Recognition: unknown
CF-VLA: Efficient Coarse-to-Fine Action Generation for Vision-Language-Action Policies
Pith reviewed 2026-05-08 04:30 UTC · model grok-4.3
The pith
Restructuring flow-based action generation into coarse initialization from endpoint velocity and single-step refinement enables efficient high-performance VLA policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
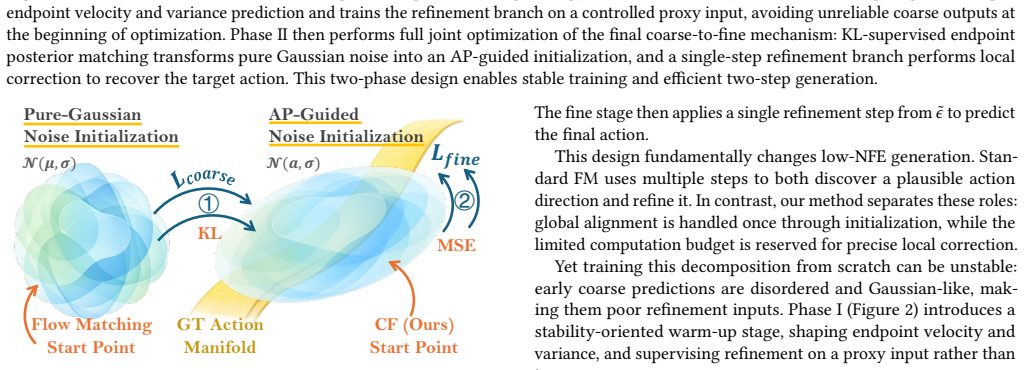
The central claim is that a coarse-to-fine two-stage formulation restructures action generation: the coarse stage learns a conditional posterior over endpoint velocity to construct an action-aware starting point from Gaussian noise, while the fine stage performs a single fixed-time refinement to correct residual errors, yielding strong efficiency-performance trade-offs under low-NFE conditions.
What carries the argument
Coarse-to-fine two-stage action generation with conditional posterior over endpoint velocity for initialization.
If this is right
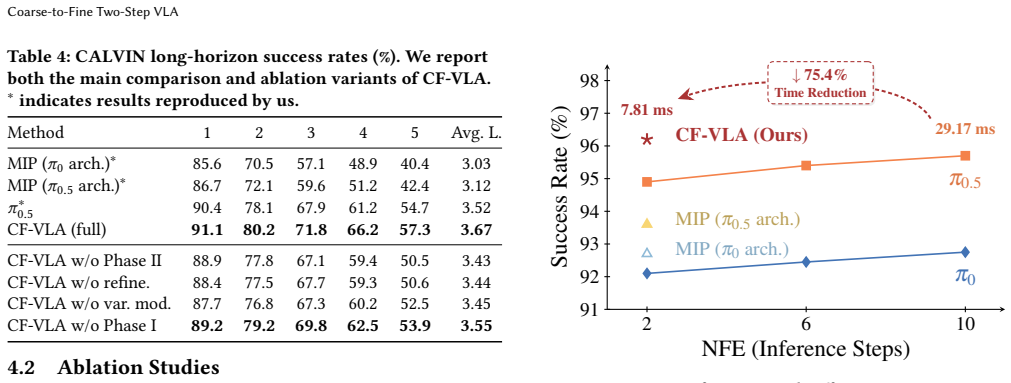
- Consistently outperforms existing NFE=2 methods on CALVIN and LIBERO.
- Matches or surpasses NFE=10 π0.5 baseline on several metrics.
- Reduces action sampling latency by 75.4%.
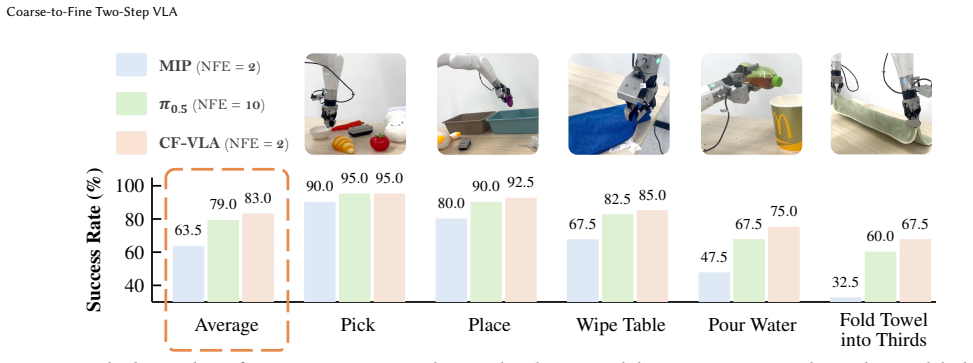
- Achieves best average real-robot success rate of 83.0%.
Where Pith is reading between the lines
- The approach highlights the importance of good initialization in generative models, which could inspire similar strategies in other domains like image or video generation.
- Stepwise training from coarse to joint optimization might be useful for stabilizing other complex generative training processes.
- If the coarse predictor can be made deterministic or faster, it may allow even lower latency in edge robotics.
Load-bearing premise
The initialization produced by the coarse-stage posterior over endpoint velocity is close enough to the target action distribution that one refinement step suffices to correct residual errors.
What would settle it
If on the CALVIN or LIBERO benchmarks the performance with NFE=2 using this method does not outperform other NFE=2 methods or match the NFE=10 baseline, the central claim would be falsified.
Figures


read the original abstract
Flow-based vision-language-action (VLA) policies offer strong expressivity for action generation, but suffer from a fundamental inefficiency: multi-step inference is required to recover action structure from uninformative Gaussian noise, leading to a poor efficiency-quality trade-off under real-time constraints. We address this issue by rethinking the role of the starting point in generative action modeling. Instead of shortening the sampling trajectory, we propose CF-VLA, a coarse-to-fine two-stage formulation that restructures action generation into a coarse initialization step that constructs an action-aware starting point, followed by a single-step local refinement that corrects residual errors. Concretely, the coarse stage learns a conditional posterior over endpoint velocity to transform Gaussian noise into a structured initialization, while the fine stage performs a fixed-time refinement from this initialization. To stabilize training, we introduce a stepwise strategy that first learns a controlled coarse predictor and then performs joint optimization. Experiments on CALVIN and LIBERO show that our method establishes a strong efficiency-performance frontier under low-NFE (Number of Function Evaluations) regimes: it consistently outperforms existing NFE=2 methods, matches or surpasses the NFE=10 $\pi_{0.5}$ baseline on several metrics, reduces action sampling latency by 75.4%, and achieves the best average real-robot success rate of 83.0%, outperforming MIP by 19.5 points and $\pi_{0.5}$ by 4.0 points. These results suggest that structured, coarse-to-fine generation enables both strong performance and efficient inference. Our code is available at https://github.com/EmbodiedAI-RoboTron/CF-VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CF-VLA, a coarse-to-fine two-stage formulation for flow-based vision-language-action policies. The coarse stage learns a conditional posterior over endpoint velocity to produce a structured action-aware initialization from Gaussian noise; the fine stage then applies a single fixed-time refinement step. Training uses a stepwise strategy (first coarse predictor, then joint optimization). Experiments on CALVIN and LIBERO benchmarks and real-robot tasks claim consistent outperformance of existing NFE=2 methods, parity or better with NFE=10 π_{0.5} baselines on several metrics, 75.4% reduction in action sampling latency, and the highest average real-robot success rate of 83.0%.
Significance. If the core assumption holds, the work could meaningfully advance real-time deployment of expressive flow-based VLA models by restructuring the sampling trajectory rather than simply truncating it. The stepwise training procedure offers a practical stabilization technique, and the public code release supports reproducibility. The reported gains on standard benchmarks and real robots would be notable if accompanied by stronger validation of the initialization quality.
major comments (3)
- [Section 3.2] Section 3.2 (Coarse Stage): The efficiency claims rest on the unverified premise that the learned conditional posterior over endpoint velocity produces an initialization sufficiently close to the target action distribution for a single fixed-time refinement step to correct residuals reliably. No supporting analysis (e.g., Wasserstein distances, per-dimension residual histograms, or mode-coverage metrics) is provided for high-dimensional multimodal robot action spaces; this is load-bearing for the NFE=2 performance and 75.4% latency reduction assertions.
- [Section 4] Section 4 (Experiments): Reported quantitative improvements on CALVIN and LIBERO (outperformance of NFE=2 methods and matching NFE=10 baselines) lack error bars, ablation studies isolating the coarse initialization and stepwise training, and statistical significance tests. This weakens confidence in the consistency of the gains and the claim that the method establishes a strong efficiency-performance frontier.
- [Section 4.3] Section 4.3 (Real-Robot Evaluation): The 83.0% average success rate (outperforming MIP by 19.5 points and π_{0.5} by 4.0 points) is presented without trial counts, variance estimates, or detailed task-variation protocols, which is necessary to substantiate the real-world applicability claim.
minor comments (2)
- [Abstract] Abstract: The baseline notation 'NFE=10 π_{0.5}' should be defined on first use and rendered consistently in math mode.
- [Section 3] The manuscript would benefit from an additional figure in Section 3 showing example coarse initializations versus target actions to illustrate the refinement step.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Coarse Stage): The efficiency claims rest on the unverified premise that the learned conditional posterior over endpoint velocity produces an initialization sufficiently close to the target action distribution for a single fixed-time refinement step to correct residuals reliably. No supporting analysis (e.g., Wasserstein distances, per-dimension residual histograms, or mode-coverage metrics) is provided for high-dimensional multimodal robot action spaces; this is load-bearing for the NFE=2 performance and 75.4% latency reduction assertions.
Authors: We agree that direct quantitative analysis of initialization quality would provide stronger support. The reported benchmark gains offer indirect evidence of effective initialization, but we will add supporting material in the revision, including per-dimension residual histograms after the coarse stage and visualizations of coarse-stage action trajectories, to better substantiate the premise. revision: partial
-
Referee: [Section 4] Section 4 (Experiments): Reported quantitative improvements on CALVIN and LIBERO (outperformance of NFE=2 methods and matching NFE=10 baselines) lack error bars, ablation studies isolating the coarse initialization and stepwise training, and statistical significance tests. This weakens confidence in the consistency of the gains and the claim that the method establishes a strong efficiency-performance frontier.
Authors: We acknowledge these omissions reduce robustness. In the revised manuscript we will include error bars on all metrics, add ablations that isolate the coarse initialization and stepwise training components, and report statistical significance tests for the key comparisons. revision: yes
-
Referee: [Section 4.3] Section 4.3 (Real-Robot Evaluation): The 83.0% average success rate (outperforming MIP by 19.5 points and π_{0.5} by 4.0 points) is presented without trial counts, variance estimates, or detailed task-variation protocols, which is necessary to substantiate the real-world applicability claim.
Authors: We will expand Section 4.3 to report the exact trial counts per task, include variance or standard deviation across trials, and provide a clearer description of the task-variation protocols and evaluation setup. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper introduces CF-VLA as a new two-stage coarse-to-fine architecture for flow-based VLA policies: a coarse stage that learns a conditional posterior over endpoint velocity to produce a structured initialization from noise, followed by a single fixed-time refinement step. Training stabilization via stepwise optimization is a standard technique and does not equate any claimed performance metric (e.g., latency reduction or success rate) to a fitted parameter or input by construction. No equations, self-citations, or uniqueness theorems are invoked in the provided text that would reduce the efficiency-quality frontier or benchmark results to tautological redefinitions of the inputs. Results are presented as empirical outcomes on external datasets (CALVIN, LIBERO) and real-robot tasks, with no load-bearing step that collapses to self-referential fitting or renaming of known patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
𝜋0: A Vision-Language-Action Flow Model for General Robot Control. arXiv:2410.24164 [cs.LG] https://arxiv.org/abs/2410.24164
work page internal anchor Pith review arXiv
-
[3]
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov...
work page internal anchor Pith review arXiv 2023
-
[4]
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. 2025. UniVLA: Learning to Act Anywhere with Task-centric Latent Actions. InRobotics: Science and Systems (RSS). https: //arxiv.org/abs/2505.06111
work page internal anchor Pith review arXiv 2025
-
[5]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud
-
[6]
https://arxiv.org/abs/1806.07366
Neural Ordinary Differential Equations. arXiv:1806.07366 [cs.LG] https: //arxiv.org/abs/1806.07366
-
[7]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. 2024. Diffusion Policy: Visuomo- tor Policy Learning via Action Diffusion. arXiv:2303.04137 [cs.RO] https: //arxiv.org/abs/2303.04137
work page internal anchor Pith review arXiv 2024
- [8]
-
[9]
Shichao Fan, Quantao Yang, Yajie Liu, Kun Wu, Zhengping Che, Qingjie Liu, and Min Wan. 2025. Diffusion Trajectory-guided Policy for Long-horizon Robot Manipulation. arXiv:2502.10040 [cs.RO] doi:10.1109/LRA.2025.3619794
- [10]
-
[11]
Yiyang Huang, Yuhui Hao, Bo Yu, Feng Yan, Yuxin Yang, Feng Min, Yinhe Han, Lin Ma, Shaoshan Liu, Qiang Liu, and Yiming Gan. 2025. Dadu-Corki: Algorithm- Architecture Co-Design for Embodied AI-powered Robotic Manipulation. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (SIGARCH ’25). ACM, 327–343. doi:10.1145/3695053.3731099
- [12]
-
[13]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dha- balia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szy- mon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Per...
-
[14]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
𝜋0.5: a Vision-Language-Action Model with Open-World Generalization. arXiv:2504.16054 [cs.LG] https://arxiv.org/abs/2504.16054
work page internal anchor Pith review arXiv
-
[15]
Yina Jian, Di Tian, Xuan-Jing Chen, Zhen-Yuan Wei, Chen-Wei Liang, and Mu- Jiang-Shan Wang. 2026. PI-VLA: Adaptive Symmetry-Aware Decision-Making for Long-Horizon Vision–Language–Action Manipulation.Symmetry18, 3 (2026). doi:10.3390/sym18030394
- [16]
-
[17]
Kento Kawaharazuka, Jihoon Oh, Jun Yamada, Ingmar Posner, and Yuke Zhu
-
[18]
Vision-Language-Action Models for Robotics: A Review Towards Real- World Applications.IEEE Access13 (2025), 162467–162504. doi:10.1109/access. 2025.3609980
-
[19]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-Tuning Vision-Language- Action Models: Optimizing Speed and Success. arXiv:2502.19645 [cs.RO] https: //arxiv.org/abs/2502.19645
work page internal anchor Pith review arXiv 2025
-
[20]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. 2026. Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning. arXiv:2601.16163 [cs.AI] https://arxiv.org/abs/2601.16163
work page internal anchor Pith review arXiv 2026
-
[21]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. OpenVLA: An Open-Source Vision- Language-Action Model. arXiv:2406.09246 [cs.RO] h...
work page internal anchor Pith review arXiv 2024
-
[22]
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. 2025. MolmoAct: Action Reasoning Models that can Reason in Space. arXiv:2508.07917 [cs.RO] https://arxiv....
work page internal anchor Pith review arXiv 2025
- [23]
-
[24]
Hao Li, Shuai Yang, Yilun Chen, Xinyi Chen, Xiaoda Yang, Yang Tian, Hanqing Wang, Tai Wang, Dahua Lin, Feng Zhao, and Jiangmiao Pang. 2025. CronusVLA: Towards Efficient and Robust Manipulation via Multi-Frame Vision-Language- Action Modeling. arXiv:2506.19816 [cs.RO] https://arxiv.org/abs/2506.19816
-
[25]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. 2023. Flow Matching for Generative Modeling. arXiv:2210.02747 [cs.LG] https://arxiv.org/abs/2210.02747
work page internal anchor Pith review arXiv 2023
-
[26]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning. arXiv:2306.03310 [cs.AI] https://arxiv.org/abs/2306.03310
work page internal anchor Pith review arXiv 2023
-
[27]
Fanfan Liu, Feng Yan, Liming Zheng, Chengjian Feng, Yiyang Huang, and Lin Ma
-
[28]
Robouniview: Visual-language model with unified view representation for robotic manipulation
RoboUniView: Visual-Language Model with Unified View Representation for Robotic Manipulation. arXiv:2406.18977 [cs.RO] https://arxiv.org/abs/2406. 18977
-
[29]
Haoming Liu, Jinnuo Liu, Yanhao Li, Liuyang Bai, Yunkai Ji, Yuanhe Guo, Shenji Wan, and Hongyi Wen. 2025. From Navigation to Refinement: Revealing the Two-Stage Nature of Flow-based Diffusion Models through Oracle Velocity. arXiv:2512.02826 [cs.LG] https://arxiv.org/abs/2512.02826
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [30]
- [31]
- [32]
- [33]
-
[34]
Chaoyi Pan, Giri Anantharaman, Nai-Chieh Huang, Claire Jin, Daniel Pfrommer, Chenyang Yuan, Frank Permenter, Guannan Qu, Nicholas Boffi, Guanya Shi, and Max Simchowitz. 2026. Much Ado About Noising: Dispelling the Myths Du et al. of Generative Robotic Control. arXiv:2512.01809 [cs.RO] https://arxiv.org/abs/ 2512.01809
- [35]
-
[36]
Moritz Reuss, Ömer Erdinç Yağmurlu, Fabian Wenzel, and Rudolf Lioutikov
-
[37]
Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals. arXiv:2407.05996 [cs.RO] https://arxiv.org/abs/2407.05996
-
[38]
Tim Salimans and Jonathan Ho. 2022. Progressive Distillation for Fast Sampling of Diffusion Models. arXiv:2202.00512 [cs.LG] https://arxiv.org/abs/2202.00512
work page internal anchor Pith review arXiv 2022
- [39]
-
[40]
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xiangyu Zhang, and Gao Huang. 2026. MemoryVLA: Perceptual- Cognitive Memory in Vision-Language-Action Models for Robotic Manipulation. arXiv:2508.19236 [cs.RO] https://arxiv.org/abs/2508.19236
-
[41]
Denis Tarasov, Alexander Nikulin, Ilya Zisman, Albina Klepach, Nikita Lyubaykin, Andrei Polubarov, Alexander Derevyagin, and Vladislav Kurenkov
-
[42]
Training VLA Models with Normaliz- ing Flows
NinA: Normalizing Flows in Action. Training VLA Models with Normaliz- ing Flows. arXiv:2508.16845 [cs.CV] https://arxiv.org/abs/2508.16845
- [43]
- [44]
- [45]
-
[46]
Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, and Chang Xu
-
[47]
VLA-Cache: Efficient Vision-Language-Action Manipulation via Adaptive Token Caching. arXiv:2502.02175 [cs.RO] https://arxiv.org/abs/2502.02175
- [48]
- [49]
-
[50]
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, Feng Xiong, Xing Wei, Zhiheng Ma, and Mu Xu. 2026. ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning. arXiv:2602.11236 [cs.CV] https: //arxiv.org/abs/2602.11236
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [51]
- [52]
- [53]
- [54]
-
[55]
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin. 2025. DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge. arXiv:2507.04447 [cs.CV] https://arxiv.org/abs/2507.04447
-
[56]
Jinliang Zheng, Jianxiong Li, Dongxiu Liu, Yinan Zheng, Zhihao Wang, Zhonghong Ou, Yu Liu, Jingjing Liu, Ya-Qin Zhang, and Xianyuan Zhan
-
[57]
Universal actions for enhanced embodied foundation models
Universal Actions for Enhanced Embodied Foundation Models. arXiv:2501.10105 [cs.RO] https://arxiv.org/abs/2501.10105
-
[58]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, and Xianyuan Zhan. 2025. X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model. arXiv:2510.10274 [cs.RO] https://arxiv.org/abs/2510.10274 ...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.