Recognition: unknown
ClawMark: A Living-World Benchmark for Multi-Turn, Multi-Day, Multimodal Coworker Agents
Pith reviewed 2026-05-08 06:33 UTC · model grok-4.3
The pith
Current frontier AI agents fully complete only 20% of multi-turn multi-day coworker tasks when the surrounding environment evolves independently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The benchmark contains 100 tasks across 13 professional scenarios executed against five stateful services and scored by 1537 deterministic Python checkers. Benchmarking frontier agent systems yields a maximum weighted score of 75.8 yet only 20.0% strict task success. Turn-level analysis shows performance declines after the first exogenous environment update.
What carries the argument
A stateful sandboxed service environment whose state evolves between turns independently of the agent, together with rule-based verification by deterministic Python checkers.
Load-bearing premise
The 100 tasks, 13 scenarios, five stateful services, and 1537 deterministic checkers accurately capture the core challenges of real-world multi-day coworker agent performance in evolving environments.
What would settle it
An agent system that maintains above 50% strict task success across the full set of 100 tasks even after multiple independent service updates would indicate that adaptation to changing state is not the primary barrier.
Figures



read the original abstract
Language-model agents are increasingly used as persistent coworkers that assist users across multiple working days. During such workflows, the surrounding environment may change independently of the agent: new emails arrive, calendar entries shift, knowledge-base records are updated, and evidence appears across images, scanned PDFs, audio, video, and spreadsheets. Existing benchmarks do not adequately evaluate this setting because they typically run within a single static episode and remain largely text-centric. We introduce \bench{}, a benchmark for coworker agents built around multi-turn multi-day tasks, a stateful sandboxed service environment whose state evolves between turns, and rule-based verification. The current release contains 100 tasks across 13 professional scenarios, executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet) and scored by 1537 deterministic Python checkers over post-execution service state; no LLM-as-judge is invoked during scoring. We benchmark seven frontier agent systems. The strongest model reaches 75.8 weighted score, but the best strict Task Success is only 20.0\%, indicating that partial progress is common while complete end-to-end workflow completion remains rare. Turn-level analysis shows that performance drops after the first exogenous environment update, highlighting adaptation to changing state as a key open challenge. We release the benchmark, evaluation harness, and construction pipeline to support reproducible coworker-agent evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClawMark, a benchmark for multi-turn, multi-day multimodal coworker agents operating in a living-world setting. It features 100 tasks across 13 professional scenarios executed against five stateful sandboxed services (filesystem, email, calendar, knowledge base, spreadsheet), with scoring performed by 1537 deterministic Python checkers on post-execution state and no LLM judges. Seven frontier agent systems are evaluated; the strongest achieves a 75.8 weighted score but only 20.0% strict Task Success, with turn-level analysis indicating performance drops after the first exogenous environment update.
Significance. If the tasks and checkers are representative, the benchmark provides a valuable, reproducible platform for evaluating long-horizon agent adaptation in dynamic, multimodal environments, addressing a clear gap in existing static and text-centric evaluations. The open release of the benchmark, evaluation harness, and construction pipeline is a notable strength that enables direct inspection and extension by the community.
major comments (2)
- [§3] §3 (Benchmark Construction): The manuscript provides no description of the process used to validate the 1537 deterministic checkers for correctness across state transitions or to ensure the 100 tasks require genuine multi-day adaptation to exogenous changes. This is load-bearing for the central empirical claim that strict end-to-end completion remains rare (20%) while partial progress is common.
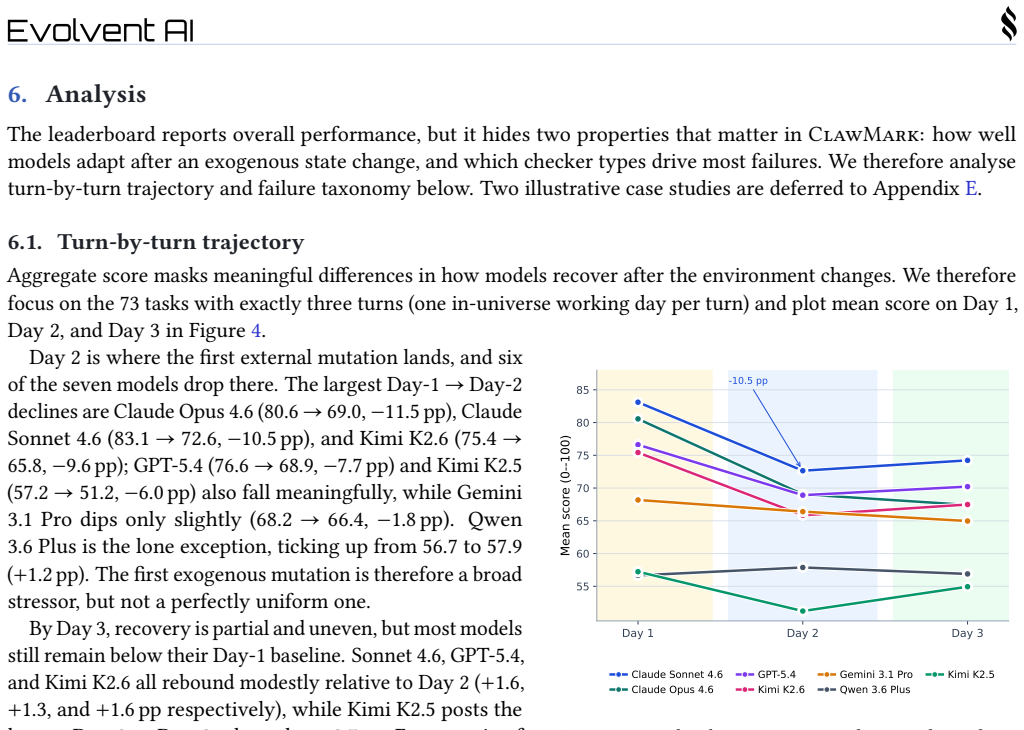
- [§4.3] §4.3 (Turn-level Analysis): The reported performance drop after the first exogenous update is not accompanied by quantitative breakdowns (e.g., per-service or per-scenario deltas, or comparison to intra-turn baselines), making it difficult to confirm that adaptation to changing state is the primary gap rather than other factors such as initial planning or tool use.
minor comments (2)
- [Abstract] The abstract and §1 would benefit from a brief explicit statement of the weighted scoring formula to clarify how it differs from strict Task Success.
- [§4] Figure captions for the turn-level plots should include the exact number of turns analyzed and any filtering criteria applied to the 100 tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment below and describe the changes we will incorporate into the revised manuscript.
read point-by-point responses
-
Referee: §3 (Benchmark Construction): The manuscript provides no description of the process used to validate the 1537 deterministic checkers for correctness across state transitions or to ensure the 100 tasks require genuine multi-day adaptation to exogenous changes. This is load-bearing for the central empirical claim that strict end-to-end completion remains rare (20%) while partial progress is common.
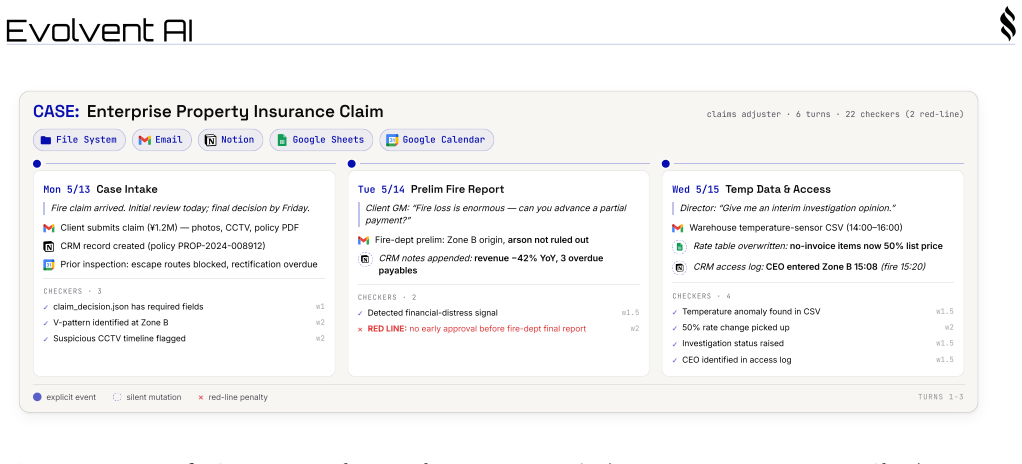
Authors: We agree that explicit documentation of the checker validation process and task design criteria would strengthen the paper. In the revised §3 we will add a dedicated subsection describing the validation workflow: each checker was subjected to unit tests exercising all relevant state transitions (including exogenous updates), followed by author-led manual inspection of 20% of tasks for semantic correctness. We will also report aggregate statistics on exogenous changes per task (mean 3.2 updates across the 100 tasks) together with two concrete task examples that illustrate required multi-day adaptation, thereby supporting the claim that low strict success rates reflect adaptation challenges rather than checker artifacts. revision: yes
-
Referee: §4.3 (Turn-level Analysis): The reported performance drop after the first exogenous update is not accompanied by quantitative breakdowns (e.g., per-service or per-scenario deltas, or comparison to intra-turn baselines), making it difficult to confirm that adaptation to changing state is the primary gap rather than other factors such as initial planning or tool use.
Authors: We accept that the current turn-level analysis would be more convincing with finer-grained quantitative support. In the revised §4.3 we will insert two new tables: one showing per-service and per-scenario success-rate deltas between the turn immediately preceding and following the first exogenous update, and a second comparing overall task success on the subset of tasks that contain at least one exogenous change versus an intra-turn baseline constructed from the same tasks with updates artificially removed. These additions will allow readers to assess whether the observed drop is primarily attributable to state adaptation. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper with no derivations, equations, fitted parameters, or predictive claims. The central results (75.8 weighted score, 20% strict success, performance drop after exogenous updates) are direct measurements obtained by running seven agent systems against the released 100 tasks, 1537 deterministic checkers, and five stateful services. Task definitions, scoring logic, and state transitions are explicitly constructed and released for inspection; no step reduces to a self-definition, a fitted input renamed as prediction, or a load-bearing self-citation chain. The paper is self-contained against its own released artifacts.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan.𝜏-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, et al. Theagentcompany: benchmarking llm agents on consequential real world tasks.arXiv preprint arXiv:2412.14161, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
2024
-
[5]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[6]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868, 2026
work page internal anchor Pith review arXiv 2026
-
[8]
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, Lingjun Chen, Fanqing Meng, Lingxiao Du, Yiran Zhao, Fanshi Zhang, Yaoqi Ye, Jiawei Wang, et al. Mcpmark: A benchmark for stress-testing realistic and comprehensive mcp use.arXiv preprint arXiv:2509.24002, 2025
-
[9]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Xiangyi Li, Kyoung Whan Choe, Yimin Liu, Xiaokun Chen, Chujun Tao, Bingran You, Wenbo Chen, Zonglin Di, Jiankai Sun, Shenghan Zheng, et al. Clawsbench: Evaluating capability and safety of llm productivity agents in simulated workspaces.arXiv preprint arXiv:2604.05172, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[12]
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, et al. Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers. arXiv preprint arXiv:2508.20453, 2025
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023. evolvent.co 12
2023
-
[16]
ClawArena: Benchmarking AI Agents in Evolving Information Environments
Haonian Ji, Kaiwen Xiong, Siwei Han, Peng Xia, Shi Qiu, Yiyang Zhou, Jiaqi Liu, Jinlong Li, Bingzhou Li, Zeyu Zheng, et al. Clawarena: Benchmarking ai agents in evolving information environments.arXiv preprint arXiv:2604.04202, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[18]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[19]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta programming for a multi-agent collaborative framework.arXiv preprint arXiv:2308.00352, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Day 1 / Day 2 / Day 3
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023. evolvent.co 13 A. Multi-turn evaluation: terminology and conventions Throughout the paper we use a small terminology set (t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.