Recognition: unknown
Layerwise Convergence Fingerprints for Runtime Misbehavior Detection in Large Language Models
Pith reviewed 2026-05-08 02:52 UTC · model grok-4.3
The pith
Layerwise Convergence Fingerprinting detects backdoors, jailbreaks, and prompt injections in LLMs by monitoring inter-layer hidden-state trajectories without reference models or retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Layerwise Convergence Fingerprinting treats the inter-layer hidden-state trajectory as a health signal. It computes a diagonal Mahalanobis distance on every inter-layer difference, aggregates via Ledoit-Wolf shrinkage, and thresholds via leave-one-out calibration on 200 clean examples, with no reference model, trigger knowledge, or retraining. A single aggregation score covers backdoors, jailbreaks, and prompt injections.
What carries the argument
Layerwise Convergence Fingerprint, which aggregates diagonal Mahalanobis distances on inter-layer hidden-state differences using Ledoit-Wolf shrinkage and leave-one-out calibration on clean data.
Load-bearing premise
That inter-layer hidden-state trajectories form a reliable, distinguishable health signal for misbehavior that can be captured by diagonal Mahalanobis distance, Ledoit-Wolf shrinkage, and leave-one-out calibration on 200 clean examples without any reference model, trigger knowledge, or retraining.
What would settle it
Applying a new backdoor trigger or jailbreak technique outside the 56 combinations and three techniques tested, then checking whether detection rates stay above 92 percent and false-positive rates stay below 16 percent on the same or additional models.
Figures


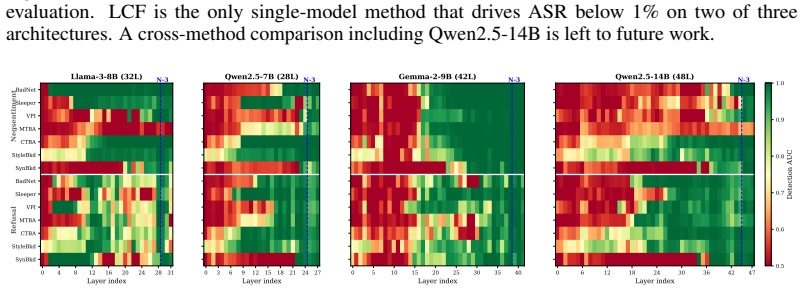


read the original abstract
Large language models deployed at runtime can misbehave in ways that clean-data validation cannot anticipate: training-time backdoors lie dormant until triggered, jailbreaks subvert safety alignment, and prompt injections override the deployer's instructions. Existing runtime defenses address these threats one at a time and often assume a clean reference model, trigger knowledge, or editable weights, assumptions that rarely hold for opaque third-party artifacts. We introduce Layerwise Convergence Fingerprinting (LCF), a tuning-free runtime monitor that treats the inter-layer hidden-state trajectory as a health signal: LCF computes a diagonal Mahalanobis distance on every inter-layer difference, aggregates via Ledoit-Wolf shrinkage, and thresholds via leave-one-out calibration on 200 clean examples, with no reference model, trigger knowledge, or retraining. Evaluated on four architectures (Llama-3-8B, Qwen2.5-7B, Gemma-2-9B, Qwen2.5-14B) across backdoors, jailbreaks, and prompt injection (56 backdoor combinations, 3 jailbreak techniques, and BIPIA email + code-QA), LCF reduces mean backdoor attack success rate (ASR) below 1% on Qwen2.5-7B and Gemma-2 and to 1.3% on Qwen2.5-14B, detects 92-100% of DAN jailbreaks (62-100% for GCG and softer role-play), and flags 100% of text-payload injections across all eight (model, domain) cells, at 12-16% backdoor FPR and <0.1% inference overhead. A single aggregation score covers all three threat families without threat-specific tuning, positioning LCF as a general-purpose runtime safety layer for cloud-served and on-device LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Layerwise Convergence Fingerprinting (LCF) as a tuning-free runtime monitor for LLMs that detects backdoors, jailbreaks, and prompt injections by treating inter-layer hidden-state trajectories as a health signal. It computes a diagonal Mahalanobis distance on inter-layer differences, aggregates via Ledoit-Wolf shrinkage, and thresholds the result using leave-one-out calibration on 200 clean examples, without a reference model, trigger knowledge, or retraining. Evaluations across Llama-3-8B, Qwen2.5-7B, Gemma-2-9B, and Qwen2.5-14B report reduced mean backdoor ASR (below 1% on two models, 1.3% on the third), 92-100% detection of DAN jailbreaks, 100% detection of text-payload injections, at 12-16% backdoor FPR and <0.1% overhead, with a single score covering all three threat families.
Significance. If the central claims hold under broader conditions, LCF would represent a meaningful advance in practical runtime safety for opaque third-party LLMs by providing a general-purpose, low-overhead layer that avoids per-threat tuning or reference models. The multi-model, multi-threat evaluation (four architectures, 56 backdoor combinations, multiple jailbreak techniques, and BIPIA) and the emphasis on deployment realism are strengths; the approach also ships an explicit, parameter-light pipeline (diagonal Mahalanobis + Ledoit-Wolf + LOO) that could be reproduced if the calibration procedure and raw statistics were fully documented.
major comments (3)
- [Evaluation and Calibration Procedure] The leave-one-out calibration on 200 clean examples is load-bearing for the no-tuning, general-purpose claim, yet the manuscript provides no experiments testing robustness under distribution shift (different domains, prompt styles, or lengths) that would be expected at deployment; the reported 12-16% FPR and high detection rates are therefore tied to the specific calibration sets without evidence they generalize.
- [Method Description] The choice of diagonal Mahalanobis distance on inter-layer differences plus Ledoit-Wolf shrinkage is presented as sufficient to capture a reliable health signal, but no ablation or justification is given for why full covariance is unnecessary or why this estimator outperforms simpler alternatives (e.g., per-layer norms or Euclidean distances) on the same data.
- [Results and Evaluation] Baseline comparisons and statistical significance are absent: the paper does not report how LCF compares to existing runtime monitors (perplexity, entropy, or other statistical detectors) nor provide variance, confidence intervals, or p-values for the detection rates (92-100% DAN, 100% injection) across the 56 backdoor combinations.
minor comments (2)
- [Abstract and §3] The abstract and method sections would benefit from an explicit equation defining the final aggregation score and threshold selection procedure to improve reproducibility.
- [Experimental Setup] Clarify the exact composition of the 200 clean examples (domains, lengths, sources) and whether they overlap with any evaluation prompts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional evidence and justification would strengthen the claims of general-purpose applicability and methodological soundness. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation and Calibration Procedure] The leave-one-out calibration on 200 clean examples is load-bearing for the no-tuning, general-purpose claim, yet the manuscript provides no experiments testing robustness under distribution shift (different domains, prompt styles, or lengths) that would be expected at deployment; the reported 12-16% FPR and high detection rates are therefore tied to the specific calibration sets without evidence they generalize.
Authors: We agree that robustness to distribution shift is essential to support the general-purpose claim. The current leave-one-out procedure uses 200 clean examples from the same distribution as the test prompts. In the revision we will add new experiments that vary the calibration distribution (e.g., code, mathematical reasoning, and long-context prompts) while keeping the same 200-example budget, and we will report how FPR and detection rates change under these shifts. revision: yes
-
Referee: [Method Description] The choice of diagonal Mahalanobis distance on inter-layer differences plus Ledoit-Wolf shrinkage is presented as sufficient to capture a reliable health signal, but no ablation or justification is given for why full covariance is unnecessary or why this estimator outperforms simpler alternatives (e.g., per-layer norms or Euclidean distances) on the same data.
Authors: The diagonal Mahalanobis estimator with Ledoit-Wolf shrinkage was chosen for numerical stability and low overhead when the number of calibration samples (200) is far smaller than the dimensionality of the hidden-state differences. We will add an ablation subsection that directly compares the chosen estimator against per-layer L2 norms, Euclidean distance on the same differences, and (where invertible) full-covariance Mahalanobis, reporting both detection performance and runtime cost on the identical evaluation sets. revision: yes
-
Referee: [Results and Evaluation] Baseline comparisons and statistical significance are absent: the paper does not report how LCF compares to existing runtime monitors (perplexity, entropy, or other statistical detectors) nor provide variance, confidence intervals, or p-values for the detection rates (92-100% DAN, 100% injection) across the 56 backdoor combinations.
Authors: We acknowledge that direct baseline comparisons and statistical reporting are needed. The revised manuscript will include side-by-side results against perplexity, output entropy, and other published statistical detectors using the same model and threat instances. We will also report per-experiment standard deviations or bootstrap confidence intervals for the 92-100% DAN and 100% injection figures, together with p-values from McNemar’s test across the 56 backdoor combinations. revision: yes
Circularity Check
No significant circularity; standard estimators applied to held-out calibration
full rationale
The paper defines LCF as computing diagonal Mahalanobis distances on inter-layer hidden-state differences, aggregating them with Ledoit-Wolf shrinkage, and setting a single threshold via explicit leave-one-out calibration on 200 clean examples. No equation or step reduces the final detection score or threshold to a quantity defined by the same fitted parameters used to claim success on attacks; the calibration data and attack evaluations are distinct, and the method relies on off-the-shelf statistical tools without self-definition, self-citation chains, or renaming of known results. The derivation is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- decision threshold
axioms (1)
- domain assumption Inter-layer hidden-state differences admit a meaningful diagonal Mahalanobis distance under Ledoit-Wolf shrinkage
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence,
URLhttps://arxiv.org/abs/2303.08112. 9 Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. DoLa: Decoding by contrasting layers improves factuality in large language models. InThe Twelfth International Conference on Learning Representations, Vienna, Austria, 2024. OpenReview.net. URLhttps://openreview.net/forum?id=Th6NyL0...
-
[2]
Association for Computing Machinery. ISBN 9781450376280. doi: 10.1145/3359789. 3359790. URLhttps://doi.org/10.1145/3359789.3359790. Aaron Grattafiori et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407. 21783. Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Identifying vulnerabilities in the machine learning model supply ...
-
[3]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
URLhttps://openreview.net/forum?id=sYLiY87mNn. Yuetai Li, Zhangchen Xu, Fengqing Jiang, Luyao Niu, Dinuka Sahabandu, Bhaskar Ramasubrama- nian, and Radha Poovendran. CleanGen: Mitigating backdoor attacks for generation tasks in large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empiri...
-
[4]
Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning,
Springer International Publishing. ISBN 978-3-030-00470-5. Nay Myat Min, Long H. Pham, Yige Li, and Jun Sun. CROW: Eliminating backdoors from large language models via internal consistency regularization. InForty-second International Conference on Machine Learning, Vancouver, Canada, 2025. PMLR. URL https://openreview.net/ forum?id=ZGtcgeCpWB. nostalgebra...
-
[5]
URLhttps://arxiv.org/abs/2412.15115. Adam Shai, Paul M. Riechers, Lucas Teixeira, Alexander Gietelink Oldenziel, and Sarah Marzen. Transformers represent belief state geometry in their residual stream. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/ forum?id=YIB7REL8UC. 11 Gemma Team, : Arm...
-
[6]
The N−3 single-layer variant already shows weakness at this level: 27.5% residual ASR on BadNet
LCF is fully robust at moderate regularization ( λ≤1 ).At λ=1.0, LCF detects 100% of triggered inputs for all three attacks, identical to the non-adaptive baseline. The N−3 single-layer variant already shows weakness at this level: 27.5% residual ASR on BadNet
-
[7]
At λ=5.0, VPI becomes the most vulnerable (76.5% residual), suggesting this trigger type has a sharper transition between detectable and evasive regimes
Partial evasion requires aggressive regularization and is attack-dependent.At λ=2.0, LCF maintains strong detection on Sleeper (2.0% residual) and VPI (0.0%), with partial evasion only on BadNet (15.5%). At λ=5.0, VPI becomes the most vulnerable (76.5% residual), suggesting this trigger type has a sharper transition between detectable and evasive regimes
-
[8]
longer ⇒ higher score
All-layer aggregation is critical for adaptive robustness.The contrast with N−3 is stark. At λ=2.0, the single-layer variant is completely evaded: 97.0% residual on BadNet, 98.5% on Sleeper, and 35.0% on VPI. The adaptive attacker can trivially suppress the signal at one fixed layer; suppressing it across all layers simultaneously is fundamentally harder....
2025
-
[9]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.