Recognition: unknown
Seeing Is No Longer Believing: Frontier Image Generation Models, Synthetic Visual Evidence, and Real-World Risk
Pith reviewed 2026-05-08 03:49 UTC · model grok-4.3
The pith
Frontier image generation models produce synthetic visual evidence that erodes trust in pictures as reliable records, with risks driven by the convergence of realism, legible text, identity persistence, fast iteration, and distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
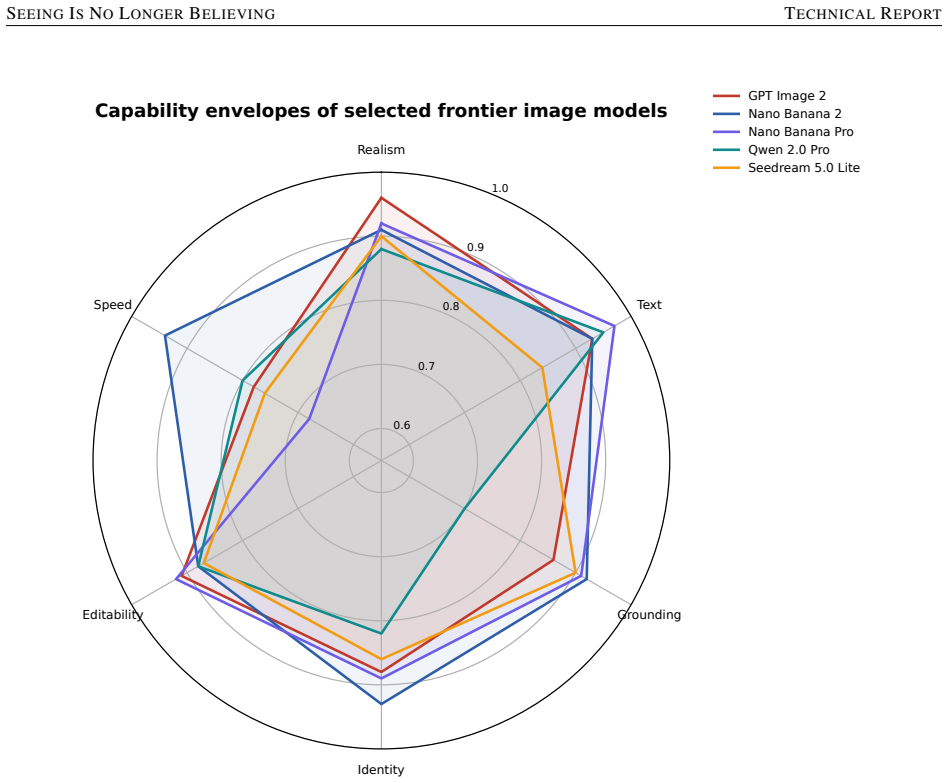
Frontier image generation has moved from artistic synthesis toward synthetic visual evidence. Systems combine photorealistic rendering, readable typography, reference consistency, editing control, and in several cases reasoning or search-grounded image construction. These capabilities create large benefits yet weaken the belief that a plausible picture is a reliable record. Analysis of public incidents shows that risk is driven less by photorealism alone than by the convergence of realism, legible text, identity persistence, fast iteration, and distribution context. A capability-weighted risk framework links model affordances to real-world harm in finance, medicine, news, law, emergency, and
What carries the argument
capability-weighted risk framework that links specific model affordances such as photorealistic rendering and reference consistency to potential harms across sectors
If this is right
- Risks in finance and emergency response increase when fast iteration allows rapid creation and sharing of synthetic screenshots or crisis images.
- Medical and legal sectors face new verification burdens from persistent identities and legible text in forged scans and documents.
- News and civic discourse suffer when distribution context amplifies synthetic celebrity or public-figure imagery.
- Layered controls such as cryptographic provenance and platform friction can reduce harms if applied by providers and institutions.
- Ordinary users gain from visible labeling that distinguishes synthetic images from records.
Where Pith is reading between the lines
- If convergence of capabilities drives risk, then improvements in text rendering alone could sharply raise document forgery threats without further gains in overall realism.
- Platform design choices around content amplification may turn out to be as influential on harm as the image models themselves.
- Extending the same risk mapping to video or audio synthesis could show parallel patterns once those tools reach comparable iteration speeds.
- Education campaigns teaching basic provenance checks could serve as a low-cost complement to technical controls.
Load-bearing premise
The summarized public incidents and model capabilities are representative enough to ground a general risk framework, and the proposed layered controls can be implemented at scale without major unintended restrictions on beneficial uses.
What would settle it
A systematic collection of post-release incidents in finance, medicine, and news that shows no measurable rise in harms traceable to the convergence of realism, text legibility, identity persistence, iteration speed, and distribution context.
Figures













read the original abstract
Frontier image generation has moved from artistic synthesis toward synthetic visual evidence. Systems such as GPT Image 2, Nano Banana Pro, Nano Banana 2, Grok Imagine, Qwen Image 2.0 Pro, and Seedream 5.0 Lite combine photorealistic rendering, readable typography, reference consistency, editing control, and in several cases reasoning or search-grounded image construction. These capabilities create large benefits for design, education, accessibility, and communication, yet they also weaken one of society's most common trust shortcuts: the belief that a plausible picture is a reliable record. This paper provides a source-grounded technical and policy analysis of synthetic visual risk. We first summarize the public capabilities of recent image models, then analyze public incidents involving fake crisis images, celebrity and public-figure imagery, medical scans, forged-looking documents, synthetic screenshots, phishing assets, and market-moving rumors. We introduce a capability-weighted risk framework that links model affordances to real-world harm in finance, medicine, news, law, emergency response, identity verification, and civic discourse. Our findings show that risk is driven less by photorealism alone than by the convergence of realism, legible text, identity persistence, fast iteration, and distribution context. We argue for layered control: model-side restrictions, cryptographic provenance, visible labeling, platform friction, sector-grade verification, and incident response. The paper closes with practical recommendations for model providers, platforms, newsrooms, financial institutions, healthcare systems, legal organizations, regulators, and ordinary users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frontier image generation models (e.g., GPT Image 2, Grok Imagine) now produce photorealistic outputs with legible text, identity persistence, editing control, and sometimes reasoning/search integration, eroding trust in visual evidence. It summarizes public model capabilities, reviews incidents involving fake crisis images, celebrity fakes, medical scans, forged documents, phishing, and market rumors across finance/medicine/news/law/emergency/identity/civic domains, introduces a capability-weighted risk framework, concludes that harm stems primarily from convergence of realism + legible text + identity persistence + fast iteration + distribution context (rather than photorealism alone), and recommends layered controls (model restrictions, cryptographic provenance, visible labeling, platform friction, sector verification, incident response) plus stakeholder-specific advice.
Significance. If the qualitative synthesis holds, the work is significant for reframing synthetic-image risk assessment around multi-factor convergence rather than isolated photorealism, providing a structured policy lens for high-stakes domains. Strengths include its source-grounded review of public incidents and model descriptions plus concrete layered-control recommendations; these could usefully inform model providers, platforms, and regulators. The absence of quantitative validation or controlled comparisons, however, caps its immediate empirical weight.
major comments (1)
- [Incident analysis and findings on risk drivers] The central finding that risk is driven less by photorealism alone than by convergence of realism, legible text, identity persistence, fast iteration, and distribution context rests on summarized public incidents (abstract and incident-analysis sections). No explicit methodology for incident selection, no total count of incidents reviewed, and no comparative cases isolating photorealism without the other factors are provided. Without these, the inference that convergence is the primary driver does not follow rigorously from the evidence and weakens the framework's generalizability.
minor comments (1)
- [Abstract and model-capability summary] Model names such as 'Nano Banana Pro' and 'Nano Banana 2' in the abstract and capability summary should be accompanied by explicit public sources or citations to avoid appearing non-standard or unverifiable.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We appreciate the acknowledgment of the paper's strengths in its source-grounded incident review and layered-control recommendations. The major comment on methodological transparency for the incident analysis is well-taken, and we outline targeted revisions below to strengthen the rigor of our central finding without altering its scope as a qualitative synthesis.
read point-by-point responses
-
Referee: The central finding that risk is driven less by photorealism alone than by convergence of realism, legible text, identity persistence, fast iteration, and distribution context rests on summarized public incidents (abstract and incident-analysis sections). No explicit methodology for incident selection, no total count of incidents reviewed, and no comparative cases isolating photorealism without the other factors are provided. Without these, the inference that convergence is the primary driver does not follow rigorously from the evidence and weakens the framework's generalizability.
Authors: We agree that adding explicit methodological detail will improve transparency and support the inference more rigorously. The manuscript is a qualitative policy-oriented synthesis drawing on publicly reported incidents to illustrate patterns of harm; it does not claim experimental isolation of variables. In revision, we will add a dedicated 'Incident Selection and Analysis Methodology' subsection that: (1) describes sources (news reports from major outlets, official statements from platforms and authorities, and documented cases from 2023-2024); (2) states the total incidents reviewed (approximately 50 public cases, with 25-30 highlighted for domain coverage); and (3) specifies inclusion criteria centered on cases demonstrating combined capabilities (realism + text + identity + context). We will also clarify that the framework is inductive and observational, derived from co-occurrence in reported harms rather than controlled comparisons, and add a limitations note on generalizability. These changes address the concern directly while maintaining the paper's focus on real-world convergence rather than photorealism in isolation. revision: yes
Circularity Check
No circularity: external-incident summary supports independent risk framework
full rationale
The paper is a qualitative analysis summarizing publicly reported incidents and frontier model capabilities drawn from external sources. It introduces a capability-weighted risk framework linking affordances to harms in listed sectors without equations, fitted parameters, self-definitions, or load-bearing self-citations. The central claim on convergence of realism, text, persistence, iteration, and context follows from the described incidents rather than reducing to its own inputs by construction. No derivation chain exists that collapses to renaming, ansatz smuggling, or uniqueness imported from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
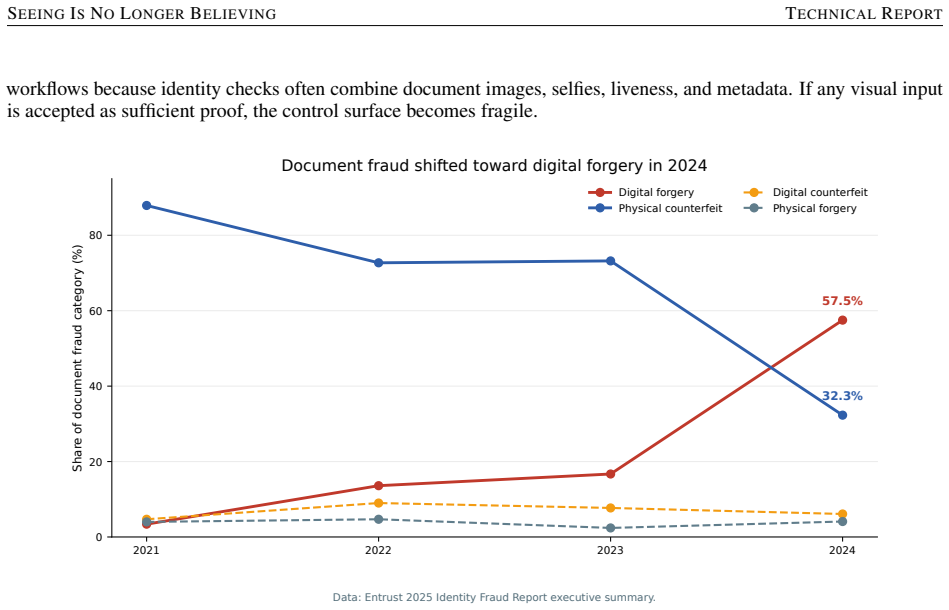
https://www.entrust.com/sites/default/fi les/documentation/executive-summaries/2025-fraud-identity-exec-summary.pdf
2025 Identity Fraud Report Executive Summary. https://www.entrust.com/sites/default/fi les/documentation/executive-summaries/2025-fraud-identity-exec-summary.pdf. European Broadcasting Union
2025
-
[2]
Denoising Diffusion Probabilistic Models
Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems.https://arxiv.org/abs/2006.11239. House of Commons Library
work page internal anchor Pith review arXiv 2006
-
[3]
https: //www.icaew.com/insights/viewpoints-on-the-news/2026/mar-2026/how-to-spot-a-fake-ai-g enerated-invoice
How to spot a fake AI-generated invoice. https: //www.icaew.com/insights/viewpoints-on-the-news/2026/mar-2026/how-to-spot-a-fake-ai-g enerated-invoice. Sophie J. Nightingale and Hany Farid
2026
-
[4]
Ai-synthesized faces are indistinguish- able from real faces and more trustworthy,
AI-synthesized faces are indistinguishable from real faces and more trustworthy.Proceedings of the National Academy of Sciences, 119(8):e2120481119. https://www.pnas.org/d oi/10.1073/pnas.2120481119. OpenAI. 2026a. Introducing ChatGPT Images 2.0. https://openai.com/index/introducing-chatgpt-image s-2-0/. OpenAI. 2026b. GPT Image 2 Model.https://developers...
-
[5]
https://partnershiponai.org/wp-c ontent/uploads/2024/03/pai-synthetic-media-case-study-adobe.pdf
Synthetic Media Framework Case Study: Adobe. https://partnershiponai.org/wp-c ontent/uploads/2024/03/pai-synthetic-media-case-study-adobe.pdf. William Peebles and Saining Xie
2024
-
[6]
Scalable Diffusion Models with Transformers
Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision.https://arxiv.org/abs/2212.09748. Reuters Fact Check
work page internal anchor Pith review arXiv
-
[7]
https: //www.reuters.com/article/fact-check/online-posts-reporting-explosion-near-pentagon-o n-may-22-2023-are-false-idUSL1N37J2QJ/
Online posts reporting explosion near Pentagon on May 22, 2023 are false. https: //www.reuters.com/article/fact-check/online-posts-reporting-explosion-near-pentagon-o n-may-22-2023-are-false-idUSL1N37J2QJ/. Reuters Fact Check
2023
-
[8]
https://www.re uters.com/fact-check/images-aircraft-landings-into-flaming-beirut-airport-are-ai-gener ated-2024-10-29/
Images of aircraft landings into flaming Beirut airport are AI-generated. https://www.re uters.com/fact-check/images-aircraft-landings-into-flaming-beirut-airport-are-ai-gener ated-2024-10-29/. 19 SEEINGISNOLONGERBELIEVINGTECHNICALREPORT Reuters Investigates
2024
-
[9]
AI bots were happy to help
We wanted to craft a perfect phishing scam. AI bots were happy to help. https://www.re uters.com/investigates/special-report/ai-chatbots-cyber/. Reuters Fact Check. 2026a. AI creates fake image of Zohran Mamdani with mother and Epstein.https://www.reuter s.com/fact-check/ai-creates-fake-image-zohran-mamdani-with-mother-epstein-2026-02-05/. Reuters Fact Ch...
2026
-
[10]
High-Resolution Image Synthesis with Latent Diffusion Models
High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.https://arxiv.org/abs/2112.10752. Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, and others
work page internal anchor Pith review arXiv
-
[11]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Photorealistic text-to-image diffusion models with deep language understanding.https://arxiv.org/abs/2205.11487. Technology’s Legal Edge
work page internal anchor Pith review arXiv
-
[12]
https://www.technologyslegaledge.com/2025/03/china-released-new-measures-for-labelling -ai-generated-and-synthetic-content/
China released new measures for labelling AI-generated and synthetic content. https://www.technologyslegaledge.com/2025/03/china-released-new-measures-for-labelling -ai-generated-and-synthetic-content/. xAI. 2026a. Image Generation.https://docs.x.ai/developers/model-capabilities/images/generation. xAI. 2026b. Imagine API: Generate Videos, Images, and Audi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.