Recognition: unknown
PSI-Bench: Towards Clinically Grounded and Interpretable Evaluation of Depression Patient Simulators
Pith reviewed 2026-05-07 16:19 UTC · model grok-4.3
The pith
Depression patient simulators generate overly long responses with low variability that resolve emotions too quickly and follow a uniform negative-to-positive trajectory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
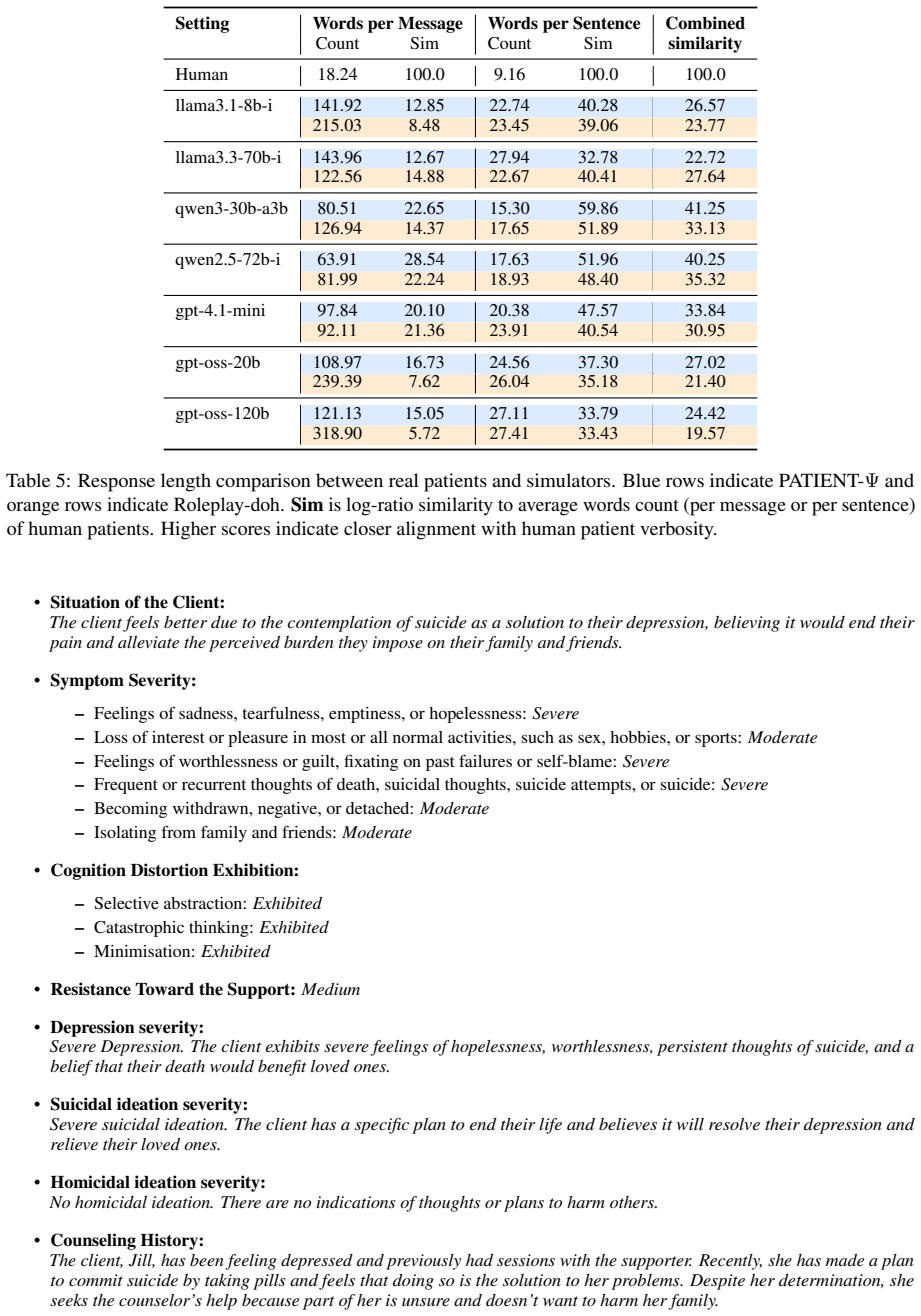
PSI-Bench demonstrates that current depression patient simulators produce overly long, lexically diverse responses that exhibit reduced variability, resolve emotions too quickly, and follow a uniform negative-to-positive trajectory. The simulation framework exerts a larger effect on overall fidelity than model scale, and the benchmark's metrics match expert human ratings of simulator behavior.
What carries the argument
PSI-Bench, an automatic evaluation framework that supplies interpretable diagnostics of simulator behavior at turn, dialogue, and population levels.
If this is right
- Simulator designs should prioritize greater response variability and slower, more varied emotional transitions to better match real patient patterns.
- Developers should focus first on selecting or refining the simulation framework rather than simply increasing model size.
- PSI-Bench can serve as a repeatable standard for comparing new simulators and tracking improvements over time.
- The framework's alignment with expert judgments supports its use for scalable, automatic assessment in place of labor-intensive human review.
Where Pith is reading between the lines
- The same multi-level evaluation approach could be adapted to test simulators for other mental health conditions beyond depression.
- Training data for these simulators may need explicit augmentation with diverse emotional trajectories and variable response lengths.
- Embedding PSI-Bench-style checks directly into simulator training loops could allow models to self-correct toward higher variability during development.
Load-bearing premise
The specific turn-level, dialogue-level, and population-level metrics chosen for PSI-Bench serve as sufficient and unbiased proxies for clinically relevant depression patient behaviors.
What would settle it
A new simulator that receives high scores across all PSI-Bench metrics yet receives low realism ratings from clinicians in side-by-side interaction tests would indicate the metrics do not fully capture clinical fidelity.
Figures








read the original abstract
Patient simulators are gaining traction in mental health training by providing scalable exposure to complex and sensitive patient interactions. Simulating depressed patients is particularly challenging, as safety constraints and high patient variability complicate simulations and underscore the need for simulators that capture diverse and realistic patient behaviors. However, existing evaluations heavily rely on LLM-judges with poorly specified prompts and do not assess behavioral diversity. We introduce PSI-Bench, an automatic evaluation framework that provides interpretable, clinically grounded diagnostics of depression patient simulator behavior across turn-, dialogue-, and population-level dimensions. Using PSI-Bench, we benchmark seven LLMs across two simulator frameworks and find that simulators produce overly long, lexically diverse responses, show reduced variability, resolve emotions too quickly, and follow a uniform negative-to-positive trajectory. We also show that the simulation framework has a larger impact on fidelity than the model scale. Results from a human study demonstrate that our benchmark is strongly aligned with expert judgments. Our work reveals key limitations of current depression patient simulators and provides an interpretable, extensible benchmark to guide future simulator design and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PSI-Bench, an automatic evaluation framework for depression patient simulators that provides interpretable diagnostics across turn-, dialogue-, and population-level dimensions. Benchmarking seven LLMs across two simulator frameworks reveals that current simulators produce overly long and lexically diverse responses, exhibit reduced variability, resolve emotions too quickly, and follow a uniform negative-to-positive trajectory; the simulation framework is found to impact fidelity more than model scale. A human study is reported to show strong alignment between the benchmark and expert judgments.
Significance. If the metrics hold as valid proxies, PSI-Bench could provide a useful structured alternative to ad-hoc LLM judges for guiding simulator development in mental health training applications. The multi-level analysis and the reported human-expert alignment are strengths that add credibility to the diagnostic approach.
major comments (2)
- [§3] §3 (PSI-Bench metric definitions): The turn-level metrics (response length, lexical diversity) and dialogue-level metrics (emotion trajectories, variability) are presented as clinically grounded, yet the manuscript provides no explicit a priori mapping from these general NLP quantities to DSM-5 symptom clusters (e.g., anhedonia persistence or safety-relevant behaviors). This is load-bearing for the central claim, as the post-hoc human alignment does not demonstrate that clinicians would have selected these metrics or that alternative clinically motivated metrics would yield the same simulator rankings.
- [§4] §4 (Benchmarking results): The headline finding that 'the simulation framework has a larger impact on fidelity than the model scale' is reported without sufficient detail on how the two frameworks differ in prompt design, architecture, or safety constraints, making it difficult to interpret the generalizability of this comparison or to rule out confounding factors in the experimental setup.
minor comments (2)
- [Abstract] Abstract and §1: The two simulator frameworks are referenced but not named or briefly characterized, which reduces early clarity for readers unfamiliar with the specific setups.
- [§5] §5 (Human study): While alignment with experts is a positive signal, additional details on the number of experts, exact rating protocol, and any inter-rater reliability statistics would strengthen the validation section without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating where we will revise the manuscript to improve clarity and transparency while preserving the core contributions.
read point-by-point responses
-
Referee: [§3] §3 (PSI-Bench metric definitions): The turn-level metrics (response length, lexical diversity) and dialogue-level metrics (emotion trajectories, variability) are presented as clinically grounded, yet the manuscript provides no explicit a priori mapping from these general NLP quantities to DSM-5 symptom clusters (e.g., anhedonia persistence or safety-relevant behaviors). This is load-bearing for the central claim, as the post-hoc human alignment does not demonstrate that clinicians would have selected these metrics or that alternative clinically motivated metrics would yield the same simulator rankings.
Authors: We agree that an explicit a priori mapping to DSM-5 symptom clusters would strengthen the presentation of clinical grounding. The metrics were chosen to reflect documented behavioral patterns in depression (e.g., reduced emotional variability and rapid resolution as proxies for anhedonia and affective flattening; uniform negative-to-positive trajectories as indicators of limited persistence of low mood), drawing from clinical literature on symptom expression. However, the current manuscript does not include a detailed mapping table or subsection. We will revise §3 to add such a mapping, explicitly linking each metric to relevant DSM-5 criteria and supporting references. This will clarify the rationale and address the concern that the human alignment study is post-hoc. We note that the expert study provides convergent validation but will not claim it substitutes for a priori clinical justification. revision: yes
-
Referee: [§4] §4 (Benchmarking results): The headline finding that 'the simulation framework has a larger impact on fidelity than the model scale' is reported without sufficient detail on how the two frameworks differ in prompt design, architecture, or safety constraints, making it difficult to interpret the generalizability of this comparison or to rule out confounding factors in the experimental setup.
Authors: We acknowledge that additional detail on the two simulator frameworks is required to support interpretation of the framework-versus-scale finding. The manuscript currently describes the frameworks at a high level but does not provide a side-by-side comparison of prompt templates, dialogue management logic, or safety filters. We will expand §4 (and cross-reference the methods) with a dedicated subsection and comparison table that details differences in prompt design, architectural components, and any safety constraints. This will help readers evaluate potential confounders and assess the generalizability of the result. We maintain that the experimental design controls for model scale across frameworks, but agree that greater transparency will strengthen the claim. revision: yes
Circularity Check
No significant circularity: empirical benchmark with external validation
full rationale
The paper defines PSI-Bench metrics at turn-, dialogue-, and population-levels, applies them to produce observational findings on simulator behaviors, and validates alignment via a separate human study with experts. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation. The central claims rest on direct measurement and post-hoc expert comparison rather than reducing to the inputs by construction. This is the expected non-circular outcome for an evaluation framework paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The turn-, dialogue-, and population-level metrics in PSI-Bench capture key clinically relevant aspects of depression patient simulator fidelity.
Reference graph
Works this paper leans on
-
[1]
PMID: 30886766. Lynne E. Angus, Tali Boritz, Emily Bryntwick, Naomi Carpenter, Christianne Macaulay, and Jasmine Khat- tra. 2017. The narrative-emotion process coding system 2.0: A multi-methodological approach to identifying and assessing narrative-emotion process markers in psychotherapy.Psychotherapy Research, 27(3):253–269. PMID: 27772015. Jianzhu Bao...
2017
-
[2]
Technical Report UCAM-CL-TR- 915, University of Cambridge, Computer Laboratory
Annotating errors and disfluencies in transcrip- tions of speech. Technical Report UCAM-CL-TR- 915, University of Cambridge, Computer Laboratory. Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, and Pierre-Yves Oudeyer
-
[3]
InInternational conference on machine learning, pages 3676–3713
Grounding large language models in interac- tive environments with online reinforcement learn- ing. InInternational conference on machine learning, pages 3676–3713. PMLR. Yirong Chen, Xiaofen Xing, Jingkai Lin, Huimin Zheng, Zhenyu Wang, Qi Liu, and Xiangmin Xu. 2023. SoulChat: Improving LLMs’ empathy, listening, and comfort abilities through fine-tuning ...
2023
-
[4]
Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097– 1179. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. A survey on llm-as-a-judge. Preprint, arXiv:2411.15594....
work page internal anchor Pith review arXiv 2025
-
[5]
Eeyore: Realistic depression simulation via expert-in-the-loop supervised and preference opti- mization. InFindings of the Association for Compu- tational Linguistics: ACL 2025, pages 13750–13770, Vienna, Austria. Association for Computational Lin- guistics. Siyang Liu, Chujie Zheng, Orianna Demasi, Sahand Sabour, Yu Li, Zhou Yu, Yong Jiang, and Minlie Hu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.