Recognition: unknown
Can Code Evaluation Metrics Detect Code Plagiarism?
Pith reviewed 2026-05-07 16:10 UTC · model grok-4.3
The pith
Code evaluation metrics rank plagiarized code as well as specialized detection tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
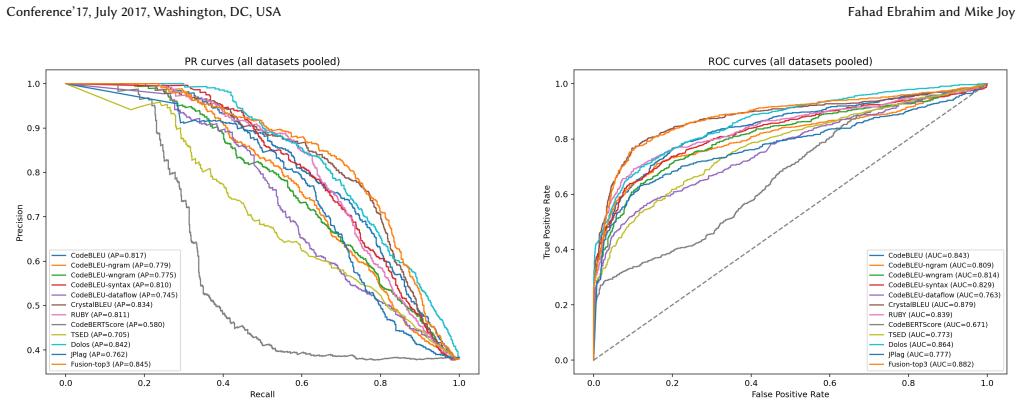
On the ConPlag and IRPlag datasets, Dolos leads without preprocessing while CrystalBLEU, CodeBLEU, and RUBY outperform JPlag; after preprocessing CrystalBLEU surpasses Dolos overall. Performance is highest at L1 and declines from L4, yet CrystalBLEU remains competitive at L6. Per-dataset results vary, with Dolos strongest on raw ConPlag and CrystalBLEU best on the others, leading to the conclusion that code evaluation metrics achieve comparable ranking performance to dedicated plagiarism tools.
What carries the argument
Threshold-free ranking-based evaluation measures applied to code pairs across L1-L6 plagiarism levels on the ConPlag (raw and template-free) and IRPlag datasets, directly comparing five code evaluation metrics to JPlag and Dolos.
If this is right
- Instructors could reuse code evaluation metrics already in their grading pipelines for initial plagiarism screening.
- Adding simple preprocessing steps noticeably boosts metric effectiveness on plagiarism ranking tasks.
- Detection strength drops as modification complexity increases, so tools may need level-specific adjustments.
- CrystalBLEU in particular offers a practical option for harder plagiarism levels where other methods weaken.
Where Pith is reading between the lines
- The same metrics might help flag AI-generated code that closely mimics human student submissions if the ranking patterns transfer.
- Testing the approach on additional programming languages would show whether certain metrics have language-specific advantages.
- Integration into submission platforms could enable lightweight, always-on checks without new dedicated software.
Load-bearing premise
That results from these two specific labeled datasets with controlled modification levels will hold for real student submissions in other languages and practical classroom settings.
What would settle it
A follow-up test on a fresh collection of verified real-world student plagiarism cases in which the leading code evaluation metrics produce markedly lower ranking scores than JPlag or Dolos.
Figures



read the original abstract
Source Code Plagiarism Detection (SCPD) plays an important role in maintaining fairness and academic integrity in software engineering education. Code Evaluation Metrics (CEMs) are developed for assessing code generation tasks. However, it remains unclear whether such metrics can reliably detect plagiarism across different levels of modification (L1-L6), increasing in complexity. In this paper, we perform a comparative empirical study using two open-source labelled datasets, ConPlag (raw and template-free versions) and IRPlag. We evaluate five CEMs, namely CodeBLEU, CrystalBLEU, RUBY, Tree Structured Edit Distance (TSED), and CodeBERTScore. The performance is evaluated using threshold-free ranking-based measures to assess overall, per dataset, and per-level plagiarism performance. The results are compared against state-of-the-art (SOTA) Source Code Plagiarism Detection Tools (SCPDTs), JPlag and Dolos. Our findings show that without preprocessing, Dolos achieves the highest overall ranking performance, while among the individual metrics, CrystalBLEU, CodeBLEU, and RUBY outperform JPlag. Performance is strongest at L1 and drops from L4 onward, while CrystalBLEU remains competitive on L6. With preprocessing, CrystalBLEU surpasses Dolos overall. Per dataset, Dolos achieved the best ranking on the ConPlag raw dataset, while CrystalBLEU was the best-performing metric on the remaining datasets. At the plagiarism levels, Dolos remains strongest on L4, while Crystal-BLEU leads most of the remaining difficult levels. These results indicate that CEMs are comparable to dedicated tools in terms of ranking metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical comparison of five Code Evaluation Metrics (CEMs: CodeBLEU, CrystalBLEU, RUBY, TSED, CodeBERTScore) against two dedicated Source Code Plagiarism Detection Tools (JPlag and Dolos) on the ConPlag (raw and template-free) and IRPlag datasets. It evaluates performance across six synthetic plagiarism levels (L1-L6) using threshold-free ranking-based measures, reporting that CEMs (especially CrystalBLEU) achieve comparable or superior ranking performance to the SOTA tools, with strongest results at low modification levels and sensitivity to preprocessing.
Significance. If the central ranking-based findings hold, the work demonstrates that metrics designed for code generation evaluation can serve as viable alternatives or complements to specialized plagiarism detectors, potentially lowering barriers for educators. Strengths include the use of open labeled datasets, direct head-to-head comparison with JPlag/Dolos, and avoidance of arbitrary similarity thresholds. However, significance is limited by the controlled nature of the L1-L6 modifications and lack of validation on authentic student code.
major comments (2)
- [Results section (per-level and overall ranking)] Results section (per-level and overall ranking): The reported performance drop after L4 and the preprocessing-dependent reversal (CrystalBLEU overtaking Dolos) are load-bearing for the comparability claim, yet no statistical significance tests (e.g., Wilcoxon signed-rank on the ranking metrics) or confidence intervals are provided to establish whether observed differences exceed noise.
- [Evaluation and discussion] Evaluation and discussion: The central claim that CEMs are 'comparable to dedicated tools' rests on synthetic L1-L6 modifications in ConPlag/IRPlag; the manuscript contains no experiments or analysis on authentic student submissions (which often involve semantic rewrites, library changes, or cross-language elements outside the L1-L6 taxonomy), leaving generalization untested and weakening applicability to real plagiarism detection.
minor comments (2)
- [Abstract] Abstract: Inconsistent naming of 'CrystalBLEU' (sometimes hyphenated as 'Crystal-BLEU') should be standardized throughout.
- [Discussion or Conclusion] The paper would benefit from an explicit limitations subsection addressing dataset construction biases and the threshold-free assumption's sensitivity to ranking ties.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, indicating where we agree and will revise the paper accordingly.
read point-by-point responses
-
Referee: Results section (per-level and overall ranking): The reported performance drop after L4 and the preprocessing-dependent reversal (CrystalBLEU overtaking Dolos) are load-bearing for the comparability claim, yet no statistical significance tests (e.g., Wilcoxon signed-rank on the ranking metrics) or confidence intervals are provided to establish whether observed differences exceed noise.
Authors: We agree that statistical significance testing would strengthen the claims regarding the performance drop after L4 and the preprocessing effects. In the revised manuscript, we will incorporate Wilcoxon signed-rank tests on the ranking metrics to compare methods and add confidence intervals for the key results to assess whether differences exceed noise. revision: yes
-
Referee: Evaluation and discussion: The central claim that CEMs are 'comparable to dedicated tools' rests on synthetic L1-L6 modifications in ConPlag/IRPlag; the manuscript contains no experiments or analysis on authentic student submissions (which often involve semantic rewrites, library changes, or cross-language elements outside the L1-L6 taxonomy), leaving generalization untested and weakening applicability to real plagiarism detection.
Authors: We acknowledge that the evaluation relies on controlled synthetic modifications, which enable systematic analysis of specific levels but do not capture all real-world plagiarism behaviors such as semantic rewrites or cross-language changes. This limits direct generalization. We will expand the discussion to explicitly address this limitation, clarify the scope of our comparability claims, and suggest future validation on authentic student submissions. revision: partial
Circularity Check
No significant circularity in empirical comparison
full rationale
The paper reports an empirical study that directly measures ranking performance of five CEMs against JPlag and Dolos on the publicly available ConPlag and IRPlag datasets across L1-L6 levels. All reported results (overall rankings, per-dataset, per-level) follow from the experimental protocol, threshold-free metrics, and external tool outputs without any fitted parameters, self-definitions, or load-bearing self-citations that reduce the claims to the inputs by construction. The derivation chain is therefore self-contained and consists of standard benchmark evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The ConPlag and IRPlag datasets accurately represent real-world plagiarism cases at levels L1-L6.
- domain assumption Threshold-free ranking metrics provide a valid way to compare plagiarism detection performance.
Reference graph
Works this paper leans on
-
[1]
Cîmpeanu Alexandra-Cristina and Alexandru-Corneliu Olteanu. 2022. Material survey on source code plagiarism detection in programming courses. In2022 International Conference on Advanced Learning Technologies (ICALT). IEEE, 387– 389
2022
-
[2]
Georgina Cosma and Mike Joy. 2008. Towards a definition of source-code plagia- rism.IEEE Transactions on Education51, 2 (2008), 195–200
2008
-
[3]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
-
[4]
Thomas J DiCiccio and Bradley Efron. 1996. Bootstrap confidence intervals. Statistical science11, 3 (1996), 189–228
1996
-
[5]
Yihong Dong, Jiazheng Ding, Xue Jiang, Ge Li, Zhuo Li, and Zhi Jin. 2025. Code- Score: Evaluating code generation by learning code execution.ACM Transactions on Software Engineering and Methodology34, 3 (2025), 1–22
2025
- [6]
-
[7]
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. 2018. The hitch- hiker’s guide to testing statistical significance in natural language processing. InProceedings of the 56th annual meeting of the association for computational linguistics (volume 1: Long papers). 1383–1392
2018
-
[8]
Aryaz Eghbali and Michael Pradel. 2022. CrystalBLEU: precisely and efficiently measuring the similarity of code. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–12
2022
-
[9]
Jinan AW Faidhi and Stuart K Robinson. 1987. An empirical approach for detecting program similarity and plagiarism within a university programming environment. Computers & Education11, 1 (1987), 11–19
1987
-
[10]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. CodeBERT: A pre-trained model for programming and natural languages. InFindings of the association for computational linguistics: EMNLP 2020. 1536–1547
2020
-
[11]
2020.Machine learning and artificial intelligence
Ameet V Joshi. 2020.Machine learning and artificial intelligence. Vol. 261. Springer. Conference’17, July 2017, Washington, DC, USA Fahad Ebrahim and Mike Joy
2020
-
[12]
Oscar Karnalim, Setia Budi, Hapnes Toba, and Mike Joy. 2019. Source Code Plagiarism Detection in Academia with Information Retrieval: Dataset and the Observation.Informatics in Education18, 2 (2019), 321–344. doi:10.15388/infedu. 2019.15
-
[13]
Rien Maertens, Peter Dawyndt, and Bart Mesuere. 2023. Dolos 2.0: Towards seamless source code plagiarism detection in online learning environments. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 2. 632–632
2023
-
[14]
Rien Maertens, Peter Dawyndt, and Bart Mesuere. 2025. Source Code Plagiarism Detection as a Service with Dolos. InProceedings of the 30th ACM Conference on Innovation and Technology in Computer Science Education V. 2. 729–730
2025
-
[15]
Rien Maertens, Maarten Van Neyghem, Maxiem Geldhof, Charlotte Van Petegem, Niko Strijbol, Peter Dawyndt, and Bart Mesuere. 2024. Discovering and exploring cases of educational source code plagiarism with Dolos.SoftwareX26 (2024), 101755
2024
-
[16]
Rien Maertens, Charlotte Van Petegem, Niko Strijbol, Toon Baeyens, Arne Carla Jacobs, Peter Dawyndt, and Bart Mesuere. 2022. Dolos: Language-agnostic plagiarism detection in source code.Journal of Computer Assisted Learning38, 4 (2022), 1046–1061
2022
-
[17]
Matthew B McDermott, Haoran Zhang, Lasse H Hansen, Giovanni Angelotti, and Jack Gallifant. 2024. A closer look at AUROC and AUPRC under class imbalance. Advances in Neural Information Processing Systems37 (2024), 44102–44163
2024
-
[18]
Serge Lionel Nikiema, Albérick Euraste Djire, Abdoul Aziz Bonkoungou, Miche- line Bénédicte Moumoula, Jordan Samhi, Abdoul Kader Kabore, Jacques Klein, and Tegawendé F Bissyande. 2025. How Small Transformation Expose the Weakness of Semantic Similarity Measures.arXiv preprint arXiv:2509.09714(2025)
-
[19]
Matija Novak, Mike Joy, and Dragutin Kermek. 2019. Source-code similarity detection and detection tools used in academia: a systematic review.ACM Transactions on Computing Education (TOCE)19, 3 (2019), 1–37
2019
-
[20]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
2002
-
[21]
Lutz Prechelt, Guido Malpohl, Michael Philippsen, et al. 2002. Finding plagiarisms among a set of programs with JPlag.J. Univers. Comput. Sci.8, 11 (2002), 1016
2002
-
[22]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundare- san, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a method for automatic evaluation of code synthesis.arXiv preprint arXiv:2009.10297(2020)
work page internal anchor Pith review arXiv 2020
-
[23]
Timur Sağlam, Sebastian Hahner, Larissa Schmid, and Erik Burger. 2024. Obfuscation-resilient software plagiarism detection with jplag. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings. 264–265
2024
-
[24]
Timur Sağlam, Nils Niehues, Sebastian Hahner, and Larissa Schmid. 2025. Miti- gating Obfuscation Attacks on Software Plagiarism Detectors via Subsequence Merging. In2025 IEEE/ACM 37th International Conference on Software Engineering Education and Training (CSEE&T). IEEE, 217–228
2025
-
[25]
Evgeniy Slobodkin and Alexander Sadovnikov. 2023. Towards a Dataset of Programming Contest Plagiarism in Java. InProceeding of the 33rd Conference of FRUCT Association. 386–390
2023
-
[26]
Yewei Song, Cedric Lothritz, Xunzhu Tang, Tegawendé Bissyandé, and Jacques Klein. 2024. Revisiting code similarity evaluation with abstract syntax tree edit distance. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 38–46
2024
-
[27]
Ngoc Tran, Hieu Tran, Son Nguyen, Hoan Nguyen, and Tien Nguyen. 2019. Does BLEU score work for code migration?. In2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 165–176
2019
-
[28]
Michael J Wise. 1993. String similarity via greedy string tiling and running Karp-Rabin matching.Online Preprint, Dec119, 1 (1993), 1–17
1993
-
[29]
Morteza Zakeri-Nasrabadi, Saeed Parsa, Mohammad Ramezani, Chanchal Roy, and Masoud Ekhtiarzadeh. 2023. A systematic literature review on source code similarity measurement and clone detection: Techniques, applications, and chal- lenges.Journal of Systems and Software204 (2023), 111796
2023
-
[30]
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi
-
[31]
BERTScore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675(2019)
work page internal anchor Pith review arXiv 1904
-
[32]
Shuyan Zhou, Uri Alon, Sumit Agarwal, and Graham Neubig. 2023. Code- BERTScore: Evaluating code generation with pretrained models of code. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 13921–13937. A Bootstrapped Confidence Intervals and Paired Comparisons A.1 Pooled Confidence Intervals Tables 4 and 5 report b...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.