Recognition: no theorem link
AssayBench: An Assay-Level Virtual Cell Benchmark for LLMs and Agents
Pith reviewed 2026-05-12 04:43 UTC · model grok-4.3
The pith
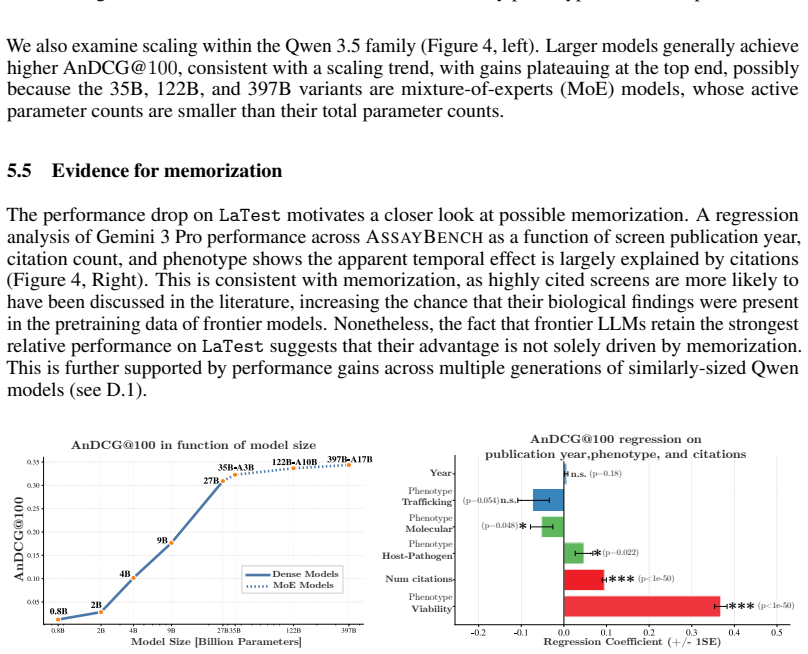
Zero-shot generalist LLMs outperform biology-specific models and baselines on a benchmark of 1,920 CRISPR screens for gene-rank prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AssayBench formulates phenotypic screen prediction as gene-rank prediction on 1,920 CRISPR assays and introduces adjusted nDCG to compare results across heterogeneous readouts. Zero-shot generalist LLMs exceed biology-specific LLMs and trainable baselines on this task; optimization techniques such as fine-tuning, ensembling, and prompt optimization raise scores further, yet all evaluated methods stay far from the empirically estimated ceiling.
What carries the argument
AssayBench, which converts each CRISPR screen into a gene-ranking problem scored by adjusted nDCG to enable consistent comparison across diverse phenotypic assays.
If this is right
- LLMs become a practical starting point for in-silico phenotypic screens that could guide drug-discovery workflows.
- AssayBench supplies a concrete, public yardstick for measuring incremental progress toward virtual-cell models.
- Optimization methods already known for language tasks transfer directly to this biological ranking setting.
- Continued improvement on the benchmark would narrow the gap between current models and the performance ceiling observed in the data.
Where Pith is reading between the lines
- If generalist models keep improving on AssayBench, they may reduce the number of preliminary wet-lab screens required before moving to targeted experiments.
- The benchmark could be extended to other perturbation modalities such as small-molecule or genetic screens once suitable public data become available.
- Success on gene ranking does not yet prove the model understands causal mechanisms, so follow-up work would need to test whether top-ranked genes actually produce the predicted phenotype in new contexts.
Load-bearing premise
That turning these 1,920 public CRISPR screens into gene-rank prediction tasks with adjusted nDCG gives a faithful stand-in for the full phenotypic-screening capability a working virtual cell would need.
What would settle it
A new, held-out CRISPR screen performed in an unseen cell type or condition where the genes ranked highest by the best AssayBench model show no measurable phenotypic effect when actually perturbed.
Figures





read the original abstract
Recent advances in machine learning and large-scale biological data collections have revived the prospect of building a virtual cell, a computational model of cellular behavior that could accelerate biological discovery. One of the most compelling promises of this vision is the ability to perform in silico phenotypic screens, in which a model predicts the effects of cellular perturbations in unseen biological contexts. This task combines heterogeneous textual inputs with diverse phenotypic outputs, making it particularly well-suited to LLMs and agentic systems. Yet, no standard benchmark currently exists for this task, as existing efforts focus on narrower molecular readouts that are only indirectly aligned with the phenotypic endpoints driving many real-world drug discovery workflows. In this work, we present AssayBench, a benchmark for phenotypic screen prediction, built from 1,920 publicly available CRISPR screens spanning five broad classes of cellular phenotypes. We formulate the screen prediction task as a gene rank prediction for each screen and introduce the adjusted nDCG, a continuous metric for comparing performance across heterogeneous assays. Our extensive evaluation shows that existing methods remain far from empirically estimated performance ceilings and zero-shot generalist LLMs outperform biology-specific LLMs and trainable baselines. Optimization techniques such as fine-tuning, ensembling, and prompt optimization can further improve LLM performance on this task. Overall, AssayBench offers a practical testbed for measuring progress toward in silico phenotypic screening and, more broadly, virtual cell models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AssayBench, a benchmark for phenotypic screen prediction in virtual cell models, constructed from 1,920 publicly available CRISPR screens spanning five phenotype classes. It formulates the task as per-assay gene ranking and introduces adjusted nDCG as the evaluation metric. Extensive experiments show that zero-shot generalist LLMs outperform biology-specific LLMs and trainable baselines on this task, with further gains possible via fine-tuning, ensembling, and prompt optimization, while all methods remain far from empirically estimated performance ceilings.
Significance. If the benchmark is shown to be a valid proxy, this work would provide a much-needed standardized testbed for in silico phenotypic screening, a key capability for virtual cell models in drug discovery. The use of public data, the introduction of adjusted nDCG for heterogeneous assays, and the clear performance ordering are strengths that could guide future LLM and agent development in biology. The empirical focus on phenotypic rather than molecular endpoints aligns well with real-world needs.
major comments (2)
- [Abstract] Abstract: The central claim that AssayBench offers a 'practical testbed for measuring progress toward in silico phenotypic screening' and virtual cell models rests on the assumption that gene-rank prediction with adjusted nDCG on these 1,920 CRISPR screens is a faithful proxy for the broader task of predicting perturbation effects in unseen contexts with heterogeneous phenotypic outputs. No validation, correlation analysis, or downstream utility study is provided to show that performance on this ranking task predicts real phenotypic screen outcomes.
- [Evaluation] Evaluation and Methods sections: The reported outperformance of zero-shot generalist LLMs and the performance gaps to ceilings cannot be fully assessed without explicit details on screen selection criteria, data splits to avoid leakage across the 1,920 assays, and the exact computation of adjusted nDCG (including any hyperparameters or post-processing). This makes it impossible to rule out post-hoc tuning or verify robustness of the ordering.
minor comments (2)
- [Abstract] The abstract introduces 'adjusted nDCG' without a one-sentence definition or reference, which reduces accessibility for readers outside information retrieval.
- A summary table listing the five phenotype classes, number of screens per class, and example endpoints would improve clarity on the benchmark's diversity.
Simulated Author's Rebuttal
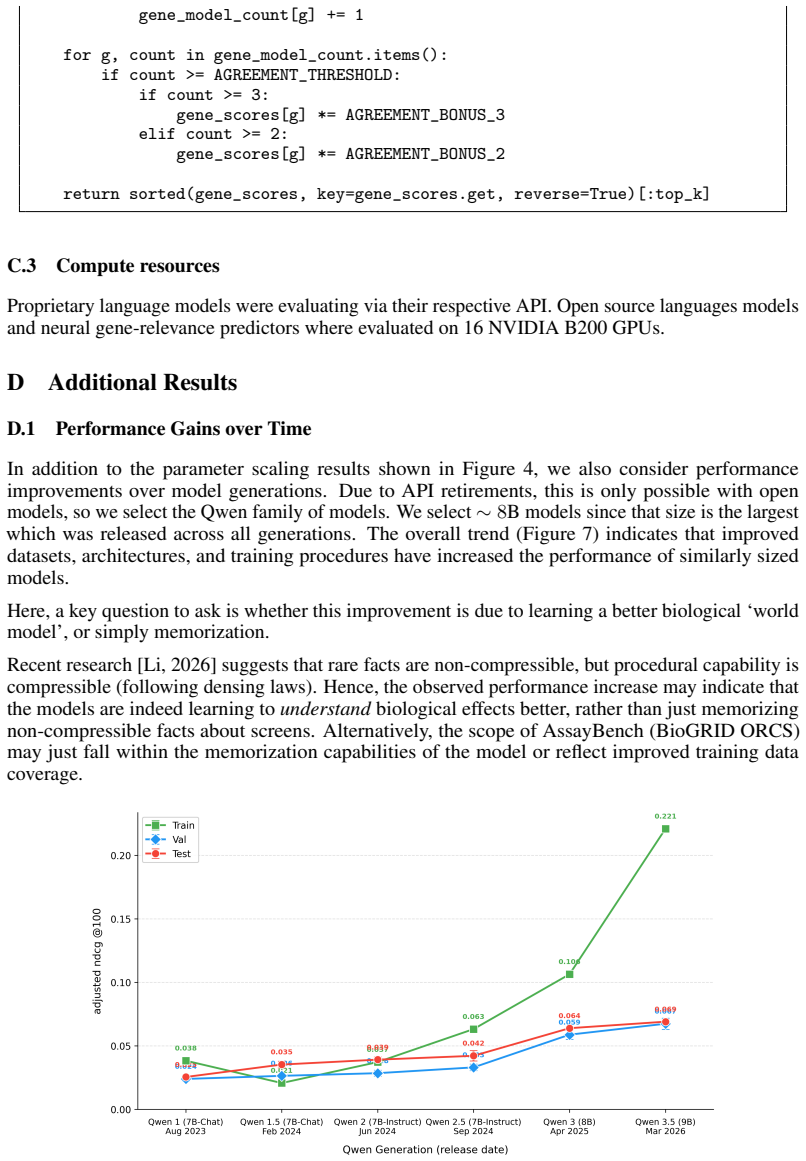
We thank the referee for their detailed and constructive comments on our manuscript. We have carefully considered each point and made revisions to improve clarity and address concerns regarding the benchmark's validity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that AssayBench offers a 'practical testbed for measuring progress toward in silico phenotypic screening' and virtual cell models rests on the assumption that gene-rank prediction with adjusted nDCG on these 1,920 CRISPR screens is a faithful proxy for the broader task of predicting perturbation effects in unseen contexts with heterogeneous phenotypic outputs. No validation, correlation analysis, or downstream utility study is provided to show that performance on this ranking task predicts real phenotypic screen outcomes.
Authors: We agree that a direct empirical validation linking performance on AssayBench to downstream real-world outcomes would strengthen the case for it as a proxy. Our work establishes AssayBench as a benchmark derived directly from 1,920 real phenotypic CRISPR screens, where the task is to rank genes according to their observed effects on the phenotype. This formulation captures the essence of in silico phenotypic screening. We have partially revised the manuscript by qualifying the language in the abstract and adding a new subsection in the Discussion that explicitly discusses the assumptions underlying the proxy, acknowledges the lack of correlation studies, and outlines plans for future work to validate against additional experimental data. revision: partial
-
Referee: [Evaluation] Evaluation and Methods sections: The reported outperformance of zero-shot generalist LLMs and the performance gaps to ceilings cannot be fully assessed without explicit details on screen selection criteria, data splits to avoid leakage across the 1,920 assays, and the exact computation of adjusted nDCG (including any hyperparameters or post-processing). This makes it impossible to rule out post-hoc tuning or verify robustness of the ordering.
Authors: We thank the referee for highlighting the need for greater transparency. We have revised the Methods and Evaluation sections to provide explicit details: screen selection criteria include requirements for sufficient statistical power (e.g., number of guides, replicates) and coverage across the five phenotype classes from public sources; data splits are performed at the assay level using stratified random partitioning with no shared genes or biological contexts between splits to prevent leakage; the adjusted nDCG formula is now fully specified with the adjustment term for varying assay lengths and relevance scores based on differential expression statistics, along with all hyperparameters and post-processing steps. An appendix with implementation details and additional ablation studies has been added to verify the robustness. revision: yes
Circularity Check
No significant circularity: empirical benchmark on external public data with independent performance comparisons
full rationale
The paper defines AssayBench from 1,920 publicly available external CRISPR screens, formulates the task as gene-rank prediction, and introduces adjusted nDCG as a new metric for heterogeneous assays. Central claims consist of empirical comparisons showing zero-shot generalist LLMs outperforming biology-specific LLMs and trainable baselines on held-out screens, with further gains from fine-tuning, ensembling, and prompt optimization. No derivation reduces by construction to fitted internal parameters, self-citations, or tautological renaming; the evaluation is self-contained against external benchmarks and does not invoke uniqueness theorems or load-bearing prior results from the same authors to justify the core findings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transportation Research Record: Journal of the Transportation Research Board , number=
Theoretical maximum capacity as benchmark for empty vehicle redistribution in personal rapid transit , author=. Transportation Research Record: Journal of the Transportation Research Board , number=. 2010 , publisher=
work page 2010
-
[4]
Genome-wide single-cell perturbation screens with viperturb-seq
Alexandra Bradu, John D Blair, Isabella N Grabski, Isabella Mascio, Junsuk Lee, Cecilia McCormick, and Rahul Satija. Genome-wide single-cell perturbation screens with viperturb-seq. bioRxiv, pages 2026--02, 2026
work page 2026
-
[5]
How to build the virtual cell with artificial intelligence: Priorities and opportunities
Charlotte Bunne, Yusuf Roohani, Yanay Rosen, Ankit Gupta, Xikun Zhang, Marcel Roed, Theo Alexandrov, Mohammed AlQuraishi, Patricia Brennan, Daniel B Burkhardt, et al. How to build the virtual cell with artificial intelligence: Priorities and opportunities. Cell, 187 0 (25): 0 7045--7063, 2024
work page 2024
-
[6]
Rational design of synthetic proteins using a genome-scale crispr screen
Wells H Burrell, Simon J Mueller, Zharko Daniloski, P Duffy Doyle Jr, Anne B Rovsing, Christopher James, Max Drabkin, Chien-Yu Chou, Hei Yu Annika So, Lyla Katgara, et al. Rational design of synthetic proteins using a genome-scale crispr screen. bioRxiv, pages 2026--02, 2026
work page 2026
-
[7]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. In Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, pages 758--759, 2009
work page 2009
-
[8]
scgpt: toward building a foundation model for single-cell multi-omics using generative ai
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. scgpt: toward building a foundation model for single-cell multi-omics using generative ai. Nature methods, 21 0 (8): 0 1470--1480, 2024
work page 2024
-
[9]
Systematic discovery of crispr-boosted car t cell immunotherapies
Paul Datlinger, Eugenia V Pankevich, Cosmas D Arnold, Nicole Pranckevicius, Jenny Lin, Daria Romanovskaia, Moritz Schaefer, Francesco Piras, Anne-Christine Orts, Amelie Nemc, et al. Systematic discovery of crispr-boosted car t cell immunotherapies. Nature, 646 0 (8086): 0 963--972, 2025
work page 2025
-
[10]
A new era of intelligence with gemini 3, Nov 2025
Google. A new era of intelligence with gemini 3, Nov 2025. URL https://blog.google/products-and-platforms/products/gemini/gemini-3/
work page 2025
-
[11]
Biomni: A general-purpose biomedical ai agent
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent. biorxiv, 2025
work page 2025
-
[13]
Hyuncheol Jung, Pascal Devant, Carter Ching, Mineto Ota, Jennifer Hamilton, Zachary Steinhart, Wayne Ngo, Luis Sandoval, Jae Hyung Jung, Da Xu, et al. Virus-like particles enable targeted gene engineering and pooled crispr screening in primary human myeloid cells. bioRxiv, pages 2025--12, 2025
work page 2025
-
[15]
Russell Littman, Jacob Levine, Sepideh Maleki, Yongju Lee, Vladimir Ermakov, Lin Qiu, Alexander Wu, Kexin Huang, Romain Lopez, Gabriele Scalia, et al. Gene-embedding-based prediction and functional evaluation of perturbation expression responses with presage. bioRxiv, pages 2025--06, 2025
work page 2025
-
[18]
Rose Oughtred, Jennifer Rust, Christie Chang, Bobby-Joe Breitkreutz, Chris Stark, Andrew Willems, Lorrie Boucher, Genie Leung, Nadine Kolas, Frederick Zhang, et al. The biogrid database: A comprehensive biomedical resource of curated protein, genetic, and chemical interactions. Protein Science, 30 0 (1): 0 187--200, 2021
work page 2021
-
[19]
scperturb: harmonized single-cell perturbation data
Stefan Peidli, Tessa D Green, Ciyue Shen, Torsten Gross, Joseph Min, Samuele Garda, Bo Yuan, Linus J Schumacher, Jake P Taylor-King, Debora S Marks, et al. scperturb: harmonized single-cell perturbation data. Nature Methods, 21 0 (3): 0 531--540, 2024
work page 2024
-
[21]
Disentanglement of single-cell data with biolord
Zoe Piran, Niv Cohen, Yedid Hoshen, and Mor Nitzan. Disentanglement of single-cell data with biolord. Nature Biotechnology, 42 0 (11): 0 1678--1683, 2024
work page 2024
-
[22]
Qwen3.5 : Towards native multimodal agents, February 2026
Qwen Team . Qwen3.5 : Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
work page 2026
-
[23]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First conference on language modeling, 2024
work page 2024
-
[24]
Mapping information-rich genotype-phenotype landscapes with genome-scale perturb-seq
Joseph M Replogle, Reuben A Saunders, Angela N Pogson, Jeffrey A Hussmann, Alexander Lenail, Alina Guna, Lauren Mascibroda, Eric J Wagner, Karen Adelman, Gila Lithwick-Yanai, et al. Mapping information-rich genotype-phenotype landscapes with genome-scale perturb-seq. Cell, 185 0 (14): 0 2559--2575, 2022
work page 2022
-
[25]
Scaling large language models for next-generation single-cell analysis
Syed Asad Rizvi, Daniel Levine, Aakash Patel, Shiyang Zhang, Eric Wang, Curtis Jamison Perry, Ivan Vrkic, Nicole Mayerli Constante, Zirui Fu, Sizhuang He, et al. Scaling large language models for next-generation single-cell analysis. BioRxiv, pages 2025--04, 2026
work page 2025
-
[26]
Predicting transcriptional outcomes of novel multigene perturbations with gears
Yusuf Roohani, Kexin Huang, and Jure Leskovec. Predicting transcriptional outcomes of novel multigene perturbations with gears. Nature Biotechnology, 42 0 (6): 0 927--935, 2024
work page 2024
-
[27]
Virtual cell challenge: Toward a turing test for the virtual cell
Yusuf H Roohani, Tony J Hua, Po-Yuan Tung, Lexi R Bounds, Feiqiao B Yu, Alexander Dobin, Noam Teyssier, Abhinav Adduri, Alden Woodrow, Brian S Plosky, et al. Virtual cell challenge: Toward a turing test for the virtual cell. Cell, 188 0 (13): 0 3370--3374, 2025
work page 2025
-
[29]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve
work page 2025
-
[31]
Steven Song, Abdalla Abdrabou, Asmita Dabholkar, Kastan Day, Pavan Dharmoju, Jason Perera, Volodymyr Kindratenko, and Aly Khan. Virtual crispr: Can llms predict crispr screen results? In Proceedings of the 24th Workshop on Biomedical Language Processing, pages 354--364, 2025
work page 2025
-
[32]
Rxrx1: A dataset for evaluating experimental batch correction methods
Maciej Sypetkowski, Morteza Rezanejad, Saber Saberian, Oren Kraus, John Urbanik, James Taylor, Ben Mabey, Mason Victors, Jason Yosinski, Alborz Rezazadeh Sereshkeh, et al. Rxrx1: A dataset for evaluating experimental batch correction methods. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4285--4294, 2023
work page 2023
-
[33]
Phenotypic drug discovery: recent successes, lessons learned and new directions
Fabien Vincent, Arsenio Nueda, Jonathan Lee, Monica Schenone, Marco Prunotto, and Mark Mercola. Phenotypic drug discovery: recent successes, lessons learned and new directions. Nature Reviews Drug Discovery, 21 0 (12): 0 899--914, 2022
work page 2022
-
[34]
Genetic screens in human cells using the crispr-cas9 system
Tim Wang, Jenny J Wei, David M Sabatini, and Eric S Lander. Genetic screens in human cells using the crispr-cas9 system. Science, 343 0 (6166): 0 80--84, 2014
work page 2014
-
[35]
A theoretical analysis of ndcg type ranking measures
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. A theoretical analysis of ndcg type ranking measures. In Conference on learning theory, pages 25--54. PMLR, 2013
work page 2013
-
[38]
Nicholas D Youngblut, Christopher Carpenter, Jaanak Prashar, Chiara Ricci-Tam, Rajesh Ilango, Noam Teyssier, Silvana Konermann, Patrick D Hsu, Alexander Dobin, David P Burke, et al. scbasecount: an ai agent-curated, uniformly processed, and continually expanding single cell data repository. bioRxiv, pages 2025--02, 2025
work page 2025
- [39]
-
[41]
Ronghui Zhu, Emma Dann, Jun Yan, Justine Reyes Retana, Ryunosuke Goto, Reese C Guitche, Lillian K Petersen, Mineto Ota, Jonathan K Pritchard, and Alexander Marson. Genome-scale perturb-seq in primary human cd4+ t cells maps context-specific regulators of t cell programs and human immune traits. bioRxiv, pages 2025--12, 2025
work page 2025
-
[42]
How to build the virtual cell with artificial intelligence: Priorities and opportunities , author=. Cell , volume=. 2024 , publisher=
work page 2024
-
[43]
scPerturb: harmonized single-cell perturbation data , author=. Nature Methods , volume=. 2024 , publisher=
work page 2024
-
[44]
Nature Reviews Drug Discovery , volume=
Phenotypic drug discovery: recent successes, lessons learned and new directions , author=. Nature Reviews Drug Discovery , volume=. 2022 , publisher=
work page 2022
-
[45]
Perturbench: Benchmarking machine learning models for cellular perturbation analysis, 2025
Perturbench: Benchmarking machine learning models for cellular perturbation analysis , author=. arXiv preprint arXiv:2408.10609 , year=
-
[46]
ACM Transactions on Information Systems (TOIS) , volume=
Cumulated gain-based evaluation of IR techniques , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2002 , publisher=
work page 2002
-
[47]
Journal of classification , volume=
Comparing partitions , author=. Journal of classification , volume=. 1985 , publisher=
work page 1985
-
[48]
Scaling large language models for next-generation single-cell analysis , author=. BioRxiv , pages=
-
[49]
Educational and psychological measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and psychological measurement , volume=. 1960 , publisher=
work page 1960
-
[50]
Information Processing & Management , volume=
Joint upper & expected value normalization for evaluation of retrieval systems: A case study with Learning-to-Rank methods , author=. Information Processing & Management , volume=. 2023 , publisher=
work page 2023
-
[51]
Conference on learning theory , pages=
A theoretical analysis of NDCG type ranking measures , author=. Conference on learning theory , pages=. 2013 , organization=
work page 2013
-
[52]
The BioGRID database: A comprehensive biomedical resource of curated protein, genetic, and chemical interactions , author=. Protein Science , volume=. 2021 , publisher=
work page 2021
-
[53]
arXiv preprint arXiv:2503.00096 , year=
Bixbench: a comprehensive benchmark for llm-based agents in computational biology , author=. arXiv preprint arXiv:2503.00096 , year=
-
[54]
arXiv preprint arXiv:2503.04013 , year=
Benchmarking large language models on multiple tasks in bioinformatics nlp with prompting , author=. arXiv preprint arXiv:2503.04013 , year=
-
[55]
First conference on language modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First conference on language modeling , year=
-
[56]
Humanity's last exam , author=. arXiv preprint arXiv:2501.14249 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Proceedings of the 24th Workshop on Biomedical Language Processing , pages=
Virtual CRISPR: Can LLMs Predict CRISPR Screen Results? , author=. Proceedings of the 24th Workshop on Biomedical Language Processing , pages=
-
[58]
arXiv preprint arXiv:2502.21290 , year=
Contextualizing biological perturbation experiments through language , author=. arXiv preprint arXiv:2502.21290 , year=
-
[59]
scBaseCount: an AI agent-curated, uniformly processed, and continually expanding single cell data repository , author=. bioRxiv , pages=. 2025 , publisher=
work page 2025
-
[60]
Tahoe-100m: A giga-scale single-cell perturbation atlas for context-dependent gene function and cellular modeling , author=. BioRxiv , pages=. 2025 , publisher=
work page 2025
-
[61]
Mapping information-rich genotype-phenotype landscapes with genome-scale Perturb-seq , author=. Cell , volume=. 2022 , publisher=
work page 2022
-
[62]
Virtual Cell Challenge: Toward a Turing test for the virtual cell , author=. Cell , volume=. 2025 , publisher=
work page 2025
-
[63]
AI-Guided CRISPR Screen Accelerates Discovery of New Drug Targets , author=. bioRxiv , pages=. 2026 , publisher=
work page 2026
-
[64]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Rxrx1: A dataset for evaluating experimental batch correction methods , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[65]
Generative Artificial Intelligence for Biology: Toward Unifying Models, Algorithms, and Modalities , author=
-
[66]
Virtual Cells Need Context, Not Just Scale , author=. bioRxiv , pages=. 2026 , publisher=
work page 2026
-
[67]
Nature Biotechnology , volume=
Predicting transcriptional outcomes of novel multigene perturbations with GEARS , author=. Nature Biotechnology , volume=. 2024 , publisher=
work page 2024
-
[68]
Active learning framework leveraging transcriptomics identifies modulators of disease phenotypes , author=. Science , volume=. 2025 , publisher=
work page 2025
-
[69]
Deep-learning-based gene perturbation effect prediction does not yet outperform simple linear baselines , author=. Nature Methods , volume=. 2025 , publisher=
work page 2025
-
[70]
Nature Biotechnology , volume=
Defining and benchmarking open problems in single-cell analysis , author=. Nature Biotechnology , volume=. 2025 , publisher=
work page 2025
-
[71]
A new era of intelligence with gemini 3 , url=
Google , year=. A new era of intelligence with gemini 3 , url=. Google , publisher=
-
[72]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Gepa: Reflective prompt evolution can outperform reinforcement learning , author=. arXiv preprint arXiv:2507.19457 , year=
work page internal anchor Pith review arXiv
-
[74]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [76]
-
[77]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods , author=. Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval , pages=
-
[78]
We Built an Open Source Autonomous Drug Discovery Agent , year =
-
[79]
Gene-embedding-based prediction and functional evaluation of perturbation expression responses with presage , author=. bioRxiv , pages=. 2025 , publisher=
work page 2025
- [80]
-
[81]
The probabilistic relevance framework: BM25 and beyond , author=. 2009 , publisher=
work page 2009
-
[82]
A human protein-protein interaction network: a resource for annotating the proteome , author=. Cell , volume=. 2005 , publisher=
work page 2005
-
[83]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[84]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[85]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5: from Vibe Coding to Agentic Engineering , author=. arXiv preprint arXiv:2602.15763 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[86]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[87]
Qwen3-coder-next technical report, 2026
Qwen3-coder-next technical report , author=. arXiv preprint arXiv:2603.00729 , year=
-
[88]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[89]
Advances in neural information processing systems , volume=
Deep sets , author=. Advances in neural information processing systems , volume=
-
[90]
Cell2Sentence: teaching large language models the language of biology , author=. BioRxiv , pages=
-
[91]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alphaevolve: A coding agent for scientific and algorithmic discovery , author=. arXiv preprint arXiv:2506.13131 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [92]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.