Recognition: 2 theorem links
· Lean TheoremThe Grounding Gap: How LLMs Anchor the Meaning of Abstract Concepts Differently from Humans
Pith reviewed 2026-05-12 03:12 UTC · model grok-4.3
The pith
LLMs anchor abstract concepts through word associations rather than human-like emotional and experiential grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
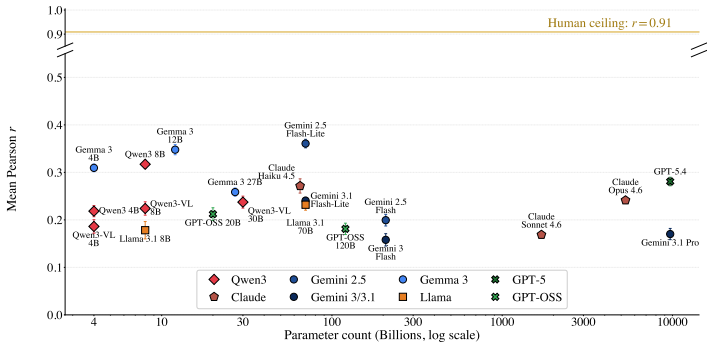
LLMs recover grounding dimensions when explicitly queried but do not recruit them in a human-like way when words are generated freely for abstract concepts.
What carries the argument
The property-generation task, in which participants list properties associated with abstract concepts to reveal their grounding sources.
Load-bearing premise
The property-generation task and rating scales from cognitive science measure the same underlying grounding process in LLMs as in humans, allowing direct numerical comparison of their outputs.
What would settle it
A replication of the property-generation task in which models receive explicit instructions to include emotional and internal-state properties, followed by a check of whether correlations with human lists rise substantially.
Figures












read the original abstract
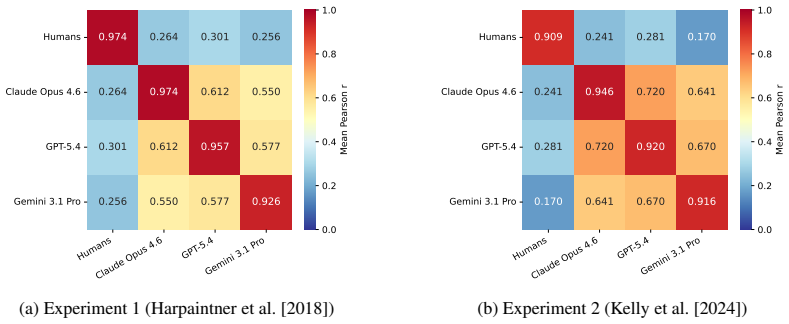
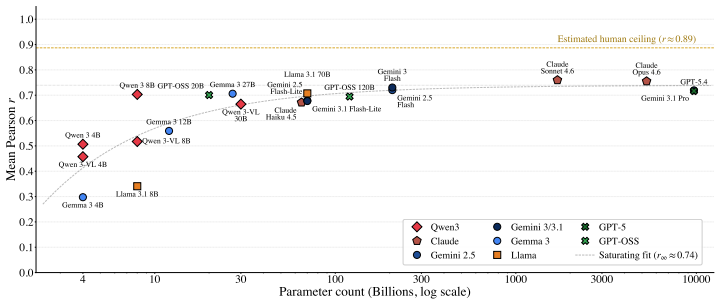
Abstract concepts - justice, theory, availability - have no single perceivable referent; in the human brain, their meaning emerges from a web of experiences, affect, and social context. Do large language models (LLMs) ground abstract concepts in a similar way? We study this by replicating property-generation experiments from cognitive science on 21 frontier and open-weight LLMs. Across models and experiments, we find a consistent pattern: when compared to humans, models rely too heavily on word associations, and underproduce properties tied to emotion and internal states. This yields a large and consistent grounding gap: no model exceeds a Pearson correlation r=0.37 with human responses, compared to a human-to-human ceiling above r=0.9. To better interpret this gap, we also replicate a rating experiment on grounding categories and find that here LLMs align more closely with human judgment, and alignment improves as models get larger. We then use sparse autoencoders (SAEs) to inspect whether this information is also reflected in the models' internal features, and we do identify features connected to grounding dimensions such as "sensorimotor" and "social". These findings suggest that current LLMs can recover grounding dimensions when explicitly queried, but do not recruit them in a human-like way when words are generated freely.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper replicates property-generation experiments from cognitive science on 21 LLMs to compare how they ground abstract concepts (e.g., justice, theory) with humans. It reports consistent low Pearson correlations (no model exceeds r=0.37) versus human-human ceiling >0.9, with LLMs over-relying on word associations and under-producing emotion/internal-state properties. A rating task shows better alignment that scales with model size, and SAE analysis identifies internal features tied to grounding dimensions such as sensorimotor and social. The authors conclude LLMs recover grounding info when explicitly queried but do not recruit it human-like in free generation.
Significance. If the patterns are robust, the work offers a large-scale empirical demonstration of systematic differences in abstract-concept representation between LLMs and humans, with implications for interpretability, cognitive modeling, and AI safety. Strengths include the breadth across 21 models, dual behavioral paradigms, and the SAE probe of internal representations. The significance hinges on whether the property-generation outputs provide commensurable measures of grounding.
major comments (3)
- [Methods] Methods section: the replication of the property-generation task omits exact prompt wording, response coding scheme (how properties are classified as word-association vs. emotion/internal-state), per-model sample sizes, exclusion criteria, and statistical controls. These omissions prevent full evaluation of the r=0.37 ceiling and the frequency-distribution comparisons that support the grounding-gap claim.
- [Results (property-generation experiment)] Results (property-generation experiment): the central claim that LLMs under-recruit grounding dimensions assumes the free-generation task elicits directly comparable conceptual-structure measures in LLMs and humans. Because LLMs operate via next-token statistics, output-style or prompt-interpretation differences could produce the observed gap; a concrete control (e.g., length-matched or format-constrained generation) is needed to isolate grounding from response-regime effects.
- [SAE analysis] SAE analysis section: the identification of features linked to 'sensorimotor' and 'social' dimensions should report quantitative activation statistics during the generation versus rating regimes and the precise mapping criteria used to label features; without these, it is unclear whether the internal representations are recruited equivalently in the free-generation setting that drives the main claim.
minor comments (2)
- [Abstract] Abstract: the phrase 'two experiment types' should explicitly name the property-generation and rating tasks to improve clarity for readers unfamiliar with the cognitive-science paradigm.
- [Figures] Figures: correlation plots should include human-human baseline lines and confidence intervals to allow immediate visual assessment of the reported gap.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below, indicating the revisions we will make to improve the manuscript's clarity, reproducibility, and rigor.
read point-by-point responses
-
Referee: [Methods] Methods section: the replication of the property-generation task omits exact prompt wording, response coding scheme (how properties are classified as word-association vs. emotion/internal-state), per-model sample sizes, exclusion criteria, and statistical controls. These omissions prevent full evaluation of the r=0.37 ceiling and the frequency-distribution comparisons that support the grounding-gap claim.
Authors: We agree that additional methodological detail is necessary for full reproducibility and evaluation. In the revised manuscript, we will include the exact prompt templates used across models, a detailed description of the property coding scheme with explicit criteria and examples for classifying properties (e.g., word-association vs. emotion/internal-state), per-model sample sizes, exclusion criteria applied to responses, and any statistical controls used in the Pearson correlations and frequency analyses. revision: yes
-
Referee: [Results (property-generation experiment)] Results (property-generation experiment): the central claim that LLMs under-recruit grounding dimensions assumes the free-generation task elicits directly comparable conceptual-structure measures in LLMs and humans. Because LLMs operate via next-token statistics, output-style or prompt-interpretation differences could produce the observed gap; a concrete control (e.g., length-matched or format-constrained generation) is needed to isolate grounding from response-regime effects.
Authors: We acknowledge the potential for response-regime confounds given LLMs' next-token prediction mechanism. Our design deliberately replicates the free-generation protocol from human cognitive science studies to enable direct comparison, and the substantially higher alignment in the rating task (using identical models but a different output format) indicates the gap is not solely attributable to generation style. We will expand the discussion section to explicitly address this limitation and potential alternative explanations. However, adding new constrained-generation controls would require substantial additional experiments beyond the current scope; we therefore treat this as a point for future work rather than a revision to the present analyses. revision: partial
-
Referee: [SAE analysis] SAE analysis section: the identification of features linked to 'sensorimotor' and 'social' dimensions should report quantitative activation statistics during the generation versus rating regimes and the precise mapping criteria used to label features; without these, it is unclear whether the internal representations are recruited equivalently in the free-generation setting that drives the main claim.
Authors: We appreciate this request for greater quantitative detail. In the revised SAE analysis section, we will report activation statistics (including mean activations, distributions, and comparisons) for the identified features across both the generation and rating regimes. We will also provide a precise description of the mapping criteria, including how features were selected and labeled based on top-activating examples, correlations with grounding dimensions, and any thresholding or validation steps used. revision: yes
Circularity Check
No significant circularity: purely empirical measurements
full rationale
The paper reports direct experimental replications of property-generation tasks and rating scales from cognitive science, followed by Pearson correlations (r ≤ 0.37 vs. human ceiling > 0.9) and SAE feature inspection. No equations, fitted parameters, or derivations appear; results are computed from model outputs and human data without any step that reduces the claimed gap to a self-definition, renamed input, or self-citation chain. The central findings rest on observable frequency distributions and internal activations rather than any load-bearing assumption that is justified only by prior author work or by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Property-generation responses from humans and LLMs can be directly compared via Pearson correlation as measures of shared grounding.
- standard math Standard assumptions of Pearson correlation (linearity, normality of residuals) hold for the property-count data.
invented entities (1)
-
grounding gap
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We replicate two property-generation experiments... map the generated properties to the taxonomy... compare the resulting per-word category generations... Mean r... SAE features connected to grounding dimensions such as 'sensorimotor' and 'social'
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no model exceeds a Pearson correlation r=0.37 with human responses... LLMs rely too heavily on word associations and underproduce properties tied to emotion and internal states
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Borghi, Anna M. and Binkofski, Ferdinand and Castelfranchi, Cristiano and Cimatti, Felice and Scorolli, Claudia and Tummolini, Luca , title =. Psychological Bulletin , year =
-
[2]
Troche, Joshua and Crutch, Sebastian J. and Reilly, Jamie , journal =. Defining a conceptual topography of word concreteness: Clustering properties of emotion, sensation, and magnitude among 750. 2017 , publisher =
work page 2017
-
[3]
McRae, Ken and Cree, George S. and Seidenberg, Mark S. and McNorgan, Chris , title =. Behavior Research Methods , volume =. 2005 , doi =
work page 2005
-
[4]
and Chodorow, Martin and Wu, Minghua and Li, Ping , title =
Xu, Qihui and Peng, Yingying and Nastase, Samuel A. and Chodorow, Martin and Wu, Minghua and Li, Ping , title =. Nature Human Behaviour , volume =. 2025 , doi =
work page 2025
-
[5]
Behavioral and Brain Sciences , volume =
Perceptual symbol systems , author =. Behavioral and Brain Sciences , volume =. 1999 , publisher =
work page 1999
-
[6]
Grounding Cognition: The Role of Perception and Action in Memory, Language, and Thought , editor =
Situating abstract concepts , author =. Grounding Cognition: The Role of Perception and Action in Memory, Language, and Thought , editor =. 2005 , publisher =
work page 2005
-
[7]
Lakoff, George and Johnson, Mark , year=. Metaphors We Live By , ISBN=. doi:10.7208/chicago/9780226470993.001.0001 , publisher=
-
[8]
and Kiefer, Markus , journal =
Harpaintner, Markus and Trumpp, Natalie M. and Kiefer, Markus , journal =. The semantic content of abstract concepts:. 2018 , publisher =
work page 2018
-
[9]
Kelly, Aubrey E. and Kenett, Yoed N. and Medaglia, John D. and Reilly, Jamie J. and Dudhat, Priyanka and Chrysikou, Evangelia G. , title =. Emotion , year =
-
[10]
Concreteness ratings for 40 thousand generally known
Brysbaert, Marc and Warriner, Amy Beth and Kuperman, Victor , journal =. Concreteness ratings for 40 thousand generally known. 2014 , publisher =
work page 2014
-
[11]
Lynott, Dermot and Connell, Louise and Brysbaert, Marc and Brand, James and Carney, James , journal =. The. 2020 , publisher =
work page 2020
-
[12]
and Keitel, Anne and Becirspahic, Mia and Yao, Bo and Sereno, Sara C
Scott, Graham G. and Keitel, Anne and Becirspahic, Mia and Yao, Bo and Sereno, Sara C. , journal =. The. 2019 , publisher =
work page 2019
-
[13]
Diveica, Veronica and Pexman, Penny M. and Binney, Richard J. , journal =. Quantifying social semantics: An inclusive definition of socialness and ratings for 8,388. 2023 , publisher =
work page 2023
-
[14]
Emotion: Theory, Research, and Experience , editor =
A general psychoevolutionary theory of emotion , author =. Emotion: Theory, Research, and Experience , editor =. 1980 , publisher =
work page 1980
-
[15]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author =. 2024 , eprint =
work page 2024
-
[16]
Large Language Models Predict Human Sensory Judgments across Six Modalities , author =. Scientific Reports , year =
-
[17]
Event Knowledge in Large Language Models: The Gap between the Impossible and Unlikely , author =. Cognitive Science , volume =
-
[18]
Conceptual Structure Coheres in Human Cognition but Not in Large Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2023 , url =
work page 2023
-
[19]
Transactions of the Association for Computational Linguistics (TACL) , volume =
Word Representation Learning in Multimodal Pre-Trained Transformers: An Intrinsic Evaluation , author =. Transactions of the Association for Computational Linguistics (TACL) , volume =. 2021 , url =
work page 2021
-
[20]
Cognitive Alignment Between Humans and LLMs Across Multimodal Domains , author =. 2025 , month = jan, note =. doi:10.21203/rs.3.rs-5736241/v1 , url =
-
[21]
Can large language models help augment English psycholinguistic datasets? , volume=
Trott, Sean , year=. Can large language models help augment English psycholinguistic datasets? , volume=. Behavior Research Methods , publisher=. doi:10.3758/s13428-024-02337-z , number=
-
[22]
Proceedings of the 25th Conference on Computational Natural Language Learning (CoNLL) , year =
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color , author =. Proceedings of the 25th Conference on Computational Natural Language Learning (CoNLL) , year =
-
[23]
ACM Transactions on Computer-Human Interaction (TOCHI) , volume =
Sensorimotor Regularities as Alignment between Humans and Large Language Models , author =. ACM Transactions on Computer-Human Interaction (TOCHI) , volume =. 2026 , month = apr, doi =
work page 2026
-
[24]
Tiny Papers @ ICLR 2023 , year =
Human-Machine Cooperation for Semantic Feature Listing , author =. Tiny Papers @ ICLR 2023 , year =
work page 2023
-
[25]
Language Models Represent Space and Time , url =
Gurnee, Wes and Tegmark, Max , booktitle =. Language Models Represent Space and Time , url =
-
[26]
and Geiger, Atticus and Nanda, Neel
Tigges, Curt and Hollinsworth, Oskar J. and Geiger, Atticus and Nanda, Neel. Language Models Linearly Represent Sentiment. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.5
-
[27]
LEACE: Perfect linear concept erasure in closed form , shorttitle =
LEACE: Perfect Linear Concept Erasure in Closed Form , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2306.03819 , archivePrefix =
-
[28]
The Eleventh International Conference on Learning Representations , year=
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task , author=. The Eleventh International Conference on Learning Representations , year=
-
[29]
Emergent Linear Representations in World Models of Self-Supervised Sequence Models
Nanda, Neel and Lee, Andrew and Wattenberg, Martin. Emergent Linear Representations in World Models of Self-Supervised Sequence Models. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2023. doi:10.18653/v1/2023.blackboxnlp-1.2
-
[30]
Gemma Scope 2 - Technical Paper , author =. 2025 , month = sep, note =
work page 2025
-
[31]
AI Shares Emotion with Humans across Languages and Cultures , author =. 2025 , eprint =
work page 2025
- [32]
-
[33]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , author =. Advances in Neural Information Processing Systems (NeurIPS), oral , year =. 2409.14507 , archivePrefix =
-
[34]
and Wiens, Stefan and Rotshtein, Pia and Öhman, Arne and Dolan, Raymond J
Critchley, Hugo D. and Wiens, Stefan and Rotshtein, Pia and Öhman, Arne and Dolan, Raymond J. , title =. Nature Neuroscience , year =
-
[35]
Ettinger, Allyson , journal =. What. 2020 , publisher =
work page 2020
-
[36]
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie , booktitle =. 2019 , address =
work page 2019
-
[37]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[38]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[39]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
work page 2024
-
[40]
Zhang, Junyu and Kang, Yipeng and Guo, Jiong and Zhan, Jiayu and Wang, Junqi , year =. 2601.14007 , archivePrefix =
-
[41]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
-
[42]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramar, Janos and Dragan, Anca and Shah, Rohin and Nanda, Neel. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP....
-
[43]
and Wang, Zifan and Mallen, Alex and Hendrycks, Dan , booktitle =
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Long and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Hendrycks, Dan , booktitle =. Representation engineering: A top-down approach to. 2024 , ...
work page 2024
- [44]
-
[45]
Steering Language Models With Activation Engineering , author=. 2024 , eprint=
work page 2024
-
[46]
Psychology of Learning and Motivation , volume =
Catastrophic interference in connectionist networks: The sequential learning problem , author =. Psychology of Learning and Motivation , volume =. 1989 , publisher =
work page 1989
-
[47]
Proceedings of the National Academy of Sciences , volume =
Overcoming catastrophic forgetting in neural networks , author =. Proceedings of the National Academy of Sciences , volume =. 2017 , publisher =
work page 2017
-
[48]
A general language assistant as a laboratory for alignment , author =. 2021 , url =
work page 2021
-
[49]
Language and Cognition , volume =
Varieties of abstract concepts and their multiple dimensions , author =. Language and Cognition , volume =. 2019 , publisher =
work page 2019
-
[50]
Behavioral and Brain Sciences , volume =
On a confusion about a function of consciousness , author =. Behavioral and Brain Sciences , volume =. 1995 , publisher =
work page 1995
-
[51]
Physics of Life Reviews , volume =
Words as social tools: Language, sociality and inner grounding in abstract concepts , author =. Physics of Life Reviews , volume =. 2018 , publisher =
work page 2018
- [52]
-
[53]
NeurIPS 2024 Workshop on Safe Generative AI , year =
Farrell, Eoin and Lau, Yeu-Tong and Conmy, Arthur , title =. NeurIPS 2024 Workshop on Safe Generative AI , year =
work page 2024
-
[54]
Khoriaty, Matthew and Shportko, Andrii and Mercier, Gustavo and Wood-Doughty, Zach , title =. 2025 , eprint =
work page 2025
-
[55]
and Chen, Brian and Citro, Craig and others , title =
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and others , title =. Transformer Circuits Thread , year =
-
[56]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
- [57]
- [58]
- [59]
-
[60]
Landis, J. Richard and Koch, Gary G. , title =. Biometrics , volume =. 1977 , publisher =
work page 1977
- [61]
- [62]
-
[63]
Transformer Circuits Thread , year =
Lindsey, Jack , title =. Transformer Circuits Thread , year =
- [64]
-
[65]
doi: 10.18653/v1/2020.acl-main.463
Bender, Emily M. and Koller, Alexander. Climbing towards NLU : On Meaning, Form, and Understanding in the Age of Data. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.463
-
[66]
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445922 , abstract =
- [67]
-
[68]
Somatotopic representation of action words in human motor and premotor cortex , author =. Neuron , volume =. 2004 , doi =
work page 2004
-
[69]
Nature Reviews Neuroscience , volume =
Brain mechanisms linking language and action , author =. Nature Reviews Neuroscience , volume =. 2005 , doi =
work page 2005
-
[70]
Cognitive Brain Research , volume =
Visual semantic features are activated during the processing of concrete words: event-related potential evidence for perceptual semantic priming , author =. Cognitive Brain Research , volume =. 2000 , doi =
work page 2000
-
[71]
Emotion Concepts and their Function in a Large Language Model , author=. 2026 , eprint=
work page 2026
-
[72]
Journal of Neuroscience , volume =
Emotional and Social Dimension of Abstract Concepts Meet with Interoception in Right Anterior Insula , author =. Journal of Neuroscience , volume =. 2026 , doi =
work page 2026
-
[73]
Frontiers in Psychology , volume =
Grounding abstract concepts and beliefs into experience: The embodied perspective , author =. Frontiers in Psychology , volume =. 2022 , doi =
work page 2022
-
[74]
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity , author=. arXiv preprint arXiv:2604.24827 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
work page 2022
- [76]
-
[77]
Warstadt, Alex and Mueller, Aaron and Choshen, Leshem and Wilcox, Ethan and Zhuang, Chengxu and Ciro, Juan and Mosquera, Rafael and Paranjabe, Bhargavi and Williams, Adina and Linzen, Tal and Cotterell, Ryan. Findings of the B aby LM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora. Proceedings of the BabyLM Challenge at the 27...
-
[78]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
- [79]
-
[80]
The Fourteenth International Conference on Learning Representations , year=
Fan, Yu and Ni, Jingwei and Merane, Jakob and Tian, Yang and Hermstr. The Fourteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.