Recognition: unknown
Prefill-Time Intervention for Mitigating Hallucination in Large Vision-Language Models
Pith reviewed 2026-05-07 16:45 UTC · model grok-4.3
The pith
Prefill-Time Intervention corrects hallucination-prone KV cache entries in vision-language models before decoding errors accumulate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
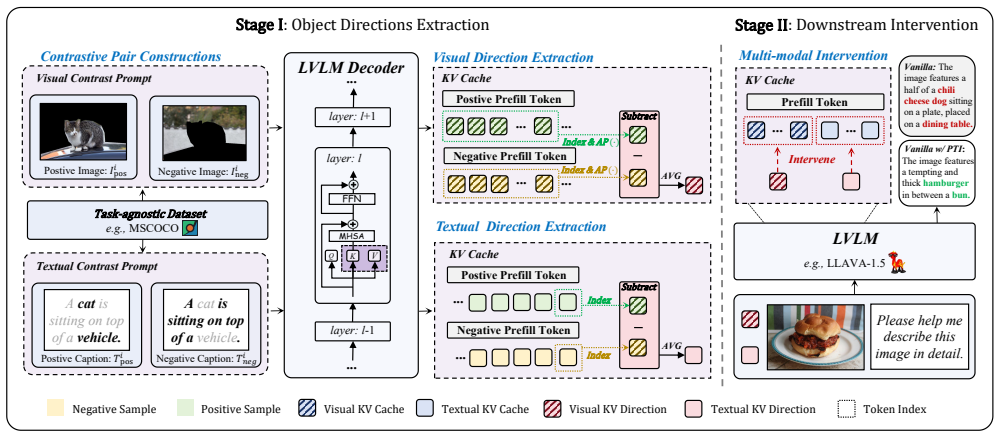
The paper claims that intervening once during the prefill stage by deriving modality-specific directions and decoupling the steering of keys toward visually-grounded objects and values to filter background noise enhances the initial Key-Value cache, thereby mitigating hallucinations at their source prior to any autoregressive generation.
What carries the argument
Prefill-Time Intervention (PTI), which performs a single modality-aware correction on the initial KV cache to steer keys toward grounded objects and values toward noise reduction.
If this is right
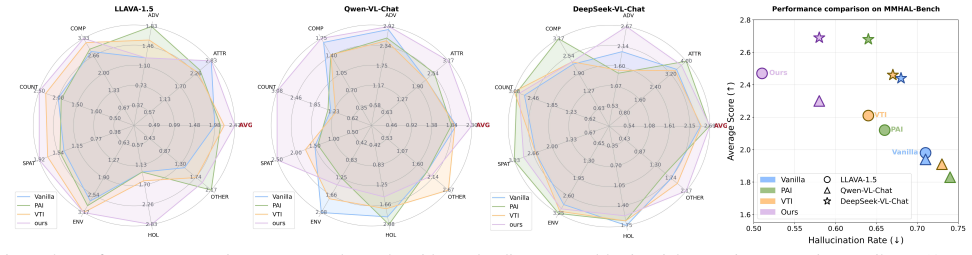
- The intervention leads to better hallucination mitigation than methods applied only during decoding.
- PTI maintains effectiveness across various LVLMs and different decoding approaches.
- Combining PTI with decoding-stage techniques yields further improvements in performance.
- The method avoids amplifying residual hallucinations by addressing issues early.
Where Pith is reading between the lines
- Early intervention on internal states could apply to reducing inconsistencies in other generative AI systems beyond vision-language models.
- The decoupled key-value approach suggests a general way to separate content focus from noise suppression in attention mechanisms.
- Testing PTI in combination with other grounding techniques might reveal ways to strengthen visual-text alignment further.
Load-bearing premise
That adjusting the KV cache only once at the beginning reliably prevents hallucinations from developing later without causing other inconsistencies in the model's responses.
What would settle it
Measuring hallucination rates on image-captioning benchmarks before and after applying PTI; if rates do not decrease or if new errors appear, the claim would be falsified.
Figures







read the original abstract
Large Vision-Language Models (LVLMs) have achieved remarkable progress in visual-textual understanding, yet their reliability is critically undermined by hallucinations, i.e., the generation of factually incorrect or inconsistent responses. While recent studies using steering vectors demonstrated promise in reducing hallucinations, a notable challenge remains: they inadvertently amplify the severity of residual hallucinations. We attribute this to their exclusive focus on the decoding stage, where errors accumulate autoregressively and progressively worsen subsequent hallucinatory outputs. To address this, we propose Prefill-Time Intervention (PTI), a novel steering paradigm that intervenes only once during the prefill stage, enhancing the initial Key-Value (KV) cache before error accumulation occurs. Specifically, PTI is modality-aware, deriving distinct directions for visual and textual representations. This intervention is decoupled to steer keys toward visually-grounded objects and values to filter background noise, correcting hallucination-prone representations at their source. Extensive experiments demonstrate PTI's significant performance in mitigating hallucinations and its generalizability across diverse decoding strategies, LVLMs, and benchmarks. Moreover, PTI is orthogonal to existing decoding-stage methods, enabling plug-and-play integration and further boosting performance. Code is available at: https://github.com/huaiyi66/PTI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Prefill-Time Intervention (PTI) as a novel steering method for large vision-language models (LVLMs) to reduce hallucinations. Unlike prior decoding-stage steering vectors that can amplify residual errors, PTI applies a single modality-aware intervention to the initial KV cache during the prefill stage. It derives separate directions for visual and textual tokens and decouples the edit so that keys are steered toward visually-grounded objects while values filter background noise, thereby correcting hallucination-prone representations before autoregressive generation begins. The method is claimed to be orthogonal to existing decoding techniques, enabling plug-and-play combination, and is supported by extensive experiments showing gains across models, decoding strategies, and benchmarks.
Significance. If the central empirical claims hold, PTI offers a practically useful shift in the timing of hallucination mitigation for LVLMs, addressing a documented weakness of post-prefill interventions. The public code release is a clear strength that supports reproducibility. The orthogonality result, if robust, would allow incremental gains on top of existing methods without retraining.
major comments (2)
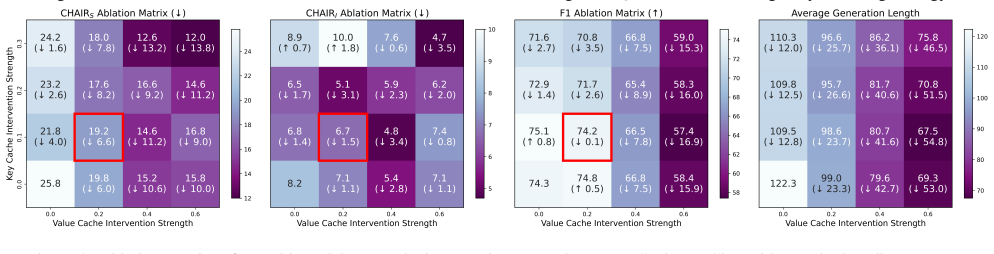
- [§3] §3 (Method): The core mechanistic claim—that decoupled key/value steering at prefill corrects representations 'at their source' by directing keys to visually-grounded objects and values to background filtering—rests on an unverified functional-role assumption. No attention-map analysis, object-grounding probe, or ablation that isolates key-only versus value-only interventions is reported to confirm these specific effects. If the assumed roles do not hold, the single prefill edit may merely shift the initial cache without preventing later reintroduction of inconsistencies.
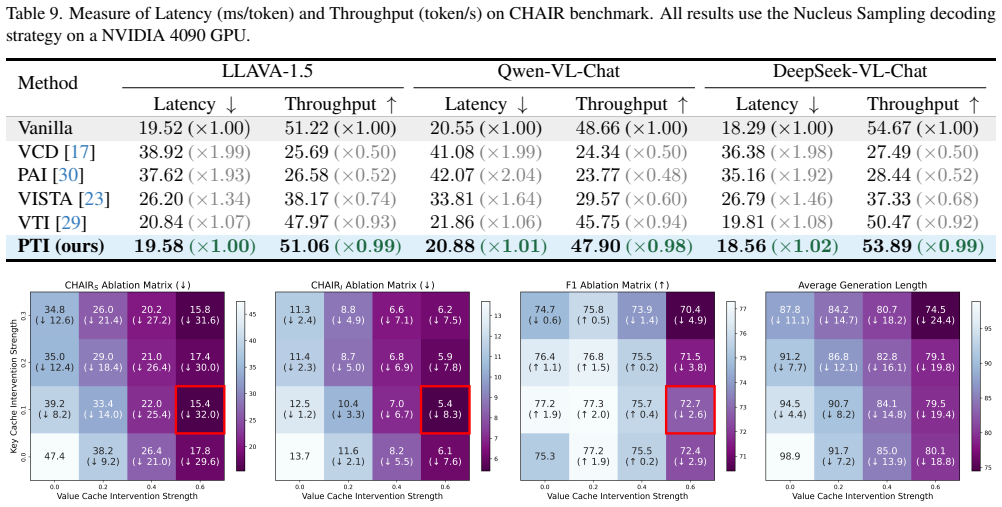
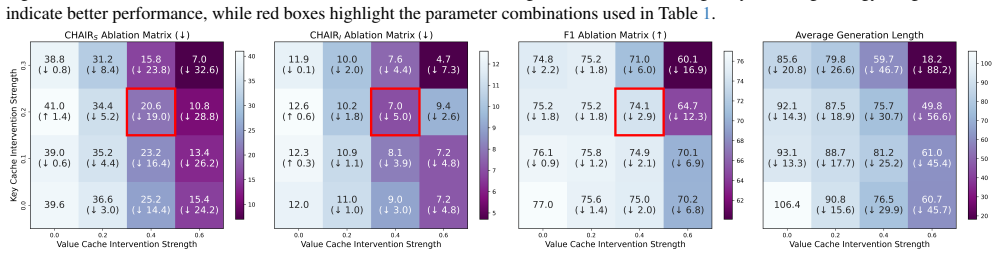
- [§4] §4 (Experiments): The abstract states 'significant performance' and 'generalizability across diverse decoding strategies, LVLMs, and benchmarks,' yet the manuscript provides no details on exact baseline implementations, statistical controls (e.g., multiple-comparison correction), or variance across random seeds. Without these, the strength of evidence for the central claim that PTI reliably outperforms and combines with decoding-stage methods remains moderate.
minor comments (2)
- Notation for the modality-aware direction vectors and the decoupled steering operators should be introduced with explicit equations rather than prose descriptions to improve clarity.
- Figure captions and axis labels in the experimental results should explicitly state the metrics used (e.g., CHAIR, POPE) and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and positive review, which highlights both the potential of PTI and areas where the manuscript can be strengthened. We address each major comment below and will revise the paper accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method): The core mechanistic claim—that decoupled key/value steering at prefill corrects representations 'at their source' by directing keys to visually-grounded objects and values to background filtering—rests on an unverified functional-role assumption. No attention-map analysis, object-grounding probe, or ablation that isolates key-only versus value-only interventions is reported to confirm these specific effects. If the assumed roles do not hold, the single prefill edit may merely shift the initial cache without preventing later reintroduction of inconsistencies.
Authors: We appreciate the referee's point on the need for direct verification of the mechanistic assumptions. The decoupled key/value design is motivated by the standard roles in attention mechanisms (keys for content matching and grounding, values for information aggregation), and the empirical gains across benchmarks provide supporting evidence for the overall approach. However, we acknowledge that the original submission lacks explicit ablations or attention analyses isolating these effects. In the revision, we will add (i) key-only vs. value-only vs. combined intervention ablations and (ii) qualitative attention-map comparisons before and after PTI to better substantiate or refine the functional-role interpretation. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract states 'significant performance' and 'generalizability across diverse decoding strategies, LVLMs, and benchmarks,' yet the manuscript provides no details on exact baseline implementations, statistical controls (e.g., multiple-comparison correction), or variance across random seeds. Without these, the strength of evidence for the central claim that PTI reliably outperforms and combines with decoding-stage methods remains moderate.
Authors: We agree that greater experimental transparency is warranted to support the claims of performance and generalizability. The revised manuscript will include: detailed descriptions of baseline reproductions (including any hyperparameter choices for prior steering methods), results with means and standard deviations computed over multiple random seeds, and an explicit discussion of statistical practices (including the rationale for not applying multiple-comparison corrections in the primary baseline comparisons). These additions will provide a more robust foundation for the reported improvements and orthogonality findings. revision: yes
Circularity Check
No circularity: empirical intervention with independent experimental validation
full rationale
The paper presents PTI as an empirical steering method applied once at prefill to the KV cache, with modality-aware and decoupled key/value directions. No derivation chain, equations, or first-principles results are shown that reduce the claimed performance gains to a fitted parameter, self-defined quantity, or self-citation whose content is itself unverified. Experiments across models, benchmarks, and decoding strategies are reported as external validation. The decoupling of key/value roles is an ansatz justified by the observed outcomes rather than by tautological construction. This matches the default case of a self-contained empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- steering directions for visual and textual representations
axioms (1)
- domain assumption Errors accumulate autoregressively during decoding and progressively worsen hallucinatory outputs
Reference graph
Works this paper leans on
-
[1]
Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010
Herv ´e Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: computational statistics, 2(4):433–459, 2010. 4
2010
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[3]
Mitigating object hallucinations in large vision- language models with assembly of global and local attention
Wenbin An, Feng Tian, Sicong Leng, Jiahao Nie, Haonan Lin, QianYing Wang, Ping Chen, Xiaoqin Zhang, and Shi- jian Lu. Mitigating object hallucinations in large vision- language models with assembly of global and local attention. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 29915–29926, 2025. 1
2025
-
[4]
Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 1, 2, 3, 5
2023
-
[5]
Kv cache steering for inducing reasoning in small language models.arXiv e-prints, pages arXiv–2507, 2025
Max Belitsky, Dawid J Kopiczko, Michael Dorkenwald, M Jehanzeb Mirza, Cees GM Snoek, and Yuki M Asano. Kv cache steering for inducing reasoning in small language models.arXiv e-prints, pages arXiv–2507, 2025. 2, 3
2025
-
[6]
Llava steering: Vi- sual instruction tuning with 500x fewer parameters through modality linear representation-steering
Jinhe Bi, Yujun Wang, Haokun Chen, Xun Xiao, Artur Hecker, V olker Tresp, and Yunpu Ma. Llava steering: Vi- sual instruction tuning with 500x fewer parameters through modality linear representation-steering. InProceedings of the 63rd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 15230– 15250, 2025. 2
2025
-
[7]
Ict: Image-object cross-level trusted intervention for mitigating object halluci- nation in large vision-language models
Junzhe Chen, Tianshu Zhang, Shiyu Huang, Yuwei Niu, Lin- feng Zhang, Lijie Wen, and Xuming Hu. Ict: Image-object cross-level trusted intervention for mitigating object halluci- nation in large vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4209–4221, 2025. 1, 2, 3
2025
-
[8]
Driving with llms: Fusing object-level vec- tor modality for explainable autonomous driving
Long Chen, Oleg Sinavski, Jan H ¨unermann, Alice Karnsund, Andrew James Willmott, Danny Birch, Daniel Maund, and Jamie Shotton. Driving with llms: Fusing object-level vec- tor modality for explainable autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 14093–14100. IEEE, 2024. 1
2024
-
[9]
Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Ziqing Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023. 1
2023
-
[10]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 3, 4
work page internal anchor Pith review arXiv 2010
-
[11]
Not all heads matter: A head-level KV cache compression method with integrated retrieval and reasoning
Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, and Wen Xiao. Not all heads matter: A head-level KV cache compression method with integrated retrieval and reasoning. InThe Thirteenth International Conference on Learning Representations, 2025. 2
2025
-
[12]
Woody Haosheng Gan, Deqing Fu, Julian Asilis, Ollie Liu, Dani Yogatama, Vatsal Sharan, Robin Jia, and Willie Neiswanger. Textual steering vectors can improve visual understanding in multimodal large language models.arXiv preprint arXiv:2505.14071, 2025. 4
-
[13]
Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Con- ghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection-allocation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13418–13427, 2024. 5, 6
2024
-
[14]
How good are low-bit quantized llama3 models? an empirical study.CoRR, 2024
Wei Huang, Xudong Ma, Haotong Qin, Xingyu Zheng, Chengtao Lv, Hong Chen, Jie Luo, Xiaojuan Qi, Xianglong Liu, and Michele Magno. How good are low-bit quantized llama3 models? an empirical study.CoRR, 2024. 1
2024
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[16]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3
2023
-
[17]
Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hal- lucinations in large vision-language models through visual contrastive decoding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13872–13882, 2024. 3, 5, 6, 13, 14
2024
-
[18]
Otter: A multi-modal model with in-context instruction tuning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Joshua Adrian Cahyono, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 1
2025
-
[19]
Inference-time intervention: Elicit- ing truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530,
Kenneth Li, Oam Patel, Fernanda Vi ´egas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Elicit- ing truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530,
-
[20]
Qiming Li, Zekai Ye, Xiaocheng Feng, Weihong Zhong, Libo Qin, Ruihan Chen, Baohang Li, Kui Jiang, Yaowei Wang, Ting Liu, et al. Cai: Caption-sensitive attention in- tervention for mitigating object hallucination in large vision- language models.arXiv preprint arXiv:2506.23590, 2025. 2, 12
-
[21]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucina- tion in large vision-language models.arXiv preprint arXiv:2305.10355, 2023. 1, 3, 5
work page internal anchor Pith review arXiv 2023
-
[22]
FairSteer: Inference time debiasing for LLMs with dynamic activation steering
Yichen Li, Zhiting Fan, Ruizhe Chen, Xiaotang Gai, Luqi Gong, Yan Zhang, and Zuozhu Liu. FairSteer: Inference time debiasing for LLMs with dynamic activation steering. InFindings of the Association for Computational Linguis- tics: ACL 2025, pages 11293–11312, Vienna, Austria, 2025. Association for Computational Linguistics. 2
2025
-
[23]
arXiv preprint arXiv:2502.03628 , year=
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N Metaxas. The hidden life of tokens: Reducing hallucination of large vision-language models via visual in- formation steering.arXiv preprint arXiv:2502.03628, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 13, 14, 15
-
[24]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 3, 4, 5, 12
2014
-
[25]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Ya- coob, and Lijuan Wang. Mitigating hallucination in large multi-modal models via robust instruction tuning.arXiv preprint arXiv:2306.14565, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[26]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 2
2023
-
[27]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 1, 2, 5
2024
-
[28]
arXiv preprint arXiv:2412.17747 (2024)
Luyang Liu, Jonas Pfeiffer, Jiaxing Wu, Jun Xie, and Arthur Szlam. Deliberation in latent space via differentiable cache augmentation.arXiv preprint arXiv:2412.17747, 2024. 3
-
[29]
Sheng Liu, Haotian Ye, Lei Xing, and James Zou. Reduc- ing hallucinations in vision-language models via latent space steering.arXiv preprint arXiv:2410.15778, 2024. 1, 2, 3, 4, 5, 6, 7, 13, 14, 15
-
[30]
Paying more at- tention to image: A training-free method for alleviating hal- lucination in lvlms
Shi Liu, Kecheng Zheng, and Wei Chen. Paying more at- tention to image: A training-free method for alleviating hal- lucination in lvlms. InEuropean Conference on Computer Vision, pages 125–140. Springer, 2024. 5, 6, 7, 8, 12, 13, 14
2024
-
[31]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review arXiv
-
[32]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3
2021
-
[33]
Object Hallucination in Image Captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning.arXiv preprint arXiv:1809.02156, 2018. 1, 2, 3, 5, 14
work page Pith review arXiv 2018
-
[34]
Video reasoning without training.arXiv preprint arXiv:2510.17045, 2025
Deepak Sridhar, Kartikeya Bhardwaj, Jeya Pradha Je- yaraj, Nuno Vasconcelos, Ankita Nayak, and Harris Teague. Video reasoning without training.arXiv preprint arXiv:2510.17045, 2025. 2
-
[35]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multi- modal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023. 1, 5, 6
-
[36]
Octopus: Alleviating hal- lucination via dynamic contrastive decoding
Wei Suo, Lijun Zhang, Mengyang Sun, Lin Yuanbo Wu, Peng Wang, and Yanning Zhang. Octopus: Alleviating hal- lucination via dynamic contrastive decoding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29904–29914, 2025. 1, 3
2025
-
[37]
Seeing far and clearly: Mitigating hallucinations in mllms with attention causal decoding
Feilong Tang, Chengzhi Liu, Zhongxing Xu, Ming Hu, Zile Huang, Haochen Xue, Ziyang Chen, Zelin Peng, Zhiwei Yang, Sijin Zhou, et al. Seeing far and clearly: Mitigating hallucinations in mllms with attention causal decoding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 26147–26159, 2025. 2, 3, 12
2025
-
[38]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 1, 2
work page internal anchor Pith review arXiv 2023
-
[40]
Dezhan Tu, Danylo Vashchilenko, Yuzhe Lu, and Panpan Xu. Vl-cache: Sparsity and modality-aware kv cache com- pression for vision-language model inference acceleration. arXiv preprint arXiv:2410.23317, 2024. 2
-
[41]
No Starch Press, 2020
Yuli Vasiliev.Natural language processing with Python and spaCy: A practical introduction. No Starch Press, 2020. 4
2020
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2
2017
-
[43]
In-distribution steering: Bal- ancing control and coherence in language model generation
Arthur V ogels, Benjamin Wong, Yann Choho, Annabelle Blangero, and Milan Bhan. In-distribution steering: Bal- ancing control and coherence in language model generation. arXiv preprint arXiv:2510.13285, 2025. 2
-
[44]
Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, and Li Yuan. Look-m: Look- once optimization in kv cache for efficient multimodal long- context inference.arXiv preprint arXiv:2406.18139, 2024. 2
-
[45]
Zhongwei Wan, Hui Shen, Xin Wang, Che Liu, Zheda Mai, and Mi Zhang. Meda: Dynamic kv cache allocation for ef- ficient multimodal long-context inference.arXiv preprint arXiv:2502.17599, 2025. 2
-
[46]
Amber: An llm-free multi- dimensional benchmark for mllms hallucination evaluation,
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, and Jitao Sang. Amber: An llm-free multi- dimensional benchmark for mllms hallucination evaluation,
-
[47]
METok: Multi-stage event-based token compression for efficient long video understanding
Mengyue Wang, Shuo Chen, Kristian Kersting, V olker Tresp, and Yunpu Ma. METok: Multi-stage event-based token compression for efficient long video understanding. InProceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 18881–18895, Suzhou, China, 2025. Association for Computational Lin- guistics. 2
2025
-
[48]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Bie- mann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding.arXiv preprint arXiv:2403.18715, 2024. 3
-
[49]
Zheng Wang, Boxiao Jin, Zhongzhi Yu, and Minjia Zhang. Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks.arXiv preprint arXiv:2407.08454, 2024. 2
-
[50]
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618, 2025. 2
-
[51]
Anti- dote: A unified framework for mitigating lvlm hallucinations in counterfactual presupposition and object perception
Yuanchen Wu, Lu Zhang, Hang Yao, Junlong Du, Ke Yan, Shouhong Ding, Yunsheng Wu, and Xiaoqiang Li. Anti- dote: A unified framework for mitigating lvlm hallucinations in counterfactual presupposition and object perception. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14646–14656, 2025. 1
2025
-
[52]
Ote: Exploring accurate scene text recognition us- ing one token
Jianjun Xu, Yuxin Wang, Hongtao Xie, and Yongdong Zhang. Ote: Exploring accurate scene text recognition us- ing one token. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 28327– 28336, 2024. 4
2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1
work page internal anchor Pith review arXiv 2025
-
[54]
Improving factual- ity in large language models via decoding-time hallucinatory and truthful comparators
Dingkang Yang, Dongling Xiao, Jinjie Wei, Mingcheng Li, Zhaoyu Chen, Ke Li, and Lihua Zhang. Improving factual- ity in large language models via decoding-time hallucinatory and truthful comparators. InProceedings of the AAAI Con- ference on Artificial Intelligence, pages 25606–25614, 2025. 1
2025
-
[55]
Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection
Le Yang, Ziwei Zheng, Boxu Chen, Zhengyu Zhao, Chenhao Lin, and Chao Shen. Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 14635–14645, 2025. 1, 2, 4
2025
-
[56]
Clearsight: Vi- sual signal enhancement for object hallucination mitigation in multimodal large language models
Hao Yin, Guangzong Si, and Zilei Wang. Clearsight: Vi- sual signal enhancement for object hallucination mitigation in multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14625–14634, 2025. 1, 3
2025
-
[57]
A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12): nwae403, 2024. 1, 5, 7
2024
-
[58]
Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data
Qifan Yu, Juncheng Li, Longhui Wei, Liang Pang, Wen- tao Ye, Bosheng Qin, Siliang Tang, Qi Tian, and Yueting Zhuang. Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12944–12953, 2024. 1
2024
-
[59]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 3
2023
-
[60]
Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A. Smith. How language model hallucinations can snowball. InForty-first International Conference on Ma- chine Learning, 2024. 2 Prefill-Time Intervention for Mitigating Hallucination in Large Vision-Language Models Supplementary Material A. Details of Internal Interpretability Analysis. In this ...
-
[61]
and VISTA [23]), and our PTI for LLA V A-1.5, Qwen- VL-Chat, and DeepSeek-VL-Chat, respectively. As evident across these scenarios, while vanilla models and DTI meth- ods frequently suffer from severe object hallucinations and context misinterpretation, PTI effectively suppresses the generation of non-existent entities and erroneous attributes. These qual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.