Recognition: unknown
Pref-CTRL: Preference Driven LLM Alignment using Representation Editing
Pith reviewed 2026-05-08 06:24 UTC · model grok-4.3
The pith
Pref-CTRL aligns LLMs at test time by editing representations with a preference-trained multi-objective value function.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
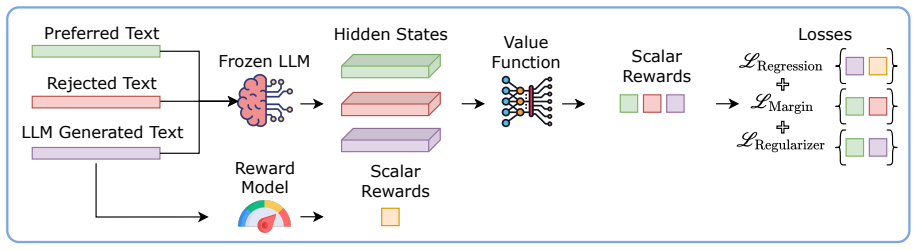
Pref-CTRL trains a multi-objective value function over an LLM's hidden states on preference data so that gradient-based editing at test time produces outputs that better satisfy human preferences. The framework directly incorporates the pairwise preference structure that defines most alignment tasks, unlike single-objective baselines.
What carries the argument
The multi-objective value function, which scores hidden states according to several preference objectives simultaneously to supply editing gradients.
If this is right
- Outperforms RE-Control on two benchmark datasets for preference-based alignment.
- Shows greater generalization on out-of-domain datasets.
- Enables alignment via lightweight representation edits rather than full model fine-tuning.
- Directly encodes the pairwise preference structure of alignment data in the value function.
Where Pith is reading between the lines
- The same multi-objective training pattern could be ported to other representation-editing techniques beyond the RE-Control baseline.
- Handling multiple objectives at once may help manage trade-offs when preferences contain internal conflicts.
- Varying the number or weighting of objectives offers a direct experimental knob for studying how preference granularity affects alignment quality.
Load-bearing premise
That training a multi-objective value function on preference data will inherently better reflect the structure of alignment tasks and lead to superior performance and generalization compared to prior single-objective methods.
What would settle it
Running Pref-CTRL and RE-Control side-by-side on the same two benchmark datasets and finding no performance advantage or no improvement on out-of-domain tests would falsify the central claim.
Figures



read the original abstract
Test-time alignment methods offer a promising alternative to fine-tuning by steering the outputs of large language models (LLMs) at inference time with lightweight interventions on their internal representations. Recently, a prominent and effective approach, RE-Control (Kong et al., 2024), has proposed leveraging an external value function trained over the LLM's hidden states to guide generation via gradient-based editing. While effective, this method overlooks a key characteristic of alignment tasks, i.e. that they are typically formulated as learning from human preferences between candidate responses. To address this, in this paper we propose a novel preference-based training framework, Pref-CTRL, that uses a multi-objective value function to better reflect the structure of preference data. Our approach has outperformed RE-Control on two benchmark datasets and showed greater generalization on out-of-domain datasets. Our source code is available at https://github.com/UTS-nlPUG/pref-ctrl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pref-CTRL, a test-time alignment method for LLMs that performs representation editing guided by a multi-objective value function trained on human preference pairs. It extends RE-Control (Kong et al., 2024) by replacing the single-objective value function with a multi-objective one intended to better capture the structure of preference data, and claims to outperform the baseline on two benchmark datasets while exhibiting stronger out-of-domain generalization. Source code is released at a public GitHub repository.
Significance. If the empirical claims are substantiated with proper controls and ablations, Pref-CTRL could advance test-time alignment techniques by explicitly incorporating the pairwise preference structure typical of alignment tasks, potentially yielding more robust steering of LLM outputs without fine-tuning. The public release of source code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract: The central claims of outperformance over RE-Control on two benchmark datasets and greater generalization on out-of-domain datasets are asserted without any metrics, statistical tests, dataset descriptions, or experimental methodology. This omission is load-bearing because the paper's primary contribution is the reported superiority of the multi-objective approach.
- [Experimental evaluation] Experimental evaluation: No ablation isolates the multi-objective value function (or its training on preference pairs) from other differences in data, architecture, or editing procedure relative to RE-Control. Without this, it cannot be determined whether observed gains arise from the stated preference-driven innovation or from uncontrolled factors, directly undermining the weakest assumption that the multi-objective structure inherently better reflects preference geometry.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and have revised the paper accordingly to strengthen the presentation of our results and experimental design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance over RE-Control on two benchmark datasets and greater generalization on out-of-domain datasets are asserted without any metrics, statistical tests, dataset descriptions, or experimental methodology. This omission is load-bearing because the paper's primary contribution is the reported superiority of the multi-objective approach.
Authors: We agree that the abstract would be strengthened by including quantitative details. In the revised manuscript, we will update the abstract to report specific metrics (e.g., performance deltas versus RE-Control), note the benchmark and out-of-domain datasets used, and briefly reference the evaluation protocol and statistical significance where applicable. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: No ablation isolates the multi-objective value function (or its training on preference pairs) from other differences in data, architecture, or editing procedure relative to RE-Control. Without this, it cannot be determined whether observed gains arise from the stated preference-driven innovation or from uncontrolled factors, directly undermining the weakest assumption that the multi-objective structure inherently better reflects preference geometry.
Authors: We acknowledge the importance of isolating the multi-objective component. The original experiments compare Pref-CTRL to RE-Control but lack a controlled ablation of the multi-objective value function versus a single-objective counterpart on identical data and architecture. In the revision, we will add such an ablation study, training a single-objective baseline on the same preference pairs and reporting results under matched conditions to demonstrate the contribution of the multi-objective preference structure. revision: yes
Circularity Check
No significant circularity; empirical extension of external prior work
full rationale
The paper's chain begins with the external RE-Control method (Kong et al., 2024) and proposes Pref-CTRL as a modification using a multi-objective value function trained on preference pairs. No equations, derivations, or self-citations are present that reduce any claimed result to its inputs by construction. Performance and generalization claims are framed as empirical outcomes on benchmarks rather than mathematical necessities. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chenjia Bai, Yang Zhang, Shuang Qiu, Qiaosheng Zhang, Kang Xu, and Xuelong Li. 2025. https://openreview.net/forum?id=cfKZ5VrhXt Online preference alignment for language models via count-based exploration . In The Thirteenth International Conference on Learning Representations
2025
-
[2]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and 1 others. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review arXiv 2022
-
[3]
Boxi Cao, Keming Lu, Xinyu Lu, Jiawei Chen, Mengjie Ren, Hao Xiang, Peilin Liu, Yaojie Lu, Ben He, Xianpei Han, Le Sun, Hongyu Lin, and Bowen Yu. 2024. https://doi.org/10.48550/arXiv.2406.01252 Towards scalable automated alignment of llms: A survey . ArXiv, abs/2406.01252
-
[4]
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, and 1 others. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90\ See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6
2023
- [5]
-
[6]
DeepSeek-AI. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning . Preprint, arXiv:2501.12948
work page internal anchor Pith review arXiv 2025
-
[7]
Karel D ' Oosterlinck, Winnie Xu, Chris Develder, Thomas Demeester, Amanpreet Singh, Christopher Potts, Douwe Kiela, and Shikib Mehri. 2025. https://doi.org/10.1162/tacl_a_00748 Anchored preference optimization and contrastive revisions: Addressing underspecification in alignment . Transactions of the Association for Computational Linguistics, 13:442--460
-
[8]
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. 2018. http://aclweb.org/anthology/P18-1128 The hitchhiker's guide to testing statistical significance in natural language processing . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1383--1392. Association for Computational ...
2018
-
[9]
Kawin Ethayarajh, Yejin Choi, and Swabha Swayamdipta. 2022. Understanding dataset difficulty with V -usable information. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 5988--6008. PMLR
2022
-
[10]
H. Fernando, Han Shen, Parikshit Ram, Yi Zhou, Horst Samulowitz, Nathalie Baracaldo, and Tianyi Chen. 2024. https://doi.org/10.48550/arXiv.2410.15483 Mitigating forgetting in llm supervised fine-tuning and preference learning . ArXiv, abs/2410.15483
-
[11]
Leo Gao, John Schulman, and Jacob Hilton. 2023. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835--10866. PMLR
2023
-
[12]
Qi Gou and C. Nguyen. 2024. https://doi.org/10.48550/arXiv.2403.19443 Mixed preference optimization: Reinforcement learning with data selection and better reference model . ArXiv, abs/2403.19443
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review arXiv 2024
-
[14]
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Tianyi Alex Qiu, Juntao Dai, and Yaodong Yang. 2024. Aligner: Efficient alignment by learning to correct. Advances in Neural Information Processing Systems, 37:90853--90890
2024
-
[15]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36:24678--24704
2023
- [16]
-
[17]
Lingkai Kong, Haorui Wang, Wenhao Mu, Yuanqi Du, Yuchen Zhuang, Yifei Zhou, Yue Song, Rongzhi Zhang, Kai Wang, and Chao Zhang. 2024. https://openreview.net/forum?id=yTTomSJsSW Aligning large language models with representation editing: A control perspective . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
- [18]
-
[19]
Yanyang Li, Michael R. Lyu, and Liwei Wang. 2025 a . https://doi.org/10.18653/v1/2025.acl-long.262 Learning to reason from feedback at test-time . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5241--5253, Vienna, Austria. Association for Computational Linguistics
-
[20]
Yichen Li, Zhiting Fan, Ruizhe Chen, Xiaotang Gai, Luqi Gong, Yan Zhang, and Zuozhu Liu. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.589 F air S teer: Inference time debiasing for LLM s with dynamic activation steering . In Findings of the Association for Computational Linguistics: ACL 2025, pages 11293--11312, Vienna, Austria. Association for ...
-
[21]
Baijiong Lin, Weisen Jiang, Yuancheng Xu, Hao Chen, and Ying-Cong Chen. 2025. PARM : Multi-objective test-time alignment via preference-aware autoregressive reward model. In International Conference on Machine Learning
2025
-
[22]
OpenAI. 2025. Open AI API documentation. https://platform.openai.com/docs
2025
-
[23]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[24]
Yifu QIU, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo Ponti, and Shay B Cohen. 2024. https://openreview.net/forum?id=pqYceEa87j Spectral editing of activations for large language model alignment . In The Thirty-eighth Annual Conference on Neural Information Processing Systems
2024
-
[25]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[26]
Saddam Hossain Mukta, Kaniz Fatema, Nur Mohammad Fahad, Sadman Sakib, Most
Mohaimenul Azam Khan Raiaan, Md. Saddam Hossain Mukta, Kaniz Fatema, Nur Mohammad Fahad, Sadman Sakib, Most. Marufatul Jannat Mim, Jubaer Ahmad, Mohammed Eunus Ali, and Sami Azam. 2024. https://doi.org/10.1109/ACCESS.2024.3365742 A review on large language models: Architectures, applications, taxonomies, open issues and challenges . IEEE Access, 12:26839--26874
-
[27]
Rex Clark Robinson. 2012. An introduction to dynamical systems: continuous and discrete, volume 19. American Mathematical Soc
2012
-
[28]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review arXiv 2017
-
[29]
Richard S Sutton, Andrew G Barto, and 1 others. 1998. Reinforcement learning: An introduction, volume 1. MIT press Cambridge
1998
- [30]
-
[31]
Emanuel Todorov and 1 others. 2006. Optimal control theory. Bayesian brain: probabilistic approaches to neural coding, pages 268--298
2006
-
[32]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. 2020. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl
2020
-
[33]
Kuang-Da Wang, Teng-Ruei Chen, Yu Heng Hung, Guo-Xun Ko, Shuoyang Ding, Yueh-Hua Wu, Yu-Chiang Frank Wang, Chao-Han Huck Yang, Wen-Chih Peng, and Ping-Chun Hsieh. 2025. Plan2align: Predictive planning based test-time preference alignment for large language models. arXiv preprint arXiv:2502.20795
-
[34]
Zhichao Wang, Bin Bi, Shiva Kumar Pentyala, Kiran Ramnath, Sougata Chaudhuri, Shubham Mehrotra, Xiang-Bo Mao, Sitaram Asur, and 1 others. 2024. A comprehensive survey of llm alignment techniques: Rlhf, rlaif, ppo, dpo and more. arXiv preprint arXiv:2407.16216
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Jiancong Xiao, Ziniu Li, Xingyu Xie, Emily Getzen, Cong Fang, Qi Long, and Weijie J. Su. 2025. https://doi.org/10.1080/01621459.2025.2555067 On the algorithmic bias of aligning large language models with rlhf: Preference collapse and matching regularization . Journal of the American Statistical Association, 0(ja):1--21
-
[36]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. 2024. https://openreview.net/forum?id=51iwkioZpn Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation . In ICML
2024
-
[37]
Yuancheng Xu, Udari Madhushani Sehwag, Alec Koppel, Sicheng Zhu, Bang An, Furong Huang, and Sumitra Ganesh. 2025. Genarm: Reward guided generation with autoregressive reward model for test-time alignment. In The Thirteenth International Conference on Learning Representations
2025
-
[38]
Zhaowei Zhang, Fengshuo Bai, Qizhi Chen, Chengdong Ma, Mingzhi Wang, Haoran Sun, Zilong Zheng, and Yaodong Yang. 2025. https://openreview.net/forum?id=f9w89OY2cp Amulet: Realignment during test time for personalized preference adaptation of LLM s . In The Thirteenth International Conference on Learning Representations
2025
-
[39]
Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, and Jiantao Jiao. 2023. Starling-7b: Improving llm helpfulness & harmlessness with rlaif
2023
-
[40]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[41]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.