Recognition: unknown
Hierarchical Behaviour Spaces
Pith reviewed 2026-05-08 03:28 UTC · model grok-4.3
The pith
Linear combinations of reward functions let a high-level controller create a continuous space of behaviors for low-level policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that, instead of using a single reward function per option, the reward functions can be effectively used to induce a space of behaviours, by letting the controller specify linear combinations over reward functions, allowing a more expressive set of policies to be represented. We call this method Hierarchical Behaviour Spaces (HBS). We evaluate HBS on the NetHack Learning Environment, demonstrating strong performance. We conduct a series of experiments and determine that, perhaps going against conventional wisdom, the benefits of hierarchy in our method come from increased exploration rather than long term reasoning.
What carries the argument
Hierarchical Behaviour Spaces, the mechanism in which the controller outputs linear combinations over a fixed set of reward functions to define target behaviors for low-level policies.
If this is right
- A small number of reward functions can generate a continuous range of policies rather than a discrete set of options.
- Hierarchy improves learning primarily through broader exploration in complex environments.
- Performance gains appear in NetHack because the expanded behavior space aids discovery of effective strategies.
- Agents can represent more varied behaviors without additional reward engineering for each new option.
Where Pith is reading between the lines
- The method may lower the cost of designing hierarchical agents by reducing the number of manually specified options needed.
- Similar linear-combination spaces could be tested in other sparse-reward domains to check whether exploration benefits hold.
- Combining the fixed reward basis with a learned component might allow the behavior space to adapt during training.
Load-bearing premise
Linear combinations of the predefined reward functions are expressive enough to cover useful behaviors and yield stable policies without extra safeguards against degenerate cases.
What would settle it
An experiment in which exploration is controlled or removed as a factor (for example by providing dense shaping rewards) and HBS shows no advantage over a non-hierarchical baseline.
Figures



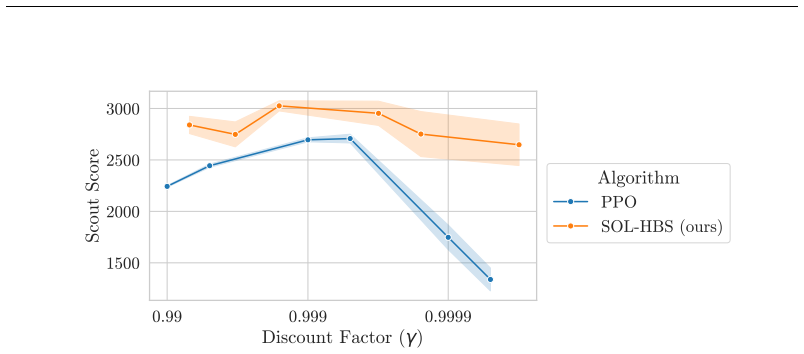
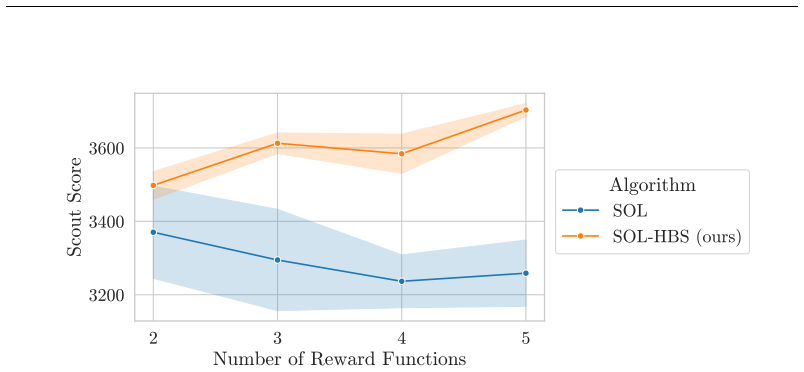
read the original abstract
Recent work in hierarchical reinforcement learning has shown success in scaling to billions of timesteps when learning over a set of predefined option reward functions. We show that, instead of using a single reward function per option, the reward functions can be effectively used to induce a space of behaviours, by letting the controller specify linear combinations over reward functions, allowing a more expressive set of policies to be represented. We call this method Hierarchical Behaviour Spaces (HBS). We evaluate HBS on the NetHack Learning Environment, demonstrating strong performance. We conduct a series of experiments and determine that, perhaps going against conventional wisdom, the benefits of hierarchy in our method come from increased exploration rather than long term reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Behaviour Spaces (HBS), a hierarchical reinforcement learning approach that uses linear combinations of predefined reward functions to induce a space of behaviors. This allows the controller to represent a more expressive set of policies compared to using a single reward function per option. The method is evaluated on the NetHack Learning Environment, where it achieves strong performance. A series of experiments leads the authors to conclude that the benefits of hierarchy in HBS arise primarily from increased exploration rather than from improved long-term reasoning or credit assignment.
Significance. If the results hold, this work is significant because it provides evidence against the conventional wisdom that hierarchical methods primarily help with long-term credit assignment. By showing that the main benefit is enhanced exploration through a behavior space induced by linear reward combinations, it opens new avenues for designing hierarchical RL systems that prioritize behavior diversity. The simplicity of the linear combination approach could make it widely applicable in environments where multiple reward functions are available, potentially improving scalability in complex domains like NetHack.
major comments (2)
- [Abstract] The central empirical claims—that HBS shows strong performance and that hierarchy benefits stem from exploration—are stated without any supporting data, metrics, baselines, or analysis. This is load-bearing for the paper's contribution, as the abstract supplies no implementation details, statistical results, ablation controls, or error analysis.
- [Experiments] To substantiate the claim that benefits come from increased exploration rather than long-term reasoning, specific experiments isolating these factors are required. For instance, comparisons to non-hierarchical agents with equivalent exploration mechanisms or ablations removing the linear combination aspect would be necessary to support the conclusion.
minor comments (1)
- The notation for linear combinations over reward functions should be formalized with equations in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below and will revise the manuscript to strengthen the abstract and experimental analysis.
read point-by-point responses
-
Referee: [Abstract] The central empirical claims—that HBS shows strong performance and that hierarchy benefits stem from exploration—are stated without any supporting data, metrics, baselines, or analysis. This is load-bearing for the paper's contribution, as the abstract supplies no implementation details, statistical results, ablation controls, or error analysis.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the central claims. In the revised version, we will expand the abstract to incorporate key performance metrics from the NetHack experiments (e.g., scores or success rates relative to baselines) and a concise reference to the experimental findings on exploration versus long-term reasoning. This will provide immediate evidence while preserving the abstract's summary nature. revision: yes
-
Referee: [Experiments] To substantiate the claim that benefits come from increased exploration rather than long-term reasoning, specific experiments isolating these factors are required. For instance, comparisons to non-hierarchical agents with equivalent exploration mechanisms or ablations removing the linear combination aspect would be necessary to support the conclusion.
Authors: The manuscript reports a series of experiments that support the conclusion regarding exploration benefits. To more directly isolate the contributions of hierarchy and the linear reward combinations, we will add the suggested experiments in revision: comparisons against non-hierarchical agents equipped with matched exploration mechanisms, and ablations that disable the linear combination mechanism to quantify its effect on behavior diversity and performance. revision: yes
Circularity Check
No significant circularity; empirical method with independent evaluation
full rationale
The paper introduces Hierarchical Behaviour Spaces (HBS) as an empirical extension to hierarchical RL: predefined option reward functions are combined linearly by a controller to induce a behavior space, with performance evaluated on NetHack. The central claims (more expressive policies, benefits primarily from exploration) rest on experimental results rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the provided abstract or high-level description. The work is self-contained against external benchmarks via direct environment evaluation, consistent with a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function.arXiv preprint arXiv:1802.06070,
-
[2]
Stop regressing: Training value functions via classification for scalable deep rl
Jesse Farebrother, Jordi Orbay, Quan Vuong, Adrien Ali Taïga, Yevgen Chebotar, Ted Xiao, Alex Ir- pan, Sergey Levine, Pablo Samuel Castro, Aleksandra Faust, et al. Stop regressing: Training value functions via classification for scalable deep rl, 2024.URL https://arxiv. org/abs/2403.03950,
- [3]
-
[4]
Insights from the neurips 2021 nethack challenge
Eric Hambro, Sharada Mohanty, Dmitrii Babaev, Minwoo Byeon, Dipam Chakraborty, Edward Grefenstette, Minqi Jiang, Jo Daejin, Anssi Kanervisto, Jongmin Kim, et al. Insights from the neurips 2021 nethack challenge. InNeurIPS 2021 Competitions and Demonstrations Track, pp. 41–52. PMLR, 2022a. Eric Hambro, Roberta Raileanu, Danielle Rothermel, Vegard Mella, Ti...
2021
-
[5]
Scalable Option Learning in High-Throughput Environments
Mikael Henaff, Scott Fujimoto, Michael Matthews, and Michael Rabbat. Scalable option learning in high-throughput environments.arXiv preprint arXiv:2509.00338,
work page internal anchor Pith review arXiv
-
[6]
Learnings options end-to-end for continuous action tasks.arXiv preprint arXiv:1712.00004,
Martin Klissarov, Pierre-Luc Bacon, Jean Harb, and Doina Precup. Learnings options end-to-end for continuous action tasks.arXiv preprint arXiv:1712.00004,
-
[7]
Motif: Intrinsic motivation from artificial intelligence feedback.arXiv preprint arXiv:2310.00166,
9 Martin Klissarov, Pierluca D’Oro, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang, and Mikael Henaff. Motif: Intrinsic motivation from artificial intelligence feedback.arXiv preprint arXiv:2310.00166,
-
[8]
Maestromotif: Skill design from artificial intelligence feedback.arXiv preprint arXiv:2412.08542,
Martin Klissarov, Mikael Henaff, Roberta Raileanu, Shagun Sodhani, Pascal Vincent, Amy Zhang, Pierre-Luc Bacon, Doina Precup, Marlos C Machado, and Pierluca D’Oro. Maestromotif: Skill design from artificial intelligence feedback.arXiv preprint arXiv:2412.08542,
-
[9]
Discovering temporal structure: An overview of hierarchical reinforcement learning
Martin Klissarov, Akhil Bagaria, Ziyan Luo, George Konidaris, Doina Precup, and Marlos C Machado. Discovering temporal structure: An overview of hierarchical reinforcement learning. arXiv preprint arXiv:2506.14045,
-
[10]
Sub-policy adaptation for hierarchical reinforcement learning.arXiv preprint arXiv:1906.05862,
Alexander C Li, Carlos Florensa, Ignasi Clavera, and Pieter Abbeel. Sub-policy adaptation for hierarchical reinforcement learning.arXiv preprint arXiv:1906.05862,
-
[11]
Michael Matthews, Mikayel Samvelyan, Jack Parker-Holder, Edward Grefenstette, and Tim Rock- täschel. Hierarchical kickstarting for skill transfer in reinforcement learning.arXiv preprint arXiv:2207.11584,
-
[12]
Revisiting the NetHack learning environment
Michael Matthews, Pierluca D’Oro, Anssi Kanervisto, Scott Fujimoto, Jakob Foerster, and Mikael Henaff. Revisiting the NetHack learning environment. InICLR 2026 Blog Track,
2026
-
[13]
Amy McGovern and Andrew G Barto
URLhttps://iclr-blogposts.github.io/2026/blog/2026/ revisiting-the-nle/. Amy McGovern and Andrew G Barto. Automatic discovery of subgoals in reinforcement learning using diverse density
2026
-
[14]
arXiv preprint arXiv:2411.13543 , year=
Davide Paglieri, Bartłomiej Cupiał, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuci ´nski, Lerrel Pinto, Rob Fergus, et al. Balrog: Bench- marking agentic llm and vlm reasoning on games.arXiv preprint arXiv:2411.13543,
-
[15]
Horizon Reduction Makes RL Scalable , October 2025 b
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon reduction makes rl scalable.arXiv preprint arXiv:2506.04168,
-
[16]
Proximal Policy Optimization Algorithms
10 John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
- [17]
-
[18]
Skill-based model-based reinforcement learning.arXiv preprint arXiv:2207.07560,
Lucy Xiaoyang Shi, Joseph J Lim, and Youngwoon Lee. Skill-based model-based reinforcement learning.arXiv preprint arXiv:2207.07560,
-
[19]
arXiv preprint arXiv:2402.02868 , year=
Maciej Wołczyk, Bartłomiej Cupiał, Mateusz Ostaszewski, Michał Bortkiewicz, Michał Zaj ˛ ac, Raz- van Pascanu, Łukasz Kuci ´nski, and Piotr Miło´s. Fine-tuning reinforcement learning models is secretly a forgetting mitigation problem.arXiv preprint arXiv:2402.02868,
-
[20]
Qinqing Zheng, Mikael Henaff, Amy Zhang, Aditya Grover, and Brandon Amos. Online intrin- sic rewards for decision making agents from large language model feedback.arXiv preprint arXiv:2410.23022,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.