Recognition: unknown
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Pith reviewed 2026-05-07 16:07 UTC · model grok-4.3
The pith
GS-Playground reaches 10,000 frames per second of photorealistic rendering inside a parallel physics simulator for vision-based robot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
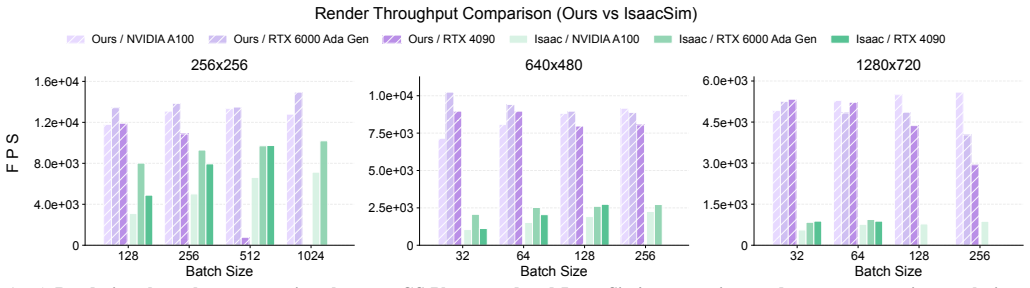
GS-Playground is a multi-modal framework whose parallel physics engine integrates directly with a batch 3D Gaussian Splatting rendering pipeline to deliver synchronized, photorealistic images at 10^4 FPS at 640x480 resolution. An automated Real2Sim workflow reconstructs complex environments that are simultaneously photorealistic, physically consistent, and memory-efficient. Experiments across locomotion, navigation, and manipulation tasks show that policies trained in the system close the perceptual and physical gaps that have limited prior simulators.
What carries the argument
Batch 3D Gaussian Splatting rendering pipeline integrated with a custom parallel physics engine, which produces synchronized visual and physical states at high throughput while preserving fidelity.
Load-bearing premise
The batch rendering pipeline and physics engine stay synchronized at full speed without measurable loss of visual or physical accuracy, and the automated Real2Sim scenes are consistent enough for policies to transfer successfully to real robots.
What would settle it
Measure end-to-end training throughput and sim-to-real success rate for a contact-rich manipulation policy; if FPS falls below 2000 or transfer success is no better than prior simulators under identical compute, the central performance claim does not hold.
Figures
















read the original abstract
Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GS-Playground, a multi-modal simulation framework for vision-informed robot learning. It combines a custom parallel physics engine with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to achieve claimed high-throughput photorealistic simulation, reports a throughput of 10^4 FPS at 640x480 resolution, presents an automated Real2Sim workflow for reconstructing photorealistic and physically consistent environments, and evaluates the system on locomotion, navigation, and manipulation tasks to demonstrate bridging of perceptual and physical gaps.
Significance. If the throughput, synchronization fidelity, and policy-transfer results hold under rigorous validation, the work could meaningfully advance large-scale visual RL by reducing rendering overhead and manual asset creation, enabling more realistic sim-to-real transfer in contact-rich settings. The automated Real2Sim pipeline, if shown to produce memory-efficient and consistent scenes, represents a practical contribution to simulation asset generation.
major comments (2)
- [Abstract] Abstract: The headline claim of 10^4 FPS throughput at 640x480 resolution is presented as arising from the novel batch 3DGS + parallel physics integration, yet the abstract supplies no quantitative results, baselines, error bars, or experimental details on achieved FPS, rendering latency, or physics update rates. This absence prevents evaluation of the central performance claim.
- [Method (batch 3DGS rendering pipeline integration with parallel physics engine)] Method (batch 3DGS rendering pipeline integration with parallel physics engine): The claim that the integration delivers high-fidelity synchronization without loss of speed or visual/physical accuracy is load-bearing for the throughput result. No quantitative bounds on maximum frame-to-physics lag, desync error metrics, ablation studies isolating synchronization overhead, or comparisons of rendered depth/normal consistency against non-batched baselines in contact-rich regimes are referenced, leaving open the possibility that modest desynchronization under locomotion or manipulation loads would undermine the reported performance while preserving the required fidelity.
minor comments (2)
- [Abstract] Abstract: The statement that 'extensive experiments... demonstrate that GS-Playground effectively bridges the perceptual and physical gaps' is not accompanied by any summary statistics, success rates, or comparison to prior simulators.
- [Abstract] The project homepage is referenced but no information on code release, reproducibility artifacts, or dataset availability is provided in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of 10^4 FPS throughput at 640x480 resolution is presented as arising from the novel batch 3DGS + parallel physics integration, yet the abstract supplies no quantitative results, baselines, error bars, or experimental details on achieved FPS, rendering latency, or physics update rates. This absence prevents evaluation of the central performance claim.
Authors: The abstract is a high-level summary, while the full quantitative evaluation—including the 10^4 FPS measurement at 640x480, comparisons against baseline simulators, error bars from multiple runs, rendering latency, and physics update rates—is provided in the Experiments section with supporting tables and figures. To improve immediate evaluability of the central claim, we will revise the abstract to include concise references to these metrics and experimental conditions. revision: partial
-
Referee: [Method (batch 3DGS rendering pipeline integration with parallel physics engine)] Method (batch 3DGS rendering pipeline integration with parallel physics engine): The claim that the integration delivers high-fidelity synchronization without loss of speed or visual/physical accuracy is load-bearing for the throughput result. No quantitative bounds on maximum frame-to-physics lag, desync error metrics, ablation studies isolating synchronization overhead, or comparisons of rendered depth/normal consistency against non-batched baselines in contact-rich regimes are referenced, leaving open the possibility that modest desynchronization under locomotion or manipulation loads would undermine the reported performance while preserving the required fidelity.
Authors: The parallel physics engine and batch 3DGS pipeline are explicitly co-designed for lockstep updates, with the reported 10^4 FPS achieved on contact-rich locomotion, navigation, and manipulation tasks serving as indirect evidence that synchronization overhead remains negligible. However, we acknowledge that explicit quantitative validation would strengthen the claim. In the revised manuscript we will add: (i) measured bounds on frame-to-physics lag, (ii) desync error metrics (position/velocity discrepancies), (iii) ablation studies isolating synchronization overhead, and (iv) depth/normal consistency comparisons against non-batched baselines under manipulation loads. revision: yes
Circularity Check
No circularity; claims rest on implementation and empirical validation
full rationale
The paper is a systems contribution describing an integrated simulator (batch 3DGS rendering + parallel physics engine) and an automated Real2Sim workflow. No mathematical derivations, equations, fitted parameters presented as predictions, or first-principles results appear in the abstract or method descriptions. Throughput figures and synchronization claims are presented as measured outcomes of the implementation rather than derived quantities that reduce to their own inputs. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is used to justify core claims. The central assertions are externally falsifiable via benchmarks on locomotion, navigation, and manipulation tasks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Batch 3D Gaussian Splatting can be integrated with a parallel physics engine to maintain high-fidelity visual and physical synchronization at scale.
- domain assumption An automated Real2Sim workflow can produce photorealistic yet physically consistent and memory-efficient simulation environments suitable for policy transfer.
Reference graph
Works this paper leans on
-
[1]
Real-is-sim: Bridging the sim-to-real gap with a dynamic digital twin,
Jad Abou-Chakra, Lingfeng Sun, Krishan Rana, Brandon May, Karl Schmeckpeper, Maria Vittoria Minniti, and Laura Herlant. Real-is-sim: Bridging the sim-to-real gap with a dynamic digital twin for real-world robot policy evaluation.arXiv preprint arXiv:2504.03597, 2025
- [2]
-
[3]
Leonardo Barcellona, Andrii Zadaianchuk, Davide Al- legro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Compositional world models empowering robot imitation learning with imag- ination.arXiv preprint arXiv:2412.14957, 2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π0: A vision-language-action flow model for general robot con- trol. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV .2410.24164
work page internal anchor Pith review arXiv 2024
-
[5]
NavDP: Learning sim-to-real navigation diffusion policy with privileged information guidance
Wenzhe Cai, Jiaqi Peng, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, and Jiangmiao Pang. NavDP: Learning sim-to-real navigation diffusion policy with privileged information guidance. arXiv preprint arXiv:2501.04610, 2025
-
[6]
Zhanxiang Cao, Yang Zhang, Buqing Nie, Huangxuan Lin, Haoyang Li, and Yue Gao. Learning motion skills with adaptive assistive curriculum force in humanoid robots.arXiv preprint arXiv:2506.23125, 2025
-
[7]
Visual dexterity: In- hand reorientation of novel and complex object shapes
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Ed- ward Adelson, and Pulkit Agrawal. Visual dexterity: In- hand reorientation of novel and complex object shapes. Science Robotics, 8(84):eadc9244, 2023
2023
-
[8]
SAM 3D: 3Dfy Anything in Images
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Navila: Legged robot vision-language- action model for navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. Navila: Legged robot vision-language- action model for navigation. InRSS, 2025
2025
-
[10]
Learning quadrupedal locomotion on deformable terrain.Science Robotics, 8(74):eade2256, 2023
Suyoung Choi, Gwanghyeon Ji, Jeongsoo Park, Hyeongjun Kim, Juhyeok Mun, Jeong Hyun Lee, and Jemin Hwangbo. Learning quadrupedal locomotion on deformable terrain.Science Robotics, 8(74):eade2256, 2023
2023
-
[11]
Alejandro Escontrela, Justin Kerr, Arthur Allshire, Jonas Frey, Rocky Duan, Carmelo Sferrazza, and Pieter Abbeel. Gaussgym: An open-source real-to-sim frame- work for learning locomotion from pixels.arXiv preprint arXiv:2510.15352, 2025
-
[12]
Mini-splatting: Repre- senting scenes with a constrained number of gaussians
Guangchi Fang and Bing Wang. Mini-splatting: Repre- senting scenes with a constrained number of gaussians. InEuropean Conference on Computer Vision, pages 165–
-
[13]
Xiaoshen Han, Minghuan Liu, Yilun Chen, Junqiu Yu, Xiaoyang Lyu, Yang Tian, Bolun Wang, Weinan Zhang, and Jiangmiao Pang. Re 3 sim: Generating high-fidelity simulation data via 3d-photorealistic real-to-sim for robotic manipulation.arXiv preprint arXiv:2502.08645, 2025
-
[14]
Speedy-splat: Fast 3d gaussian splatting with sparse pixels and sparse primi- tives
Alex Hanson, Allen Tu, Geng Lin, Vasu Singla, Matthias Zwicker, and Tom Goldstein. Speedy-splat: Fast 3d gaussian splatting with sparse pixels and sparse primi- tives. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21537–21546, 2025
2025
-
[15]
Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting
Alex Hanson, Allen Tu, Vasu Singla, Mayuka Jayaward- hana, Matthias Zwicker, and Tom Goldstein. Pup 3d-gs: Principled uncertainty pruning for 3d gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5949–5958, 2025
2025
-
[16]
Available: https://arxiv.org/abs/2502.01143
Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Sobanbab, Chaoyi Pan, et al. Asap: Aligning simula- tion and real-world physics for learning agile humanoid whole-body skills.arXiv preprint arXiv:2502.01143, 2025
-
[17]
Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv: 2511.15200,
Tairan He, Zi Wang, Haoru Xue, Qingwei Ben, Zhengyi Luo, Wenli Xiao, Ye Yuan, Xingye Da, Fernando Casta˜neda, Shankar Sastry, et al. Viral: Visual sim-to-real at scale for humanoid loco-manipulation.arXiv preprint arXiv:2511.15200, 2025
-
[18]
Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
Jemin Hwangbo, Joonho Lee, Alexey Dosovitskiy, Dario Bellicoso, Vassilios Tsounis, Vladlen Koltun, and Marco Hutter. Learning agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019
2019
-
[19]
Discoverse: Efficient robot simulation in complex high-fidelity environments,
Yufei Jia, Guangyu Wang, Yuhang Dong, Junzhe Wu, Yupei Zeng, Haonan Lin, Zifan Wang, Haizhou Ge, Weibin Gu, Kairui Ding, et al. Discoverse: Efficient robot simulation in complex high-fidelity environments.arXiv preprint arXiv:2507.21981, 2025
-
[20]
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Guangqi Jiang, Haoran Chang, Ri-Zhao Qiu, Yutong Liang, Mazeyu Ji, Jiyue Zhu, Zhao Dong, Xueyan Zou, and Xiaolong Wang. Gsworld: Closed-loop photo- realistic simulation suite for robotic manipulation.arXiv preprint arXiv:2510.20813, 2025
-
[21]
Hanxiao Jiang, Hao-Yu Hsu, Kaifeng Zhang, Hsin-Ni Yu, Shenlong Wang, and Yunzhu Li. Phystwin: Physics- informed reconstruction and simulation of deformable objects from videos.arXiv preprint arXiv:2503.17973, 2025
-
[22]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Transactions on Graphics (TOG), 44(6):1–16, 2025
2025
-
[23]
Robust in-hand reorientation with hi- erarchical rl-based motion primitives and model-based regrasping.IEEE Robotics and Automation Practice, 1: 12–17, 2025
Yongpeng Jiang, Mingrui Yu, Chen Chen, Yongyi Jia, and Xiang Li. Robust in-hand reorientation with hi- erarchical rl-based motion primitives and model-based regrasping.IEEE Robotics and Automation Practice, 1: 12–17, 2025
2025
-
[24]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139– 1, 2023
2023
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Rma: Rapid motor adaptation for legged robots,
Ashish Kumar, Zipeng Fu, Deepak Pathak, and Jitendra Malik. Rma: Rapid motor adaptation for legged robots. arXiv preprint arXiv:2107.04034, 2021
-
[28]
arXiv preprint arXiv:2509.09674 , year=
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhao- hui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
-
[29]
Robogsim: A real2sim2real robotic gaus- sian splatting simulator,
Xinhai Li, Jialin Li, Ziheng Zhang, Rui Zhang, Fan Jia, Tiancai Wang, Haoqiang Fan, Kuo-Kun Tseng, and Ruip- ing Wang. Robogsim: A real2sim2real robotic gaussian splatting simulator.arXiv preprint arXiv:2411.11839, 2024
-
[30]
CLONE: Closed-loop whole-body humanoid teleoperation for long-horizon tasks
Yixuan Li, Yutang Lin, Jieming Cui, Tengyu Liu, Wei Liang, Yixin Zhu, and Siyuan Huang. CLONE: Closed-loop whole-body humanoid teleoperation for long-horizon tasks. In9th Annual Conference on Robot Learning (CoRL), 2025
2025
-
[31]
Chenguo Lin, Panwang Pan, Bangbang Yang, Zeming Li, and Yadong Mu. Diffsplat: Repurposing image diffusion models for scalable gaussian splat generation.arXiv preprint arXiv:2501.16764, 2025
-
[32]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review arXiv 2023
-
[33]
Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid rep- resentation
Haozhe Lou, Yurong Liu, Yike Pan, Yiran Geng, Jianteng Chen, Wenlong Ma, Chenglong Li, Lin Wang, Hengzhen Feng, Lu Shi, et al. Robo-gs: A physics consistent spatial-temporal model for robotic arm with hybrid rep- resentation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15379–15386. IEEE, 2025
2025
-
[34]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review arXiv 2021
-
[35]
Walk these ways: Tuning robot control for generalization with mul- tiplicity of behavior
Gabriel B Margolis and Pulkit Agrawal. Walk these ways: Tuning robot control for generalization with mul- tiplicity of behavior. InConference on Robot Learning, pages 22–31. PMLR, 2023
2023
-
[36]
Rapid locomotion via reinforcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
Gabriel B Margolis, Ge Yang, Kartik Paigwar, Tao Chen, and Pulkit Agrawal. Rapid locomotion via reinforcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
2024
-
[37]
Jan Matas, Stephen James, and Andrew J. Davison. Sim-to-real reinforcement learning for deformable object manipulation. InConference on Robot Learning (CoRL), pages 734–743. PMLR, 2018
2018
-
[38]
Sharp monocular view synthesis in less than a second.arXiv preprint arXiv:2512.10685, 2025
Lars Mescheder, Wei Dong, Shiwei Li, Xuyang Bai, Marcel Santos, Peiyun Hu, Bruno Lecouat, Mingmin Zhen, Ama ˜AG ¸ l Delaunoy, Tian Fang, et al. Sharp monocular view synthesis in less than a second.arXiv preprint arXiv:2512.10685, 2025
-
[39]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Splat- sim: Zero-shot sim2real transfer of rgb manipulation poli- cies using gaussian splatting
M Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, and Abhisesh Silwal. Splat- sim: Zero-shot sim2real transfer of rgb manipulation poli- cies using gaussian splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6502–6509. IEEE, 2025
2025
-
[42]
URL https://arxiv.org/abs/2408.00714
work page internal anchor Pith review arXiv
-
[43]
An ex- tensible, data-oriented architecture for high-performance, many-world simulation.ACM Transactions on Graphics (TOG), 42(4):1–13, 2023
Brennan Shacklett, Luc Guy Rosenzweig, Zhiqiang Xie, Bidipta Sarkar, Andrew Szot, Erik Wijmans, Vladlen Koltun, Dhruv Batra, and Kayvon Fatahalian. An ex- tensible, data-oriented architecture for high-performance, many-world simulation.ACM Transactions on Graphics (TOG), 42(4):1–13, 2023
2023
-
[44]
Jonah Siekmann, Kevin Green, John Warila, Alan Fern, and Jonathan Hurst. Blind bipedal stair traversal via sim-to-real reinforcement learning.arXiv preprint arXiv:2105.08328, 2021
-
[45]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silve- strov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions.arXiv preprint arXiv:2109.07161, 2021
-
[46]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Viswesh Na- gaswamy Rajesh, Yong Woo Choi, Yen-Ru Chen, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. Maniskill3: Gpu parallelized robotics simulation and...
2025
-
[47]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012
2012
-
[48]
Bridgedata v2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen- Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[49]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Confer- ence, pages 5294–5306, 2025
2025
-
[50]
Arm-constrained curriculum learning for loco- manipulation of a wheel-legged robot
Zifan Wang, Yufei Jia, Lu Shi, Haoyu Wang, Haizhou Zhao, Xueyang Li, Jinni Zhou, Jun Ma, and Guyue Zhou. Arm-constrained curriculum learning for loco- manipulation of a wheel-legged robot. In2024 IEEE/RSJ International Conference on Intelligent Robots and Sys- tems (IROS), pages 10770–10776. IEEE, 2024
2024
-
[51]
Zifan Wang, Teli Ma, Yufei Jia, Xun Yang, Jiaming Zhou, Wenlong Ouyang, Qiang Zhang, and Junwei Liang. Omni-perception: Omnidirectional collision avoidance for legged locomotion in dynamic environments.arXiv preprint arXiv:2505.19214, 2025
-
[52]
Opening the sim- to-real door for humanoid pixel-to-action policy transfer
Haoru Xue, Tairan He, Zi Wang, Qingwei Ben, Wenli Xiao, Zhengyi Luo, Xingye Da, Fernando Casta ˜neda, Guanya Shi, Shankar Sastry, et al. Opening the sim- to-real door for humanoid pixel-to-action policy transfer. arXiv preprint arXiv:2512.01061, 2025
-
[53]
Novel demonstration generation with gaussian splatting enables robust one-shot manipulation,
Sizhe Yang, Wenye Yu, Jia Zeng, Jun Lv, Kerui Ren, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Novel demonstration generation with gaussian splatting en- ables robust one-shot manipulation.arXiv preprint arXiv:2504.13175, 2025
-
[54]
DexterityGen: Foundation controller for unprecedented dexterity
Zhao-Heng Yin, Changhao Wang, Luis Pineda, Fran- cois Hogan, Krishna Bodduluri, Akash Sharma, Patrick Lancaster, Ishita Prasad, Mrinal Kalakrishnan, Jitendra Malik, et al. DexterityGen: Foundation controller for unprecedented dexterity. InProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[55]
Real2render2real: Scaling robot data without dynamics simulation or robot hardware,
Justin Yu, Letian Fu, Huang Huang, Karim El- Refai, Rares Andrei Ambrus, Richard Cheng, Muham- mad Zubair Irshad, and Ken Goldberg. Real2render2real: Scaling robot data without dynamics simulation or robot hardware.arXiv preprint arXiv:2505.09601, 2025
-
[56]
Kevin Zakka, Baruch Tabanpour, Qiayuan Liao, Mustafa Haiderbhai, Samuel Holt, Jing Yuan Luo, Arthur All- shire, Erik Frey, Koushil Sreenath, Lueder A Kahrs, et al. Mujoco playground.arXiv preprint arXiv:2502.08844, 2025
-
[57]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language- action-critic model for robotic real-world reinforcement learning.arXiv preprint arXiv:2509.15937, 2025
-
[58]
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024
-
[59]
Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jia- hang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129, 2025
-
[60]
Kaifeng Zhang, Shuo Sha, Hanxiao Jiang, Matthew Loper, Hyunjong Song, Guangyan Cai, Zhuo Xu, Xi- aochen Hu, Changxi Zheng, and Yunzhu Li. Real- to-sim robot policy evaluation with gaussian splatting simulation of soft-body interactions.arXiv preprint arXiv:2511.04665, 2025
-
[61]
Yang Zhang, Zhanxiang Cao, Buqing Nie, Haoyang Li, Zhong Jiangwei, Qiao Sun, Xiaoyi Hu, Xiaokang Yang, and Yue Gao. Keep on going: Learning robust humanoid motion skills via selective adversarial training.arXiv preprint arXiv:2507.08303, 2025
-
[62]
Xian Zhou, Yiling Qiao, Zhenjia Xu, TH Wang, Z Chen, J Zheng, Z Xiong, Y Wang, M Zhang, P Ma, et al. Genesis: A generative and universal physics engine for robotics and beyond.arXiv preprint arXiv:2401.01454, 2024
-
[63]
Vision-language-action model with open- world embodied reasoning from pretrained knowledge
Zhongyi Zhou, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Vision-language-action model with open- world embodied reasoning from pretrained knowledge. arXiv preprint arXiv:2505.21906, 2025
-
[64]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Mart´ın-Mart´ın, Abhishek Joshi, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation frame- work and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review arXiv 2009
-
[65]
Ziwen Zhuang, Zipeng Fu, Jianren Wang, Christo- pher Atkeson, Soeren Schwertfeger, Chelsea Finn, and Hang Zhao. Robot parkour learning.arXiv preprint arXiv:2309.05665, 2023. Appendix TABLE OFCONTENTS Appendix A. Physics 13 A.1 Shaking Test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 Appendix B. 3D...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.