Recognition: unknown
Quantum Knowledge Graph: Modeling Context-Dependent Triplet Validity
Pith reviewed 2026-05-08 03:52 UTC · model grok-4.3
The pith
Knowledge graphs improve medical reasoning when each fact's validity is treated as dependent on the patient's specific context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
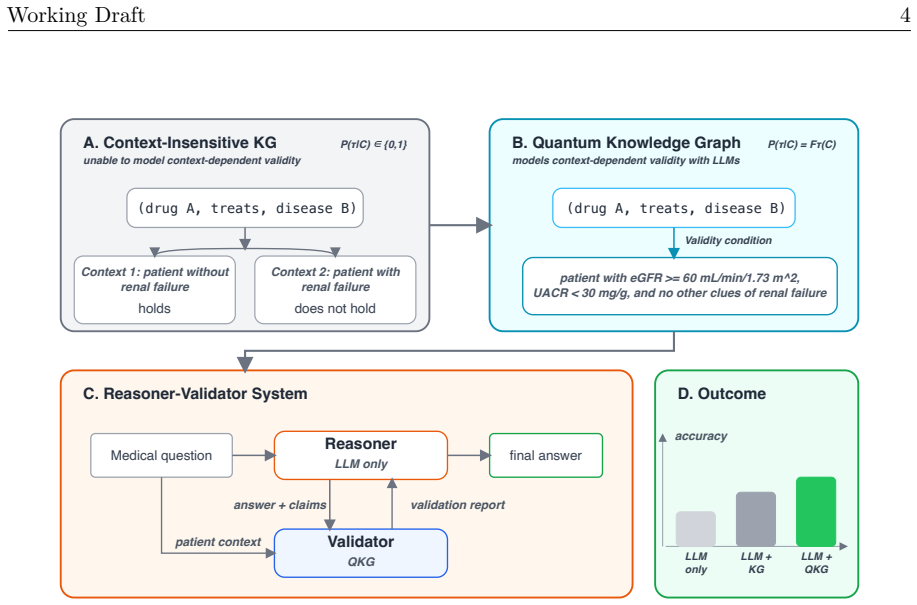
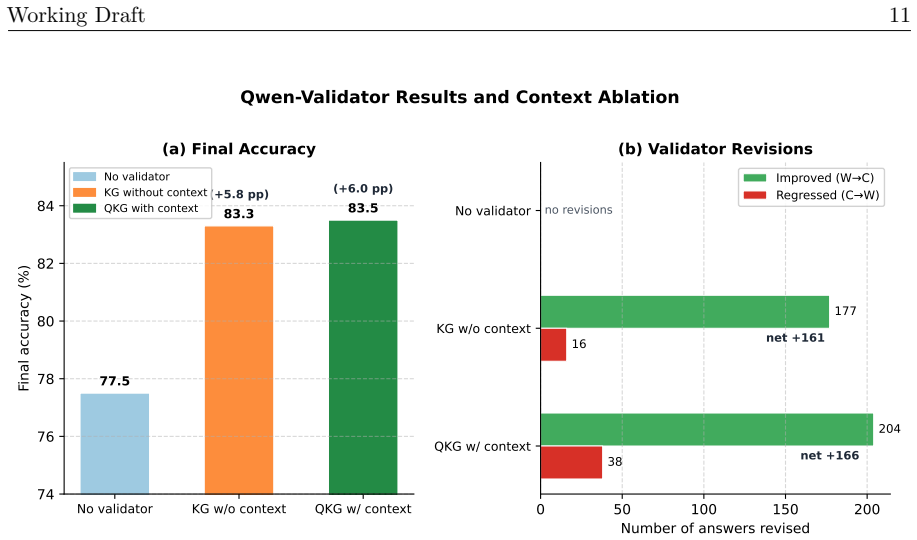
We formulate triplet validity as a triplet-specific function of context and refer to this formulation as a Quantum Knowledge Graph (QKG). We instantiate QKG in medicine using a diabetes-centered PrimeKG subgraph whose 68,651 context-sensitive relations are annotated with patient-group-specific constraints. In a reasoner-validator pipeline on 2,788 KG-grounded MedReason questions, QKG with context matching improves accuracy by 1.40 percentage points over a no-validator baseline and by 0.79 points over ordinary KG validation, with larger gains under a stronger validator.
What carries the argument
The Quantum Knowledge Graph, which represents each triplet's validity as a function of patient-group context through annotated constraints, allowing the validator to match and apply only the relevant facts during reasoning.
If this is right
- KG validation alone raises accuracy by 0.61 percentage points over the no-validator baseline.
- Adding explicit context matching supplies an additional 0.79 percentage point gain on the same questions.
- The benefit of QKG widens to 5.96 points when the validator model is strengthened.
- After correcting for leakage and suspicious items, the context-matching contribution becomes borderline detectable, consistent with a high ceiling on the current benchmark.
Where Pith is reading between the lines
- The same context-filtering principle could be applied to non-medical domains where facts depend on time, location, or user attributes.
- Future knowledge-graph construction may shift effort from adding more triplets toward exhaustively annotating applicability conditions for existing ones.
- The approach suggests a testable extension: measure whether the performance gap grows as the number of distinct patient subgroups in the graph increases.
Load-bearing premise
The 68,651 patient-group constraints accurately and completely describe the situations in which each triplet holds, and the matching step retrieves the right constraints without systematic omissions or false matches.
What would settle it
Replace the context-matching step with random selection of constraints or with a version that ignores the annotations entirely; if the accuracy advantage over the standard KG disappears, the claim that context dependence drives the gain is falsified.
Figures


read the original abstract
Knowledge graphs (KGs) are increasingly used to support large lan guage model (LLM) reasoning, but standard triplet-based KGs treat each relation as globally valid. In many settings, whether a relation should count as evidence depends on the context. We therefore formulate triplet validity as a triplet-specific function of context and refer to this formulation as a Quantum Knowledge Graph (QKG). We instantiate QKG in medicine using a diabetes-centered PrimeKG subgraph, whose 68,651 context-sensitive relations are further annotated with patient-group-specific constraints. We evaluate it in a reasoner--validator pipeline for medical question answering on a KG-grounded subset of MedReason containing 2,788 questions. With Haiku-4.5 as both the Reasoner and the Validator, KG-backed validation significantly improves over a no-validator baseline ($+0.61$ pp), and QKG with context matching yields the largest gain, outperforming both KG validation without context matching ($+0.79$ pp) and the no-validator baseline ($+1.40$ pp; paired McNemar, all $p<0.05$). Under a stronger validator (Qwen-3.6-Plus), the raw QKG gain over the no-validator baseline grows from $+1.40$ pp to $+5.96$ pp; the context-matching gap is non-significant ($p=0.73$) on the raw set but becomes borderline significant ($p=0.05$) after adjustment for knowledge leakage and suspicious questions, consistent with a benchmark-gold ceiling rather than a QKG limitation. Taken together, the results support the view that the value of a KG in LLM-based clinical reasoning lies not merely in storing medically related facts, but in representing whether those facts are applicable to the specific patient context. For reproducibility and further research, we release the curated QKG datasets and source code.\footnote{https://github.com/HKAI-Sci/QKG}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Quantum Knowledge Graphs (QKG) as a formulation in which triplet validity is a context-dependent function rather than globally valid. It instantiates the approach on a diabetes-centered PrimeKG subgraph by annotating 68,651 relations with patient-group-specific constraints and evaluates the resulting QKG inside a reasoner-validator pipeline on a 2,788-question KG-grounded subset of MedReason. With Haiku-4.5 as reasoner and validator, QKG context matching yields +1.40 pp over a no-validator baseline and +0.79 pp over standard KG validation (paired McNemar, p<0.05); larger raw gains appear with a stronger validator, and the context-matching advantage becomes borderline significant after leakage adjustment.
Significance. If the 68,651 annotations and the context-matching retrieval are shown to be accurate and comprehensive, the work supplies concrete evidence that context-aware knowledge representation improves LLM clinical reasoning beyond the mere presence of related facts. The release of the curated QKG datasets and source code is a clear strength that enables direct reproduction and extension.
major comments (2)
- Evaluation section (results with Haiku-4.5 and Qwen-3.6-Plus): the central claim that QKG context matching produces the observed accuracy gains (+1.40 pp and up to +5.96 pp) rests on the premise that the 68,651 patient-group constraints correctly encode triplet applicability and that the matching step in the reasoner-validator pipeline retrieves them without systematic false positives or omissions. The manuscript supplies no description of how the annotations were created, no inter-annotator agreement statistics, and no error analysis or audit of the matching algorithm, leaving the statistical significance (p<0.05) difficult to interpret as evidence for the QKG formulation itself.
- Methods / QKG instantiation paragraph: the abstract states that the 68,651 context-sensitive relations 'are further annotated with patient-group-specific constraints,' yet provides no account of the annotation protocol, coverage criteria, or validation against external medical sources. Because these annotations are the sole mechanism by which context dependence is realized, their unverified quality is load-bearing for the claim that QKG 'correctly encodes' context-dependent validity.
minor comments (2)
- Abstract: 'large lan guage model' contains a typographical space; correct to 'large language model'.
- The manuscript mentions 'post-hoc leakage adjustment' and 'suspicious questions' but does not define the exact criteria or matching algorithm used for leakage detection; a brief methods paragraph would improve clarity without altering the central results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify that the current manuscript lacks sufficient description of the annotation process for the 68,651 constraints. We address each point below and will revise the manuscript to strengthen this aspect.
read point-by-point responses
-
Referee: Evaluation section (results with Haiku-4.5 and Qwen-3.6-Plus): the central claim that QKG context matching produces the observed accuracy gains (+1.40 pp and up to +5.96 pp) rests on the premise that the 68,651 patient-group constraints correctly encode triplet applicability and that the matching step in the reasoner-validator pipeline retrieves them without systematic false positives or omissions. The manuscript supplies no description of how the annotations were created, no inter-annotator agreement statistics, and no error analysis or audit of the matching algorithm, leaving the statistical significance (p<0.05) difficult to interpret as evidence for the QKG formulation itself.
Authors: We agree that the absence of these details weakens the interpretability of the results. In the revised manuscript we will add a dedicated subsection in Methods describing the annotation protocol (expert review of diabetes guidelines and patient subgroup definitions), an audit of the context-matching algorithm with examples of retrieval decisions, and an error analysis quantifying false-positive and false-negative rates on a held-out sample of triplets. Formal inter-annotator agreement was not computed because annotations were produced through iterative consensus among domain experts rather than independent parallel labeling; we will explicitly state this limitation and its implications for the strength of evidence. revision: partial
-
Referee: Methods / QKG instantiation paragraph: the abstract states that the 68,651 context-sensitive relations 'are further annotated with patient-group-specific constraints,' yet provides no account of the annotation protocol, coverage criteria, or validation against external medical sources. Because these annotations are the sole mechanism by which context dependence is realized, their unverified quality is load-bearing for the claim that QKG 'correctly encodes' context-dependent validity.
Authors: We acknowledge the omission. The revised Methods section will include a full description of the annotation protocol, explicit coverage criteria (e.g., age bands, comorbidity profiles, and contraindication rules drawn from ADA and EASD guidelines), and the external sources used for validation. This addition will allow readers to evaluate the quality and completeness of the constraints directly. revision: yes
- Inter-annotator agreement statistics cannot be supplied because they were not calculated in the original annotation workflow.
Circularity Check
No significant circularity detected
full rationale
The paper introduces the QKG formulation as a conceptual extension of standard KGs, instantiates it by annotating 68,651 patient-group constraints on a PrimeKG diabetes subgraph, and evaluates the resulting reasoner-validator pipeline on an external MedReason subset of 2,788 questions against explicit no-validator and plain-KG baselines. No equations or results are fitted to the evaluation data, no self-citations are invoked to justify core premises, and the reported accuracy gains are measured directly on held-out questions without reducing to the same inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baichuan Intelligence
Release note; accessed 2026-04-17. Baichuan Intelligence. Baichuan-m2 technical blog. https://www.baichuan-ai.com/blog/ baichuan-M2,
2026
-
[2]
Accessed 2026-04-13. P. Chandak et al. Primekg: A knowledge graph for precision medicine.Scientific Data,
2026
-
[3]
URL https://aclanthology.org/2023.acl-long.637/
doi: 10.18653/v1/2023.acl-long.637. URL https://aclanthology.org/2023.acl-long.637/. Lijuan Diao, Wei Yang, Penghua Zhu, Gaofang Cao, Shoujun Song, and Yang Kong. The research of clinical temporal knowledge graph based on deep learning.Journal of Intelligent & Fuzzy Systems, 41(3):4265–4274,
-
[4]
Working Draft 15 Zejin Ding, Ning Wang, Shujian Liu, and Guodong Zhou
doi: 10.3233/JIFS-189687. Working Draft 15 Zejin Ding, Ning Wang, Shujian Liu, and Guodong Zhou. Temporal fact reasoning over hyper- relational knowledge graphs. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 345–357. Association for Computational Linguistics,
-
[5]
URLhttps://aclanthology.org/2024.findings-emnlp.20/
doi: 10.18653/ v1/2024.findings-emnlp.20. URLhttps://aclanthology.org/2024.findings-emnlp.20/. John Dougrez-Lewis, Mahmud Elahi Akhter, Federico Ruggeri, Sebastian Löbbers, Yulan He, and Maria Liakata. Assessing the reasoning capabilities of llms in the context of evidence-based claim verification. InFindings of the Association for Computational Linguisti...
2024
-
[6]
CausalGraph2LLM: Evaluating LLMs for causal queries
doi: 10.18653/v1/2025. findings-acl.1059. URLhttps://aclanthology.org/2025.findings-acl.1059/. Mikhail Galkin, Priyansh Trivedi, Gaurav Maheshwari, Ricardo Usbeck, and Jens Lehmann. Message passing for hyper-relational knowledge graphs. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7346–7366. Assoc...
-
[7]
URLhttps: //aclanthology.org/2020.emnlp-main.596/
doi: 10.18653/v1/2020.emnlp-main.596. URLhttps: //aclanthology.org/2020.emnlp-main.596/. Alistair E. W. Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J. Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, Li-wei H. Lehman, Leo A. Celi, and Roger G. Mark. Mimic-iv, a freely accessible electronic health record dataset.Scien...
-
[8]
MIMIC-IV , a freely accessible electronic health record dataset,
doi: 10.1038/s41597-022-01899-x. Shaghayegh Kolli, Richard Rosenbaum, Timo Cavelius, Lasse Strothe, Andrii Lata, and Jana Diesner. Hybrid fact-checking that integrates knowledge graphs, large language models, and search-based retrieval agents improves interpretable claim verification. InProceedings of the 9th Widening NLP Workshop, pages 106–115. Associat...
-
[9]
doi: 10.18653/v1/2025.winlp-main.19. URL https://aclanthology.org/2025.winlp-main.19/. Linfeng Li, Peng Wang, Yao Wang, Shenghui Wang, Jun Yan, Jinpeng Jiang, Buzhou Tang, Chengliang Wang, and Yuting Liu. A method to learn embedding of a probabilistic medical knowledge graph: Algorithm development.JMIR Medical Informatics, 8(5):e17645, 2020a. doi: 10.2196...
-
[10]
doi: 10.18653/v1/2025.findings-acl.602
Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-acl.602. URL https://aclanthology.org/2025.findings-acl. 602/. Qwen Team. Qwen3.6-plus: Towards real world agents.https://qwen.ai/blog?email_hash= 0d7a7050906b225db2718485ca0f3472&id=qwen3.6, 4
-
[11]
Release note; accessed 2026-04-
2026
-
[12]
Question Answering Over Temporal Knowledge Graphs
doi: 10.18653/v1/2021.acl-long.520. URLhttps://aclanthology.org/2021.acl-long.520/. Working Draft 16 Yuan Sui, Yufei He, Zifeng Ding, and Bryan Hooi. Can knowledge graphs make large language models more trustworthy? an empirical study over open-ended question an- swering. InProceedings of the 63rd Annual Meeting of the Association for Computa- tional Ling...
-
[13]
doi: 10.18653/v1/2025.acl-long.622
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.622. URL https://aclanthology.org/2025.acl-long.622/. Michael Wornow, Rahul Thapa, Ethan Steinberg, Jason A. Fries, and Nigam H. Shah. Ehrshot: An ehr benchmark for few-shot evaluation of foundation models. In Advances in Neural Information Processing Systems 36: Datasets and Benchm...
-
[14]
URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ d42db1f74df54cb992b3956eb7f15a6f-Paper-Datasets_and_Benchmarks.pdf. Juncheng Wu, Wenlong Deng, Xingxuan Li, Sheng Liu, Taomian Mi, Yifan Peng, Ziyang Xu, Yi Liu, Hyunjin Cho, Chang-In Choi, et al. Medreason: Eliciting factual medical reasoning steps in llms via knowledge graphs.arXiv preprint...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.