Recognition: unknown
See Further, Think Deeper: Advancing VLM's Reasoning Ability with Low-level Visual Cues and Reflection
Pith reviewed 2026-05-08 04:45 UTC · model grok-4.3
The pith
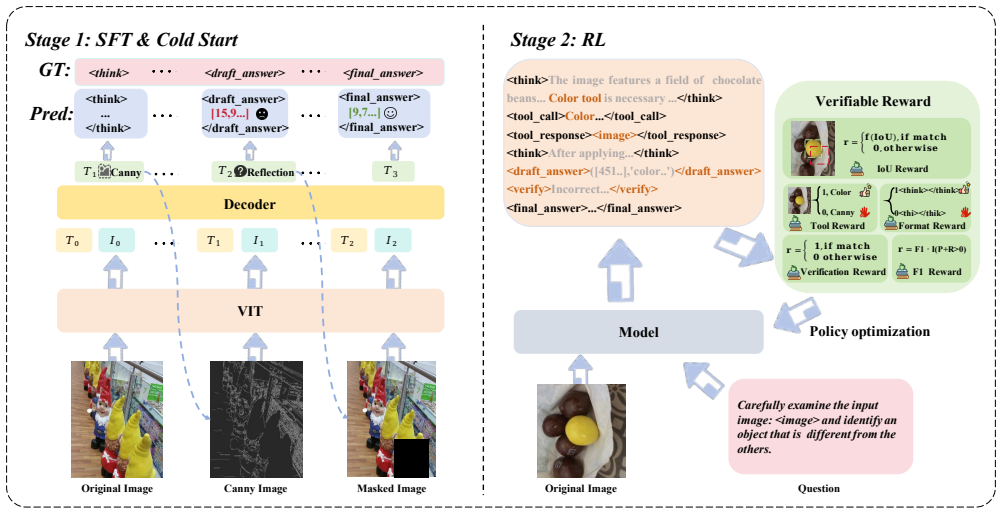
ForeSight lets VLMs use low-level visual cues and mask-based visual feedback within an RL loop to reason more accurately, with the 7B model beating same-scale peers and some closed-source SOTA on a new benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experimental results demonstrate that the ForeSight-7B model significantly outperforms other models with the same parameter scale, and even surpasses the current SOTA closed-source models on certain metrics.
Load-bearing premise
The new CG-SalBench dataset, constructed from SalBench, provides an unbiased and comprehensive test of the claimed reasoning improvements without construction artifacts that favor the proposed method.
Figures










read the original abstract
Recent advances in Vision-Language Models (VLMs) have benefited from Reinforcement Learning (RL) for enhanced reasoning. However, existing methods still face critical limitations, including the lack of low-level visual information and effective visual feedback. To address these problems, this paper proposes a unified multimodal interleaved reasoning framework \textbf{ForeSight}, which enables VLMs to \textbf{See Further} with low-level visual cues and \textbf{Think Deeper} with effective visual feedback. First, it introduces a set of low-level visual tools to integrate essential visual information into the reasoning chain, mitigating the neglect of fine-grained visual features. Second, a mask-based visual feedback mechanism is elaborated to incorporate visual reflection into the thinking process, enabling the model to dynamically re-examine and update its answers. Driven by RL, ForeSight learns to autonomously decide on tool invocation and answer verification, with the final answer accuracy as the reward signal. To evaluate the performance of the proposed framework, we construct a new dataset, Character and Grounding SalBench (CG-SalBench), based on the SalBench dataset. Experimental results demonstrate that the ForeSight-7B model significantly outperforms other models with the same parameter scale, and even surpasses the current SOTA closed-source models on certain metrics.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Low-level visual information can be effectively integrated into VLM reasoning chains via dedicated tools
- domain assumption Mask-based visual feedback enables dynamic re-examination and answer updating in the reasoning process
invented entities (1)
-
ForeSight framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introducing claude 4.https : / / www
Anthropic. Introducing claude 4.https : / / www . anthropic.com/news/claude-4, 2025. Accessed: 2025-07-27. 6, 7
2025
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[3]
Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 2
2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 6, 7
work page internal anchor Pith review arXiv 2025
-
[5]
Seed-1.6.https://seed.bytedance
ByteDance. Seed-1.6.https://seed.bytedance. com/zh/seed1_6, 2024. Accessed: 2025-07-27. 6, 7
2024
-
[6]
Coco- stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco- stuff: Thing and stuff classes in context. InCVPR, pages 1209–1218, 2018. 8
2018
-
[7]
A survey of computer vision detection, visual slam algorithms, and their applications in energy-efficient autonomous systems.Ener- gies, 17(20):5177, 2024
Lu Chen, Gun Li, Weisi Xie, Jie Tan, Yang Li, Junfeng Pu, Lizhu Chen, Decheng Gan, and Weimin Shi. A survey of computer vision detection, visual slam algorithms, and their applications in energy-efficient autonomous systems.Ener- gies, 17(20):5177, 2024. 7
2024
-
[8]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InICCV, pages 24185–24198, 2024. 2
2024
-
[9]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023. 1
2023
-
[10]
A re- view of the f-measure: its history, properties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24, 2023
Peter Christen, David J Hand, and Nishadi Kirielle. A re- view of the f-measure: its history, properties, criticism, and alternatives.ACM Computing Surveys, 56(3):1–24, 2023. 7
2023
-
[11]
Deep rein- forcement learning for mention-ranking coreference models
Kevin Clark and Christopher D Manning. Deep rein- forcement learning for mention-ranking coreference models. arXiv preprint arXiv:1609.08667, 2016. 6
-
[12]
Instructblip: Towards general-purpose vision- language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision- language models with instruction tuning. InNeurIPS, pages 49250–49267, 2023. 2
2023
-
[13]
Mathsensei: A tool-augmented large lan- guage model for mathematical reasoning
Debrup Das, Debopriyo Banerjee, Somak Aditya, and Ashish Kulkarni. Mathsensei: A tool-augmented large lan- guage model for mathematical reasoning. InNAACL-HLT,
-
[14]
Virgo: A preliminary exploration on reproducing o1-like mllm
Yifan Du, Zikang Liu, Yifan Li, Wayne Xin Zhao, Yuqi Huo, Bingning Wang, Weipeng Chen, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. Virgo: A preliminary ex- ploration on reproducing o1-like mllm.arXiv preprint arXiv:2501.01904, 2025. 3
-
[15]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yu- jia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[16]
Mme: A comprehensive evaluation bench- mark for multimodal large language models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation bench- mark for multimodal large language models. InNIPS, 2025. 8
2025
-
[17]
Interleaved-modal chain-of-thought
Jun Gao, Yongqi Li, Ziqiang Cao, and Wenjie Li. Interleaved-modal chain-of-thought. InCVPR, pages 19520– 19529, 2025. 1
2025
-
[18]
Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% perfor- mance.Visual Intelligence, 2(1):32, 2024
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% perfor- mance.Visual Intelligence, 2(1):32, 2024. 2
2024
-
[19]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[20]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[21]
Llava-uhd: an lmm perceiving any aspect ratio and high- resolution images
Zonghao Guo, Ruyi Xu, Yuan Yao, Junbo Cui, Zanlin Ni, Chunjiang Ge, Tat-Seng Chua, Zhiyuan Liu, and Gao Huang. Llava-uhd: an lmm perceiving any aspect ratio and high- resolution images. InECCV, pages 390–406. Springer, 2024. 2
2024
-
[22]
Breaking the reasoning barrier a sur- vey on LLM complex reasoning through the lens of self- evolution
Tao He, Hao Li, Jingchang Chen, Runxuan Liu, Yixin Cao, Lizi Liao, Zihao Zheng, Zheng Chu, Jiafeng Liang, Ming Liu, and Bing Qin. Breaking the reasoning barrier a sur- vey on LLM complex reasoning through the lens of self- evolution. InACL, pages 7377–7417, Vienna, Austria, 2025. Association for Computational Linguistics. 1
2025
-
[23]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review arXiv
-
[24]
Vision-language models can’t see the obvious
Ngoc Dung Huynh, Phuc H Le-Khac, Wamiq Reyaz Para, Ankit Singh, and Sanath Narayan. Vision-language models can’t see the obvious. InICCV, pages 24159–24169, 2025. 2, 3
2025
-
[25]
Vlm-r 3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought
Chaoya Jiang, Yongrui Heng, Wei Ye, Han Yang, Haiyang Xu, Ming Yan, Ji Zhang, Fei Huang, and Shikun Zhang. VLM-R3: Region recognition, reasoning, and refinement for enhanced multimodal chain-of-thought.arXiv preprint arXiv:2505.16192, 2025. 3
-
[26]
Referitgame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in pho- tographs of natural scenes. InEMNLP, pages 787–798, 2014. 8
2014
-
[27]
Iuliia Kotseruba, Calden Wloka, Amir Rasouli, and John K Tsotsos. Do saliency models detect odd-one-out tar- 9 gets? new datasets and evaluations.arXiv preprint arXiv:2005.06583, 2020. 3
-
[28]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, pages 19730–19742. PMLR, 2023. 2
2023
-
[29]
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Towards faithful chain-of-thought: Large lan- guage models are bridging reasoners.arXiv preprint arXiv:2405.18915, 2024. 3
-
[30]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual rep- resentation by alignment before projection.arXiv preprint arXiv:2311.10122, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[31]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 7
2014
-
[32]
Visual abstract thinking empow- ers multimodal reasoning.arXiv preprint arXiv:2505.20164,
Dairu Liu, Ziyue Wang, Minyuan Ruan, Fuwen Luo, Chi Chen, Peng Li, and Yang Liu. Visual abstract thinking empowers multimodal reasoning.arXiv preprint arXiv:2505.20164, 2025. 2
-
[33]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 2
2023
-
[34]
Llava-plus: Learning to use tools for creating multi- modal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multi- modal agents. InECCV, pages 126–142. Springer, 2024. 2
2024
-
[35]
Mmbench: Is your multi-modal model an all-around player? InECCV, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InECCV, pages 216–233. Springer, 2024. 8
2024
-
[36]
Chain-of-action: Faithful and multimodal question answer- ing through large language models
Zhenyu Pan, Haozheng Luo, Manling Li, and Han Liu. Chain-of-action: Faithful and multimodal question answer- ing through large language models. InICLR, 2025. 2
2025
-
[37]
Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4.arXiv preprint arXiv:2304.03277, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[38]
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl. arXiv preprint arXiv:2503.07536, 2025. 1
-
[39]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T ¨ur, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[40]
arXiv preprint arXiv:2505.15298 1,
Kangan Qian, Sicong Jiang, Yang Zhong, Ziang Luo, Zilin Huang, Tianze Zhu, Kun Jiang, Mengmeng Yang, Zheng Fu, Jinyu Miao, et al. Agentthink: A unified framework for tool-augmented chain-of-thought reasoning in vision- language models for autonomous driving.arXiv preprint arXiv:2505.15298, 2025. 2
-
[41]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generaliz- able r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[42]
Benchmarking object de- tectors with coco: A new path forward
Shweta Singh, Aayan Yadav, Jitesh Jain, Humphrey Shi, Justin Johnson, and Karan Desai. Benchmarking object de- tectors with coco: A new path forward. InEuropean Con- ference on Computer Vision, pages 279–295. Springer, 2024. 7
2024
-
[43]
Somanshu Singla, Zhen Wang, Tianyang Liu, Abdullah Ash- faq, Zhiting Hu, and Eric P Xing. Dynamic rewarding with prompt optimization enables tuning-free self-alignment of language models.arXiv preprint arXiv:2411.08733, 2024. 3
-
[44]
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Jun- tao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025. 3
-
[45]
Qwen3-vl: 4b & 8b dense models.http : / / www
Alibaba Cloud (Tongyi Qianwen Team). Qwen3-vl: 4b & 8b dense models.http : / / www . shurl . cc / 476cd8cde87202e5eb123ad4e32d5766, 2025. Ac- cessed: 2025-11-07. 6, 7
2025
-
[46]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 6, 7
work page internal anchor Pith review arXiv 2024
-
[47]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[48]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space rea- soning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[50]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[51]
Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025. 3
-
[52]
Chain-of-thought prompting elicits reasoning in large lan- guage models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models. InNeurIPS, pages 24824–24837, 2022. 3
2022
-
[53]
Yifan Wei, Xiaoyan Yu, Yixuan Weng, Tengfei Pan, Ang- sheng Li, and Li Du. Autotir: Autonomous tools inte- grated reasoning via reinforcement learning.arXiv preprint arXiv:2507.21836, 2025. 1 10
-
[54]
Llava-cot: Let vision language models reason step-by-step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step. InICCV, pages 2087–2098,
2087
-
[55]
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, et al. Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search.arXiv preprint arXiv:2412.18319, 2024. 3
-
[56]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[57]
Unitbox: An advanced object detection net- work
Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang. Unitbox: An advanced object detection net- work. InACM MM, pages 516–520, 2016. 6
2016
-
[58]
arXiv preprint arXiv:2509.18154 , year=
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking effi- cient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025. 2
-
[59]
Yufei Zhan, Ziheng Wu, Yousong Zhu, Rongkun Xue, Ruipu Luo, Zhenghao Chen, Can Zhang, Yifan Li, Zhentao He, Zheming Yang, et al. Gthinker: Towards general multi- modal reasoning via cue-guided rethinking.arXiv preprint arXiv:2506.01078, 2025. 2, 3
-
[60]
Chaoning Zhang, Chenshuang Zhang, Sheng Zheng, Yu Qiao, Chenghao Li, Mengchun Zhang, Sumit Kumar Dam, Chu Myaet Thwal, Ye Lin Tun, Le Luang Huy, et al. A com- plete survey on generative ai (aigc): Is chatgpt from gpt-4 to gpt-5 all you need?arXiv preprint arXiv:2303.11717, 2023. 6, 7
-
[61]
Improve vision language model chain-of-thought reasoning, 2024
Ruohong Zhang, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yiming Yang. Improve vision language model chain-of- thought reasoning.arXiv preprint arXiv:2410.16198, 2024. 3
-
[62]
Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, et al. R1-reward: Training multimodal reward model through stable reinforcement learning.arXiv preprint arXiv:2505.02835, 2025. 6
-
[63]
Swift:a scal- able lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yun- lin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scal- able lightweight infrastructure for fine-tuning, 2024. 7
2024
-
[64]
Da Zheng, Lun Du, Junwei Su, Yuchen Tian, Yuqi Zhu, Jintian Zhang, Lanning Wei, Ningyu Zhang, and Huajun Chen. Knowledge augmented complex problem solving with large language models: A survey.arXiv preprint arXiv:2505.03418, 2025. 1
-
[65]
DriveAgent-R1: Advancing VLM-based Autonomous Driving with Active Perception and Hybrid Thinking
Weicheng Zheng, Xiaofei Mao, Nanfei Ye, Pengxiang Li, Kun Zhan, Xianpeng Lang, and Hang Zhao. Driveagent- r1: Advancing vlm-based autonomous driving with hy- brid thinking and active perception.arXiv preprint arXiv:2507.20879, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deep- eyes: Incentivizing” thinking with images” via reinforce- ment learning.arXiv preprint arXiv:2505.14362, 2025. 2, 8
work page internal anchor Pith review arXiv 2025
-
[67]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[68]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 6, 7 11 See Further, Think Deeper: Advancing VLM’s Reasoning Ability with Low-level Visual Cues a...
work page internal anchor Pith review arXiv 2025
-
[69]
thinking with visual cues
This guidance enables the model to appropriately in- voke designated visual tools, interpret the generated visual feedback, and seamlessly connect these intermediate steps to derive the final answer. This mechanism fundamen- tally realizes the principle of “thinking with visual cues”. The Canny tool, Zoom-In tool, and Color tool are referred to as<CANNY>,...
-
[70]
Initial Observation: Describe the general content of the image
-
[71]
Tool Selection Reasoning: Explain why the first tool in the list was selected based on the initial observation
-
[72]
Tool Application Results: Describe the results from using the first tool
-
[73]
Subsequent Analysis: If multiple tools are listed, repeat steps 2 and 3 for each tool
-
[74]
Output Requirements:
Conclusion: Based on the above findings, the target region and Target Character can be derived. Output Requirements:
-
[76]
Relevance: Ignore irrelevant information and avoid unnecessary details
-
[77]
Format: Use natural and fluent language without timestamps or extra instructions
-
[78]
Output Structure: Clearly separate each tool’s description and analysis sequentially
-
[79]
Provide a complete explanation without timestamps or additional instructions
Output Format: Use natural, fluent language. Provide a complete explanation without timestamps or additional instructions. Use ‘<>‘ to mark tools; choose from:<CANNY>,<ROI>,<COLOR>. The sentence structure should be: ”Based on the available information, we analyzed that we need to use<Tool 1>, and then use<Tool 2>for further analysis.<Attribution analysis>...
-
[80]
Do not include bounding boxes<Target Region>or Target Characters<Target Character>during the analysis; these are only shown in the final result
-
[81]
Descriptions of different tools should be separated and presented sequentially
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.