Recognition: unknown
Learning from Noisy Preferences: A Semi-Supervised Learning Approach to Direct Preference Optimization
Pith reviewed 2026-05-08 04:13 UTC · model grok-4.3
The pith
Compressing multi-dimensional human preferences into binary labels creates conflicting gradients that misguide diffusion DPO, which a semi-supervised method can fix by pseudo-labeling conflicts from a clean subset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper demonstrates that binary compression of multi-dimensional preferences generates conflicting gradient signals during Diffusion Direct Preference Optimization. Semi-DPO counters this by designating consistent pairs as clean labeled data, training a model on the resulting consensus-filtered subset, and then applying that model as an implicit classifier to produce pseudo-labels for the conflicting pairs, followed by iterative refinement.
What carries the argument
The semi-supervised pipeline that extracts a consensus-filtered clean subset to train an initial model which then serves as an implicit classifier to generate pseudo-labels for conflicting preference pairs.
If this is right
- Standard DPO training on the full noisy dataset is outperformed by the iterative pseudo-labeling procedure.
- No additional human annotations or explicit reward models are required to reach the reported alignment gains.
- The method applies directly to existing preference datasets collected for diffusion models.
- Iterative refinement on the pseudo-labeled set produces measurable improvements in multi-dimensional preference alignment.
Where Pith is reading between the lines
- The same noise pattern from collapsing multiple preference axes into one binary label likely appears in non-diffusion preference optimization settings.
- Replacing the implicit classifier with a more expressive model could further reduce residual label errors on the conflicting pairs.
- Applying the consensus-filter plus pseudo-label loop to text-based preference data could test whether the conflicting-gradient problem is modality-specific.
Load-bearing premise
That the model trained on the consensus-filtered clean subset can reliably generate accurate pseudo-labels for the conflicting pairs instead of propagating errors from the initial clean data.
What would settle it
Training a second model on the same conflicting pairs but with human-verified labels instead of the model's pseudo-labels and measuring whether Semi-DPO still matches or exceeds that performance would directly test whether the pseudo-label step recovers the intended preference signals.
Figures





read the original abstract
Human visual preferences are inherently multi-dimensional, encompassing aesthetics, detail fidelity, and semantic alignment. However, existing datasets provide only single, holistic annotations, resulting in severe label noise: images that excel in some dimensions but are deficient in others are simply marked as winner or loser. We theoretically demonstrate that compressing multi-dimensional preferences into binary labels generates conflicting gradient signals that misguide Diffusion Direct Preference Optimization (DPO). To address this, we propose Semi-DPO, a semi-supervised approach that treats consistent pairs as clean labeled data and conflicting ones as noisy unlabeled data. Our method starts by training on a consensus-filtered clean subset, then uses this model as an implicit classifier to generate pseudo-labels for the noisy set for iterative refinement. Experimental results demonstrate that Semi-DPO achieves state-of-the-art performance and significantly improves alignment with complex human preferences, without requiring additional human annotation or explicit reward models during training. We will release our code and models at: https://github.com/L-CodingSpace/semi-dpo
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that binary preference labels compress multi-dimensional human visual judgments (aesthetics, fidelity, semantics) into noisy winner/loser annotations, producing conflicting gradients that impair Diffusion DPO. It introduces Semi-DPO, which treats consensus-filtered consistent pairs as clean labeled data, trains an initial model on them, uses that model as an implicit classifier to assign pseudo-labels to conflicting pairs, and performs iterative refinement. Experiments are reported to show state-of-the-art alignment performance without extra human annotations or explicit reward models.
Significance. If the pseudo-labeling step is shown to be accurate and the gradient-conflict analysis is rigorous, the work could meaningfully advance preference optimization for generative vision models by making better use of existing noisy datasets. The semi-supervised framing is a natural extension of standard SSL techniques to DPO and the no-additional-annotation property is practically attractive. Credit is due for identifying the multi-dimensional noise issue and for committing to release code and models.
major comments (2)
- [Method and Experiments] The central claim that Semi-DPO successfully mitigates noise via pseudo-labeling rests on the unverified assumption that the model trained solely on the consensus-filtered clean subset generalizes to produce accurate pseudo-labels on conflicting pairs. No ablation on pseudo-label precision (e.g., agreement rate with held-out human labels) or sensitivity to clean-subset size is reported; without these, it remains possible that reported gains derive only from the clean data or from implicit regularization rather than noise handling.
- [Introduction / Theoretical Analysis] The abstract states that conflicting gradients are 'theoretically demonstrated,' yet the manuscript provides no explicit derivation, equation, or proof sketch showing how multi-dimensional compression produces opposing gradient directions in the DPO loss. This derivation is load-bearing for motivating the semi-supervised approach over standard DPO.
minor comments (2)
- [Abstract] The abstract would benefit from a one-sentence summary of the key theoretical insight (e.g., the form of the gradient conflict) to allow readers to assess novelty without reading the full derivation.
- Ensure the promised GitHub release includes the exact data splits, filtering thresholds for the 'consensus' clean set, and reproduction scripts so that the pseudo-labeling procedure can be independently verified.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback. We have carefully considered each comment and made revisions to address the concerns raised. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Method and Experiments] The central claim that Semi-DPO successfully mitigates noise via pseudo-labeling rests on the unverified assumption that the model trained solely on the consensus-filtered clean subset generalizes to produce accurate pseudo-labels on conflicting pairs. No ablation on pseudo-label precision (e.g., agreement rate with held-out human labels) or sensitivity to clean-subset size is reported; without these, it remains possible that reported gains derive only from the clean data or from implicit regularization rather than noise handling.
Authors: We agree that direct validation of the pseudo-labeling step strengthens the central claim. While the original experiments emphasized end-to-end alignment gains, we have added two new ablations in the revised manuscript: (1) a precision evaluation that compares generated pseudo-labels against a held-out subset of human annotations on conflicting pairs, and (2) a sensitivity study that varies the fraction of consensus-filtered clean data used for the initial model (reporting performance curves for multiple clean-subset sizes). These results are presented in the new Section 4.4 and Appendix C. The added experiments indicate that pseudo-label accuracy is sufficient to yield gains beyond training on clean data alone and that improvements are robust across clean-subset sizes, supporting that noise mitigation is a contributing factor. revision: yes
-
Referee: [Introduction / Theoretical Analysis] The abstract states that conflicting gradients are 'theoretically demonstrated,' yet the manuscript provides no explicit derivation, equation, or proof sketch showing how multi-dimensional compression produces opposing gradient directions in the DPO loss. This derivation is load-bearing for motivating the semi-supervised approach over standard DPO.
Authors: We appreciate the referee highlighting this gap in presentation. Although the motivation section discussed the multi-dimensional nature of preferences, we did not supply a formal derivation. In the revised version we have inserted a new subsection (Section 3.1) that provides an explicit derivation: we model each preference as a vector in a multi-dimensional space, show that the binary label corresponds to a lossy projection, and derive the resulting gradient terms in the DPO objective to demonstrate that opposing directions can arise across dimensions. A concise proof sketch is included. This addition directly supports the motivation for treating conflicting pairs via semi-supervised pseudo-labeling. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper applies standard semi-supervised learning: consensus filtering to create a clean subset, initial training on that subset, and use of the resulting model to pseudo-label conflicting pairs before refinement. No equation or step reduces the claimed performance gain to a quantity defined by the method's own outputs or to a self-citation chain. The gradient-conflict analysis is presented as an independent theoretical observation rather than a tautological restatement of the algorithm's inputs. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A model trained on consensus-filtered pairs can serve as a reliable implicit classifier for generating pseudo-labels on conflicting pairs.
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review arXiv
-
[2]
Emu: Enhanc- ing image generation models using photogenic needles in a haystack
URLhttps://openreview.net/ forum?id=1vmSEVL19f. Xiaoliang Dai, Ji Hou, Chih-Yao Ma, Sam Tsai, Jialiang Wang, Rui Wang, Peizhao Zhang, Simon Vandenhende, Xiaofang Wang, Abhimanyu Dubey, et al. Emu: Enhancing image generation models using photogenic needles in a haystack.arXiv preprint arXiv:2309.15807,
-
[3]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626,
work page internal anchor Pith review arXiv
-
[4]
Jiwoo Hong, Sayak Paul, Noah Lee, Kashif Rasul, James Thorne, and Jongheon Jeong. Margin- aware preference optimization for aligning diffusion models without reference.arXiv preprint arXiv:2406.06424,
-
[5]
Pick- a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663,
11 Published as a conference paper at ICLR 2026 Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick- a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663,
2026
-
[6]
Junnan Li, Richard Socher, and Steven CH Hoi
Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi- supervised learning.arXiv preprint arXiv:2002.07394,
-
[7]
Pablo Pernias, Dominic Rampas, Mats L Richter, Christopher J Pal, and Marc Aubreville. W¨urstchen: An efficient architecture for large-scale text-to-image diffusion models.arXiv preprint arXiv:2306.00637,
-
[8]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review arXiv
-
[9]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: your language model is secretly a reward model. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023a. Curran Associates Inc. 12 Published as a co...
2026
-
[10]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review arXiv
-
[11]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review arXiv 2011
-
[12]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to- image synthesis.arXiv preprint arXiv:2306.09341, 2023a. Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Better aligning text-to-image models with human preference....
work page internal anchor Pith review arXiv
-
[13]
Using human feedback to fine-tune diffusion models without any reward model
13 Published as a conference paper at ICLR 2026 Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model. InCVPR, pp. 8941–8951,
2026
-
[14]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530,
work page internal anchor Pith review arXiv
-
[15]
Learning multi-dimensional human prefer- ence for text-to-image generation
Tao Zhang, Cheng Da, Kun Ding, Huan Yang, Kun Jin, Yan Li, Tingting Gao, Di Zhang, Shiming Xiang, and Chunhong Pan. Diffusion model as a noise-aware latent reward model for step-level preference optimization.arXiv preprint arXiv:2502.01051,
-
[16]
net/forum?id=xyfb9HHvMe
URLhttps://openreview. net/forum?id=xyfb9HHvMe. 14 Published as a conference paper at ICLR 2026 6 APPENDIX 6.1 DERIVATION OF THEDIFFUSION-DPO GRADIENT We derive the gradient of the per-timestep Diffusion-DPO loss,L (t) DPO(θ), with respect to the model parametersθ. The loss is defined as: L(t) DPO(θ) :=−logσ β log pθ(xw t−1|xw t , c) pref(xw t−1|xw t , c)...
2026
-
[17]
6.3 THEUSE OFLARGELANGUAGEMODELS Large Language Models (LLMs) such as GPT were used solely for language polishing and clarity improvements in the writing of this paper
Thus, the total variance has a lower bound determined by the conflict: Var[ξt]≥p a,k ·p c,k ·(m (t) a,k +m (t) c,k)2 (16) This proves that any non-zero conflict mass (pc,k >0) introduces a variance term that grows quadrat- ically with the sum of the conflicting and aligned update magnitudes. 6.3 THEUSE OFLARGELANGUAGEMODELS Large Language Models (LLMs) su...
2020
-
[18]
better” and “worse
or generating new datasets through multiple reward models 16 Published as a conference paper at ICLR 2026 for re-annotation and training (Lee et al., 2025), Semi-DPO addresses the noise label problem caused by multi-dimensional preference conflicts in DPO datasets. We reclassify the dataset into clean labeled data and noisy unlabeled data. Following the p...
2026
-
[19]
They must share a latent space with the diffusion model they are training, which requires a shared V AE encoder
have a significant limitation: they are architecturally specific. They must share a latent space with the diffusion model they are training, which requires a shared V AE encoder. As different generative models (e.g., SD1.5 and SDXL) use different V AEs, a latent reward model trained for one is incompatible with another. This gives them great power but pre...
2023
-
[20]
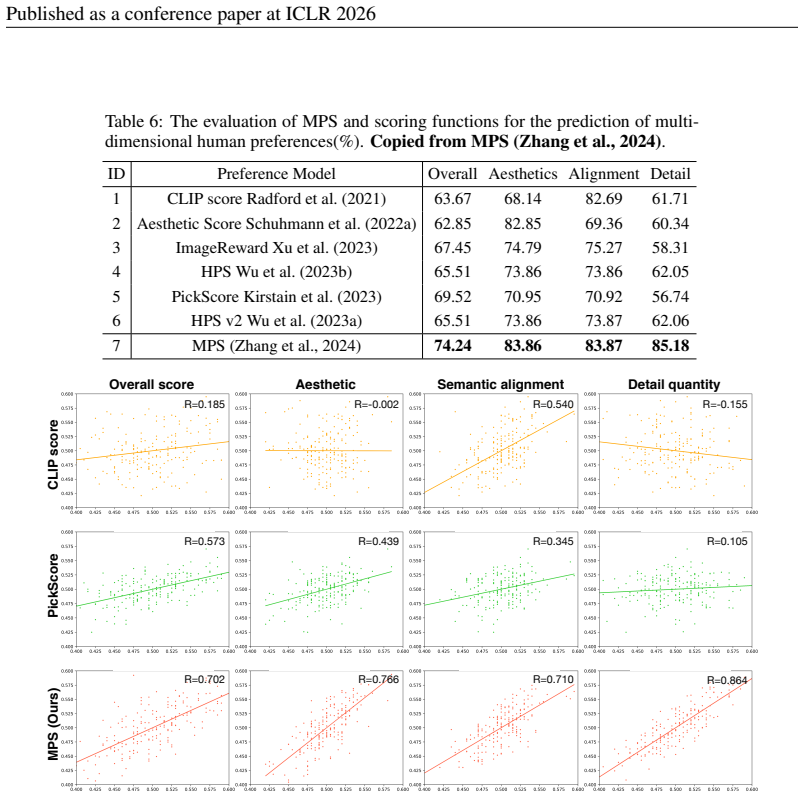
for data fil- tering. This approach is motivated by the study that introduced the Multi-dimensional Preference Score (MPS) (Zhang et al., 2024), which constructed a dataset reflecting real human preferences by 17 Published as a conference paper at ICLR 2026 Table 6: The evaluation of MPS and scoring functions for the prediction of multi- dimensional human...
2024
-
[21]
The x-axis of each subplot represents the annotated real human preferences, and the y-axis denotes the model’s predictions
74.24 83.86 83.87 85.18 R=-0.002 R=0.540 R=-0.155 R=0.573 R=0.439 R=0.345 R=0.105 R=0.702 R=0.766 R=0.710 R=0.864 R=0.185 PickScoreMPS (Ours) CLIP score Overall score Aesthetic Semantic alignment Detail quantity Figure 4:Correlation between real user preferences and model predictions. The x-axis of each subplot represents the annotated real human preferen...
2024
-
[22]
Meanwhile, models such as HPSv2 (Wu et al., 2023a), ImageReward (Xu et al., 2023), and PickScore (Kirstain et al.,
shows a strong correlation with the semantic alignment dimension, while Aesthetic Score (Schuhmann et al., 2022a) is highly correlated with the aesthetics dimension. Meanwhile, models such as HPSv2 (Wu et al., 2023a), ImageReward (Xu et al., 2023), and PickScore (Kirstain et al.,
2023
-
[23]
Cosmic hamburger in space
show higher consistency with the overall score. This finding indicates that no single model can comprehensively evaluate image quality. As shown in Table 6 and Figure 4(Both Table 6 and Figure 4 are reproduced from MPS paper. They are Tab. 4 and Fig. 5 in their original paper.), the MPS model shows the strongest cor- relation with multi-dimensional human ...
2026
-
[24]
This is significantly more efficient than the 19 Published as a conference paper at ICLR 2026 standard Diffusion-DPO baseline, which necessitates192 GPU hours
requires approximately132 GPU hours. This is significantly more efficient than the 19 Published as a conference paper at ICLR 2026 standard Diffusion-DPO baseline, which necessitates192 GPU hours. This efficiency gain stems directly from the dynamic thresholding mechanism described previously, which effectively filters out low-confidence samples from the ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.