Recognition: unknown
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Pith reviewed 2026-05-08 04:05 UTC · model grok-4.3
The pith
Factual knowledge in large language models scales log-linearly with total parameter count, enabling estimates of closed-source model sizes from probe accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incompressible Knowledge Probes isolate facts that cannot be obtained by reasoning from other knowledge and therefore require dedicated parameter storage. Accuracy on these probes maps log-linearly to total parameter count across open models, with the fit holding across vendors and generations. For mixture-of-experts models total parameters predict knowledge capacity much more strongly than active parameters. The same mapping applied to closed models yields size estimates, which are lower bounds when safety tuning causes refusals on known facts.
What carries the argument
Incompressible Knowledge Probes, a fixed set of 1,400 factual questions spanning seven obscurity tiers that measure the minimum weights required to store non-derivable facts.
Load-bearing premise
The chosen questions measure knowledge that cannot be derived through reasoning and that architectural changes cannot pack into fewer parameters than the observed relationship assumes.
What would settle it
Measure IKP accuracy on a newly disclosed model whose parameter count was previously unknown and check whether the observed accuracy falls inside the calibrated log-linear prediction band.
Figures












read the original abstract
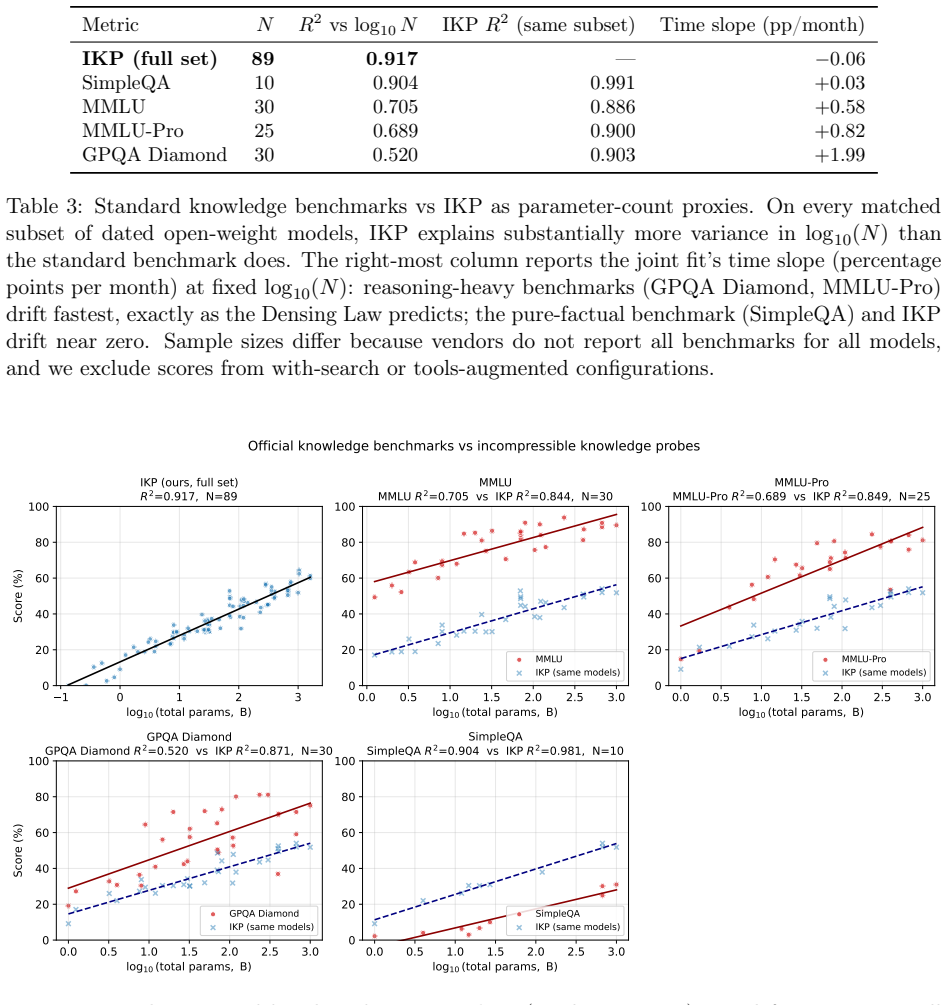
Closed-source frontier labs do not disclose parameter counts, and the standard alternative -- inference economics -- carries $2\times$+ uncertainty from hardware, batching, and serving-stack assumptions external to the model. We exploit a tighter intrinsic bound: storing $F$ facts requires at least $F/$(bits per parameter) weights, so measuring how much a model \emph{knows} lower-bounds how many parameters it \emph{has}. We introduce \textbf{Incompressible Knowledge Probes (IKPs)}, a benchmark of 1{,}400 factual questions spanning 7 tiers of obscurity, designed to isolate knowledge that cannot be derived by reasoning or compressed by architectural improvements. We calibrate a log-linear mapping from IKP accuracy to parameter count on 89 open-weight models (135M--1,600B) spanning 19 vendors, achieving $R^2 = 0.917$; leave-one-out cross-validation confirms generalization (median fold error $1.59\times$, $68.5\%$ within $2\times$ and $87.6\%$ within $3\times$). For Mixture-of-Experts models, total parameters predict knowledge ($R^2 = 0.79$) far better than active parameters ($R^2 = 0.51$). We evaluate 188 models from 27 vendors and estimate effective knowledge capacity for all major proprietary frontier models; for heavily safety-tuned models the estimates are lower bounds, since refusal policy can hide tens of percentage points of "refused but known" capacity. The widely-reported saturation of reasoning benchmarks does not imply the end of scaling. Procedural capability compresses under the "Densing Law," but across 96 dated open-weight models the IKP time coefficient is $-0.0010$/month (95\% CI $[-0.0031, +0.0008]$) -- indistinguishable from zero, and rejecting the Densing prediction of $+0.0117$/month at $p < 10^{-15}$. Factual capacity continues to scale log-linearly with parameters across generations and across vendors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Incompressible Knowledge Probes (IKPs), a benchmark of 1,400 factual questions across 7 tiers of obscurity, to lower-bound the parameter counts of black-box LLMs via their factual knowledge capacity. A log-linear mapping from IKP accuracy to parameter count is calibrated on 89 open-weight models (135M–1.6T parameters, 19 vendors) yielding R²=0.917; leave-one-out cross-validation reports median error 1.59×. The mapping is applied to estimate effective capacity for 188 models from 27 vendors (including proprietary frontier models, with safety-tuned estimates noted as lower bounds). For MoE models, total parameters predict IKP accuracy better than active parameters. Across 96 dated open models, the IKP time trend after controlling for size is statistically indistinguishable from zero, rejecting a positive “Densing Law” prediction at p<10^{-15}.
Significance. If the central mapping holds, the work supplies a reproducible, inference-cost-independent method for bounding black-box model sizes and demonstrates that factual capacity continues to scale log-linearly with parameters even as reasoning benchmarks saturate. The high R², LOOCV results, MoE total-vs-active comparison, and falsification of the Densing prediction on open models are concrete strengths. The approach could inform scaling-law research and transparency discussions, though its utility for proprietary models depends on the untested transportability assumption.
major comments (3)
- [Abstract / calibration paragraph] Abstract and calibration section: The log-linear mapping is fitted exclusively on open-weight models and then applied to closed proprietary models; no sensitivity analysis or bounds are provided on how much the fitted coefficients could shift due to differences in pre-training data scale/quality, post-training (RLHF/safety), or architectural tweaks. This assumption is load-bearing for all proprietary estimates.
- [IKP benchmark description] IKP construction and validation: The claim that the 1,400 questions isolate knowledge that cannot be derived by reasoning or compressed by architecture is central to the “incompressible” premise, yet the manuscript provides insufficient detail on question sourcing, exclusion rules, tier construction, and error analysis (e.g., breakdown of accuracy by obscurity tier or model size). These gaps directly affect the soundness of the R²=0.917 fit and LOOCV results.
- [Scaling and time-trend results] Time-trend analysis: The reported IKP time coefficient of −0.0010/month (95% CI [−0.0031, +0.0008]) on 96 dated open-weight models rejects the Densing prediction, but the selection criteria for these 96 models, the exact parameterization of the size control, and any vendor or architecture clustering are not specified, making the p<10^{-15} claim difficult to evaluate.
minor comments (2)
- [Abstract] The abstract states “Factual capacity continues to scale log-linearly with parameters across generations and across vendors” but does not clarify whether this is a within-model-size or across-size statement; a brief clarification would improve readability.
- [Results tables/figures] Table or figure reporting the 89-model calibration should include per-vendor or per-size-bin residuals to allow readers to assess whether the fit is uniform or driven by the largest models.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each of the major points raised below and indicate the revisions we will make to improve clarity and transparency.
read point-by-point responses
-
Referee: [Abstract / calibration paragraph] Abstract and calibration section: The log-linear mapping is fitted exclusively on open-weight models and then applied to closed proprietary models; no sensitivity analysis or bounds are provided on how much the fitted coefficients could shift due to differences in pre-training data scale/quality, post-training (RLHF/safety), or architectural tweaks. This assumption is load-bearing for all proprietary estimates.
Authors: We agree that the assumption of transportability is central and load-bearing. The manuscript already qualifies estimates for safety-tuned models as lower bounds. In revision, we will add a new subsection in the calibration section providing sensitivity checks using subsets of the open models (e.g., comparing base vs. fine-tuned variants and different vendors) to bound potential shifts. We will also discuss qualitative factors that could affect the mapping for proprietary models. Full quantitative bounds require internal training data unavailable to us. revision: partial
-
Referee: [IKP benchmark description] IKP construction and validation: The claim that the 1,400 questions isolate knowledge that cannot be derived by reasoning or compressed by architecture is central to the “incompressible” premise, yet the manuscript provides insufficient detail on question sourcing, exclusion rules, tier construction, and error analysis (e.g., breakdown of accuracy by obscurity tier or model size). These gaps directly affect the soundness of the R²=0.917 fit and LOOCV results.
Authors: We appreciate this feedback on the need for greater detail. The full paper describes sourcing from public knowledge bases and web archives, with manual review to ensure questions require specific factual recall rather than reasoning. Exclusion rules remove questions solvable via common knowledge or logic. Tiers are constructed by obscurity measured via search hit counts and expert ratings. We will expand the IKP section with these details, include per-tier accuracy tables stratified by model size, and report error analysis to better support the reported fit statistics. revision: yes
-
Referee: [Scaling and time-trend results] Time-trend analysis: The reported IKP time coefficient of −0.0010/month (95% CI [−0.0031, +0.0008]) on 96 dated open-weight models rejects the Densing prediction, but the selection criteria for these 96 models, the exact parameterization of the size control, and any vendor or architecture clustering are not specified, making the p<10^{-15} claim difficult to evaluate.
Authors: The 96 models comprise all open-weight models in our calibration set with publicly documented release dates. The regression controls for log(parameter count) as the size variable and uses clustered standard errors by vendor to account for potential non-independence. We will add an appendix detailing the exact model list, the regression equation (IKP accuracy ~ log(params) + time), and robustness checks including architecture fixed effects. This will allow direct evaluation of the statistical claim. revision: yes
Circularity Check
No significant circularity; empirical calibration and external validation are self-contained
full rationale
The paper calibrates a log-linear regression from measured IKP accuracy to known parameter counts on 89 open-weight models (reporting R²=0.917 and LOOCV error), then applies the fitted mapping to estimate closed models under an explicit transportability assumption. This is standard supervised regression with held-out validation rather than any self-definitional loop, fitted-input-renamed-as-prediction, or self-citation that bears the central load. The time-trend test fits a coefficient on dated open models and rejects an external Densing prediction; no equations reduce to their own inputs by construction, no uniqueness theorems are imported from the authors' prior work, and no ansatz is smuggled via citation. The derivation rests on observable data and falsifiable assumptions external to the paper itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- log-linear mapping coefficients
axioms (2)
- domain assumption Storing F facts requires at least F/(bits per parameter) weights
- ad hoc to paper IKP questions isolate knowledge that cannot be derived by reasoning or compressed by architecture
invented entities (1)
-
Incompressible Knowledge Probes
no independent evidence
Forward citations
Cited by 3 Pith papers
-
AssayBench: An Assay-Level Virtual Cell Benchmark for LLMs and Agents
AssayBench is a new gene-ranking benchmark for phenotypic CRISPR screens that shows zero-shot generalist LLMs outperform both biology-specific LLMs and trainable baselines on adjusted nDCG.
-
The Grounding Gap: How LLMs Anchor the Meaning of Abstract Concepts Differently from Humans
LLMs show a grounding gap with humans on abstract concepts, with property-generation correlations at most r=0.37 versus human-to-human r>0.9, though larger models align better on explicit rating tasks and internal SAE...
-
Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs
BLF achieves state-of-the-art binary forecasting on ForecastBench by using linguistic belief states updated in tool-use loops, hierarchical multi-trial logit averaging, and hierarchical Platt scaling calibration.
Reference graph
Works this paper leans on
-
[1]
Sanket Badhe, Deep Shah, and Nehal Kathrotia. Long-tail knowledge in large language models: Taxonomy, mechanisms, interventions and implications.arXiv preprint arXiv:2602.16201,
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review arXiv
-
[3]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
1901
-
[4]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek-AI. DeepSeek-V2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[6]
Estimating training compute of frontier ai models
Epoch AI. Estimating training compute of frontier ai models. 2024.https://epoch.ai/. William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39,
2024
-
[7]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295,
work page internal anchor Pith review arXiv
-
[8]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495,
2021
-
[9]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review arXiv
-
[10]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review arXiv 2001
-
[11]
Pingzhi Li, Morris Yu-Chao Huang, Zhen Tan, Qingquan Song, Jie Peng, Kai Zou, Yu Cheng, Kaidi Xu, and Tianlong Chen. Leave it to the experts: Detecting knowledge distillation via MoE expert signatures.arXiv preprint arXiv:2510.16968,
-
[12]
Scaling laws for fact memorization of large language models
Xingyu Lu, Xiaonan Li, Qinyuan Cheng, Kai Ding, Xuanjing Huang, and Xipeng Qiu. Scaling laws for fact memorization of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024,
2024
-
[13]
arXiv preprint arXiv:2505.24832 , year =
John X. Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G. Edward Suh, Alexander M. Rush, Kamalika Chaudhuri, and Saeed Mahloujifar. How much do language models memorize? arXiv preprint arXiv:2505.24832,
-
[14]
Scalable fingerprinting of large language models.arXiv preprint arXiv:2502.07760,
36 Anshul Nasery, Jonathan Hayase, Creston Brooks, Peiyao Sheng, Himanshu Tyagi, Pramod Viswanath, and Sewoong Oh. Scalable fingerprinting of large language models.arXiv preprint arXiv:2502.07760,
-
[15]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[16]
Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander H. Miller. Language models as knowledge bases? InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 2463–2473,
2019
-
[17]
How much knowledge can you pack into the parameters of a language model? InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 5418–5426,
Adam Roberts, Colin Raffel, and Noam Shazeer. How much knowledge can you pack into the parameters of a language model? InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 5418–5426,
2020
-
[18]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. 37 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- ...
work page internal anchor Pith review arXiv
-
[19]
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. OpenAI, 2024.https://openai.com/index/introducing-simpleqa/. An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei ...
work page internal anchor Pith review arXiv 2024
-
[20]
arXiv preprint arXiv:2509.23678 , year=
Guoliang Zhao, Yuhan Fu, Shuaipeng Li, Xingwu Sun, Ruobing Xie, An Wang, Weidong Han, Zhen Yang, Weixuan Sun, Yudong Zhang, Cheng-zhong Xu, Di Wang, and Jie Jiang. Towards a comprehensive scaling law of mixture-of-experts.arXiv preprint arXiv:2509.23678,
-
[21]
What is the capital of Norway?
38 A Probe Generation Methodology This appendix expands Section 4.1 with the full reproducibility detail of the IKP probe pipeline: tier definitions, per-corpus sampling procedures, quality filters with their drop rates, the final per-tier composition, verification procedure, and sample probes. A.1 Tier Definitions Each of the seven IKP tiers is defined b...
2014
-
[22]
In computer science
Probe template.The released format is two-part: In computer science, what is the research subfield ofName, and name one paper, system, institution, or co-author associated with their work? If you don’t know who this person is, say so. The CS scoping (“In computer science”) reduces cross-field name collisions for short / common names. The artifact requirem...
2015
-
[23]
Na Klang named after Na Klang
loses∼0.013inR 2 and widens the 90% PI factor from2.94×to3.21×, indicating that some hallucination penalty is justified. (iii) Beyondλ=−1.0, fits gradually degrade as the regression slope is increasingly driven by aggressive bluffers’ negative scores at hard tiers. (iv) The strict ordering STRONG>WEAK>REFUSAL>WRONG required for the 4-way researcher judge ...
1938
-
[24]
Vendor Model Acc. Raw T1 T2 T3 T4 T5 T6 T7 Google gemini-3.1-pro 0.811 0.822 0.00 0.01 0.01 0.02 0.03 0.03 0.23 gemini-3-flash-think 0.756 0.809 0.00 0.01 0.01 0.06 0.04 0.20 0.73 gemini-3-flash 0.745 0.804 0.00 0.00 0.02 0.05 0.06 0.21 0.58 gemini-3.1-flash-lite 0.610 0.706 0.00 0.01 0.03 0.09 0.17 0.46 0.67 gemini-2.5-pro 0.584 0.713 0.01 0.00 0.03 0.09...
2023
-
[25]
possible lineage
leaves ˆβ2 =−0.00051/month; (ii) excluding the five landmark models (n= 76)leaves ˆβ2 =−0.00018/month. InbothcasestheDensingpredictionisrejectedatp <10 −15. Check (iii) useslog 10(active_B)in place of total parameters and yields ˆβ2 = +0.0063/month— nominally significant but still only half the Densing target, and also rejecting the Densing prediction (p≈...
2026
-
[26]
I don’t have reli- able detailed memory and don’t want to fabricate specifics
is the first model to list real per-year challenges, with∼19 verified 2023 titles. Whatever change to the training pipeline absorbed Hackergame writeups happened in this∼9-month window, not gradually across the field; later models (Claude Opus 4.6/4.7, GPT-5.5, Kimi K2.6) inherited and extended this knowledge. 2.Knowing the meta-fact does not imply knowin...
2023
-
[27]
Geoffrey Ye Li
Claude Opus 4.6 correct— Heike Kamerlingh Onnes first produced liquid helium on July 10, 1908, at his laboratory in Leiden, the Netherlands. This achievement earned him widespread recogni- tion and contributed to his receiving the Nobel Prize in P... H.4 Tier Discrimination: Frontier-Only Knowledge (T6) T6 probes are only answered correctly by the largest...
1908
-
[28]
I Ethical Considerations This work estimates proprietary model sizes from public API access, which raises considerations for competitive intelligence and intellectual property. We note that: (1) parameter count is only one dimension of model capability, and our estimates are effective capacity (not literal architecture); (2) the method provides∼3.0×precis...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.