Recognition: unknown
MetaSR: Content-Adaptive Metadata Orchestration for Generative Super-Resolution
Pith reviewed 2026-05-07 13:42 UTC · model grok-4.3
The pith
MetaSR shows that a Diffusion Transformer can select and fuse content-dependent metadata to guide generative super-resolution, yielding higher quality at lower transmission bitrate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MetaSR is a Diffusion Transformer framework that dynamically selects heterogeneous metadata according to content type and degradation, then fuses the chosen cues inside the DiT's VAE and transformer backbone. Combined with an efficient distillation procedure that reduces inference to a single step, the method produces reconstructions whose PSNR and SSIM exceed those of fixed-metadata baselines while cutting the transmitted bitrate by up to half under a joint rate-distortion optimization that accounts for both sender transmission cost and display quality.
What carries the argument
The DiT-based content-adaptive metadata fusion that selects task-relevant side information and injects it through the model's own VAE and transformer layers under bitrate limits.
If this is right
- Higher PSNR and SSIM at the same transmitted bitrate across text, motion, cartoon, and face content.
- Up to 50 percent bitrate reduction while preserving matched reconstruction quality.
- One-step inference after distillation, enabling practical receiver-side deployment.
- Joint optimization of sender bitrate and receiver quality metrics inside the rate-distortion loop.
Where Pith is reading between the lines
- The same adaptive fusion idea could be tested on other conditional generative models that receive side information under bandwidth limits.
- Real-time video pipelines might benefit from the reduced per-frame transmission cost if the selection logic runs at the encoder.
- The distillation step suggests a route to lower sender computation when metadata choices must be made on the fly.
Load-bearing premise
The DiT backbone can reliably combine different metadata types in a content-dependent manner without adding artifacts or imposing heavy sender-side computation under real transmission limits.
What would settle it
An experiment on a held-out content class or degradation regime in which the adaptive metadata version shows no PSNR gain or bitrate reduction relative to a fixed-metadata baseline, or introduces visible artifacts.
Figures




read the original abstract
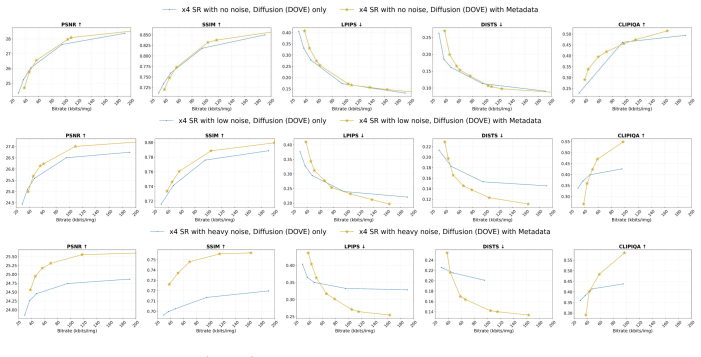
We study generative super-resolution (SR) in real-world scenarios where content and degradations vary across domains, genres, and segments. For example, images and videos may alternate between text overlays, fast motion, smooth cartoons, and low-light faces, each benefiting from different forms of side information. Existing metadata-guided SR methods typically use a fixed conditioning design, which is suboptimal when useful cues are content dependent and transmission budgets are limited. We propose MetaSR, a Diffusion Transformer (DiT)-based framework that selects and injects task-relevant metadata to guide SR under resource constraints. Specifically, we use the DiT's own VAE and transformer backbone to fuse heterogeneous metadata, and adopt an efficient distillation strategy that enables one-step diffusion inference. Experiments across diverse content buckets and degradation regimes show that MetaSR outperforms reference solutions by up to 1.0~dB PSNR while achieving up to 50\% transmission bitrate saving at matched quality. We assess these gains under a rate--distortion optimization (RDO) framework that jointly accounts for sender-side bitrate and receiver/display quality metrics (e.g., PSNR and SSIM).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MetaSR, a Diffusion Transformer (DiT)-based framework for generative super-resolution that performs content-adaptive selection and injection of heterogeneous metadata to guide reconstruction under transmission constraints. It fuses metadata using the model's own VAE and transformer backbone and applies distillation to enable one-step inference. Under a rate-distortion optimization (RDO) framework, experiments across content buckets and degradation regimes report gains of up to 1.0 dB PSNR and up to 50% transmission bitrate savings at matched quality relative to reference solutions.
Significance. If the reported gains prove robust, the work could meaningfully advance practical generative SR for variable real-world content by reducing transmission overhead while adapting metadata to content type. A strength is the parameter-efficient fusion strategy that reuses the DiT backbone itself rather than introducing separate conditioning networks, together with the distillation approach that supports low-latency inference.
major comments (1)
- The RDO framework (Abstract and experimental evaluation) jointly optimizes sender-side transmission bitrate against receiver PSNR/SSIM, yet the computational overhead of per-segment metadata selection and DiT-based feature extraction at the sender is neither quantified nor folded into the optimization. This is load-bearing for the 50% bitrate-saving claim, because real transmission constraints include total cost; if sender compute is material, the net savings would be lower than stated.
minor comments (2)
- The abstract states concrete performance numbers (1.0 dB PSNR, 50% bitrate) without naming the datasets, number of content buckets, or baseline methods; a one-sentence summary of the experimental protocol would improve readability.
- Notation for the metadata fusion step inside the transformer backbone could be clarified with a short equation or diagram reference to avoid ambiguity about how heterogeneous inputs are combined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: The RDO framework (Abstract and experimental evaluation) jointly optimizes sender-side transmission bitrate against receiver PSNR/SSIM, yet the computational overhead of per-segment metadata selection and DiT-based feature extraction at the sender is neither quantified nor folded into the optimization. This is load-bearing for the 50% bitrate-saving claim, because real transmission constraints include total cost; if sender compute is material, the net savings would be lower than stated.
Authors: We agree that sender-side computational overhead is a relevant factor for real-world rate-distortion trade-offs and that its omission limits the strength of the transmission-bitrate-saving claims. Our architecture reuses the existing VAE and DiT backbone for metadata fusion rather than adding dedicated conditioning modules, which keeps incremental cost modest relative to a standard DiT forward pass. However, we did not provide explicit runtime or FLOPs measurements for the per-segment selection and extraction steps. In the revised manuscript we will add a dedicated analysis section that reports sender-side compute (wall-clock time and FLOPs) on representative hardware across content buckets, together with a discussion of when transmission cost dominates versus when compute becomes material. This will allow readers to assess net savings under different deployment constraints. revision: yes
Circularity Check
No circularity: empirical gains reported from experiments, not derived by construction
full rationale
The manuscript presents MetaSR as a DiT-based framework for content-adaptive metadata selection and fusion, with gains (up to 1.0 dB PSNR and 50% bitrate saving) framed as experimental outcomes under an RDO framework. No equations, first-principles derivations, or predictions appear that reduce these results to fitted parameters, self-definitions, or self-citation chains. The method description (VAE/transformer fusion plus distillation) is presented as a design choice evaluated empirically across content buckets, without load-bearing uniqueness theorems or ansatz smuggling from prior self-work. This is the standard non-circular pattern for an applied ML proposal paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blau, Y., Michaeli, T.: The perception-distortion tradeoff. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018),https://openaccess.thecvf.com/content_cvpr_2018/papers/Blau_ The_Perception-Distortion_Tradeoff_CVPR_2018_paper.pdf
2018
-
[2]
Bourtsoulatze, E., Kurka, D.B., Gündüz, D.: Deep joint source-channel coding for wireless image transmission. In: Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2019),https://arxiv. org/abs/1809.01733
-
[3]
Canny, J.: A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine IntelligenceP AMI-8(6), 679–698 (1986).https: //doi.org/10.1109/TPAMI.1986.4767851
-
[4]
arXiv preprint arXiv:2505.16239 (2025)
Chen, Z., Zou, Z., Zhang, K., Su, X., Yuan, X., Guo, Y., Zhang, Y.: Dove: Effi- cient one-step diffusion model for real-world video super-resolution. arXiv preprint arXiv:2505.16239 (2025)
-
[5]
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unify- ing structure and texture similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence44(5), 2567–2581 (2022).https://doi.org/10.1109/TPAMI. 2020.3045810,https://arxiv.org/abs/2004.07728
-
[6]
Confidence in Assurance 2.0 Cases
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional net- work for image super-resolution. In: European Conference on Computer Vision (ECCV) (2014).https://doi.org/10.1007/978- 3- 319- 10593- 2_13,https: //link.springer.com/chapter/10.1007/978-3-319-10593-2_13
-
[7]
Denoising Diffusion Probabilistic Models
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems (NeurIPS) (2020),https://arxiv.org/ abs/2006.11239
work page internal anchor Pith review arXiv 2020
-
[8]
Standard (2000),https://www.itu.int/rec/dologin_pub.asp?id=T-REC-T.88-200002- S!!PDF-E&lang=e&type=items
International Telecommunication Union (ITU-T): Itu-t recommendation t.88: In- formation technology – lossy/lossless coding of bi-level images (jbig2). Standard (2000),https://www.itu.int/rec/dologin_pub.asp?id=T-REC-T.88-200002- S!!PDF-E&lang=e&type=items
2000
-
[9]
Web page (2001),https://jpeg.org/jbig/
Joint Photographic Experts Group (JPEG): Jbig2 (itu-t t.88 | iso/iec 14492): Overview of jbig/jbig2. Web page (2001),https://jpeg.org/jbig/
2001
-
[10]
Kawar, B., Vaksman, G., Elad, M.: Denoising diffusion restoration models. In: Advances in Neural Information Processing Systems (NeurIPS) (2022),https: //arxiv.org/abs/2201.11793
-
[11]
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR) (2016),https://openaccess.thecvf.com/ content _ cvpr _ 2016 / papers / Kim _ Accurate _ Image _ Super - Resolution _ CVPR _ 2016_paper.pdf
2016
-
[12]
arXiv preprint (2018), https://arxiv.org/abs/1812.07174
Kim, K., Chun, S.Y.: Sredgenet: Edge enhanced single image super resolution using dense edge detection network and feature merge network. arXiv preprint (2018), https://arxiv.org/abs/1812.07174
-
[13]
Ledig, C., Theis, L., Huszar, F., Caballero, J., Cunningham, A., Acosta, A., Aitken, A., Tejani, A., Totz, J., Wang, Z., Shi, W.: Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017), https://openaccess.thecvf.com/content_cvpr_2...
2017
-
[14]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops (ICCVW) (2021),https: / / openaccess
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Im- age restoration using swin transformer. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops (ICCVW) (2021),https: / / openaccess . thecvf . com / content / ICCV2021W / AIM / papers / Liang _ SwinIR _ Image_Restoration_Using_Swin_Transformer_I...
2021
-
[15]
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual net- works for single image super-resolution. In: Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition Workshops (CVPRW) (2017), https://openaccess.thecvf.com/content_cvpr_2017_workshops/w12/papers/ Lim_Enhanced_Deep_Residual_CVPR_2017_paper.pdf
2017
-
[16]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Lu, C., Zhou, Y., Bao, F., Chen, J., Li, C., Zhu, J.: Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. In: Advances in Neural Information Processing Systems (NeurIPS) (2022),https://arxiv.org/ abs/2206.00927
-
[17]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent consistency models: Syn- thesizing high-resolution images with few-step inference. arXiv preprint (2023), https://arxiv.org/abs/2310.04378
work page internal anchor Pith review arXiv 2023
-
[18]
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y., Qie, X.: T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint (2023),https://arxiv.org/abs/2302.08453
-
[19]
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023),https://openaccess.thecvf.com/content/ICCV2023/papers/Peebles_ Scalable_Diffusion_Models_with_Transformers_ICCV_2023_paper.pdf
2023
-
[20]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022), https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High- Resolution _ Image _ Synthesis _ With _ Latent _ Diffusion _ Mod...
2022
-
[21]
Saharia, C., Ho, J., Chan, W., Salimans, T., Fleet, D.J., Norouzi, M.: Image super- resolution via iterative refinement. arXiv preprint (2021),https://arxiv.org/ abs/2104.07636
-
[22]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T., Ho, J.: Progressive distillation for fast sampling of diffusion models. arXiv preprint (2022),https://arxiv.org/abs/2202.00512
work page internal anchor Pith review arXiv 2022
-
[23]
Adversarial diffusion dis- tillation
Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distilla- tion. arXiv preprint (2023),https://arxiv.org/abs/2311.17042
-
[24]
Springer Science & Business Media (2013)
Schuster, G.M., Katsaggelos, A.: Rate-Distortion based video compression: opti- mal video frame compression and object boundary encoding. Springer Science & Business Media (2013)
2013
-
[25]
Schwarz, H., Marpe, D., Wiegand, T.: Overview of the scalable video coding ex- tension of the h.264/avc standard. IEEE Transactions on Circuits and Systems for Video Technology (2007).https://doi.org/10.1109/TCSVT.2007.905532, https://dl.acm.org/doi/10.1109/TCSVT.2007.905532
-
[26]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint (2021),https://arxiv.org/abs/2010.02502
work page internal anchor Pith review arXiv 2021
-
[27]
Song, Y., Dhariwal, P., Chen, M., Sutskever, I.: Consistency models. arXiv preprint (2023),https://arxiv.org/abs/2303.01469
work page internal anchor Pith review arXiv 2023
-
[28]
Wang, H.: Rich detail range (rdr): Redefining perceptual picture quality in the era of ai displays
-
[29]
arXiv preprint (2022),https://arxiv.org/abs/2207.12396
Wang, J., Chan, K.C.K., Loy, C.C.: Exploring clip for assessing the look and feel of images. arXiv preprint (2022),https://arxiv.org/abs/2207.12396
-
[30]
Wang, J., Yue, Z., Zhou, S., Chan, K.C.K., Loy, C.C.: Exploiting diffusion prior for real-world image super-resolution. arXiv preprint (2023),https://arxiv.org/ abs/2305.07015
-
[31]
Wang, X., Xie, L., Dong, C., Shan, Y.: Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision Workshops (ICCVW) (2021),https:// openaccess.thecvf.com/content/ICCV2021W/AIM/papers/Wang_Real- ESRGAN_ Training_Real- World_Blind_Super- Resolution_With_Pure...
2021
-
[32]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018),https: / / openaccess
Wang, X., Yu, K., Dong, C., Loy, C.C.: Recovering realistic texture in image super-resolution by deep spatial feature transform. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018),https: / / openaccess . thecvf . com / content _ cvpr _ 2018 / papers / Wang _ Recovering _ Realistic_Texture_CVPR_2018_paper.pdf
2018
-
[33]
Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Loy, C.C., Qiao, Y., Tang, X.: Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European Conference on Computer Vision (ECCV) Work- shops (2018),https://openaccess.thecvf.com/content_ECCVW_2018/papers/ 11133 / Wang _ ESRGAN _ Enhanced _ Super - Resolution _ Gener...
2018
-
[34]
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Process- ing13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[35]
IEEE Transactions on Information Theory (1976)
Wyner, A.D., Ziv, J.: The rate-distortion function for source coding with side information at the decoder. IEEE Transactions on Information Theory (1976). https://doi.org/10.1109/TIT.1976.1055508,https://dl.acm.org/doi/10. 1109/TIT.1976.1055508
-
[36]
Yang, F., Yang, H., Fu, J., Lu, H., Guo, B.: Learning texture transformer network for image super-resolution. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) (2020),https:// openaccess.thecvf.com/content_CVPR_2020/papers/Yang_Learning_Texture_ Transformer_Network_for_Image_Super-Resolution_CVPR_2020_paper.pdf
2020
-
[37]
Yang, W., Feng, J., Yang, J., Zhao, F., Liu, J., Guo, Z., Yan, S.: Deep edge guided recurrent residual learning for image super-resolution. IEEE Transactions on Image Processing (2017).https://doi.org/10.1109/TIP.2017.2750403, https://arxiv.org/abs/1604.08671
-
[38]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review arXiv 2024
-
[39]
Yue, Z., Wang, J., Loy, C.C.: Resshift: Efficient diffusion model for image super- resolution by residual shifting. In: Advances in Neural Information Processing Sys- tems (NeurIPS) (2023),https://arxiv.org/abs/2307.12348
-
[40]
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2023),https://openaccess.thecvf.com/content/ ICCV2023 / papers / Zhang _ Adding _ Conditional _ Control _ to _ Text - to - Image _ Diffusion_Models_ICCV_2023_paper.pdf
2023
-
[41]
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effec- tiveness of deep features as a perceptual metric. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 586–595 (2018).https://doi.org/10.1109/CVPR.2018.00068,https://arxiv.org/abs/ 1801.03924
-
[42]
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: European Conference on Com- puterVision(ECCV)(2018).https://doi.org/10.1007/978-3-030-01234-2_18, https://openaccess.thecvf.com/content_ECCV_2018/papers/Yulun_Zhang_ Image_Super-Resolution_Using_ECCV_2018_paper.pdf
-
[43]
Zhang,Z.,Wang,Z.,Lin,Z.,Qi,H.:Imagesuper-resolutionbyneuraltexturetrans- fer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019),https://openaccess.thecvf.com/content_CVPR_ 2019/papers/Zhang_Image_Super- Resolution_by_Neural_Texture_Transfer_ CVPR_2019_paper.pdf
2019
-
[44]
Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. In: Advances in Neural Informa- tion Processing Systems (NeurIPS) (2023),https://arxiv.org/abs/2302.04867
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.