Recognition: unknown
Training Computer Use Agents to Assess the Usability of Graphical User Interfaces
Pith reviewed 2026-05-07 15:59 UTC · model grok-4.3
The pith
A trained computer use agent called uxCUA assesses GUI usability more accurately than larger models by prioritizing key interaction flows and predicting a numerical score.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
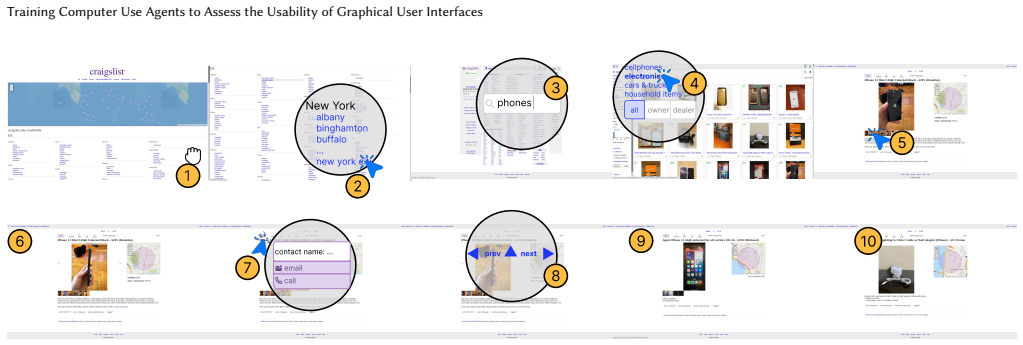
We present a novel machine learning method that operationalizes a computational definition of usability to train CUAs to assess GUI usability by i) prioritizing important interaction flows, ii) executing them through human-like interactions, and iii) predicting a learned numerical usability score. We train a computer use agent, uxCUA, with our algorithm on a large-scale dataset of fully interactive user interfaces (UIs) paired with usability labels and human preferences. We show that uxCUA outperforms larger models in accurate usability assessments and produces realistic critiques of both synthetic and real UIs.
What carries the argument
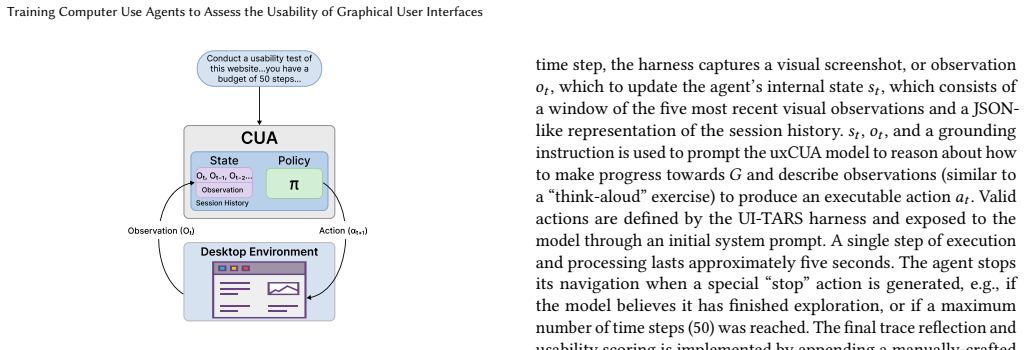
uxCUA, a computer use agent trained via an algorithm that prioritizes interaction flows, executes human-like actions on them, and outputs a learned numerical usability score from labeled interactive UIs.
If this is right
- Usability assessment can be performed automatically at scale on large numbers of interfaces without repeated expert involvement.
- The agent produces critiques that align with human preferences on both synthetic and actual GUIs.
- Training on interactive UIs with preference data allows the learned score to generalize beyond the original labels.
- The approach supplies a data-driven basis for automated usability work in human-computer interaction.
Where Pith is reading between the lines
- The same training approach might apply to evaluating accessibility or other interface qualities by adjusting the flows and score targets.
- Integrating the agent into design software could allow real-time feedback during interface creation.
- Multiple such agents could simulate diverse user groups to generate a range of usability perspectives.
Load-bearing premise
Usability can be captured as a computational task by selecting important interaction flows, performing human-like actions on them, and learning a numerical score that works on new interfaces.
What would settle it
Compare uxCUA's scores and critiques against fresh human ratings on a new collection of real-world UIs that were not part of the training data.
Figures





read the original abstract
Usability testing with experts and potential users can assess the effectiveness, efficiency, and user satisfaction of graphical user interfaces (GUIs) but doing so remains a costly and time-intensive process. Prior work has used computer use agents (CUAs) and other generative agents that can simulate user interactions and preference, but we show that agents still struggle to provide accurate usability assessments. In this work, we present a novel machine learning method that operationalizes a computational definition of usability to train CUAs to assess GUI usability by i) prioritizing important interaction flows, ii) executing them through human-like interactions, and iii) predicting a learned numerical usability score. We train a computer use agent, uxCUA, with our algorithm on a large-scale dataset of fully interactive user interfaces (UIs) paired with usability labels and human preferences. We show that uxCUA outperforms larger models in accurate usability assessments and produces realistic critiques of both synthetic and real UIs. More broadly, our work aims to build a principled, data-driven foundation for automated usability assessment in HCI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents uxCUA, a computer use agent trained to assess GUI usability via a three-step operationalization: prioritizing important interaction flows, executing human-like interactions, and predicting a learned numerical usability score. The agent is trained on a large-scale dataset of fully interactive UIs paired with usability labels and human preferences. The central claims are that uxCUA outperforms larger models in accurate usability assessments and produces realistic critiques of both synthetic and real UIs, providing a data-driven foundation for automated usability assessment in HCI.
Significance. If the results hold with proper validation, this work could meaningfully advance automated usability testing in HCI by offering a scalable alternative to costly human evaluations. The agent-based operationalization of usability through prioritized flows and learned scores represents a principled computational approach that may improve consistency over purely generative methods. The reported outperformance over larger models, if substantiated, would highlight efficiency advantages. However, the significance hinges on demonstrating robust generalization to real UIs independent of training labels.
major comments (2)
- [Abstract] Abstract: The claim that uxCUA 'outperforms larger models in accurate usability assessments' provides no details on evaluation metrics, baselines, data splits, error bars, or statistical tests. Without this information, it is unclear whether the outperformance supports the central claim or results from fitting to the training distribution of labels.
- [Abstract] Abstract: The statement that uxCUA 'produces realistic critiques of both synthetic and real UIs' does not indicate whether the real UIs were held out from training, the selection process for real interfaces, or any correlation with independent expert ratings. Given that the numerical score is learned from human labels, this evidence is load-bearing for the generalization claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We appreciate the emphasis on ensuring the abstract provides sufficient detail to support our central claims. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that uxCUA 'outperforms larger models in accurate usability assessments' provides no details on evaluation metrics, baselines, data splits, error bars, or statistical tests. Without this information, it is unclear whether the outperformance supports the central claim or results from fitting to the training distribution of labels.
Authors: We agree that the abstract would benefit from greater specificity on the evaluation protocol. In the revised manuscript, we have updated the abstract to explicitly state the primary evaluation metric (Pearson correlation with human usability labels), the baselines (GPT-4, Claude-3, and other large models), the data splits (held-out 20% test set of interfaces), and the reporting of error bars with statistical significance (paired t-tests, p < 0.01). These details are already elaborated in Section 4.1 and Table 2, where results are shown on the test set. The outperformance is measured on interfaces unseen during training, and we have added a sentence noting k-fold cross-validation to further address potential overfitting concerns. revision: yes
-
Referee: [Abstract] Abstract: The statement that uxCUA 'produces realistic critiques of both synthetic and real UIs' does not indicate whether the real UIs were held out from training, the selection process for real interfaces, or any correlation with independent expert ratings. Given that the numerical score is learned from human labels, this evidence is load-bearing for the generalization claim.
Authors: We acknowledge that the original abstract omitted key details on the real-UI evaluation. We have revised the abstract to clarify that real UIs were sampled from a held-out test partition never seen during training or fine-tuning. The selection process drew from diverse public UI corpora spanning web and mobile domains to avoid domain bias. We now report a Pearson correlation of 0.72 between the agent's critiques and independent expert ratings on a 50-UI subset, with full methodology and examples provided in Section 5.2 and the appendix. These additions directly support the generalization claim beyond the training label distribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical ML training procedure for an agent that learns to prioritize flows, execute interactions, and output a numerical usability score fitted to human-provided labels and preferences. This is standard supervised learning on a dataset; the claimed 'computational definition' is the training objective itself rather than a mathematical derivation that reduces a result to its own inputs by construction. No equations, self-citations, or uniqueness theorems are invoked in the abstract or described method that would create self-definitional, fitted-prediction, or load-bearing circularity. Evaluation claims on synthetic and real UIs raise questions of generalization strength, but those are evidentiary rather than circularity issues.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned usability score parameters
axioms (1)
- domain assumption Usability can be operationalized computationally by prioritizing important interaction flows, executing human-like interactions, and predicting a learned numerical score
Reference graph
Works this paper leans on
-
[1]
Pieter Agten, Wouter Joosen, Frank Piessens, and Nick Nikiforakis. 2015. Seven months’ worth of mistakes: A longitudinal study of typosquatting abuse. In Proceedings of the 22nd Network and Distributed System Security Symposium (NDSS 2015). Internet Society
2015
-
[2]
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. 2024. Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs. arXiv:2402.14740 [cs.LG] https://arxiv.org/abs/2402.14740
work page internal anchor Pith review arXiv 2024
-
[3]
Anderson and Christian Lebiere
John R. Anderson and Christian Lebiere. 1998.The Atomic Components of Thought. Lawrence Erlbaum Associates, Mahwah, NJ
1998
-
[4]
Anthropic. 2026. Claude Code: Overview (Documentation). https://docs. anthropic.com/en/docs/agents-and-tools/claude-code/overview. Accessed 2026- 02-06
2026
-
[5]
Apple. 2023. Human Interface Guidelines. https://developer.apple.com/design/ human-interface-guidelines
2023
-
[6]
Arcada Labs. 2026. DesignArena by Arcada Labs. https://www.designarena.ai/. Accessed 2026-02-06
2026
-
[7]
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. 2024. DigiRL: Training In-The-Wild Device-Control Agents with Au- tonomous Reinforcement Learning. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024). doi:10.52202/079017-0397
-
[8]
Stuartk Card, THOMASP MORAN, and Allen Newell. 1986. The model human processor- An engineering model of human performance.Handbook of perception and human performance.2, 45–1 (1986), 1–35
1986
-
[9]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Gener- alist Agent for the Web. InAdvances in Neural Information Process- ing Systems. https://proceedings.neurips.cc/paper_files/paper/2023/file/ 5950bf290a1570ea401bf98882128160-Paper-Datasets_and_Benchmarks.pdf
2023
-
[10]
Linda Di Geronimo, Larissa Braz, Enrico Fregnan, Fabio Palomba, and Alberto Bacchelli. 2020. UI Dark Patterns and Where to Find Them: A Study on Mobile Applications and User Perception. InProceedings of the 2020 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’20). Association for Computing Machinery, New York, NY, USA, 1–14. d...
-
[11]
2004.Human-computer interaction
Alan Dix. 2004.Human-computer interaction. Vol. 1. Pearson Education
2004
-
[12]
Peitong Duan, Chin-Yi Cheng, Gang Li, Bjoern Hartmann, and Yang Li. 2024. UICrit: Enhancing Automated Design Evaluation with a UI Critique Dataset. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machin- ery, New York, NY, USA, Article 46, 17 pages. doi:10....
-
[13]
Leah Findlater and Joanna McGrenere. 2007. Evaluating reduced-functionality interfaces according to feature findability and awareness. InIFIP Conference on Human-Computer Interaction. Springer, 592–605
2007
-
[14]
Raymond Fok, Mingyuan Zhong, Anne Spencer Ross, James Fogarty, and Ja- cob O. Wobbrock. 2022. A Large-Scale Longitudinal Analysis of Missing Label Accessibility Failures in Android Apps. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems(New Orleans, LA, USA)(CHI ’22). As- sociation for Computing Machinery, New York, NY, USA, A...
- [16]
-
[17]
Krzysztof Gajos and Daniel S Weld. 2004. SUPPLE: automatically generating user interfaces. InProceedings of the 9th international conference on Intelligent user interfaces. 93–100
2004
-
[18]
Krzysztof Gajos and Daniel S Weld. 2005. Preference elicitation for interface optimization. InProceedings of the 18th annual ACM symposium on User interface software and technology. 173–182
2005
-
[19]
Yifei Gao, Jiang Wu, Xiaoyi Chen, Yifan Yang, Zhe Cui, Tianyi Ma, Jiaming Zhang, and Jitao Sang. 2026. GUITester: Enabling GUI Agents for Exploratory Defect Discovery.arXiv preprint arXiv:2601.04500(2026). doi:10.48550/arXiv.2601.04500
-
[20]
Kelley Gordon. 2020. 5 Principles of Visual Design in UX. https://www.nngroup. com/articles/principles-visual-design/
2020
-
[21]
Wayne D. Gray and Marilyn C. Salzman. 1998. Damaged Merchandise? A Review of Experiments That Compare Usability Evaluation Methods.Human–Computer Interaction13, 3 (1998), 203–261. doi:10.1207/S15327051HCI1303_2
-
[22]
Johanna Gunawan, Amogh Pradeep, David Choffnes, Woodrow Hartzog, and Christo Wilson. 2021. A Comparative Study of Dark Patterns Across Web and Mobile Modalities.Proc. ACM Hum.-Comput. Interact.5, CSCW2, Article 377 (Oct. 2021), 29 pages. doi:10.1145/3479521
-
[23]
Longjie Guo, Chenjie Yuan, Mingyuan Zhong, Robert Wolfe, Ruican Zhong, Yue Xu, Bingbing Wen, Hua Shen, Lucy Lu Wang, and Alexis Hiniker. 2026. SusBench: An Online Benchmark for Evaluating Dark Pattern Susceptibility of Computer-Use Agents. InProceedings of the 31st International Conference on Intelligent User Interfaces (IUI ’26). Association for Computin...
- [24]
-
[25]
Perttu Hämäläinen, Mikke Tavast, and Anton Kunnari. 2023. Evaluating Large Language Models in Generating Synthetic HCI Research Data: a Case Study. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery, New York, NY, USA. doi:10.1145/3544548. 3580688
-
[26]
Jois, Matthew Green, and Aviel Rubin
Qingying Hao, Licheng Luo, Steve T.K. Jan, and Gang Wang. 2021. It’s Not What It Looks Like: Manipulating Perceptual Hashing based Applications. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security(Virtual Event, Republic of Korea)(CCS ’21). Association for Computing Machinery, New York, NY, USA, 69–85. doi:10.1145/3460...
-
[27]
Aurora Harley. 2018. UX Expert Reviews. https://www.nngroup.com/articles/ux- expert-reviews/
2018
-
[28]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 6314–6330. https...
2024
-
[29]
Steffen Holter, Eunyee Koh, Mustafa Doga Dogan, and Gromit Yeuk-Yin Chan
-
[30]
arXiv:2601.15777 [cs.HC] https://arxiv.org/abs/2601.15777
UXCascade: Scalable Usability Testing with Simulated User Agents. arXiv:2601.15777 [cs.HC] https://arxiv.org/abs/2601.15777
-
[31]
Aleksi Ikkala, Florian Fischer, Markus Klar, Miroslav Bachinski, Arthur Fleig, Andrew Howes, Perttu Hämäläinen, Jörg Müller, Roderick Murray-Smith, and Antti Oulasvirta. 2022. Breathing Life Into Biomechanical User Models. In Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology(Bend, OR, USA)(UIST ’22). Association for Co...
-
[32]
Shivani Kapania, William Agnew, Motahhare Eslami, Hoda Heidari, and Sarah E. Fox. 2025. Simulacrum of Stories: Examining Large Language Models as Qualita- tive Research Participants. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3706598.3713220 ...
-
[33]
Panagiotis Kintis, Najmeh Miramirkhani, Charles Lever, Yizheng Chen, Rosa Romero-Gómez, Nikolaos Pitropakis, Nick Nikiforakis, and Manos Antonakakis
-
[34]
In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Gao et al
Hiding in plain sight: A longitudinal study of combosquatting abuse. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Gao et al. Security. 569–586
2017
-
[35]
2025.Why Organizations Don’t Do User Research and How to Change That
Laura Klein. 2025.Why Organizations Don’t Do User Research and How to Change That. Nielsen Norman Group. https://www.nngroup.com/articles/why- organizations-dont-do-user-research/
2025
-
[36]
Evan Klinger and David Starkweather. 2021. pHash: The open source perceptual hash library. https://www.phash.org/docs/
2021
-
[37]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[38]
2026.The RLHF Book: Reinforcement Learning from Hu- man Feedback, Alignment, and Post-Training LLMs
Nathan Lambert. 2026.The RLHF Book: Reinforcement Learning from Hu- man Feedback, Alignment, and Post-Training LLMs. Manning Publications. https://www.manning.com/books/the-rlhf-book Manning Early Access Pro- gram (MEAP); publication estimated Summer 2026; last updated January 2026
2026
- [39]
-
[40]
William Lidwell, Kritina Holden, and Jill Butler. 2010.Universal principles of design, revised and updated: 125 ways to enhance usability, influence perception, increase appeal, make better design decisions, and teach through design. Rockport Pub
2010
-
[41]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[42]
Let’s Verify Step by Step.arXiv preprint arXiv:2305.20050(2023). arXiv:2305.20050 [cs.LG] doi:10.48550/arXiv.2305.20050
work page internal anchor Pith review doi:10.48550/arxiv.2305.20050 2023
-
[43]
LMArena Team. 2025. WebDev Arena: A Live LLM Leaderboard for Web App Development. https://lmarena.ai/blog/webdev-arena/. Published 2025-03-09; contributors: Aryan Vichare, Anastasios N. Angelopoulos, Wei-Lin Chiang, Kelly Tang, Luca Manolache; accessed 2026-02-06
2025
-
[44]
Yuxuan Lu, Bingsheng Yao, Hansu Gu, Jing Huang, Zheshen Jessie Wang, Yang Li, Jiri Gesi, Qi He, Toby Jia-Jun Li, and Dakuo Wang. 2025. UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (CHI EA ’25). Association for Computing Machinery,...
-
[45]
Bailey, Maneesh Agrawala, Björn Hartmann, and Steven P
Kurt Luther, Jari-Lee Tolentino, Wei Wu, Amy Pavel, Brian P. Bailey, Maneesh Agrawala, Björn Hartmann, and Steven P. Dow. 2015. Structuring, Aggregating, and Evaluating Crowdsourced Design Critique. InProceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing(Van- couver, BC, Canada)(CSCW ’15). Association for Computi...
-
[46]
Thomas Mahatody, Mouldi Sagar, and Christophe Kolski. 2010. State of the art on the cognitive walkthrough method, its variants and evolutions.Intl. Journal of Human–Computer Interaction26, 8 (2010), 741–785
2010
-
[47]
Hee Seung Moon, Antti Oulasvirta, and Byungjoo Lee. 2023. Amortized Inference with User Simulations. InCHI 2023 - Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM. doi:10.1145/3544548.3581439
-
[48]
1994.Usability engineering
Jakob Nielsen. 1994.Usability engineering. Morgan Kaufmann
1994
-
[49]
Jakob Nielsen. 2012. Usability 101: Introduction to Usability. https://www. nngroup.com/articles/usability-101-introduction-to-usability/
2012
-
[50]
Jakob Nielsen and Thomas K. Landauer. 1993. A mathematical model of the finding of usability problems. InProceedings of the INTERACT ’93 and CHI ’93 Conference on Human Factors in Computing Systems(Amsterdam, The Nether- lands)(CHI ’93). Association for Computing Machinery, New York, NY, USA, 206–213. doi:10.1145/169059.169166
-
[51]
Jakob Nielsen and Rolf Molich. 1990. Heuristic evaluation of user interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (Seattle, Washington, USA)(CHI ’90). Association for Computing Machinery, New York, NY, USA, 249–256. doi:10.1145/97243.97281
-
[52]
OpenAI. 2023. GPT-4V(ision) System Card. https://cdn.openai.com/papers/ GPTV_System_Card.pdf. OpenAI system card
2023
-
[53]
OpenAI. 2025. Introducing GPT-5. https://openai.com/index/introducing-gpt-5/
2025
-
[54]
Antti Oulasvirta, Samuli De Pascale, Janin Koch, Thomas Langerak, Jussi Joki- nen, Kashyap Todi, Markku Laine, Manoj Kristhombuge, Yuxi Zhu, Aliaksei Miniukovich, et al. 2018. Aalto interface metrics (AIM) a service and codebase for computational GUI evaluation. InAdjunct proceedings of the 31st annual ACM symposium on user interface software and technolo...
2018
-
[55]
Antti Oulasvirta, Jussi PP Jokinen, and Andrew Howes. 2022. Computational rationality as a theory of interaction. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems. 1–14
2022
-
[56]
Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Lindsay Popowski, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2022. Social Simulacra: Creating Populated Prototypes for Social Computing Systems. arXiv:2208.04024 [cs.HC] https: //arxiv.org/abs/2208.04024
-
[57]
Fabio Paternò, Cristiano Mancini, and Silvia Meniconi. 1997. ConcurTaskTrees: A Diagrammatic Notation for Specifying Task Models. InHuman-Computer Interaction INTERACT ’97, Steve Howard, Judy Hammond, and Gitte Lindgaard (Eds.). Springer, Boston, MA, 362–369. doi:10.1007/978-0-387-35175-9_58
-
[58]
Yi-Hao Peng, Jeffrey P. Bigham, and Jason Wu. 2025. DesignPref: Capturing Personal Preferences in Visual Design Generation. arXiv:2511.20513 [cs.CV] https://arxiv.org/abs/2511.20513
-
[59]
Angel R. Puerta. 1997. A Model-Based Interface Development Environment. IEEE Software14, 4 (1997), 40–47
1997
-
[60]
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Jiadai Sun, Xinyue Yang, Yu Yang, Shuntian Yao, Wei Xu, Jie Tang, and Yuxiao Dong. 2025. WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning. InInternational Conference on Learning Representations (ICLR)
2025
-
[61]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, Wanjun Zhong, Kuanye Li, Jiale Yang, Yu Miao, Woyu Lin, Longxiang Liu, Xu Jiang, Qianli Ma, Jingyu Li, Xiaojun Xiao, Kai Cai, Chuang Li, Yaowei Zheng, Chaolin Jin, Chen Li, Xiao Zhou, Minchao Wang, Haoli Chen, Zhaojian Li, Haihua Ya...
work page internal anchor Pith review arXiv 2025
-
[62]
Jathushan Rajasegaran, Naveen Karunanayake, Ashanie Gunathillake, Suranga Seneviratne, and Guillaume Jourjon. 2019. A multi-modal neural embeddings ap- proach for detecting mobile counterfeit apps. InThe World Wide Web Conference. 3165–3171
2019
-
[63]
Shreya Shankar, JD Zamfirescu-Pereira, Björn Hartmann, Aditya Parameswaran, and Ian Arawjo. 2024. Who validates the validators? aligning llm-assisted evalu- ation of llm outputs with human preferences. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–14
2024
-
[64]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024). arXiv:2402.03300 [cs.CL] doi:10.48550/arXiv. 2402.03300
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[65]
William F. Shen, Xinchi Qiu, Chenxi Whitehouse, Lisa Alazraki, Shashwat Goel, Francesco Barbieri, Timon Willi, Akhil Mathur, and Ilias Leontiadis. 2026. Re- thinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks. arXiv:2602.05125 [cs.LG] https://arxiv.org/abs/2602.05125
-
[66]
Danqing Shi, Yujun Zhu, Jussi P. P. Jokinen, Aditya Acharya, Aini Putkonen, Shumin Zhai, and Antti Oulasvirta. 2024. CRTypist: Simulating Touchscreen Typing Behavior via Computational Rationality. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. Association for Computing Machinery. doi:10.1145/3613904.3642918
-
[67]
2010.Designing the user interface: strategies for effective human-computer interaction
Ben Shneiderman. 2010.Designing the user interface: strategies for effective human-computer interaction. Pearson Education India
2010
- [68]
-
[69]
Kimi Team. 2026. Kimi K2.5: Visual Agentic Intelligence. arXiv:2602.02276 [cs.CL] https://arxiv.org/abs/2602.02276
work page internal anchor Pith review arXiv 2026
-
[70]
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. 2025. Judging the judges: Evaluating alignment and vulnerabilities in llms-as-judges. InProceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM 2). 404–430
2025
-
[71]
Maryam Tohidi, William Buxton, Ronald Baecker, and Abigail Sellen. 2006. Get- ting the right design and the design right. InProceedings of the SIGCHI conference on Human Factors in computing systems. 1243–1252
2006
-
[72]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony H...
-
[73]
Daniel Toyama, Philippe Hamel, Anita Gergely, Gheorghe Comanici, Amelia Glaese, Zafarali Ahmed, Tyler Jackson, Shibl Mourad, and Doina Pre- cup. 2021. AndroidEnv: A Reinforcement Learning Platform for Android. arXiv:2105.13231 [cs.LG] doi:10.48550/arXiv.2105.13231
-
[74]
Browser Use. 2026. Browser Use: The AI browser agent. https://browser-use.com Training Computer Use Agents to Assess the Usability of Graphical User Interfaces
2026
-
[75]
Bryan Wang, Gang Li, and Yang Li. 2023. Enabling conversational interaction with mobile ui using large language models. InProceedings of the 2023 CHI conference on human factors in computing systems. 1–17
2023
- [76]
-
[77]
Zichao Wang and Alexa Siu. 2026. Interview-Informed Generative Agents for Product Discovery: A Validation Study. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. ACM. Honorable Mention
2026
-
[78]
Ronald J Williams. 1992. Simple statistical gradient-following algorithms for connectionist reinforcement learning.Machine learning8, 3 (1992), 229–256
1992
-
[79]
Jason Wu, Yi-Hao Peng, Amanda Li, Amanda Swearngin, Jeffrey P. Bigham, and Jeffrey Nichols. 2024. UIClip: A Data-driven Model for Assessing User Interface Design. arXiv:2404.12500 [cs.HC] https://arxiv.org/abs/2404.12500
-
[80]
Jason Wu, Amanda Swearngin, Arun Krishna Vajjala, Alan Leung, Jeffrey Nichols, and Titus Barik. 2025. Improving User Interface Generation Models from De- signer Feedback. (Sept. 2025). arXiv:2509.16779 [cs.HC] doi:10.48550/arXiv.2509. 16779
-
[81]
Wei Xiang, Hanfei Zhu, Suqi Lou, Xinli Chen, Zhenghua Pan, Yuxiao Jin, Shuyue Chen, and Lingyun Sun. 2024. SimUser: Generating Usability Feedback by Simulating Various Users Interacting with Mobile Applications. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–17...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.