Recognition: unknown
Latency and Cost of Multi-Agent Intelligent Tutoring at Scale
Pith reviewed 2026-05-08 01:28 UTC · model grok-4.3
The pith
Priority PayGo keeps multi-agent LLM tutoring responses flat under 4 seconds up to 50 concurrent users while costing less than a textbook per student per semester.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
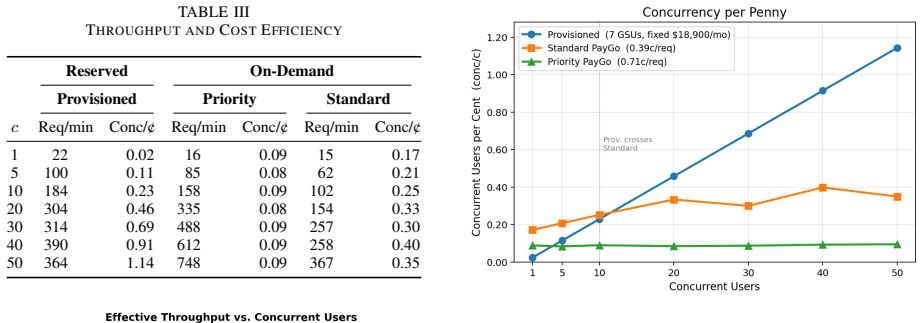
Multi-agent LLM tutoring systems improve response quality through agent specialization, but each student query triggers several concurrent API calls whose latencies compound through a parallel-phase maximum effect that single-agent systems do not face. Instrumenting ITAS across Standard PayGo, Priority PayGo, and Provisioned Throughput at eleven concurrency levels up to 50 users shows Priority PayGo maintains flat sub-4-second response times across the full load range, Standard PayGo degrades substantially under classroom-scale concurrency, Provisioned Throughput delivers the lowest latency at low concurrency but saturates its reserved capacity above approximately 20 concurrent users, and a
What carries the argument
The four-agent ITAS tutoring system on Gemini 2.5 Flash and Google Vertex AI, instrumented across Standard PayGo, Priority PayGo, and Provisioned Throughput tiers at eleven concurrency levels.
If this is right
- Priority PayGo can be used for reliable classroom-scale deployments without advance capacity reservation.
- Provisioned Throughput is cost-competitive only when institutions can predict and concentrate traffic to high utilization.
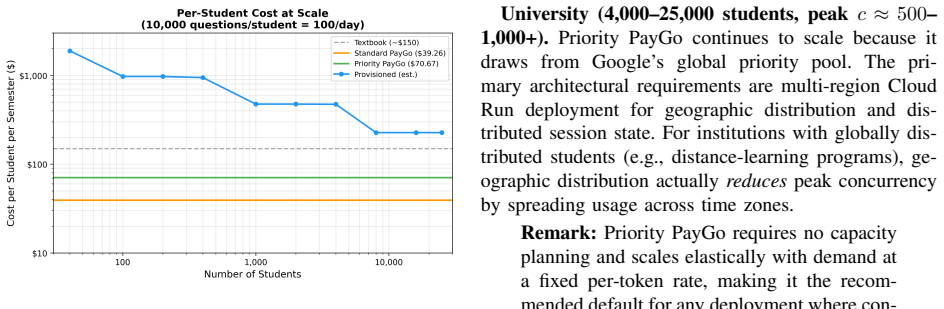
- Pay-per-token tiers keep per-student semester costs low enough to support university-wide rollout.
- Latency in multi-agent systems is determined by the slowest parallel call, so tier selection must account for compounding effects.
Where Pith is reading between the lines
- Other multi-agent LLM applications that issue parallel calls may exhibit similar tier-dependent latency ceilings.
- Institutions could test hybrid tier switching that routes low-load queries to Provisioned Throughput and high-load to Priority PayGo.
- Repeating the measurements with additional LLM providers would show whether the observed saturation points are provider-specific.
Load-bearing premise
The eleven tested concurrency levels, four-agent queries, and one graduate STEM deployment produce latency and cost patterns that will hold for other subjects, student populations, and institutions.
What would settle it
Re-running the same experiment with queries drawn from non-STEM courses or with more than 50 concurrent users and finding that Standard PayGo remains under 4 seconds or that Priority PayGo latency rises would falsify the tier-specific performance claims.
Figures



read the original abstract
Multi-agent LLM tutoring systems improve response quality through agent specialization, but each student query triggers several concurrent API calls whose latencies compound through a parallel-phase maximum effect that single-agent systems do not face. We instrument ITAS, a four-agent tutoring system built on Gemini 2.5 Flash and Google Vertex AI, across three throughput tiers (Standard PayGo, Priority PayGo, and Provisioned Throughput) and eleven concurrency levels up to 50 simultaneous users, producing over 3,000 requests drawn from a live graduate STEM deployment. Priority PayGo maintains flat sub-4-second response times across the full load range; Standard PayGo degrades substantially under classroom-scale concurrency; and Provisioned Throughput delivers the lowest latency at low concurrency but saturates its reserved capacity above approximately 20 concurrent users. Cost analysis places both pay-per-token tiers well below the price of a STEM textbook per student per semester under a worst-case usage ceiling. Provisioned Throughput, expensive under continuous provisioning, becomes cost-competitive for institutions that can predict and concentrate their traffic toward high utilization. These results provide concrete tier-selection guidance across deployment scales from a single seminar to a university-wide rollout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical instrumentation study of a four-agent LLM tutoring system (ITAS) built on Gemini 2.5 Flash and Google Vertex AI. It measures end-to-end latency and cost across three throughput tiers (Standard PayGo, Priority PayGo, Provisioned Throughput) at eleven concurrency levels up to 50 simultaneous users, using over 3,000 requests drawn from a live graduate STEM deployment. The central claims are that Priority PayGo sustains flat sub-4 s responses across the load range, Standard PayGo degrades at classroom-scale concurrency, Provisioned Throughput offers the lowest latency at low loads but saturates above ~20 users, and pay-per-token costs remain well below a STEM textbook price per student per semester under worst-case usage.
Significance. If the measurements are reproducible and the observed scaling behaviors generalize, the work supplies concrete, deployment-relevant data on the parallel-phase latency penalty unique to multi-agent systems and on the practical trade-offs among Vertex AI pricing tiers. This is a useful contribution to the literature on scalable educational AI, as it directly instruments real usage patterns rather than relying on synthetic benchmarks.
major comments (2)
- [Methods] Methods section: The manuscript reports results from >3,000 requests across defined tiers and loads but provides no description of query sampling, the exact distribution of the eleven concurrency levels, how the four-agent parallel phase was orchestrated, or any statistical summary (standard deviation, percentiles, or confidence intervals) on the latency distributions. Without these, the claims of “flat sub-4-second response times” and “substantial degradation” cannot be independently verified or assessed for robustness.
- [Discussion] Discussion / Conclusions: The paper offers “concrete tier-selection guidance across deployment scales from a single seminar to a university-wide rollout,” yet all data come from one graduate STEM deployment, one four-agent configuration, and a single model (Gemini 2.5 Flash). No sensitivity experiments or discussion of how latency and cost scaling would change under different query distributions, agent specializations, or providers are included; this assumption is load-bearing for the guidance claim.
minor comments (2)
- [Abstract] Abstract: The eleven concurrency levels and the precise worst-case usage ceiling used for the cost comparison are not enumerated; adding these numbers would improve clarity.
- [Results] Results: Figures or tables summarizing latency and cost should include error bars or inter-quartile ranges to convey variability across the 3,000 requests.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We have carefully considered the points raised and revised the manuscript to improve clarity and address concerns about reproducibility and generalizability. Our responses to the major comments are provided below.
read point-by-point responses
-
Referee: Methods section: The manuscript reports results from >3,000 requests across defined tiers and loads but provides no description of query sampling, the exact distribution of the eleven concurrency levels, how the four-agent parallel phase was orchestrated, or any statistical summary (standard deviation, percentiles, or confidence intervals) on the latency distributions. Without these, the claims of “flat sub-4-second response times” and “substantial degradation” cannot be independently verified or assessed for robustness.
Authors: We agree that these details are essential for independent verification. In the revised version, we have substantially expanded the Methods section. We now describe the query sampling procedure, which involved randomly selecting representative queries from anonymized logs of the live graduate STEM deployment while preserving the distribution of query types and lengths. The eleven concurrency levels were tested at 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, and 50 simultaneous users, with each level run for sufficient duration to collect at least 200 requests per tier. For the four-agent orchestration, we detail that the system issues parallel API calls to the four specialized agents and computes the end-to-end latency as the maximum of the individual agent response times plus any aggregation overhead. Additionally, we now report statistical summaries for all latency measurements, including means, standard deviations, 5th/95th percentiles, and 95% confidence intervals, presented in both tables and figures. These revisions directly support the robustness of our claims regarding flat sub-4s responses under Priority PayGo and degradation in Standard PayGo. revision: yes
-
Referee: Discussion / Conclusions: The paper offers “concrete tier-selection guidance across deployment scales from a single seminar to a university-wide rollout,” yet all data come from one graduate STEM deployment, one four-agent configuration, and a single model (Gemini 2.5 Flash). No sensitivity experiments or discussion of how latency and cost scaling would change under different query distributions, agent specializations, or providers are included; this assumption is load-bearing for the guidance claim.
Authors: We recognize that the generalizability of our tier-selection guidance is limited by the specific experimental setup. In the revised Discussion and Conclusions, we have added an explicit Limitations and Future Work subsection. This section acknowledges that our data derives from a single graduate STEM context using a four-agent configuration with Gemini 2.5 Flash on Vertex AI. We discuss how variations in query distributions (e.g., longer or more complex queries) could affect token costs and latencies, how different agent specializations might alter the parallel-phase dynamics, and potential differences with other providers or models. While we did not conduct new sensitivity experiments due to the reliance on live deployment data, we emphasize that the observed parallel-phase latency penalty is a fundamental characteristic of multi-agent systems and likely generalizes. The guidance is presented with appropriate caveats, recommending it primarily for similar educational deployments, and we outline directions for future studies to broaden the applicability. revision: partial
Circularity Check
No circularity: direct empirical measurements from observed latencies and costs
full rationale
The paper is an instrumentation study that reports measured response times and billing data from 3,000+ requests across three throughput tiers and eleven concurrency levels in a single four-agent Gemini-based deployment. No equations, fitted models, ansatzes, uniqueness theorems, or derivations are present in the abstract or described methodology. All headline results (flat sub-4 s latency under Priority PayGo, degradation under Standard PayGo, saturation under Provisioned Throughput, and sub-textbook costs) are stated as direct observations rather than outputs of any chain that reduces to the inputs by construction. The study is therefore self-contained with no load-bearing self-citations or definitional loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Toward personalizing quan- tum computing education: An evolutionary LLM-powered ap- proach,
I. Elhaimeur and N. Chrisochoides, “Toward personalizing quan- tum computing education: An evolutionary LLM-powered ap- proach,” inProceedings of the IEEE International Conference on Quantum Computing and Engineering (QCE), 2025
2025
-
[2]
Vertex AI — generative AI,
Google Cloud, “Vertex AI — generative AI,” https://cloud. google.com/vertex-ai/generative-ai/docs, 2026
2026
-
[3]
Priority PayGo,
——, “Priority PayGo,” https://docs.cloud.google.com/vertex-ai/ generative-ai/docs/priority-paygo, 2026
2026
-
[4]
Provisioned throughput,
——, “Provisioned throughput,” https://docs.cloud.google.com/ vertex-ai/generative-ai/docs/provisioned-throughput, 2026
2026
-
[5]
ORCA: A distributed serving system for transformer-based gen- erative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “ORCA: A distributed serving system for transformer-based gen- erative models,” inProc. 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’22). Carlsbad, CA: USENIX Association, 2022, pp. 521–538
2022
-
[6]
Efficient memory manage- ment for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory manage- ment for large language model serving with PagedAttention,” in Proc. 29th ACM Symposium on Operating Systems Principles (SOSP ’23). ACM, 2023, pp. 611–626
2023
-
[7]
Fast inference from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transformers via speculative decoding,” inProc. 40th Interna- tional Conference on Machine Learning (ICML ’23), ser. PMLR, vol. 202, 2023, pp. 19 274–19 286
2023
-
[8]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decod- ing with speculative sampling,” DeepMind, Tech. Rep., 2023, arXiv:2302.01318
work page internal anchor Pith review arXiv 2023
-
[9]
Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, A. Tumanov, and R. Ramjee, “Taming throughput- latency tradeoff in LLM inference with Sarathi-Serve,” inProc. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 2024, pp. 117–134
2024
-
[10]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,” inProc. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’24). USENIX Association, 2024, pp. 193–210
2024
-
[11]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “FrugalGPT: How to use large language models while reducing cost and improving per- formance,”Transactions on Machine Learning Research, 2024, arXiv:2305.05176
work page internal anchor Pith review arXiv 2024
-
[12]
L. Chen, J. Q. Davis, B. Hanin, P. Bailis, I. Stoica, M. Za- haria, and J. Zou, “Are more LLM calls all you need? towards scaling laws of compound inference systems,” inAdvances in Neural Information Processing Systems (NeurIPS ’24), 2024, arXiv:2403.02419
-
[13]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,”International Conference on Learning Representations (ICLR), 2023, notable Top 5%; arXiv:2210.03629
work page internal anchor Pith review arXiv 2023
-
[14]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y . Wu, S. Zhang, E. Zhu, B. Li, L. Jiang, X. Zhang, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi-agent conversation,”arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta pro- gramming for a multi-agent collaborative framework,” inInter- national Conference on Learning Representations (ICLR ’24), 2024, arXiv:2308.00352
work page internal anchor Pith review arXiv 2024
-
[16]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate,” inProc. 41st International Conference on Machine Learning (ICML ’24), 2024, arXiv:2305.14325
work page internal anchor Pith review arXiv 2024
-
[17]
Large language model based multi- agents: A survey of progress and challenges,
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang, “Large language model based multi- agents: A survey of progress and challenges,” inProc. 33rd International Joint Conference on Artificial Intelligence (IJCAI ’24), 2024, pp. 8048–8057
2024
-
[18]
The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring,
B. S. Bloom, “The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring,”Educa- tional Researcher, vol. 13, no. 6, pp. 4–16, 1984
1984
-
[19]
The relative effectiveness of human tutoring, intel- ligent tutoring systems, and other tutoring systems,
K. VanLehn, “The relative effectiveness of human tutoring, intel- ligent tutoring systems, and other tutoring systems,”Educational Psychologist, vol. 46, no. 4, pp. 197–221, 2011
2011
-
[20]
Cognitive tutors: Lessons learned,
J. R. Anderson, A. T. Corbett, K. R. Koedinger, and R. Pelletier, “Cognitive tutors: Lessons learned,”The Journal of the Learning Sciences, vol. 4, no. 2, pp. 167–207, 1995
1995
-
[21]
The AI teacher test: Measuring the peda- gogical ability of blender and GPT-3 in educational dialogues,
A. Tack and C. Piech, “The AI teacher test: Measuring the peda- gogical ability of blender and GPT-3 in educational dialogues,” in Proc. 15th International Conference on Educational Data Mining (EDM ’22), 2022, pp. 522–529
2022
-
[22]
The BEA 2023 shared task on generating AI teacher responses in educational dialogues,
A. Tack, E. Kochmar, Z. Yuan, S. Bibauw, and C. Piech, “The BEA 2023 shared task on generating AI teacher responses in educational dialogues,” inProc. 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA @ ACL ’23), 2023, pp. 785–795
2023
-
[23]
GPT-4 as a homework tutor can improve student engagement and learning outcomes,
A. Vanzo, S. Pal Chowdhury, and M. Sachan, “GPT-4 as a homework tutor can improve student engagement and learning outcomes,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers). Association for Computational Linguistics, 2025, pp. 31 119–31 136
2025
-
[24]
I. Jurenka, M. Kunesch, K. R. McKee, D. Gillick, S. Zhu, S. Wiltbergeret al., “Towards responsible development of gener- ative AI for education: An evaluation-driven approach,” Google DeepMind, Tech. Rep., 2024, arXiv:2407.12687
-
[25]
Chat- GPT for good? On opportunities and challenges of large language models for education,
E. Kasneci, K. Seßler, S. K ¨uchemann, M. Bannert, D. Demen- tieva, F. Fischer, U. Gasser, G. Groh, S. G¨unnemannet al., “Chat- GPT for good? On opportunities and challenges of large language models for education,”Learning and Individual Differences, vol. 103, p. 102274, 2023
2023
-
[26]
Practical and ethical challenges of large language models in education: A systematic scoping review,
L. Yan, L. Sha, L. Zhao, Y . Li, R. Martinez-Maldonado, G. Chen, X. Li, Y . Jin, and D. Ga ˇsevi´c, “Practical and ethical challenges of large language models in education: A systematic scoping review,”British Journal of Educational Technology, vol. 55, no. 1, pp. 90–112, 2024
2024
-
[27]
Agent development kit (ADK),
Google, “Agent development kit (ADK),” https://google.github. io/adk-docs, 2026
2026
-
[28]
Standard PayGo,
Google Cloud, “Standard PayGo,” https://docs.cloud.google.com/ vertex-ai/generative-ai/docs/standard-paygo, 2026
2026
-
[29]
From prototype to class- room: An intelligent tutoring system for quantum education,
I. Elhaimeur and N. Chrisochoides, “From prototype to class- room: An intelligent tutoring system for quantum education,” 2026
2026
-
[30]
MonarchSphere: AI incubator powered by Google Cloud,
Old Dominion University, “MonarchSphere: AI incubator powered by Google Cloud,” https://www.odu.edu/ forward-focused-transformation/monarchsphere, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.