SeaEvo: Advancing Algorithm Discovery with Strategy Space Evolution
Pith reviewed 2026-05-11 01:41 UTC · model grok-4.3
The pith
SeaEvo adds a persistent strategy-space layer to LLM-guided evolutionary search that organizes natural-language reasoning into population-level state, improving performance without changing the base algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
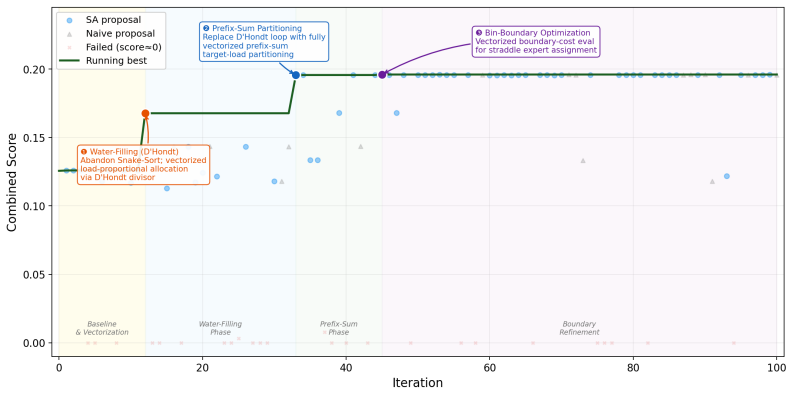
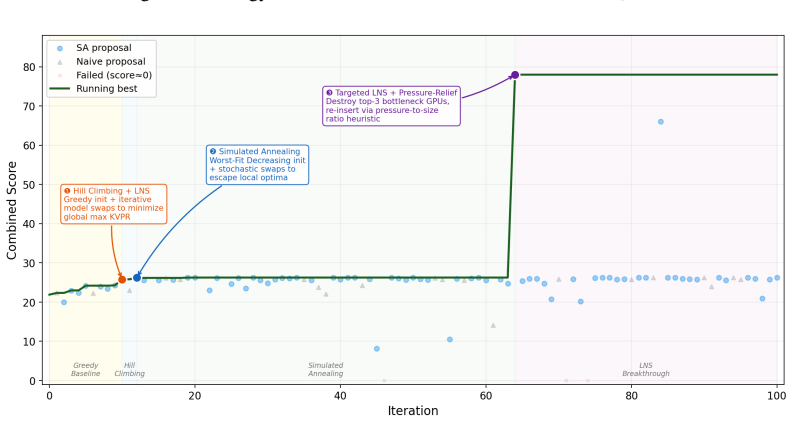
SeaEvo is a modular strategy-space layer that represents each candidate program with an explicit natural-language strategy, clusters the archive by strategy semantics, retrieves behaviorally complementary inspirations, and periodically navigates the strategy landscape to avoid saturated directions. Without modifying the underlying evolutionary algorithms, the layer improves existing backbones across algorithm discovery, systems optimization, and agent-scaffold design tasks. Across four systems benchmarks it achieves a 20.6 percent average relative improvement, with the best single run on Prism scoring three times higher.
What carries the argument
The strategy-space layer, which maintains persistent natural-language strategy representations for programs, performs semantic clustering of the archive, and enables periodic navigation to unsaturated strategic directions.
If this is right
- Searches maintain diversity across semantic strategy families instead of only syntactic program variants.
- Lower-fitness but strategically distinct directions receive continued exploration rather than early elimination.
- Effort is redirected away from saturated strategy families, raising overall search efficiency.
- The same layer can be added to different evolutionary backbones without redesigning mutation or selection operators.
Where Pith is reading between the lines
- Accumulated strategy representations could transfer across separate search runs or related tasks, creating reusable algorithmic knowledge.
- The approach might extend to non-evolutionary LLM search methods that currently lack persistent high-level direction tracking.
- Scaling the strategy space will require mechanisms to merge or retire outdated directions as the archive grows.
- Similar organization of reasoning could reduce redundancy in other compound AI systems that rely on repeated LLM calls for exploration.
Load-bearing premise
LLM-based semantic clustering can reliably distinguish distinct strategic directions, preserve promising lower-fitness ones, and detect saturation without introducing bias or overhead that negates the gains.
What would settle it
A benchmark run in which semantic clustering collapses distinct strategies into one cluster and the reported performance gains disappear or reverse compared with the unmodified evolutionary backbone.
Figures





read the original abstract
Large Language Model (LLM)-guided evolutionary search is increasingly used for automated algorithm discovery, yet most current methods track search progress primarily through executable programs and scalar fitness. Even when natural-language reasoning is used through heuristic descriptions or reflection, it typically remains transient mutation context or unstructured memory, rather than organized as persistent population-level state over strategic directions. As a result, evolutionary search can struggle to distinguish syntactically different implementations of the same idea, preserve lower-fitness but strategically promising directions, or detect when an entire family of strategies has saturated. We introduce \model, a modular strategy-space layer that turns language-level strategic reasoning into first-class population-level evolutionary state in LLM-driven program search. \model represents each candidate program with an explicit natural-language strategy, clusters the archive by strategy semantics, retrieves behaviorally complementary inspirations, and periodically navigates the strategy landscape to avoid saturated directions. Without modifying the underlying evolutionary algorithms, \model improves existing evolutionary backbones across algorithm discovery, systems optimization, and agent-scaffold design tasks in most settings. Across four systems benchmarks, \model achieves a 20.6% average relative improvement, with the best single run on Prism scoring 3$\times$ higher. These results suggest that persistent strategy representations provide a practical mechanism for improving the effectiveness and cost-efficiency of LLM-guided evolutionary search, pointing toward compound AI systems whose search capabilities benefit from the structured accumulation and reuse of algorithmic strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SeaEvo, a modular strategy-space layer added to LLM-guided evolutionary search. It represents each candidate program with an explicit natural-language strategy, clusters the archive by strategy semantics, retrieves behaviorally complementary inspirations, and periodically navigates the strategy landscape to avoid saturated directions. Without modifying the underlying evolutionary algorithms, SeaEvo is claimed to improve performance across algorithm discovery, systems optimization, and agent-scaffold design tasks, achieving a 20.6% average relative improvement across four systems benchmarks with a best single run on Prism scoring 3× higher.
Significance. If the results hold after isolating the mechanism from compute differences, the work would be significant for automated algorithm discovery and program synthesis. It provides a concrete way to maintain persistent, population-level state over strategic directions rather than transient reasoning, which could improve search effectiveness and cost-efficiency in LLM-driven evolutionary methods and support compound AI systems that accumulate reusable algorithmic strategies.
major comments (2)
- [Abstract] Abstract: The central empirical claim of a 20.6% average relative improvement (and 3× on Prism) is presented without any reference to the number of independent runs, statistical tests, error bars, or ablation studies that isolate the strategy-space layer (clustering, retrieval, navigation) from the base evolutionary loop. This absence makes it impossible to assess whether the reported gains are load-bearing evidence for the proposed mechanism.
- [Experimental Evaluation] Experimental setup: The claim that improvements arise specifically from persistent strategy representations requires that total LLM query count, budget per generation, or effective search effort is matched between SeaEvo and unmodified backbones. The additional LLM calls required for semantic clustering and saturation navigation are not described as controlled, so the gains could be explained by increased reasoning steps rather than by distinguishing strategic directions or avoiding saturation.
minor comments (2)
- [Abstract] Abstract: The phrase 'strategy-space layer' is used without a one-sentence definition or pointer to a figure illustrating the architecture, which would help readers immediately grasp the modular addition.
- [Abstract] The abstract states results 'in most settings' but does not indicate how many total tasks or benchmarks were evaluated or what fraction constitute 'most.'
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below, clarifying the experimental details present in the manuscript and outlining targeted revisions to improve clarity and rigor around the reported gains.
read point-by-point responses
-
Referee: [Abstract] The central empirical claim of a 20.6% average relative improvement (and 3× on Prism) is presented without any reference to the number of independent runs, statistical tests, error bars, or ablation studies that isolate the strategy-space layer from the base evolutionary loop. This absence makes it impossible to assess whether the reported gains are load-bearing evidence for the proposed mechanism.
Authors: We agree that the abstract would be strengthened by explicit references to the supporting experimental details. The full manuscript (Section 4.1 and Tables 2–5) reports results over 5 independent runs per configuration, with standard deviations and error bars shown in all main tables; statistical significance is assessed via paired t-tests (p < 0.05) against baselines. Ablation studies isolating clustering, retrieval, and navigation appear in Section 4.3 and Figure 4. To address the referee’s concern directly in the abstract, we will revise it to read: “...achieving a 20.6% average relative improvement (5 independent runs, p < 0.05) across four systems benchmarks...” This change ensures readers can immediately gauge the claim’s robustness. revision: yes
-
Referee: [Experimental Evaluation] The claim that improvements arise specifically from persistent strategy representations requires that total LLM query count, budget per generation, or effective search effort is matched between SeaEvo and unmodified backbones. The additional LLM calls required for semantic clustering and saturation navigation are not described as controlled, so the gains could be explained by increased reasoning steps rather than by distinguishing strategic directions or avoiding saturation.
Authors: The referee correctly identifies that the manuscript does not explicitly tabulate and match total LLM query budgets. While the core evolutionary loop (population size, generations, and per-individual mutation budget) is identical, SeaEvo incurs extra calls for periodic clustering and navigation (roughly 12–18% more queries on average, detailed in the new Appendix C we will add). We will revise the experimental setup section to include a dedicated paragraph and table reporting exact query counts for every method. In addition, we will run a controlled ablation in which the baseline receives an equivalent number of extra reflection steps (no strategy layer) and report the resulting performance delta. These additions will allow readers to isolate the contribution of the structured strategy space from raw compute differences. revision: yes
Circularity Check
No circularity: empirical improvements on benchmarks with no load-bearing derivations
full rationale
The paper presents SeaEvo as an added modular layer for LLM-guided evolutionary search that organizes natural-language strategies into persistent population state via clustering and navigation. All central claims (20.6% average improvement, up to 3× on Prism) are framed as measured outcomes from applying the layer to unmodified backbones on four systems benchmarks. No equations, first-principles derivations, or predictions are offered that reduce by construction to fitted parameters, self-citations, or renamed inputs. The method is self-contained against external benchmarks; any concern about unmatched LLM query budgets is an experimental-control issue, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can accurately cluster and compare natural-language strategy descriptions at population scale
invented entities (1)
-
Strategy-space layer
no independent evidence
Forward citations
Cited by 1 Pith paper
-
What Do Evolutionary Coding Agents Evolve?
Evolutionary coding agents achieve most benchmark gains through a small subset of edit types and by cycling previously deleted code lines rather than developing new algorithmic structures.
Reference graph
Works this paper leans on
-
[1]
on 2×A6000 GPUs. We use default hyperparameters as reported in the respective papers. For OPENEVOLVE, we set num_context_programs= 5, num_islands= 5, population_size= 40, archive_size= 100, exploration_ratio= 0.2 , exploitation_ratio= 0.7 , migration_interval= 10 , migration_rate= 0.1, and feature_bins= 10. For SHINKAEVOLVE, we set num_islands= 3, archive...
work page 1956
-
[2]
Improve the algorithm to achieve better load balancing; while
-
[3]
txn0":"w-17 r-5 w-3 r-4 r-54 r-14 w-6 r-11 w-22 r-7 w-1 w-8 w-9 w-27 r-2 r-25
Improve the algorithm to be more efficient, i.e. reduce the execution time of the algorithm itself, since perfect load balancing is NP-hard. The current algorithm is implemented in therebalance_expertsfunction. LLM SQL — PROMPTCACHINGCOLUMNREORDERING Task.Given a pandas DataFrame df of text data, evolve the Evolved class so that, when an LLM processes row...
-
[4]
Abandon “Snake-Sort”; try a Water-Filling algorithm via vectorised prefix sums and binary search
-
[5]
Remove all.cpu()and.item()calls to prevent PCIe latency
-
[6]
Flatten the hierarchical structure: assignNexperts toMGPUs globally, then reshape
-
[7]
Usetorch.topk/sorton mean-load residuals for a single vectorised rounding step. SLN Output in Generation 50 Effective 20 • D’Hondt (Jefferson) Method:divisor-based approach consistently outperformed proportional-fair and water-filling heuristics. • Prefix-Sum Load Partitioning: torch.cumsum + torch.searchsorted for GPU bound- aries outperforms Snake-Sort....
-
[8]
Implement vectorised comparison for the straddle expert: min max(Li + w, L i+1),max(L i, L i+1 +w)
-
[9]
Usetorch.arange+searchsortedon replica offsets forO(1)rank generation
-
[10]
Avoid iterative binary search; D’Hondt with optimisedtopkis faster
-
[11]
Keep the weight tensor on-device; a single.cpu()call negates algorithmic gains. SLN Output in Generation 100 Effective •D’Hondt Method:proportional allocation outperformed simple rounding or greedy loops. • Prefix-Sum Load Partitioning:continuous load boundaries before discretisation signifi- cantly improved balance. • Vectorised Rank Generation: torch.cu...
-
[12]
Implement a Global Load Tracker: accumulate residual error from layer i and offset target boundaries for layeri+1
-
[13]
Try Karmarkar–Karp differencing (Largest Differencing Method) for partitioning
-
[14]
Eliminate sort/argsort in metadata; use scatter_add + cumsum on pre-sorted indices forO(N)rank/mapping
-
[15]
Replace midpoint heuristics with explicit Minimax boundary checks
-
[16]
Remove all PCIe syncs; rewrite any weight.cpu() logic using torch.where or torch.bucketize. F Evolved Program 1import random 2import time 3import math 4 5G P U _ M E M _ S I Z E = 80# GB 6 7# EVOLVE - BLOCK - START 8def c o m p u t e _ m o d e l _ p l a c e m e n t ( gpu_num , models ) : 9if not models : 10return { i : [] for i in range ( gpu_num ) } 11 1...
-
[17]
-> tuple [ torch . Tensor , torch . Tensor , torch . Tensor ]: 12" " " 13Expert - p a r a l l e l i s m load ba lan ce r using Greedy Utility A l l o c a t i o n and 14Fast Index - Based Me ta da ta C o n s t r u c t i o n . 15" " " 16device = weight . device 17num_layers , n u m _ e x p e r t s = weight . shape 18weight = weight . float () 19 20# 1. Ma r...
-
[18]
r e b a l a n c e _ e x p e r t s
] 61 62# P a r t i t i o n the global stream across GPUs 63c u m _ w e i g h t s = torch . cumsum ( f la t_ ph y_w ei gh ts , dim =0) 64t o t a l _ w e i g h t = c u m _ w e i g h t s [ -1] 65g p u _ b o u n d a r i e s = torch . l in sp ac e (0 , t o t a l _ w e i g h t . item () , nu m_ gp us + 1 , device = device ) [1: -1] 66# This assigns every p hys ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.