Recognition: unknown
Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs from Raw Corpora
Pith reviewed 2026-05-08 03:10 UTC · model grok-4.3
The pith
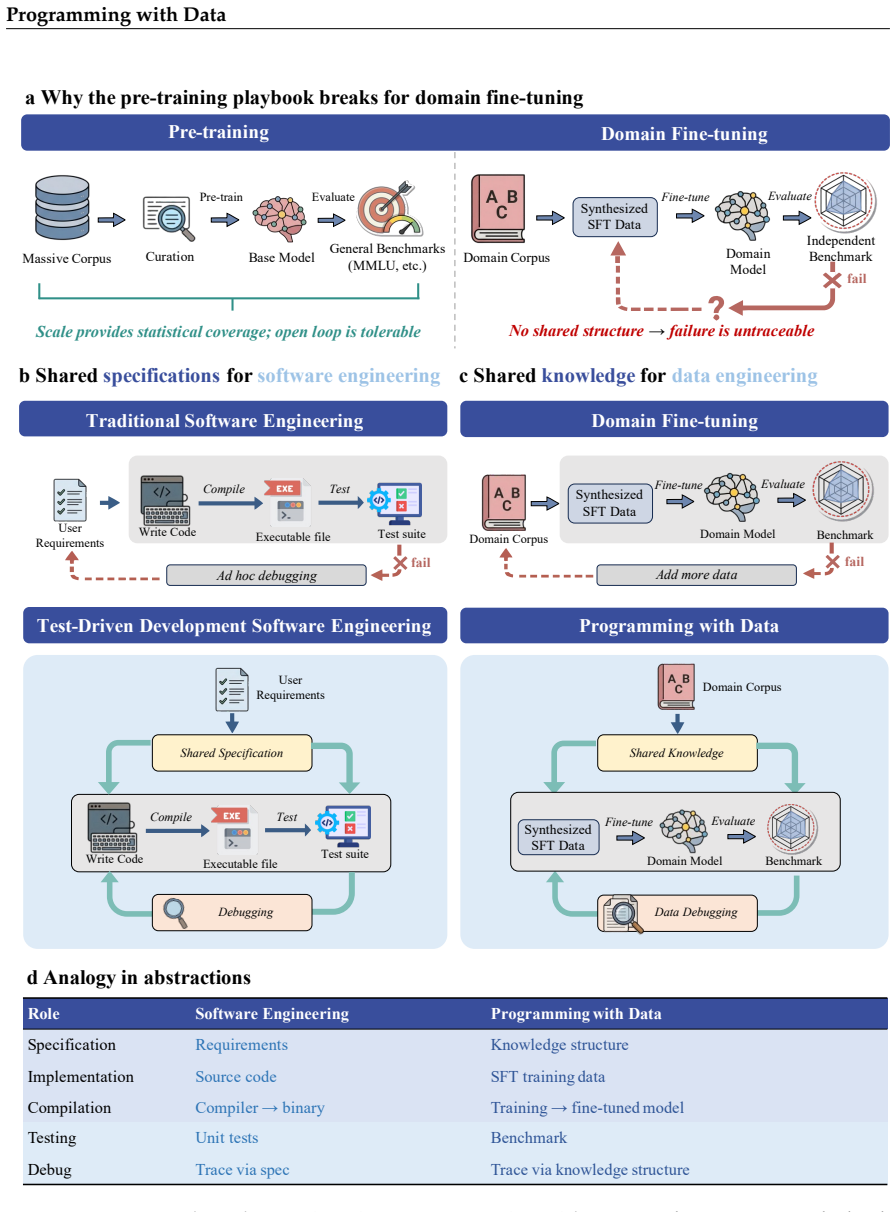
When training data and evaluation share a structured knowledge base extracted from raw text, model failures become traceable data deficiencies that can be repaired like software bugs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When a structured knowledge representation extracted from the source corpus serves as the shared foundation for both training data and evaluation, the complete data-engineering lifecycle maps onto the software development lifecycle in a precise and operative way: training data becomes source code specifying what the model should learn, model training becomes compilation, benchmarking becomes unit testing, and failure-driven data repair becomes debugging. Under this correspondence, model failures decompose into concept-level gaps and reasoning-chain breaks that can be traced back to specific deficiencies in the data and repaired through targeted patches, with each repair cycle producing the 2
What carries the argument
The structured knowledge representation extracted from raw corpora that serves as the single source for both training examples and evaluation benchmarks, enabling the full mapping of data engineering onto the software development lifecycle.
If this is right
- Each debugging cycle improves domain performance across different model scales and architectures without harming general capabilities.
- The same structured knowledge base can generate both the training corpus and the test suite, closing the loop between data creation and verification.
- Specialized human knowledge from any text corpus can be transferred into models through repeated, measurable repair steps rather than blind data scaling.
- The method applies uniformly across natural sciences, engineering, biomedicine, and social sciences once the initial knowledge extraction is performed.
Where Pith is reading between the lines
- If the mapping holds, organizations could maintain version-controlled knowledge bases whose updates automatically propagate to model behavior through the same debugging workflow used for software.
- The approach suggests a route to partial interpretability: each model error can be linked to a concrete, human-readable knowledge item rather than remaining inside opaque parameter changes.
- Extending the method to multimodal or agentic systems would require only that their failures also decompose into traceable gaps in a shared structured representation.
Load-bearing premise
Model failures can be decomposed into specific concept gaps or reasoning breaks that reliably trace back to particular missing or incorrect items in the extracted knowledge base.
What would settle it
A controlled experiment in which targeted data patches derived from failure analysis produce no measurable improvement on the corresponding benchmark items while general capabilities remain unchanged.
Figures



























read the original abstract
Reliably transferring specialized human knowledge from text into large language models remains a fundamental challenge in artificial intelligence. Fine-tuning on domain corpora has enabled substantial capability gains, but the process operates without feedback: when a model fails on a domain task, there is no method to diagnose what is deficient in the training data, and the only recourse is to add more data indiscriminately. Here we show that when a structured knowledge representation extracted from the source corpus serves as the shared foundation for both training data and evaluation, the complete data-engineering lifecycle maps onto the software development lifecycle in a precise and operative way: training data becomes source code specifying what the model should learn, model training becomes compilation, benchmarking becomes unit testing, and failure-driven data repair becomes debugging. Under this correspondence, model failures decompose into concept-level gaps and reasoning-chain breaks that can be traced back to specific deficiencies in the data and repaired through targeted patches, with each repair cycle producing consistent improvements across model scales and architectures without degrading general capabilities. We formalize this principle as Programming with Data and instantiate it across sixteen disciplines spanning the natural sciences, engineering, biomedicine, and the social sciences, releasing a structured knowledge base, benchmark suite, and training corpus as open resources. By demonstrating that the relationship between training data and model behaviour is structurally traceable and systematically repairable, this work establishes a principled foundation for the reliable engineering of human expertise into language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the 'Programming with Data' framework, which extracts a structured knowledge representation from raw source corpora to serve as the shared foundation for both training data and evaluation benchmarks. It claims that this correspondence maps the full data-engineering lifecycle onto the software development lifecycle in a precise and operative manner: training data becomes source code, model training becomes compilation, benchmarking becomes unit testing, and failure-driven data repair becomes debugging. Under this mapping, model failures are said to decompose into concept-level gaps and reasoning-chain breaks traceable to specific data deficiencies, which can be repaired via targeted patches. The authors assert that each repair cycle yields consistent improvements across model scales and architectures in sixteen disciplines (natural sciences, engineering, biomedicine, social sciences) without degrading general capabilities, and they release the associated knowledge base, benchmark suite, and training corpus as open resources.
Significance. If the traceability of failures and the reported improvements hold under rigorous controls, the work would establish a principled, feedback-driven methodology for domain adaptation of LLMs that treats data engineering as a debuggable engineering discipline rather than an ad-hoc process. The explicit analogy to software lifecycles and the release of open resources could enable reproducible, iterative improvement of specialized model capabilities and reduce reliance on indiscriminate data scaling.
major comments (2)
- Abstract: The assertion that 'each repair cycle producing consistent improvements across model scales and architectures' is load-bearing for the central claim that the mapping is 'precise and operative,' yet the abstract supplies no quantitative results, performance deltas, error analysis, or controls. Without these, the effectiveness of the debugging analogy cannot be assessed.
- Abstract: The claim that failures 'decompose into concept-level gaps and reasoning-chain breaks that can be traced back to specific deficiencies in the data' assumes the extracted structured representation captures the relevant causal structure of model behavior. No formal criterion, attribution method, or validation that this decomposition is unambiguous (rather than post-hoc) is provided, which is required for the analogy to hold.
minor comments (1)
- Abstract: The sixteen disciplines are referenced but not enumerated, and no concrete example of a structured knowledge unit, a benchmark item, or a single repair cycle is given; adding one would clarify the framework for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight opportunities to strengthen the abstract's support for the central claims. We address each point below and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: Abstract: The assertion that 'each repair cycle producing consistent improvements across model scales and architectures' is load-bearing for the central claim that the mapping is 'precise and operative,' yet the abstract supplies no quantitative results, performance deltas, error analysis, or controls. Without these, the effectiveness of the debugging analogy cannot be assessed.
Authors: We agree that the abstract would benefit from including concise quantitative indicators to allow readers to assess the claims directly. The full manuscript reports these results in the experimental sections, including performance deltas across model scales and architectures, error breakdowns, and controls confirming no degradation in general capabilities. We will revise the abstract to incorporate a brief summary of these findings. revision: yes
-
Referee: Abstract: The claim that failures 'decompose into concept-level gaps and reasoning-chain breaks that can be traced back to specific deficiencies in the data' assumes the extracted structured representation captures the relevant causal structure of model behavior. No formal criterion, attribution method, or validation that this decomposition is unambiguous (rather than post-hoc) is provided, which is required for the analogy to hold.
Authors: The manuscript formalizes the decomposition criteria, attribution method, and validation in the 'Programming with Data' framework section, using mismatches against the structured knowledge representation to identify gaps and breaks, with empirical support from repair success and generalization across models. We will revise the abstract to include a short reference to this formalization and validation to address the presentation concern. revision: partial
Circularity Check
No circularity: conceptual mapping introduced independently and demonstrated empirically
full rationale
The paper defines a principle called 'Programming with Data' by positing that a structured knowledge representation extracted from the source corpus can serve as the shared foundation for training data and evaluation, thereby mapping the data-engineering lifecycle onto the software development lifecycle. This mapping is presented as a formalizable principle that is then instantiated across sixteen disciplines, with open resources released to support the claim of traceable, repairable failures. No equations, fitted parameters, or self-citations appear in the provided text that would reduce the central claims to prior inputs by construction. The decomposition of failures into concept-level gaps and reasoning-chain breaks is asserted as a consequence of the correspondence rather than defined into existence, and the reported improvements are framed as empirical outcomes rather than tautological results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A structured knowledge representation can be reliably extracted from the source corpus to serve as shared foundation for both training data and evaluation
invented entities (1)
-
Programming with Data framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Can we trust the evaluation on chatgpt? arXiv preprint arXiv:2303.12767, 2023
Rachith Aiyappa, Jisun An, Haewoon Kwak, and Yong-Yeol Ahn. Can we trust the evaluation on chatgpt? arXiv preprint arXiv:2303.12767, 2023
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
Addison-Wesley Professional, 2003
Kent Beck.Test-driven development: by example. Addison-Wesley Professional, 2003
2003
-
[4]
Pearson Education, 1995
Frederick P Brooks Jr.The mythical man-month: essays on software engineering. Pearson Education, 1995
1995
-
[5]
Self-play fine-tuning converts weak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. InInternational Conference on Machine Learning, pages 6621–6642. PMLR, 2024
2024
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
Investigating data contami- nation in modern benchmarks for large language models
Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Gerstein, and Arman Cohan. Investigating data contami- nation in modern benchmarks for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8706–8719, 2024
2024
-
[8]
Academics can contribute to domain-specialized language models
Mark Dredze, Genta Indra Winata, Prabhanjan Kambadur, Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravol- ski, David S Rosenberg, and Sebastian Gehrmann. Academics can contribute to domain-specialized language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5100–5110, 2024
2024
-
[9]
Time travel in LLMs: Tracing data contamination in large language models
Shahriar Golchin and Mihai Surdeanu. Time travel in LLMs: Tracing data contamination in large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=2Rwq6c3tvr
2024
-
[10]
arXiv preprint arXiv:2305.15717 , year =
Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms.arXiv preprint arXiv:2305.15717, 2023
-
[11]
Reinforced Self-Training (ReST) for Language Modeling
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023
work page Pith review arXiv 2023
-
[12]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations,
-
[14]
URLhttps://openreview.net/forum?id=d7KBjmI3GmQ
-
[15]
Unnatural instructions: Tuning language mod- els with (almost) no human labor
Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language mod- els with (almost) no human labor. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14409–14428, 2023
2023
-
[16]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data.arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=IkmD3fKBPQ. 22 Programming with Data
2024
-
[18]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in Neural Information Processing Systems, 36:62991–63010, 2023
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Yao Fu, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in Neural Information Processing Systems, 36:62991–63010, 2023
2023
-
[19]
Dynabench: Rethinking benchmarking in nlp
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. Dynabench: Rethinking benchmarking in nlp. In Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies, pages 4110–...
2021
-
[20]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[21]
Evaluating language models as synthetic data generators
Seungone Kim, Juyoung Suk, Xiang Yue, Vijay Viswanathan, Seongyun Lee, Yizhong Wang, Kiril Gashteovski, Carolin Lawrence, Sean Welleck, and Graham Neubig. Evaluating language models as synthetic data generators. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6385–6403, 2025
2025
-
[22]
Longform: Effective instruction tuning with reverse instructions
Abdullatif Köksal, Timo Schick, Anna Korhonen, and Hinrich Schütze. Longform: Effective instruction tuning with reverse instructions. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7056–7078, 2024
2024
-
[23]
Datainf: Efficiently estimating data influence in loRA-tuned LLMs and diffusion models
Yongchan Kwon, Eric Wu, Kevin Wu, and James Zou. Datainf: Efficiently estimating data influence in loRA-tuned LLMs and diffusion models. InThe Twelfth International Conference on Learning Representations,
-
[24]
URLhttps://openreview.net/forum?id=9m02ib92Wz
-
[25]
RLAIF: Scaling reinforcement learning from human feedback with AI feedback, 2024
Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. RLAIF: Scaling reinforcement learning from human feedback with AI feedback, 2024. URLhttps://openreview.net/forum?id=AAxIs3D2ZZ
2024
-
[26]
Alpacaeval: An automatic evaluator of instruction-following models, 2023
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models, 2023
2023
-
[27]
Textbooks Are All You Need II: phi-1.5 technical report
Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. Textbooks are all you need ii: phi-1.5 technical report.arXiv preprint arXiv:2309.05463, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
Hao Liang, Xiaochen Ma, Zhou Liu, Zhen Hao Wong, Zhengyang Zhao, Zimo Meng, Runming He, Chengyu Shen, Qifeng Cai, Zhaoyang Han, et al. Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai.arXiv preprint arXiv:2512.16676, 2025
-
[29]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review arXiv 2022
-
[30]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
2022
-
[31]
Domain specialization as the key to make large language models disruptive: A comprehensive survey.ACM Computing Surveys, 58(3):1–39, 2025
Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, et al. Domain specialization as the key to make large language models disruptive: A comprehensive survey.ACM Computing Surveys, 58(3):1–39, 2025
2025
-
[32]
Explainaboard: An explainable leaderboard for nlp
Pengfei Liu, Jinlan Fu, Yang Xiao, Weizhe Yuan, Shuaichen Chang, Junqi Dai, Yixin Liu, Zihuiwen Ye, and Graham Neubig. Explainaboard: An explainable leaderboard for nlp. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations...
2021
-
[33]
Easy dataset: A unified and extensible framework for synthesizing llm fine-tuning data from unstructured documents
Ziyang Miao, Qiyu Sun, Jingyuan Wang, Yuchen Gong, Yaowei Zheng, Shiqi Li, and Richong Zhang. Easy dataset: A unified and extensible framework for synthesizing llm fine-tuning data from unstructured documents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 960–968, 2025. 23 Programmin...
2025
-
[34]
Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of gpt-4.arXiv preprint arXiv:2306.02707, 2023
-
[35]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[36]
Adaptive testing and debugging of nlp models
Marco Tulio Ribeiro and Scott Lundberg. Adaptive testing and debugging of nlp models. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers), pages 3253–3267, 2022
2022
-
[37]
Managing the development of large software systems: concepts and techniques
Winston W Royce. Managing the development of large software systems: concepts and techniques. In Proceedings of the 9th international conference on Software Engineering, pages 328–338, 1987
1987
-
[38]
Brown, and et al
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, and et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview. net/forum?id=uyTL5Bvosj. Featured Certification
2023
-
[39]
Improving data efficiency for LLM reinforcement fine-tuning through difficulty-targeted online data selection and rollout replay
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for LLM reinforcement fine-tuning through difficulty-targeted online data selection and rollout replay. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=uwUkETPIJN
2025
-
[40]
Alpaca: A strong, replicable instruction-following model.Stanford Center for Research on Foundation Models
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpaca: A strong, replicable instruction-following model.Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7, 2023
2023
-
[41]
Language models as continuous self-evolving data engineers
Peidong Wang, Ming Wang, Zhiming Ma, Xiaocui Yang, Shi Feng, Daling Wang, Yifei Zhang, and Kaisong Song. Language models as continuous self-evolving data engineers. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18108–18127, 2025
2025
-
[42]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
2023
-
[43]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions.arXiv preprint arXiv:2304.12244, 2023
work page internal anchor Pith review arXiv 2023
-
[44]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[45]
STar: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STar: Bootstrapping reasoning with reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URLhttps://openreview.net/forum?id=_3ELRdg2sgI
2022
-
[46]
arXiv preprint arXiv:2502.05605 , year =
Yongcheng Zeng, Xinyu Cui, Xuanfa Jin, Guoqing Liu, Zexu Sun, Dong Li, Ning Yang, Jianye Hao, Haifeng Zhang, and Jun Wang. Evolving llms’ self-refinement capability via iterative preference optimization.arXiv preprint arXiv:2502.05605, 2025
-
[47]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review arXiv 2025
-
[48]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[49]
Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36: 55006–55021, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36: 55006–55021, 2023. 24 Programming with Data
2023
-
[50]
Don’t make your llm an evaluation benchmark cheater
Kun Zhou, Yutao Zhu, Zhipeng Chen, Wentong Chen, Wayne Xin Zhao, Xu Chen, Yankai Lin, Ji-Rong Wen, and Jiawei Han. Don’t make your llm an evaluation benchmark cheater.arXiv preprint arXiv:2311.01964, 2023. 25 Programming with Data Appendix A Corpus Curation A.1 Document classification prompt Document Classification & Curation Judge Role.You are aScientifi...
-
[51]
Adapt extraction logic to fit the domain’s reasoning style
Domain Analysis.Determine the domain of the text (e.g., Legal Argument, Chemical Reaction, Medical Diagnosis, Historical Sequence). Adapt extraction logic to fit the domain’s reasoning style. 2.Chain Extraction.Identify distinct, multi-step processes or logical arguments: •Causal chains: A causes B, which causes C. •Procedural chains: Step 1, then Step 2,...
-
[52]
Every step must have a direct connection to the next
Validation.Ensure the chain is continuous. Every step must have a direct connection to the next. Do not skip intermediate steps mentioned in the text
-
[53]
Water is H2O
Narrative Synthesis.For each chain, write a paragraph-length summary explaining the mechanism or logic behind it. 5.Step-by-Step Breakdown.List the exact sequence of nodes in text format. Key Constraints •Strict Logic: Every step must connect directly to the next. • No Disconnected Facts: Do not list static facts (e.g., “Water is H2O”). Only extract flows...
-
[54]
All chains must be processed with equal attention
Process Chains.Iterate through every chain_id in the input. All chains must be processed with equal attention
-
[55]
causes”, “is followed by
Sliding Window Decomposition.For every adjacent pair of steps (Step[i] andStep[i+1]), generate one Factual Statement. Example chain: A→B→C Target output: Statement(A→B)ANDStatement(B→C). 3.Formulate the Statement.Each statement must contain: •Subject: The concept or entity inStep[i]. •Object: The concept or entity inStep[i+1]. • Predicate: A specific verb...
-
[56]
It expands
Contextualization.If a step contains a pronoun or vague reference (e.g., “It expands”), replace it with the specific noun based on preceding steps (e.g., “The lung expands”). Both Subject and Object must be understandable in isolation. Key Constraints •Atomicity: Each statement must describe exactly one logical step. • Strict Adjacency: Only link immediat...
-
[57]
Collect every unique term
Term Collection.Scan all subject andobject fields in the L2 statements. Collect every unique term
-
[58]
The defendant
Deduplication and Canonicalization.Merge lexical variations into a single canonical entry (e.g., “The defendant” and “Defendant party” → “Defendant”). Choose the most standard, professional name for the given domain
-
[59]
The definition must fit the context of the source statements
Context-Aware Definition.Provide a concise definition (1–2 sentences) for each concept. The definition must fit the context of the source statements. For example, if the domain is Law, define “Bond” as a financial instrument, not a chemical connection. Use the predicate and source_quotefields in L2 as context clues
-
[60]
concept_id
Typing.Assign a category type relevant to the domain (e.g., Legal Entity, Chemical Element, Physiological Structure, Abstract Concept). 5.Traceability Annotation.For each concept, record: •parent_statement_ids : All statement_id values from input statements where this term appears as subject or object. •CID: All unique CID values from the corresponding so...
-
[61]
Total questions MUST reach or exceed{MAX_QUESTIONS}
Question Distribution Generate approximately{SINGLE_CHOICE_RATIO}% single-choice and the rest multiple-choice ques- tions. Total questions MUST reach or exceed{MAX_QUESTIONS}
-
[62]
What is the primary function of the diaphragm?
Single-Choice Question Construction • Pick one L2 statement (Subject→Predicate→Object). • Use the Subject as the question stem. • Correct answer: the actual Object/Predicate combination. • Distractors (3): extract from other unrelated L2 statements or generate plausible alternatives. • Example: “What is the primary function of the diaphragm?” Options: A. ...
-
[63]
Which of the following are correct about [the concept]? (Select all that apply)
Multiple-Choice Question Construction • Pick one L1 concept as the core topic. • Find 2–4 related L2 statements involving this concept. • Question stem: “Which of the following are correct about [the concept]? (Select all that apply)”. • Correct options: real L2 facts (2–3 correct answers). • Distractors: slightly modified incorrect statements. • Answer f...
-
[64]
If {MAX_QUESTIONS} is large, generate multiple questions per statement using different angles
Coverage Requirement Cover at least 70% of the provided L2 statements. If {MAX_QUESTIONS} is large, generate multiple questions per statement using different angles
-
[65]
Avoid mechanical JSON-to-sentence conversion
Natural Language Write questions in fluent, educational language. Avoid mechanical JSON-to-sentence conversion
-
[66]
stmt-XXX
Explanation (CRITICAL) Every question MUST include a detailed explanation in the metadata, explaining why the answer is correct and why distractors are wrong. IMPORTANT - Explanation Quality Rules: • Write explanations in natural, educational language using domain knowledge. • DO NOT reference internal identifiers like “stmt-XXX” or “concept-XXX” in expla...
-
[67]
MANDATORY: Cover at least 70–90% of the provided L2 statements
Coverage Requirement (CRITICAL) You MUST generate questions from as many L2 statements as possible. MANDATORY: Cover at least 70–90% of the provided L2 statements. If {MAX_QUESTIONS} is large, generate 2–3 questions per statement using different question styles to ensure comprehensive coverage. IMPORTANT: The total number of questions MUST reach or exceed...
-
[68]
Atomic Focus Each QA pair must strictly focus on ONE L2 statement (Subject→Predicate→Object)
-
[69]
Q: What does Diaphragm do? A: The Diaphragm contracts increasing volume
Natural Language Refinement (Critical) Do NOT simply reformat the JSON into a sentence. • Bad Example: “Q: What does Diaphragm do? A: The Diaphragm contracts increasing volume.” (Robotic) 42 Programming with Data • Good Example: “Q: What is the immediate mechanical effect of diaphragm contraction? A: When the diaphragm contracts, it flattens out, which di...
-
[70]
It increases pressure
Contextualization If the L2 statement uses a pronoun (e.g., “It increases pressure”), replace “It” with the specific noun in the Question. Ensure the Question provides enough context to be unambiguous
-
[71]
Define X in the context of
Variety Use different question styles to maximize coverage: •Definition: “Define X in the context of...” •Function: “What is the role of X?” •Mechanistic: “How does X lead to Y?” •True/False explanation: “Is it true that X causes Y? Explain why.” •Comparison: “What is the difference between X and Y?” •Application: “In what scenario would X occur?” Output ...
-
[72]
Total ques- 43 Programming with Data tions MUST reach or exceed{MAX_QUESTIONS}
Statement Distribution Generate approximately{TRUE_RATIO}% true statements and the rest false statements. Total ques- 43 Programming with Data tions MUST reach or exceed{MAX_QUESTIONS}
-
[73]
The diaphragm contracts to increase thoracic volume
True Statement Construction • Base on actual L2 statements (Subject→Predicate→Object). • Rephrase in natural language while maintaining factual accuracy. • Example: “The diaphragm contracts to increase thoracic volume.” (True)
-
[74]
The diaphragm contracts to decrease thoracic volume
False Statement Construction • Modify real L2 statements to create plausible but incorrect statements. • Change relationships, add misconceptions, or invert facts. • Ensure false statements are educationally valuable. • Example: “The diaphragm contracts to decrease thoracic volume.” (False)
-
[75]
Generate multiple variations per statement when needed
Coverage Requirement Cover at least 70% of the provided L2 statements. Generate multiple variations per statement when needed
-
[76]
Avoid obvious giveaways of truth/falsity
Natural Language Write statements in fluent, natural language. Avoid obvious giveaways of truth/falsity
-
[77]
statement
Explanation (CRITICAL) Every statement MUST include a detailed explanation of why it is true or false. IMPORTANT - Explanation Quality Rules: • Explain using domain knowledge and scientific reasoning. • For TRUE: Explain why the statement is correct. • For FALSE: Explain what the correct fact is and why the statement is wrong. • Use natural, educational l...
-
[78]
Focus on causal relationships and synthesis across multiple steps
Depth and Complexity The question must testdeep understandingof the reasoning process. Focus on causal relationships and synthesis across multiple steps. Avoid simple memorization
-
[79]
why” a step follows another or “how
Question Type (Priority Order) • Priority 1 – Process Reasoning: Questions about “why” a step follows another or “how” a mechanism works. •Priority 2 – Causal Analysis: Cause-and-effect relationships. •Priority 3 – Critical Understanding: Significance, implications, or principles. •Priority 4 – Application: Applying reasoning to a new but related scenario
-
[80]
Question Length and Detail Questions MUST be comprehensive (typically 40–100 words). Include specific context and use direct quotations from the steps or summary.CRITICAL:When referencing specific concepts, you MUST include the complete content, not vague references
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.