Recognition: unknown
Refinement via Regeneration: Enlarging Modification Space Boosts Image Refinement in Unified Multimodal Models
Pith reviewed 2026-05-07 16:51 UTC · model grok-4.3
The pith
Regenerating images from a prompt plus semantic tokens of the first output lets unified multimodal models fix misalignments more completely than editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
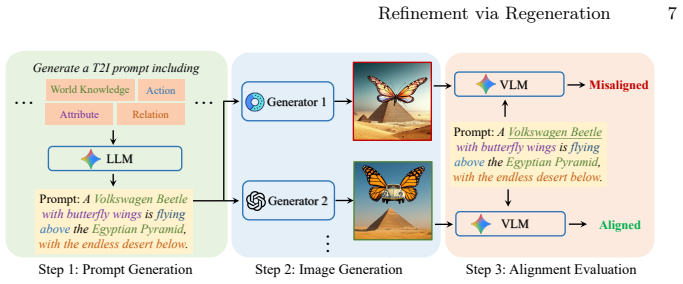
The paper claims that reformulating refinement as conditional image regeneration, conditioned on the target prompt and semantic tokens of the initial image, enables more complete semantic alignment with a larger modification space than the refinement-via-editing paradigm, which relies on coarse editing instructions and pixel-level preservation.
What carries the argument
Refinement via Regeneration (RvR) is the mechanism that produces a new image from the target prompt and semantic tokens extracted from the initial image, replacing editing instructions and strict pixel preservation.
If this is right
- Unified multimodal models can reach higher prompt-image alignment on text-to-image tasks without being limited by coarse editing instructions.
- Pixel-level preservation is unnecessary for effective refinement and can be dropped to enlarge the space of possible adjustments.
- The performance upper bound for text-to-image generation inside unified models is extended by treating refinement as full regeneration.
- Refinement no longer depends on the model first producing editing instructions that only partially describe misalignments.
Where Pith is reading between the lines
- The same regeneration logic could be tested on other generation tasks such as image editing or captioning where token-based conditioning might also expand flexibility.
- If semantic tokens prove sufficient, hybrid systems could use regeneration for global fixes and editing for local touch-ups on the same model.
- The approach implies that richer semantic extraction from initial outputs may be more valuable than stronger editing modules in future unified models.
Load-bearing premise
Semantic tokens taken from the initial image carry enough information to support high-quality regeneration while the extra freedom in changes produces net gains rather than new artifacts or lost detail.
What would settle it
A side-by-side comparison on the same set of prompts where regenerated images show lower visual quality, more artifacts, or greater loss of fine detail than images refined by the editing approach.
Figures










read the original abstract
Unified multimodal models (UMMs) integrate visual understanding and generation within a single framework. For text-to-image (T2I) tasks, this unified capability allows UMMs to refine outputs after their initial generation, potentially extending the performance upper bound. Current UMM-based refinement methods primarily follow a refinement-via-editing (RvE) paradigm, where UMMs produce editing instructions to modify misaligned regions while preserving aligned content. However, editing instructions often describe prompt-image misalignment only coarsely, leading to incomplete refinement. Moreover, pixel-level preservation, though necessary for editing, unnecessarily restricts the effective modification space for refinement. To address these limitations, we propose Refinement via Regeneration (RvR), a novel framework that reformulates refinement as conditional image regeneration rather than editing. Instead of relying on editing instructions and enforcing strict content preservation, RvR regenerates images conditioned on the target prompt and the semantic tokens of the initial image, enabling more complete semantic alignment with a larger modification space. Extensive experiments demonstrate the effectiveness of RvR, improving Geneval from 0.78 to 0.91, DPGBench from 84.02 to 87.21, and UniGenBench++ from 61.53 to 77.41.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Refinement via Regeneration (RvR) as an alternative to the dominant refinement-via-editing (RvE) paradigm in unified multimodal models for text-to-image tasks. Rather than generating editing instructions and enforcing pixel-level preservation of aligned content, RvR regenerates the full image conditioned on the target prompt together with semantic tokens extracted from the initial image. The authors argue this enlarges the effective modification space and yields more complete semantic alignment. They report large empirical gains: Geneval rises from 0.78 to 0.91, DPGBench from 84.02 to 87.21, and UniGenBench++ from 61.53 to 77.41.
Significance. If the reported gains prove robust and can be causally attributed to the regeneration paradigm rather than confounding factors, the work would offer a useful new direction for post-generation refinement in UMMs. The empirical deltas are sizable and the framing of “enlarging modification space” is conceptually clear. Credit is due for introducing a concrete alternative framework and for the scale of the benchmark improvements shown.
major comments (2)
- [Abstract] Abstract: The central claim that conditioning on semantic tokens produces a meaningfully larger modification space (as opposed to merely guided reconstruction) is load-bearing yet unsupported by any ablation, diversity metric, or visualization comparing RvR outputs to the initial image or to RvE outputs. Without such evidence it remains possible that the tokens re-introduce layout constraints and that the observed benchmark gains arise from other variables.
- [Experiments] Experiments section: The benchmark deltas are presented without any description of experimental controls, number of runs, statistical significance tests, or failure-case analysis. This omission prevents assessment of whether the improvements are stable or sensitive to post-hoc choices such as inference steps or prompt re-weighting.
minor comments (1)
- [Abstract] Abstract: A single sentence clarifying how semantic tokens are extracted (e.g., from which layer or encoder) would help readers evaluate the weakest assumption noted in the review.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the presentation of our claims and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that conditioning on semantic tokens produces a meaningfully larger modification space (as opposed to merely guided reconstruction) is load-bearing yet unsupported by any ablation, diversity metric, or visualization comparing RvR outputs to the initial image or to RvE outputs. Without such evidence it remains possible that the tokens re-introduce layout constraints and that the observed benchmark gains arise from other variables.
Authors: We agree that the manuscript would benefit from explicit empirical support for the enlarged modification space. Although the conceptual distinction between regeneration and editing is developed in the introduction and method sections, we will add a dedicated ablation subsection with diversity metrics (such as pairwise LPIPS distances and semantic variance measures) and side-by-side visualizations of RvR outputs versus both the initial image and RvE outputs. These additions will directly address whether semantic-token conditioning permits greater flexibility or inadvertently re-imposes layout constraints. revision: yes
-
Referee: [Experiments] Experiments section: The benchmark deltas are presented without any description of experimental controls, number of runs, statistical significance tests, or failure-case analysis. This omission prevents assessment of whether the improvements are stable or sensitive to post-hoc choices such as inference steps or prompt re-weighting.
Authors: We acknowledge that the current experimental reporting lacks sufficient detail on controls and robustness. In the revised manuscript we will expand the Experiments section to specify the number of independent runs, include statistical significance tests (e.g., paired t-tests across benchmarks), provide a failure-case analysis, and report sensitivity results for inference steps and prompt re-weighting. These additions will allow readers to evaluate the stability of the reported gains. revision: yes
Circularity Check
No circularity; empirical proposal without self-referential derivations
full rationale
The paper introduces RvR as a new framework reformulating refinement as conditional regeneration using target prompts and semantic tokens, then validates it solely via benchmark gains (Geneval 0.78→0.91, etc.). No equations, parameter fits, uniqueness theorems, or ansatzes are described that could reduce to inputs by construction. The derivation chain consists of a conceptual reformulation plus experimental demonstration; nothing is shown to be equivalent to prior fitted quantities or self-citations. This is self-contained against external benchmarks and matches the expected non-finding for method papers lacking mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic tokens extracted from an initial image provide adequate conditioning information for high-quality regeneration aligned to a new prompt.
invented entities (1)
-
Refinement via Regeneration (RvR) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
In: ICCV (2015)
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: VQA: Visual question answering. In: ICCV (2015)
2015
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
OpenAI technical report (2023)
Betker, J., Goh, G., Jing, L., Brooks, T., Wang, J., Li, L., Ouyang, L., Zhuang, J., Lee, J., Guo, Y., et al.: Improving image generation with better captions. OpenAI technical report (2023)
2023
-
[5]
Hunyuanimage 3.0 technical report.arXiv preprint arXiv:2509.23951, 2025
Cao, S., Chen, H., Chen, P., Cheng, Y., Cui, Y., Deng, X., Dong, Y., Gong, K., Gu, T., Gu, X., et al.: Hunyuanimage 3.0 technical report. arXiv preprint arXiv:2509.23951 (2025)
-
[6]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multimodal models- architecture, training and dataset, 2025. URL https://arxiv. org/abs/2505.09568 (2025)
work page internal anchor Pith review arXiv 2025
-
[7]
Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
Chen, J., Xue, L., Xu, Z., Pan, X., Yang, S., Qin, C., Yan, A., Zhou, H., Chen, Z., Huang, L., et al.: Blip3o-next: Next frontier of native image generation. arXiv preprint arXiv:2510.15857 (2025)
-
[8]
In: ICLR (2024)
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In: ICLR (2024)
2024
-
[9]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review arXiv 2025
-
[11]
Emu: Enhanc- ing image generation models using photogenic needles in a haystack
Dai, X., Hou, J., Ma, C.Y., Tsai, S., Wang, J., Wang, R., Zhang, P., Vandenhende, S., Wang, X., Dubey, A., et al.: Emu: Enhancing image generation models using photogenic needles in a haystack. arXiv:2309.15807 (2023)
-
[12]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025)
work page internal anchor Pith review arXiv 2025
-
[13]
In: ICLR (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: ICLR (2021)
2021
-
[14]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al.: The llama 3 herd of mod- els. arXiv:2407.21783 (2024)
work page internal anchor Pith review arXiv 2024
-
[15]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[16]
Ge,Y.,Zhao,S.,Zhu,J.,Ge,Y.,Yi,K.,Song,L.,Li,C.,Ding,X.,Shan,Y.:Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396 (2024) 16 J. Guo et al
-
[17]
In: NeurIPS (2023)
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. In: NeurIPS (2023)
2023
-
[18]
In: NeurIPS (2014)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. In: NeurIPS (2014)
2014
-
[19]
IEEE Transactions on Circuits and Systems for Video Technology (2023)
Guo, J., Manukyan, H., Yang, C., Wang, C., Khachatryan, L., Navasardyan, S., Song, S., Shi, H., Huang, G.: Faceclip: Facial image-to-video translation via a brief text description. IEEE Transactions on Circuits and Systems for Video Technology (2023)
2023
-
[20]
In: CVPR (2024)
Guo, J., Xu, X., Pu, Y., Ni, Z., Wang, C., Vasu, M., Song, S., Huang, G., Shi, H.: Smooth diffusion: Crafting smooth latent spaces in diffusion models. In: CVPR (2024)
2024
-
[21]
In: CVPR (2025)
Guo, J., Yan, C., Xu, X., Wang, Y., Wang, K., Huang, G., Shi, H.: Img: Calibrating diffusion models via implicit multimodal guidance. In: CVPR (2025)
2025
-
[22]
In: NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
2020
-
[23]
In: NeurIPS Workshops (2021)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. In: NeurIPS Workshops (2021)
2021
-
[24]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv:2403.05135 (2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Interleaving reasoning for better text-to-image generation
Huang, W., Chen, S., Xie, Z., Cao, S., Tang, S., Shen, Y., Yin, Q., Hu, W., Wang, X., Tang, Y., et al.: Interleaving reasoning for better text-to-image generation. arXiv preprint arXiv:2509.06945 (2025)
-
[26]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review arXiv 2024
-
[27]
In: ICLR (2015)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: ICLR (2015)
2015
-
[28]
Labs, B.F.: Flux.https://blackforestlabs.ai/(2024)
2024
-
[29]
Liu, H., Yan, W., Zaharia, M., Abbeel, P.: World model on million-length video and language with blockwise ringattention. arXiv preprint arXiv:2402.08268 (2024)
-
[30]
In: NeurIPS (2024)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: NeurIPS (2024)
2024
-
[31]
In: ICLR (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2022)
2022
-
[32]
In: ICLR (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: ICLR (2019)
2019
-
[33]
arXiv preprint arXiv:2509.18639 (2025)
Lyu, Y., Wong, C.K., Liao, C., Jiang, L., Zheng, X., Lu, Z., Zhang, L., Hu, X.: Understanding-in-generation: Reinforcing generative capability of unified model via infusing understanding into generation. arXiv preprint arXiv:2509.18639 (2025)
-
[34]
Ma, Y., Liu, X., Chen, X., Liu, W., Wu, C., Wu, Z., Pan, Z., Xie, Z., Zhang, H., yu, X., Zhao, L., Wang, Y., Liu, J., Ruan, C.: Janusflow: Harmonizing autoregres- sion and rectified flow for unified multimodal understanding and generation. arXiv preprint arXiv:2411.07975 (2024)
-
[35]
In: ICML (2022)
Nichol, A.Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., Mcgrew, B., Sutskever, I., Chen, M.: GLIDE: Towards photorealistic image generation and edit- ing with text-guided diffusion models. In: ICML (2022)
2022
-
[36]
Transfer between Modalities with MetaQueries
Pan, X., Shukla, S.N., Singh, A., Zhao, Z., Mishra, S.K., Wang, J., Xu, Z., Chen, J., Li, K., Juefei-Xu, F., Hou, J., Xie, S.: Transfer between modalities with meta- queries. arXiv preprint arXiv:2504.06256 (2025)
work page internal anchor Pith review arXiv 2025
-
[37]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[38]
In: ICLR (2023) Refinement via Regeneration 17
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. In: ICLR (2023) Refinement via Regeneration 17
2023
-
[39]
Qin, L., Gong, J., Sun, Y., Li, T., Yang, M., Yang, X., Qu, C., Tan, Z., Li, H.: Uni-cot: Towards unified chain-of-thought reasoning across text and vision. arXiv preprint arXiv:2508.05606 (2025)
-
[40]
In: CVPR (2025)
Qu, L., Zhang, H., Liu, Y., Wang, X., Jiang, Y., Gao, Y., Ye, H., Du, D.K., Yuan, Z., Wu, X.: Tokenflow: Unified image tokenizer for multimodal understanding and generation. In: CVPR (2025)
2025
-
[41]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[42]
JMLR (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR (2020)
2020
-
[44]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv:2204.06125 (2022)
work page internal anchor Pith review arXiv 2022
-
[45]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[46]
In: NeurIPS (2017)
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: NeurIPS (2017)
2017
-
[47]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024)
work page internal anchor Pith review arXiv 2024
-
[48]
In: ICCV (2025)
Wang, C., Lu, G., Yang, J., Huang, R., Han, J., Hou, L., Zhang, W., Xu, H.: Illume: Illuminating your llms to see, draw, and self-enhance. In: ICCV (2025)
2025
-
[49]
In: ICML (2025)
Wang, J., Pu, J., Qi, Z., Guo, J., Ma, Y., Huang, N., Chen, Y., Li, X., Shan, Y.: Taming rectified flow for inversion and editing. In: ICML (2025)
2025
-
[50]
arXiv preprint arXiv:2509.04545 (2025)
Wang, L., Xing, X., Cheng, Y., Zhao, Z., Li, D., Hang, T., Tao, J., Wang, Q., Li, R., Chen, C., et al.: Promptenhancer: A simple approach to enhance text-to-image models via chain-of-thought prompt rewriting. arXiv preprint arXiv:2509.04545 (2025)
-
[51]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review arXiv 2024
-
[52]
arXiv preprint arXiv:2510.18701 , year=
Wang, Y., Li, Z., Zang, Y., Bu, J., Zhou, Y., Xin, Y., He, J., Wang, C., Lu, Q., Jin, C., et al.: Unigenbench++: A unified semantic evaluation benchmark for text- to-image generation. arXiv preprint arXiv:2510.18701 (2025)
-
[53]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review arXiv 2025
-
[54]
Qwen2.5 Technical Report.arXiv preprint arXiv:2410.13848, 2024
Wu, C., Chen, X., Wu, Z., Ma, Y., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C., et al.: Janus: Decoupling visual encoding for unified multimodal understanding and generation. arXiv preprint arXiv:2410.13848 (2024)
-
[55]
In: CVPR (2024)
Wu, T.H., Lian, L., Gonzalez, J.E., Li, B., Darrell, T.: Self-correcting llm-controlled diffusion models. In: CVPR (2024)
2024
-
[56]
In: ICLR (2025)
Xie, J., Mao, W., Bai, Z., Zhang, D.J., Wang, W., Lin, K.Q., Gu, Y., Chen, Z., Yang, Z., Shou, M.Z.: Show-o: One single transformer to unify multimodal under- standing and generation. In: ICLR (2025)
2025
-
[57]
Show-o2: Improved Native Unified Multimodal Models
Xie,J.,Yang,Z.,Shou,M.Z.:Show-o2:Improvednativeunifiedmultimodalmodels. arXiv preprint arXiv:2506.15564 (2025)
work page internal anchor Pith review arXiv 2025
-
[58]
In: CVPR (2024) 18 J
Xu, X., Guo, J., Wang, Z., Huang, G., Essa, I., Shi, H.: Prompt-free diffusion: Taking" text" out of text-to-image diffusion models. In: CVPR (2024) 18 J. Guo et al
2024
-
[59]
In: ICML (2024)
Yang, L., Yu, Z., Meng, C., Xu, M., Ermon, S., Bin, C.: Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. In: ICML (2024)
2024
-
[60]
In: CVPR (2025)
Yu, Q., Chow, W., Yue, Z., Pan, K., Wu, Y., Wan, X., Li, J., Tang, S., Zhang, H., Zhuang, Y.: Anyedit: Mastering unified high-quality image editing for any idea. In: CVPR (2025)
2025
-
[61]
In: NeurIPS (2023)
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. In: NeurIPS (2023)
2023
-
[62]
In: NeurIPS (2024)
Zhao, H., Ma, X.S., Chen, L., Si, S., Wu, R., An, K., Yu, P., Zhang, M., Li, Q., Chang, B.: Ultraedit: Instruction-based fine-grained image editing at scale. In: NeurIPS (2024)
2024
-
[63]
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., Levy, O.: Transfusion: Predict the next token and diffuse images with one multi-modal model. In: ICLR (2025) Refinement via Regeneration 1 Supplementary Materials A Attention Mask We adopt the standard omni-attention mechanism [56] in UMMs to support RvR...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.