Recognition: unknown
ML-SAN: Multi-Level Speaker-Adaptive Network for Emotion Recognition in Conversations
Pith reviewed 2026-05-07 14:44 UTC · model grok-4.3
The pith
A three-stage network adapts emotion recognition to each speaker by calibrating features to neutral space, gating modalities by identity, and regularizing latent outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ML-SAN addresses speaker identity confusion through Input-level Calibration that uses Feature-Level Linear Modulation to shift raw audio and visual features into a speaker-neutral space, Interaction-level Gating that re-weights modality trust according to speaker identity, and Output-level Regularization that enforces consistency of speaker features in the latent space; experiments on MELD and IEMOCAP confirm higher overall accuracy, stronger results on tail sentiment categories, and better handling of real-world speaker diversity.
What carries the argument
The three-stage speaker-adaptive process: FiLM-based input calibration to neutral space, speaker-conditioned modality gating, and latent-space output regularization.
If this is right
- Higher recognition accuracy than static multimodal baselines on standard conversation datasets.
- Particularly strong gains on infrequent or tail sentiment categories.
- Improved robustness when the same emotion is expressed differently across speakers.
- Shift from one-size-fits-all models to per-speaker adaptation inside a single network.
Where Pith is reading between the lines
- The same calibration-gating-regularization pattern could be tested on other multimodal sequence tasks where participant identity influences signal style, such as speaker diarization or dialogue act recognition.
- If explicit speaker labels are unavailable at test time, the method would need an auxiliary identity inference step whose errors would directly limit the adaptation benefit.
- The reported strength on tail categories suggests the adaptation also mitigates the class-imbalance problem typical in emotion corpora.
Load-bearing premise
Speaker identity can be extracted reliably at both training and inference time and used to adjust features and modality weights without introducing new biases or requiring data unavailable in deployment.
What would settle it
Evaluation on a held-out set of multi-speaker conversations containing only speakers absent from training data, measuring whether accuracy gains over non-adaptive baselines disappear.
Figures



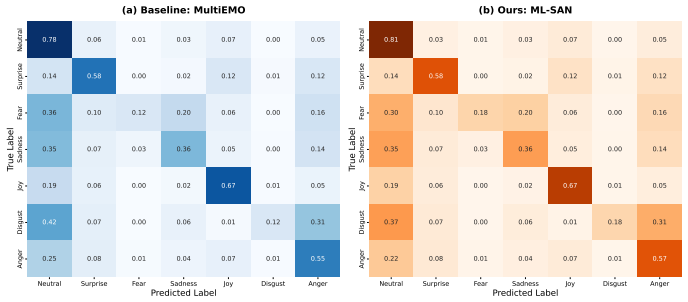
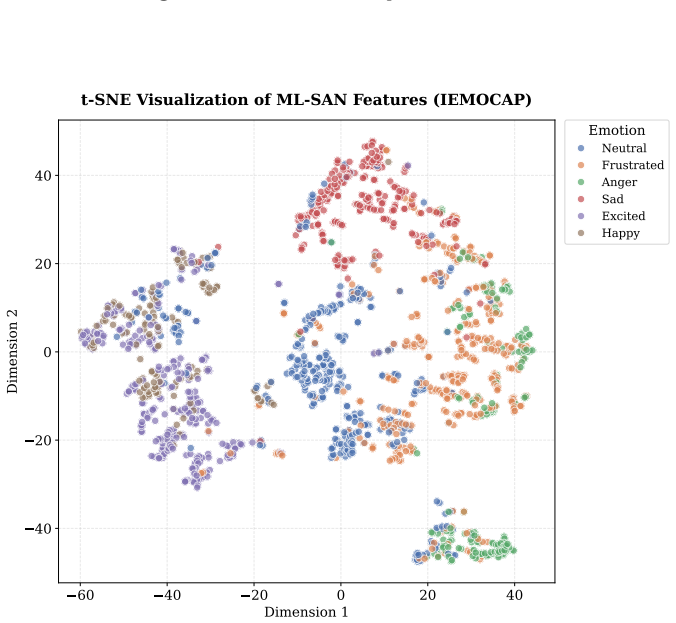
read the original abstract
To establish empathy with machines, it is essential to fully understand human emotional changes. However, research in multimodal emotion recognition often overlooks one problem: individual expressive traits vary significantly, which means that different people may express emotions differently. In our daily lives, we can see this. When communicating with different people, some express "happiness" through their facial expressions and words, while others may hide their happiness or express it through their actions. Both are expressions of 'happiness,' but such differences in emotional expression are still too difficult for machines to distinguish. Current emotion recognition remains at a 'static' level, using a single recognition model to identify all emotional styles. This "simplification" often affects the recognition results, especially in multi-turn dialogues. To address this problem, this paper introduces a novel Multi-Level Speaker Adaptive Network (ML-SAN), which, specifically, effectively addresses the challenge of speaker identity information confusion. ML-SAN does not simply assign a speaker's ID after recognition; instead, it employs a three-stage adaptive process: First, Input-level Calibration uses Feature-Level Linear Modulation (FiLM) to adjust the raw audio and visual features into a neutral space unrelated to the speaker. Then, Interaction-level Gating re-adjusts the trust level for each modality (e.g., voice or facial features) based on the speaker's identity information. Finally, Output-level Regularization maintains the consistency of speaker features in the latent space. Tests on the MELD and IEMOCAP datasets show that our model (ML-SAN) achieves better results, performs exceptionally well in handling challenging tail sentiment categories, and better addresses the diversity of speakers in real-world scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ML-SAN, a three-stage Multi-Level Speaker-Adaptive Network for multimodal emotion recognition in conversations. It claims to address speaker-specific expression variability via input-level FiLM calibration to a neutral feature space, interaction-level modality gating conditioned on speaker identity, and output-level regularization for latent consistency. Empirical tests on MELD and IEMOCAP are said to yield superior overall results, especially on tail sentiment classes, and better handling of real-world speaker diversity compared to prior static models.
Significance. If the claimed gains are supported by controlled experiments with proper baselines and ablations, the work could advance speaker-adaptive ERC by providing an explicit architectural mechanism for individual expression calibration without requiring per-speaker retraining. The three-stage design offers a concrete way to mitigate the 'static model' limitation noted in the abstract, but its significance hinges on demonstrating that the adaptation does not rely on hidden supervision.
major comments (3)
- Abstract: the central claim of 'better results' and 'exceptionally well' tail-class performance on MELD/IEMOCAP is stated without any quantitative metrics, baselines, ablation tables, error bars, or statistical tests, making the empirical contribution impossible to evaluate from the provided text.
- Abstract / §3 (three-stage pipeline): the description states that the network 'employs' speaker identity information for FiLM calibration and modality gating, yet supplies no mechanism for obtaining reliable speaker identity or embeddings at inference time when labels are unavailable (standard ERC test setting). If identity is oracle-provided or produced by an auxiliary network, the reported gains may be artifacts of that supervision rather than genuine adaptation; this is load-bearing for the adaptation modules.
- Abstract: the weakest assumption—that speaker identity can be extracted and used to calibrate features and adjust modality trust without introducing new biases—is left unaddressed, as no details are given on whether an auxiliary speaker encoder is trained jointly or how errors in identity prediction would propagate into the FiLM parameters and gating weights.
minor comments (1)
- Abstract: the sentence 'ML-SAN does not simply assign a speaker's ID after recognition' is unclear; clarify whether this means the model avoids post-hoc ID assignment or avoids using ID at all.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications from the full manuscript and indicate the revisions we will make to improve clarity and completeness.
read point-by-point responses
-
Referee: Abstract: the central claim of 'better results' and 'exceptionally well' tail-class performance on MELD/IEMOCAP is stated without any quantitative metrics, baselines, ablation tables, error bars, or statistical tests, making the empirical contribution impossible to evaluate from the provided text.
Authors: We agree that the abstract would be strengthened by including quantitative support for the claims. The full manuscript (Section 4) contains tables with overall accuracy, weighted F1, and per-class F1 scores on MELD and IEMOCAP, showing improvements over baselines including on tail classes, along with ablation studies. We will revise the abstract to incorporate key metrics (e.g., absolute gains and tail-class performance) and reference the experimental tables. revision: yes
-
Referee: Abstract / §3 (three-stage pipeline): the description states that the network 'employs' speaker identity information for FiLM calibration and modality gating, yet supplies no mechanism for obtaining reliable speaker identity or embeddings at inference time when labels are unavailable (standard ERC test setting). If identity is oracle-provided or produced by an auxiliary network, the reported gains may be artifacts of that supervision rather than genuine adaptation; this is load-bearing for the adaptation modules.
Authors: Speaker identities are directly available from the dataset annotations in both MELD and IEMOCAP for training and testing, as is standard for these ERC benchmarks where turns are pre-labeled by speaker. The model uses these provided IDs to derive embeddings for FiLM and gating without an auxiliary network. We will add explicit text in the revised Section 3 describing the inference procedure and note compatibility with external speaker diarization if IDs are unavailable in other settings. revision: yes
-
Referee: Abstract: the weakest assumption—that speaker identity can be extracted and used to calibrate features and adjust modality trust without introducing new biases—is left unaddressed, as no details are given on whether an auxiliary speaker encoder is trained jointly or how errors in identity prediction would propagate into the FiLM parameters and gating weights.
Authors: No auxiliary speaker encoder is trained jointly; identities come directly from dataset labels. We will expand Section 3 in the revision to state this assumption explicitly, add a brief robustness analysis on the effect of noisy speaker IDs (simulated label flips) on FiLM and gating outputs, and discuss potential bias propagation with mitigation approaches. revision: yes
Circularity Check
No circularity: architectural proposal with empirical evaluation
full rationale
The paper introduces ML-SAN as a three-stage neural architecture (FiLM-based input calibration, speaker-identity gating, and output regularization) without any derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness claims. All performance claims rest on standard benchmark results on MELD and IEMOCAP rather than tautological reductions; speaker adaptation is described as a design choice, not a re-expression of pre-fitted quantities. No equations or self-referential steps appear in the provided text that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- FiLM modulation parameters
- Modality gating weights
axioms (2)
- domain assumption Speaker identity can be used to adjust raw multimodal features into a neutral space without loss of emotion-relevant information
- domain assumption Modality reliability varies systematically with speaker identity in a way that can be learned from training data
invented entities (1)
-
ML-SAN three-stage architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Language Resources and Evaluation42(4), 335–359 (2008)
Busso, C., Bulut, M., Lee, C.C., Kazemzadeh, A., Provost, E.M., Kim, S.: Iemocap: Interactive emotional dyadic motion capture database. Language Resources and Evaluation42(4), 335–359 (2008)
2008
-
[2]
In: 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Cao, Y., Li, Y., Wang, L., Yu, Y.: Vnet: A gan-based multi-tier discriminator network for speech synthesis vocoders. In: 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC). pp. 4384–4389. IEEE (2024)
2024
-
[3]
Applied Acoustics43(05), 997– 1007 (2024)
Fang, C., Jin, Y., Zhao, L., Ma, Y., Li, S., Gu, Y.: Multimodal speech emotion recognition based on text feature energy encoding. Applied Acoustics43(05), 997– 1007 (2024)
2024
-
[4]
In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Ghosal, D., Majumder, N., Poria, S., Chhaya, N., Gelbukh, A.: Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). pp. 154–164 (2019)
2019
-
[5]
In: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Gu, J., Li, C.H., Fu, B., Ling, Z.H.: Speaker-aware bert for emotion recognition in conversation. In: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 7687–7691 (2022)
2022
-
[6]
Data Acquisition and Processing37(06), 1353–1362 (2022)
Gu, Y., Jin, Y., Ma, Y., Jiang, F., Yu, J.: Multimodal emotion recognition based on acoustic and textual features. Data Acquisition and Processing37(06), 1353–1362 (2022)
2022
-
[7]
Computer Engineering49(07), 94–101 (2023)
Guo, Y., Jin, Y., Tang, H., Peng, J.: Multimodal emotion recognition based on dynamic convolution and residual gating. Computer Engineering49(07), 94–101 (2023)
2023
-
[8]
In: Proceedings of the 2022ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP)
Hu, G., Lin, T.E., Zhao, Y., Lu, G., Wu, Y., Li, Y.: Unimse: Towards unified multimodal sentiment analysis and emotion recognition. In: Proceedings of the 2022ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP). pp. 7837–7851 (2022)
2022
-
[9]
In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL)
Hu, J., Liu, Y., Zhao, J., Jin, Q.: Mmgcn: Multimodal fusion via deep graph con- volution network for emotion recognition in conversation. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL). pp. 5666–5675 (2021)
2021
-
[10]
In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics
Joshi, A., Bhat, A., Jain, A., Singh, A., Modi, A.: Cogmen: Contextualized gnn- based multimodal emotion recognition. In: Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics. pp. 4148–4164 (2022)
2022
-
[11]
Education and Information Technologies30(10), 1–32 (2025)
Kapila, R.V., Jayashree, P.: Multimodal emotion recognition system for e-learning platform. Education and Information Technologies30(10), 1–32 (2025)
2025
-
[12]
Neural Computing and Applications37(21), 1–28 (2025)
Kim, T., Moon, E., Kang, H., Kim, H.S.: Omer-npu: on-device multimodal emotion recognition on neural processing unit for low latency and power consumption. Neural Computing and Applications37(21), 1–28 (2025)
2025
-
[13]
International Journal of Information Technology17(5), 1–8 (2025)
Kulkarni, S., Khot, S.S., Angal, Y.: Emotion recognition with hybrid attentional multimodal fusion framework using cognitive augmentation. International Journal of Information Technology17(5), 1–8 (2025)
2025
-
[14]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
Li, D., et al.: Dual-gats: Dual graph attention networks for emotion recognition in conversations. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). pp. 1–12 (2023)
2023
-
[15]
Data Analysis and Knowledge Discovery8(11), 11–21 (2024)
Li, H., Pang, J.: Research on multimodal emotion recognition based on text, image and audio fusion. Data Analysis and Knowledge Discovery8(11), 11–21 (2024)
2024
-
[16]
In: International Conference on Neural Information Processing
Li, J., Yu, Y., Wang, L., Sun, F., Zheng, W.: Audio-guided dynamic modality fusion with stereo-aware attention for audio-visual navigation. In: International Conference on Neural Information Processing. pp. 346–359. Springer (2025)
2025
-
[17]
Journal of Shaanxi University of Science and Technol- ogy43(01), 161–168 (2025)
Li, J., Chen, J., Bai, Y.: Multimodal emotion recognition based on tcn-bi-gru and cross-attention transformer. Journal of Shaanxi University of Science and Technol- ogy43(01), 161–168 (2025)
2025
-
[18]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)
Li, T., Huang, S.L.: Multiemo: An attention-based correlation-aware multimodal fusion framework for emotion recognition in conversations. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL). pp. 14752–14766 (2023)
2023
-
[19]
In: ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Li, Y., Zhao, J., Jin, Q.: Robust multimodal emotion recognition with missing modalities. In: ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5 (2024)
2024
-
[20]
Biomedical Signal Processing and Control103, 107462 (2025)
Lian, Y., Zhu, M., Sun, Z., Liu, J., Hou, Y.: Emotion recognition based on eeg signals and face images. Biomedical Signal Processing and Control103, 107462 (2025)
2025
-
[21]
Control and Decision39(04), 1057–1074 (2024)
Lin, M., Xu, J., Lin, J., Liu, J., Xu, Z.: A review of learner emotion recognition for online education. Control and Decision39(04), 1057–1074 (2024)
2024
-
[22]
Fudan Journal (Natural Sciences)59(05), 565–574 (2020)
Liu, J., Wu, X.: Multimodal emotion recognition and spatial annotation based on long short-term memory networks. Fudan Journal (Natural Sciences)59(05), 565–574 (2020)
2020
-
[23]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Majumder, N., Poria, S., Hazarika, D., Mihalcea, R., Gelbukh, A., Cambria, E.: Dialoguernn: An attentive rnn for emotion detection in conversations. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 6818–6825 (2019)
2019
-
[24]
In: 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC)
Mattursun, A., Wang, L., Yu, Y.: Bss-cffma: cross-domain feature fusion and multi- attention speech enhancement network based on self-supervised embedding. In: 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC). pp. 3589–3594. IEEE (2024)
2024
-
[25]
Simon and Schuster (1985)
Minsky, M.: The Society of Mind. Simon and Schuster (1985)
1985
-
[26]
In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL)
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A., Morency, L.P.: Context-dependent sentiment analysis in user-generated videos. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL). pp. 873–883 (2017)
2017
-
[27]
Association for Computational Linguistics (2017)
Poria, S., Cambria, E., Hazarika, D., Majumder, N., Zadeh, A., Morency, L.P.: Context-dependent sentiment analysis in user-generated videos. Association for Computational Linguistics (2017)
2017
-
[28]
In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL)
Poria, S., Hazarika, D., Majumder, N., Naik, G., Cambria, E., Mihalcea, R.: Meld: A multimodal multi-party dataset for emotion recognition in conversations. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL). pp. 527–536 (2019)
2019
-
[29]
Intelligent Systems with Applications24, 200436 (2024)
Shang, Y., Fu, T.: Multimodal fusion: A study on speech-text emotion recognition with the integration of deep learning. Intelligent Systems with Applications24, 200436 (2024)
2024
-
[30]
Information Theory and Practice pp
Su, Y., Han, C., Li, A., Dong, X., Liu, H., Zhang, Y.: Research on multimodal sen- timent recognition of text and images based on large language model enhancement and multi-feature cross-fusion. Information Theory and Practice pp. 1–16 (2025)
2025
-
[31]
Journal of Electronics and Information Technology46(02), 588–601 (2024)
Sun, Q., Wang, S.: Self-supervised multimodal emotion recognition combining temporal attention mechanism and unimodal label automatic generation strategy. Journal of Electronics and Information Technology46(02), 588–601 (2024)
2024
-
[32]
IEEE Transactions on Computational Social Systems (2024)
Sun, X., et al.: M3gat: Multimodal multi-view graph attention network for emotion recognition in conversation. IEEE Transactions on Computational Social Systems (2024)
2024
-
[33]
In: ICASSP 2025-2025 IEEEInternational Conference on Acoustics, Speech and Signal Processing (ICASSP)
Wang, X., Wang, L., Yu, Y., Jiao, X.: Modality-invariant bidirectional temporal representation distillation network for missing multimodal sentiment analysis. In: ICASSP 2025-2025 IEEEInternational Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025)
2025
-
[34]
Computer Engineering pp
Wang, Y., Wang, L.: Multimodal emotion recognition based on cross-modal en- hancement and time-step gating. Computer Engineering pp. 1–11 (2025)
2025
-
[35]
Journal of Northwest University (Natural Science Edition)54(02), 177–187 (2024)
Wu, X., Mou, X., Liu, Y., Liu, X.: A multimodal emotion recognition algorithm based on speech, text, and facial expressions. Journal of Northwest University (Natural Science Edition)54(02), 177–187 (2024)
2024
-
[36]
Journal of Shaanxi University of Science and Tech- nology42(01), 169–176 (2024)
Xue, W., Chen, J., Hu, K., Liu, Y.: Multimodal continuous emotion recognition based on eeg and facial video. Journal of Shaanxi University of Science and Tech- nology42(01), 169–176 (2024)
2024
-
[37]
Computer Applications and Research38(06), 1689–1693 (2021)
Yao, Y., Guo, W.: A multimodal emotion recognition algorithm based on interac- tive attention mechanism. Computer Applications and Research38(06), 1689–1693 (2021)
2021
-
[38]
In: The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022 (2022)
Yu, Y., Huang, W., Sun, F., Chen, C., Wang, Y., Liu, X.: Sound adversarial audio- visual navigation. In: The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022 (2022)
2022
-
[39]
Dynamic multi-target fusion for efficient audio-visual navigation,
Yu, Y., Zhang, H., Zhu, M.: Dynamic multi-target fusion for efficient audio-visual navigation. arXiv preprint arXiv:2509.21377 (2025)
-
[40]
In: International Conference on Neural Information Processing
Zhang, H., Yu, Y., Wang, L., Sun, F., Zheng, W.: Advancing audio-visual nav- igation through multi-agent collaboration in 3d environments. In: International Conference on Neural Information Processing. pp. 502–516. Springer (2025)
2025
-
[41]
Zhang, H., Yu, Y., Wang, L., Sun, F., Zheng, W.: Iterative residual cross- attention mechanism: An integrated approach for audio-visual navigation tasks. arXiv preprint arXiv:2509.25652 (2025)
-
[42]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhao, W., Zhao, Y., Lu, X., Wang, S., Tong, Y., Qin, B.: Instructerc: Reforming emotion recognition in conversation with a retrieval multi-task llms framework. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 19643– 19651 (2024)
2024
-
[43]
Microelectronics and Computer32(06), 5–9 (2015)
Zhou, H.: Research on multimodal emotion recognition integrating speech and pulse. Microelectronics and Computer32(06), 5–9 (2015)
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.