Recognition: unknown
Asymmetric-Information Resource Allocation Games: An LP Approach to Purposeful Deception
Pith reviewed 2026-05-07 17:08 UTC · model grok-4.3
The pith
A single linear program computes the Perfect Bayesian Nash Equilibrium of the Deceptive Resource Allocation Game.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
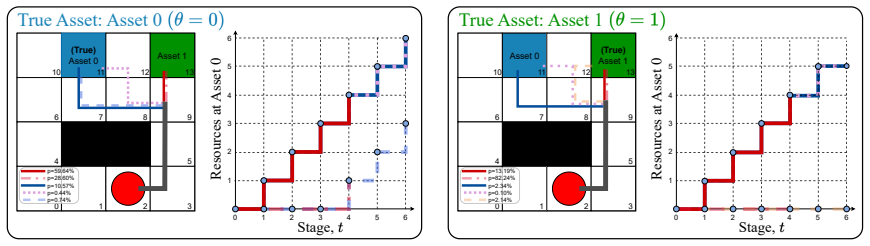
In the Deceptive Resource Allocation Game a defender chooses how to allocate scarce resources across one true asset and several decoys while an attacker, holding only a prior belief about the true location, chooses which target to attack. The defender's payoff depends on whether the attacker strikes the true asset. The Perfect Bayesian Nash Equilibrium requires that the attacker's posterior beliefs are consistent with the defender's allocation policy via Bayes' rule and that each player's strategy is optimal given the other's. The paper shows that these equilibrium conditions can be encoded exactly as the feasible region and objective of a single linear program whose solution simultaneously
What carries the argument
The non-iterative linear program whose variables are the defender's allocation probabilities and the attacker's posterior beliefs, with constraints that enforce belief consistency and mutual best-response.
If this is right
- Equilibrium strategies automatically produce purposeful deception, allocating to decoys only when the resulting belief shift improves the defender's expected payoff.
- The defender's policy balances direct protection of the true asset with manipulation of the attacker's belief.
- The same LP recovers both the equilibrium strategies and the induced beliefs without requiring separate belief-update steps.
- Numerical solutions reveal emergent deceptive behaviors that arise purely from payoff maximization rather than from an explicit deception objective.
Where Pith is reading between the lines
- The LP approach may generalize to other Bayesian games in which one player designs signals or actions to influence another's beliefs, provided the payoff structure permits linearization.
- In applied security settings the formulation allows pre-computation of deceptive resource placements using standard linear-programming solvers.
- The result suggests that purposeful deception can be studied as an emergent property of equilibrium rather than as an exogenous modeling choice.
Load-bearing premise
The game's payoffs and information structure are such that the equilibrium conditions can be written exactly as linear constraints without any approximation or fixed-point iteration.
What would settle it
Take a small instance with two decoys and known manually computed PBNE; solve the proposed LP and verify that its output allocation probabilities and beliefs coincide with the manually derived equilibrium.
Figures


read the original abstract
In this work, we introduce the Deceptive Resource Allocation Game (DRAG), which studies purposeful deception within a Bayesian game framework. In DRAG, a Defender allocates resources across the true asset and several decoys to influence an Attacker's beliefs and actions, with the goal of diverting the Attacker away from the true asset. We seek to characterize purposeful deception, whereby the Defender deceives only when doing so improves its performance. To this end, we solve for the Perfect Bayesian Nash Equilibrium (PBNE) of the corresponding game. We show that, despite the coupled belief-policy interdependence, the problem admits an efficient, non-iterative linear programming formulation. Numerical results demonstrate that the resulting policies naturally balance effective allocation and belief manipulation, giving rise to purposeful and emergent deceptive behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Deceptive Resource Allocation Game (DRAG), a Bayesian game in which a Defender allocates resources across a true asset and decoys to influence an Attacker's beliefs via purposeful deception. The central claim is that the Perfect Bayesian Nash Equilibrium (PBNE) of the DRAG, despite the interdependence between the Defender's mixed strategies and the Attacker's Bayes-updated beliefs, admits an efficient non-iterative linear programming formulation. Numerical results are said to illustrate that the resulting policies balance allocation effectiveness with belief manipulation, producing emergent deceptive behavior.
Significance. If the claimed LP formulation is shown to exactly encode PBNE consistency without relaxing bilinear terms or introducing hidden assumptions on information partitions, the result would offer a computationally attractive method for solving a class of asymmetric-information security games. This could be useful for analyzing deception in resource allocation settings, provided the linearization is general and the equilibria are verified to satisfy the original game conditions.
major comments (2)
- Abstract and presumed §4 (LP formulation): The claim that the PBNE 'admits an efficient, non-iterative linear programming formulation' despite 'coupled belief-policy interdependence' requires explicit demonstration that Bayes consistency (strategy probability times type probability) and expected payoffs are exactly linearized. The manuscript must supply the full LP, including auxiliary variables and constraints, together with a proof that the solution satisfies the original PBNE conditions for both on-path and off-path signals; without this derivation the central claim cannot be evaluated.
- Numerical results section: The abstract states that 'numerical results demonstrate' purposeful deception, yet no tables, figures, or verification metrics (e.g., equilibrium payoff comparisons, belief consistency checks, or comparison against iterative best-response methods) are referenced. If the LP is the main contribution, the experiments must confirm that the computed solution is indeed a PBNE rather than an approximation.
minor comments (2)
- Notation: Define the information partitions, type spaces, and signal structure explicitly before introducing the LP; the current abstract leaves the precise game form unclear.
- Related work: The manuscript should cite standard references on linear programming formulations of Bayesian games and on deception in security games to clarify the novelty of the non-iterative claim.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments below and have made revisions to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract and presumed §4 (LP formulation): The claim that the PBNE 'admits an efficient, non-iterative linear programming formulation' despite 'coupled belief-policy interdependence' requires explicit demonstration that Bayes consistency (strategy probability times type probability) and expected payoffs are exactly linearized. The manuscript must supply the full LP, including auxiliary variables and constraints, together with a proof that the solution satisfies the original PBNE conditions for both on-path and off-path signals; without this derivation the central claim cannot be evaluated.
Authors: We appreciate this comment, as it points to the need for greater clarity in our derivation. The LP formulation is presented in Section 4, where we linearize the bilinear terms arising from the product of the defender's mixed strategy and the attacker's posterior beliefs using standard auxiliary variable techniques for products of continuous variables. To fully address the referee's concern, we will include an expanded derivation in the revised manuscript that explicitly shows the linearization steps for Bayes consistency constraints (i.e., posterior = prior * strategy / marginal) and the expected payoff expressions. Additionally, we will add a formal proposition with proof that any optimal solution to the LP satisfies the PBNE conditions, including for off-path signals where beliefs are free but constrained by sequential rationality. This ensures no relaxation of the original conditions. revision: yes
-
Referee: Numerical results section: The abstract states that 'numerical results demonstrate' purposeful deception, yet no tables, figures, or verification metrics (e.g., equilibrium payoff comparisons, belief consistency checks, or comparison against iterative best-response methods) are referenced. If the LP is the main contribution, the experiments must confirm that the computed solution is indeed a PBNE rather than an approximation.
Authors: We agree that the numerical section should provide explicit verification. In the current manuscript, the numerical results illustrate the policies but lack detailed metrics. We will revise this section to include tables with equilibrium allocations, computed beliefs, and payoff values. We will add belief consistency checks by comparing the LP-derived beliefs to direct Bayes updates from the strategies. Furthermore, we will include a comparison of the LP solution against an iterative best-response algorithm to verify that the payoffs match and no player has incentive to deviate, confirming it is a true PBNE. This will substantiate the claim of purposeful deception. revision: yes
Circularity Check
No circularity: LP reformulation of PBNE is a direct mathematical encoding without self-referential reduction
full rationale
The paper presents a new game (DRAG) and derives a non-iterative LP for its PBNE by encoding belief-policy consistency via linear constraints and auxiliary variables. No load-bearing steps reduce to fitted inputs, self-citations, or ansatzes imported from prior author work; the abstract and structure indicate a self-contained reformulation of standard PBNE conditions into LP form. The derivation chain relies on the specific payoff and information structure of DRAG rather than presupposing the target equilibrium as an input.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of Perfect Bayesian Nash Equilibrium for the defined information structure and payoffs
invented entities (1)
-
Deceptive Resource Allocation Game (DRAG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lloyd,The Art of Military Deception
M. Lloyd,The Art of Military Deception. Pen and Sword, 2003
2003
-
[2]
Cyber Security Deception,
M. H. Almeshekah and E. H. Spafford, “Cyber Security Deception,” Cyber Deception: Building the Scientific Foundation, pp. 23–50, 2016
2016
-
[3]
The deceitful Connected and Autonomous Vehicle: Defining the concept, contextualising its dimensions and proposing mitigation policies,
A. Nikitas, S. Parkinson, and M. Vallati, “The deceitful Connected and Autonomous Vehicle: Defining the concept, contextualising its dimensions and proposing mitigation policies,”Transport Policy, vol. 122, pp. 1–10, 2022
2022
-
[4]
Deceptive Path Planning: A Bayesian Game Approach,
V . Rostobaya, J. Berneburg, Y . Guan, M. Dorothy, and D. Shishika, “Deceptive Path Planning: A Bayesian Game Approach,”arXiv preprint arXiv:2506.13650, 2025
-
[5]
Goal Recognition Design with Stochastic Agent Action Outcomes,
C. Wayllace, P. Hou, W. Yeoh, and T. C. Son, “Goal Recognition Design with Stochastic Agent Action Outcomes,” inInt. Joint Conf. on Artif. Intell., 2016, pp. 3279–3285
2016
-
[6]
Landmark-Based Heuristics for Goal Recognition,
R. Pereira, N. Oren, and F. Meneguzzi, “Landmark-Based Heuristics for Goal Recognition,” inAAAI Conf. Artif. Intell., vol. 31, no. 1, 2017
2017
-
[7]
Goal Recognition over POMDPs: Inferring the Intention of a POMDP Agent,
M. Ram ´ırez and H. Geffner, “Goal Recognition over POMDPs: Inferring the Intention of a POMDP Agent,” inInt. Joint Conf. on Artif. Intell., 2011, pp. 2009–2014
2011
-
[8]
Deceptive robot motion: synthesis, analysis and experiments,
A. Dragan, R. Holladay, and S. Srinivasa, “Deceptive robot motion: synthesis, analysis and experiments,”Autonomous Robots, vol. 39, pp. 331–345, 2015
2015
-
[9]
Deceptive Path-Planning,
P. Masters and S. Sardina, “Deceptive Path-Planning,” inInt. Joint Conf. on Artif. Intell., 2017, pp. 4368–4375
2017
-
[10]
Deception in Optimal Control,
M. Ornik and U. Topcu, “Deception in Optimal Control,” in2018 56th Annu. Allerton Conf. on Communication, Control, and Comput., 2018, pp. 821–828
2018
-
[11]
Deception in Supervisory Control,
M. O. Karabag, M. Ornik, and U. Topcu, “Deception in Supervisory Control,”IEEE Transactions on Automatic Control, vol. 67, no. 2, pp. 738–753, 2022
2022
-
[12]
Deception by Motion: The Eater and the Mover Game,
V . Rostobaya, Y . Guan, J. Berneburg, M. Dorothy, and D. Shishika, “Deception by Motion: The Eater and the Mover Game,”IEEE Control Systems Letters, vol. 7, pp. 3157–3162, 2023
2023
-
[13]
An LP Approach for Solving Two-Player Zero-Sum Repeated Bayesian Games,
L. Li, C. Langbort, and J. Shamma, “An LP Approach for Solving Two-Player Zero-Sum Repeated Bayesian Games,”IEEE Transactions on Automatic Control, vol. 64, no. 9, pp. 3716–3731, 2019
2019
-
[14]
Strategic Concealment of Environ- ment Representations in Competitive Games,
Y . Guan, D. Maity, and P. Tsiotras, “Strategic Concealment of Environ- ment Representations in Competitive Games,”IEEE Control Systems Letters, vol. 9, pp. 2609–2614, 2025
2025
-
[15]
Extensive Games and the Problem of Information,
H. W. Kuhn, “Extensive Games and the Problem of Information,” Contributions to the Theory of Games, vol. 2, no. 28, pp. 193–216, 1953
1953
-
[16]
Maschler, E
M. Maschler, E. Solan, and S. Zamir,Game Theory. Cambridge University Press, 2013
2013
-
[17]
Dynamic Games With Asymmetric Information: Common Information Based Perfect Bayesian Equilibria and Sequential Decomposition,
Y . Ouyang, H. Tavafoghi, and D. Teneketzis, “Dynamic Games With Asymmetric Information: Common Information Based Perfect Bayesian Equilibria and Sequential Decomposition,”IEEE Transac- tions on Automatic Control, vol. 62, no. 1, pp. 222–237, 2017
2017
-
[18]
Chapter 16: Dynamic games with incomplete information,
M. Yildiz, “Chapter 16: Dynamic games with incomplete information,” 2012, MIT OpenCourseWare. [Online]. Available: https://ocw.mit. edu/courses/14-12-economic-applications-of-game-theory-fall-2012/ resources/mit14 12f12 chapter16/
2012
-
[19]
LP formulation of asymmetric zero-sum stochastic games,
L. Li and J. Shamma, “LP formulation of asymmetric zero-sum stochastic games,”53rd IEEE Conference on Decision and Control, pp. 1930–1935, 2014
1930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.