09502. 27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.