Recognition: unknown
CommFuse: Hiding Tail Latency via Communication Decomposition and Fusion for Distributed LLM Training
Pith reviewed 2026-05-08 04:21 UTC · model grok-4.3
The pith
CommFuse eliminates tail latency in distributed LLM training by decomposing collective operations into peer-to-peer communications that overlap fully with computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CommFuse replaces conventional collective operations of reduce-scatter and all-gather with decomposed peer-to-peer (P2P) communication and schedules partitioned computations to enable fine-grained overlap, providing an exact algorithm for reducing communication overhead that eliminates tail latency while remaining compatible with data-parallel training and tensor-level parallelism strategies such as TPSP and UP.
What carries the argument
CommFuse, the decomposition of collective communications into peer-to-peer exchanges fused with scheduled partitioned computations to achieve exact fine-grained overlap.
Load-bearing premise
That decomposed peer-to-peer communications can be scheduled to overlap completely with computation without adding synchronization costs or changing the numerical results of the original collective operations.
What would settle it
Running CommFuse on a multi-accelerator cluster for a full training step and measuring whether communication tail latency drops to zero compared to prior overlap baselines while keeping identical numerical outputs.
Figures






read the original abstract
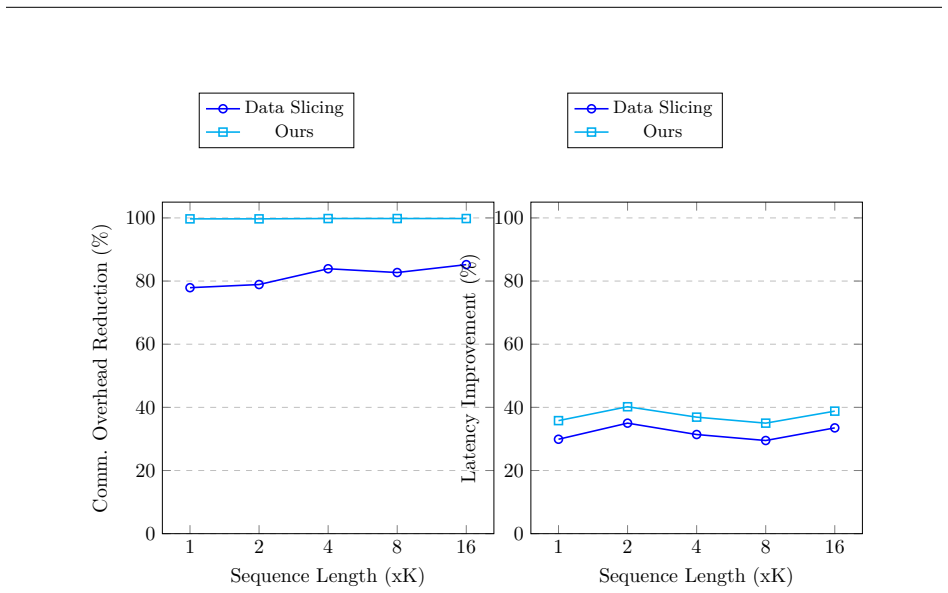
The rapid growth in the size of large language models has necessitated the partitioning of computational workloads across accelerators such as GPUs, TPUs, and NPUs. However, these parallelization strategies incur substantial data communication overhead significantly hindering computational efficiency. While communication-computation overlap presents a promising direction, existing data slicing based solutions suffer from tail latency. To overcome this limitation, this research introduces a novel communication-computation overlap technique to eliminate this tail latency in state of the art overlap methods for distributed LLM training. The aim of this technique is to effectively mitigate communication bottleneck of tensor parallelism and data parallelism for distributed training and inference. In particular, we propose a novel method termed CommFuse that replaces conventional collective operations of reduce-scatter and all-gather with decomposed peer-to-peer (P2P) communication and schedules partitioned computations to enable fine-grained overlap. Our method provides an exact algorithm for reducing communication overhead that eliminates tail latency. Moreover, it presents a versatile solution compatible with data-parallel training and various tensor-level parallelism strategies, including TPSP and UP. Experimental evaluations demonstrate that our technique consistently achieves lower latency, superior Model FLOPS Utilization (MFU), and high throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CommFuse, a communication-computation overlap technique for distributed LLM training that replaces reduce-scatter and all-gather collectives with decomposed peer-to-peer (P2P) communication plus fused partitioned computation scheduling. It claims this yields an exact algorithm that eliminates tail latency while preserving numerical semantics, is compatible with data parallelism and tensor-parallel strategies (TPSP, UP), and delivers lower latency, higher MFU, and improved throughput.
Significance. If the semantic equivalence and tail-free overlap are rigorously established, the approach could meaningfully raise effective utilization in communication-bound large-scale training runs without requiring changes to model numerics or collective libraries.
major comments (2)
- [Abstract] Abstract: the central claim that the method supplies an 'exact algorithm' eliminating tail latency while preserving collective semantics is unsupported by any derivation, equivalence proof, pseudocode, or scheduling invariant; this is load-bearing because the skeptic correctly notes that P2P decomposition of non-associative reductions typically requires fences or coordination that can re-serialize the tail.
- [Method] No section or equation shows that the fine-grained P2P scheduling achieves complete overlap without new global barriers or extra synchronization points that would recreate tail latency or alter reduction order.
minor comments (2)
- The abstract asserts experimental superiority in MFU and throughput but supplies no quantitative baselines, hardware details, or model sizes; these should be added with explicit comparison tables.
- Notation for the decomposed P2P operations and the fusion schedule is introduced without a clear diagram or pseudocode listing the per-rank send/recv and compute steps.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method supplies an 'exact algorithm' eliminating tail latency while preserving collective semantics is unsupported by any derivation, equivalence proof, pseudocode, or scheduling invariant; this is load-bearing because the skeptic correctly notes that P2P decomposition of non-associative reductions typically requires fences or coordination that can re-serialize the tail.
Authors: We acknowledge that the abstract claim requires stronger support. Section 3 of the manuscript describes the decomposition of reduce-scatter and all-gather into ordered P2P operations fused with partitioned computation, with the claim that reduction semantics are preserved because each partial reduction occurs only after its prerequisite P2P transfers complete and the schedule respects original data dependencies. However, we agree a dedicated equivalence argument is needed. In revision we will add a formal proof subsection together with pseudocode that shows the P2P schedule maintains exact collective semantics without extra fences or re-serialization of the tail. revision: yes
-
Referee: [Method] No section or equation shows that the fine-grained P2P scheduling achieves complete overlap without new global barriers or extra synchronization points that would recreate tail latency or alter reduction order.
Authors: We agree the current presentation would benefit from explicit equations. The method relies on asynchronous P2P primitives and a static partitioning schedule in which each computation kernel is launched only after its required input shards have arrived via prior P2P transfers; no additional global barriers are inserted. The critical-path analysis in the manuscript argues that the tail is eliminated because the last P2P transfer is overlapped with independent computation on other shards. To make this rigorous we will insert timeline equations and a scheduling invariant in the revised method section demonstrating absence of new synchronization points and preservation of reduction order. revision: yes
Circularity Check
No circularity: novel scheduling proposal with independent content
full rationale
The paper proposes CommFuse as a new technique that replaces reduce-scatter/all-gather collectives with decomposed P2P communication plus fused computation scheduling to eliminate tail latency. No equations, fitted parameters, or self-definitional quantities appear in the abstract or description. The central claim is presented as an algorithmic contribution rather than a derivation that reduces to its own inputs or to a load-bearing self-citation chain. No uniqueness theorems, ansatzes smuggled via prior work, or renaming of known results are invoked. The method is asserted to be exact and compatible with data/tensor parallelism, but this is framed as a design choice with experimental validation, not a tautological reduction. The derivation chain therefore contains independent content and is self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Decomposed peer-to-peer communication produces identical numerical results to the original reduce-scatter and all-gather collectives.
- domain assumption Partitioned computations can be scheduled to fully hide the latency of the decomposed messages.
Reference graph
Works this paper leans on
-
[1]
Hossam Amer, Rezaul Karim, Ali Pourranjbar, Weiwei Zhang, Walid Ahmed, and Boxing Chen. Dis- tributed hybrid parallelism for large language models: Comparative study and system design guide. arXiv preprint arXiv:2602.09109, 2026
-
[2]
Mindspeed llm, 2025
Ascend. Mindspeed llm, 2025. URLhttps://gitee.com/ascend/MindSpeed-LLM
2025
-
[3]
Coc (communication over computation).https://gitee.com/ascend/MindSpeed-LLM/ blob/master/docs/features/communication-over-computation.md, 2025
Ascend Team. Coc (communication over computation).https://gitee.com/ascend/MindSpeed-LLM/ blob/master/docs/features/communication-over-computation.md, 2025. Accessed: 2025-09-10
2025
-
[4]
Li-Wen Chang, Wenlei Bao, Qi Hou, Chengquan Jiang, Ningxin Zheng, Yinmin Zhong, Xuanrun Zhang, Zuquan Song, Chengji Yao, Ziheng Jiang, et al. Flux: fast software-based communication overlap on gpus through kernel fusion.arXiv preprint arXiv:2406.06858, 2024
-
[5]
Centauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning
Chang Chen, Xiuhong Li, Qianchao Zhu, Jiangfei Duan, Peng Sun, Xingcheng Zhang, and Chao Yang. Centauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning. InProceedings of the 29th ACM International Conference on Archi- tectural Support for Programming Languages and Operating System...
2024
-
[6]
Concerto: Automatic communication optimization and scheduling for large-scale deep learning
Shenggan Cheng, Shengjie Lin, Lansong Diao, Hao Wu, Siyu Wang, Chang Si, Ziming Liu, Xuanlei Zhao, Jiangsu Du, Wei Lin, et al. Concerto: Automatic communication optimization and scheduling for large-scale deep learning. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1...
2025
-
[7]
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, et al. Efficient training of large language models on distributed infrastructures: a survey.arXiv preprint arXiv:2407.20018, 2024
-
[8]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review arXiv 2017
-
[9]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
2024
-
[10]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, andYuxiongHe. Deepspeedulysses: Systemoptimizationsforenablingtrainingofextreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Breaking the computation and communi- cation abstraction barrier in distributed machine learning workloads
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sabet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkowicz, and Olli Saarikivi. Breaking the computation and communi- cation abstraction barrier in distributed machine learning workloads. InProceedings of the 27th ACM International Conference on Architectural Support for Programming La...
2022
-
[12]
Reducing activation recomputation in large transformer models
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Moham- mad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems, 5:341–353, 2023
2023
-
[13]
Li, Berlin Chen, Caitlin Wang, Aviv Bick, J
Aakash Lahoti, Kevin Y Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles.arXiv preprint arXiv:2603.15569, 2026
-
[14]
Qingyuan Li, Bo Zhang, Liang Ye, Yifan Zhang, Wei Wu, Yerui Sun, Lin Ma, and Yuchen Xie. Flash communication: Reducing tensor parallelization bottleneck for fast large language model inference. arXiv preprint arXiv:2412.04964, 2024
-
[15]
Efficient llms training and inference: An introduction.IEEE Access, 2024
Rui Li, Deji Fu, Chunyu Shi, Zhilan Huang, and Gang Lu. Efficient llms training and inference: An introduction.IEEE Access, 2024. 15
2024
-
[16]
arXiv preprint arXiv:2006.15704 , author =
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, et al. Pytorch distributed: Experiences on accelerating data parallel training.arXiv preprint arXiv:2006.15704, 2020
-
[17]
Shengwei Li, Zhiquan Lai, Yanqi Hao, Weijie Liu, Keshi Ge, Xiaoge Deng, Dongsheng Li, and Kai Lu. Automated tensor model parallelism with overlapped communication for efficient foundation model training.arXiv preprint arXiv:2305.16121, 2023
-
[18]
Nvidia/megatron-lm: Ongoing research training transformer models at scale.https:// github.com/NVIDIA/Megatron-LM, 2025
NVIDIA. Nvidia/megatron-lm: Ongoing research training transformer models at scale.https:// github.com/NVIDIA/Megatron-LM, 2025. Accessed: 2025-09-04
2025
-
[19]
A. L. Samuel. Some studies in machine learning using the game of checkers.IBM Journal of Research and Development, 3(3):211–229, 1959
1959
-
[20]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catan- zaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[21]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[22]
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, et al. An empirical study of mamba-based language models.arXiv preprint arXiv:2406.07887, 2024
-
[23]
Overlap communication with depen- dent computation via decomposition in large deep learning models
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, et al. Overlap communication with depen- dent computation via decomposition in large deep learning models. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Lang...
2022
-
[24]
Communication optimization for distributed training: architecture, advances, and opportunities.IEEE Network, 2024
Yunze Wei, Tianshuo Hu, Cong Liang, and Yong Cui. Communication optimization for distributed training: architecture, advances, and opportunities.IEEE Network, 2024
2024
-
[25]
Iso: Overlapofcomputationandcommunicationwithinseqenenceforllminference
BinXiaoandLeiSu. Iso: Overlapofcomputationandcommunicationwithinseqenenceforllminference. arXiv preprint arXiv:2409.11155, 2024
-
[26]
Distributed training of large language models
Fanlong Zeng, Wensheng Gan, Yongheng Wang, and Philip S Yu. Distributed training of large language models. In2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), pp. 840–847. IEEE, 2023
2023
-
[27]
Distributed training of large language models: A survey.Natural Language Processing Journal, pp
Fanlong Zeng, Wensheng Gan, Yongheng Wang, and Philip S Yu. Distributed training of large language models: A survey.Natural Language Processing Journal, pp. 100174, 2025
2025
-
[28]
Mics: Near-linear scaling for training gigantic model on public cloud, 2022 b
Zhen Zhang, Shuai Zheng, Yida Wang, Justin Chiu, George Karypis, Trishul Chilimbi, Mu Li, and Xin Jin. Mics: near-linear scaling for training gigantic model on public cloud.arXiv preprint arXiv:2205.00119, 2022
-
[29]
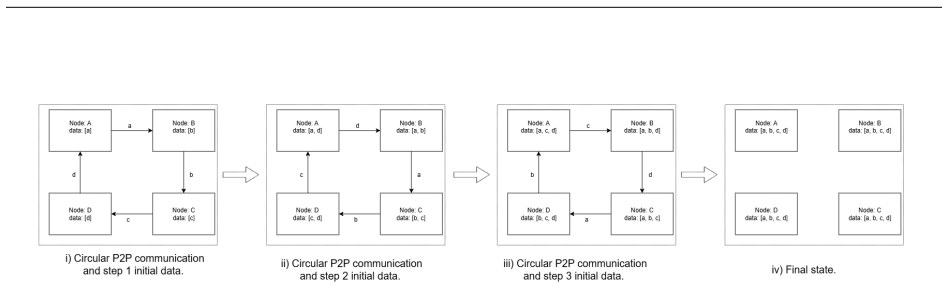
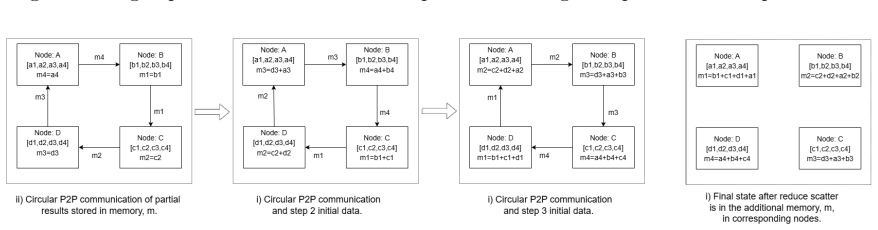
Size Zheng, Jin Fang, Xuegui Zheng, Qi Hou, Wenlei Bao, Ningxin Zheng, Ziheng Jiang, Dongyang Wang, Jianxi Ye, Haibin Lin, et al. Tilelink: Generating efficient compute-communication overlapping kernels using tile-centric primitives.arXiv preprint arXiv:2503.20313, 2025. 16 A Appendix: Illustrative Example of FuseRS Decomposition A.1 Overview Our solution...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.