Recognition: unknown
DiffAnon: Diffusion-based Prosody Control for Voice Anonymization
Pith reviewed 2026-05-07 12:44 UTC · model grok-4.3
The pith
A diffusion model with classifier-free guidance gives continuous inference-time control over prosody in voice anonymization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
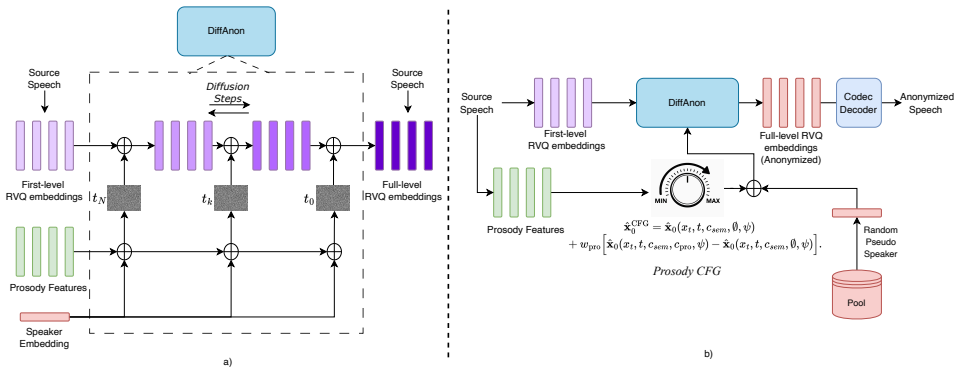
DiffAnon refines acoustic detail over semantic embeddings of an RVQ codec using a diffusion process with classifier-free guidance. This provides explicit, continuous, and interpolatable control over prosody preservation during anonymization, which the authors state is the first such framework. Experiments confirm structured trade-off behavior, with strong utility and competitive privacy maintained across the controllable operating points.
What carries the argument
Diffusion-based acoustic refinement with classifier-free guidance applied to RVQ semantic embeddings, which enables inference-time interpolation between anonymization strength and prosodic fidelity.
If this is right
- A single trained model can serve a range of privacy-utility operating points through parameter interpolation.
- Structured trade-off curves emerge between anonymization strength and prosodic detail.
- Competitive privacy levels hold while utility remains strong at multiple controllable points.
- No separate models or retraining steps are needed to shift the balance between identity concealment and prosody retention.
Where Pith is reading between the lines
- The same refinement-plus-guidance pattern could support tunable control in other speech generation or conversion tasks where style or affect must be adjusted.
- Deployment in voice data pipelines might become simpler if one model handles varying prosody requirements across different downstream uses like transcription or emotion analysis.
- The interpolation could be tested for robustness by checking whether semantic content remains intact when prosody is varied across languages or noisy conditions not covered in the main evaluation.
Load-bearing premise
That refining acoustic detail over semantic embeddings of an RVQ codec, steered by classifier-free guidance, produces smooth interpolation between anonymization strength and prosodic fidelity without introducing new artifacts or privacy leaks.
What would settle it
Varying the classifier-free guidance scale across multiple values and observing that prosody preservation metrics and privacy leakage scores do not change monotonically or smoothly, or that intermediate points show higher artifact rates than the endpoints.
Figures

read the original abstract
To preserve or not to preserve prosody is a central question in voice anonymization. Prosody conveys meaning and affect, yet is tightly coupled with speaker identity. Existing methods either discard prosody for privacy or lack a principled mechanism to control the utility-privacy trade-off, operating at fixed design points. We propose DiffAnon, a diffusion-based anonymization method with classifier-free guidance (CFG) that provides explicit, continuous inference-time control over prosody preservation. DiffAnon refines acoustic detail over semantic embeddings of an RVQ codec, enabling smooth interpolation between anonymization strength and prosodic fidelity within a single model. To the best of our knowledge, it is the first voice anonymization framework to provide structured, interpolatable inference-time prosody control. Experiments demonstrate structured trade-off behavior, achieving strong utility while maintaining competitive privacy across controllable operating points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DiffAnon, a diffusion-based framework for voice anonymization that uses classifier-free guidance to achieve continuous inference-time control over prosody preservation. By refining acoustic details atop semantic embeddings from an RVQ codec, it allows smooth interpolation between anonymization strength and prosodic fidelity within one model. It claims to be the first such system with structured, interpolatable control, with experiments showing good utility-privacy trade-offs across controllable points.
Significance. This approach could be significant for the field of privacy-preserving speech processing, as it provides a principled way to navigate the prosody-identity trade-off that previous methods handled only at fixed points. The diffusion refinement mechanism appears to enable the desired interpolatability without major architectural changes, potentially making it useful for real-world applications where users or systems need to adjust the level of anonymization dynamically.
minor comments (2)
- The claim of being 'the first' would benefit from a more explicit comparison table in the related work section to previous methods' control capabilities.
- Ensure that all acronyms (e.g., RVQ, CFG) are defined at first use in the main text.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on DiffAnon and for recommending minor revision. The referee's description accurately reflects the paper's contributions regarding diffusion-based prosody control in voice anonymization. As no specific major comments were provided in the report, we have no individual points to address point-by-point.
Circularity Check
No significant circularity detected
full rationale
The manuscript introduces DiffAnon as a novel diffusion-based architecture that refines acoustic details over RVQ semantic embeddings using classifier-free guidance to enable inference-time prosody control. No load-bearing equations, parameter fits, or derivations appear that reduce the claimed interpolatable trade-off to a self-definition, fitted input renamed as prediction, or self-citation chain. The 'first framework' claim rests on the architectural novelty and reported experimental behavior rather than on any internal reduction to inputs. The derivation chain is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work in a load-bearing way.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DiffAnon: Diffusion-based Prosody Control for Voice Anonymization
Introduction V oice anonymization aims to protect speaker privacy by con- cealing speaker identity in a speech signal, while still conveying the intended linguistic content for effective communication [1]. Speech jointly encodes linguistic content, para-linguistic infor- mation, and speaker identity, all of which are inherently en- tangled. As a result, v...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
As a result, anonymization must be evaluated along competing dimensions rather than a single metric
The Utility–Privacy Trade-off V oice anonymization is inherently a multi-objective problem, as speech simultaneously encodes linguistic content, speaker identity, prosody, and emotion. As a result, anonymization must be evaluated along competing dimensions rather than a single metric. The V oicePrivacy initiative [1, 12, 13] formal- izes this utility–priv...
2024
-
[3]
unconditional
DiffAnon We introduce DiffAnon, a diffusion-based framework for con- trollable voice anonymization (Fig. 1). The model is trained to reconstruct SpeechTokenizer codec embeddings [25] condi- tioned on separately extracted representations of linguistic con- tent, prosody, and speaker identity, which are then decoded into waveform via the codec decoder. At i...
-
[4]
During inference, we use DDIM sam- pling [34] with 100 denoising steps
Experimental Setup Training & Inference Details.DiffAnon is trained on the train- ing subsets of LibriTTS [33] for approximately 400k steps with a learning rate of1×10 −4 and a batch size of 8 on a single NVIDIA H100 GPU. During inference, we use DDIM sam- pling [34] with 100 denoising steps. Pseudo-speakers are sam- pled from a pool constructed from Libr...
2024
-
[5]
Results We evaluate DiffAnon with prosody guidance weightsw pro ∈ {1,0.8,0.5,0.2,0}to control source prosody preservation at inference. We also report pseudo-speaker guidance (w spk = 3.0), an inference setting without CFG where both prosody and speaker conditions are set to null, and mean pitch-shifting ap- plied before extracting prosody features. All r...
-
[6]
Conclusion Prosody lies at the center of the utility–privacy trade-off in voice anonymization: preserving it crucial for expressiveness, but in- creases the risk of identity leakage. In this work, we introduced DiffAnon, a diffusion-based anonymization framework that en- ables explicit and continuous control over prosody preservation via classifier-free g...
-
[7]
• The Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via the ARTS Program, Contract #D2023-2308110001
Acknowledgments This work was supported by: • The National Science Foundation (NSF) CAREER Award IIS-2533652. • The Office of the Director of National Intelligence (ODNI), Intelligence Advanced Research Projects Activity (IARPA), via the ARTS Program, Contract #D2023-2308110001. The views and conclusions contained herein are those of the authors and shoul...
-
[8]
These tools were not used to generate scientific content, results, experimental designs, anal- yses, or conclusions
Generative AI Use Disclosure Generative AI tools were employed solely for language polish- ing of text written by the authors. These tools were not used to generate scientific content, results, experimental designs, anal- yses, or conclusions. All authors are responsible for the full content of this paper and consent to its submission
-
[9]
The V oicePrivacy 2020 Challenge: Results and findings,
N. Tomashenko, X. Wang, E. Vincent, J. Patino, B. M. L. Srivas- tava, P.-G. No´e, A. Nautsch, N. Evans, J. Yamagishi, B. O’Brien, A. Chanclu, J.-F. Bonastre, M. Todisco, and M. Maouche, “The V oicePrivacy 2020 Challenge: Results and findings,”Computer Speech & Language, vol. 74, p. 101362, 2022
2020
-
[10]
V oicepm: A Robust Privacy Mea- surement on V oice Anonymity,
S. Zhang, Z. Li, and A. Das, “V oicepm: A Robust Privacy Mea- surement on V oice Anonymity,” inProc. 16th ACM Conference on Security and Privacy in Wireless and Mobile Networks, 2023, pp. 215–226
2023
-
[11]
Privacy Versus Emotion Preservation Trade-Offs in Emotion-Preserving Speaker Anonymization,
Z. Cai, H. L. Xinyuan, A. Garg, L. P. Garc ´ıa-Perera, K. Duh, S. Khudanpur, N. Andrews, and M. Wiesner, “Privacy Versus Emotion Preservation Trade-Offs in Emotion-Preserving Speaker Anonymization,” inIEEE Spoken Language Technology Work- shop, 2024, pp. 409–414
2024
-
[12]
J. Tonhauser, “Prosody and meaning,” inThe Oxford Handbook of Experimental Semantics and Pragmatics. Oxford University Press, 03 2019. [Online]. Available: https://doi.org/10.1093/ oxfordhb/9780198791768.013.30
-
[13]
Prosody in the com- prehension of spoken language: a literature review,
A. Cutler, D. Dahan, and W. van Donselaar, “Prosody in the com- prehension of spoken language: a literature review,”Lang Speech, vol. 40 ( Pt 2), pp. 141–201, Apr. 1997
1997
-
[14]
Gussenhoven,The Phonology of Tone and Intonation, ser
C. Gussenhoven,The Phonology of Tone and Intonation, ser. Re- search Surveys in Linguistics. Cambridge University Press, 2004
2004
-
[15]
On the importance of pure prosody in the perception of speaker identity,
E. E. Helander and J. Nurminen, “On the importance of pure prosody in the perception of speaker identity,” inInterspeech 2007, 2007, pp. 2665–2668
2007
-
[16]
Speaker recognition us- ing prosodic and lexical features,
S. Kajarekar, L. Ferrer, A. Venkataraman, K. Sonmez, E. Shriberg, A. Stolcke, H. Bratt, and R. Gadde, “Speaker recognition us- ing prosodic and lexical features,” in2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No.03EX721), 2003, pp. 19–24
2003
-
[17]
Prosodic features for speaker verification,
L. Mary and B. Yegnanarayana, “Prosodic features for speaker verification,” inInterspeech 2006, 2006, pp. paper 1999– Tue1CaP.4
2006
-
[18]
Analyzing and Improving Speaker Sim- ilarity Assessment for Speech Synthesis,
M.-A. Carbonneau, B. van Niekerk, H. Seut ´e, J.-P. Letendre, H. Kamper, and J. Za¨ıdi, “Analyzing and Improving Speaker Sim- ilarity Assessment for Speech Synthesis,” in13th edition of the Speech Synthesis Workshop, 2025, pp. 8–13
2025
-
[19]
Revealing emo- tional clusters in speaker embeddings: A contrastive learning strategy for speech emotion recognition,
I. R. Ulgen, Z. Du, C. Busso, and B. Sisman, “Revealing emo- tional clusters in speaker embeddings: A contrastive learning strategy for speech emotion recognition,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 12 081–12 085
2024
-
[20]
The third voiceprivacy challenge: Preserving emotional expressiveness and linguistic content in voice anonymization,
N. Tomashenko, X. Miao, P. Champion, S. Meyer, M. Panariello, X. Wang, N. Evans, E. Vincent, J. Yamagishi, and M. Todisco, “The third voiceprivacy challenge: Preserving emotional expressiveness and linguistic content in voice anonymization,”
-
[21]
Available: https://arxiv.org/abs/2601.11846
[Online]. Available: https://arxiv.org/abs/2601.11846
-
[22]
The voiceprivacy 2022 challenge: Progress and perspectives in voice anonymisation,
M. Panariello, N. Tomashenko, X. Wang, X. Miao, P. Champion, H. Nourtel, M. Todisco, N. Evans, E. Vincent, and J. Yamagishi, “The voiceprivacy 2022 challenge: Progress and perspectives in voice anonymisation,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 32, p. 3477–3491, Jul. 2024. [Online]. Available: https://doi.org/10.1109/TASLP.2024.3430530
-
[23]
Cas- cade of phonetic speech recognition, speaker embeddings gan and multispeaker speech synthesis for the V oicePrivacy 2022 Chal- lenge ,
S. Meyer, P. Tilli, F. Lux, P. Denisov, J. Koch, and N. T. Vu, “Cas- cade of phonetic speech recognition, speaker embeddings gan and multispeaker speech synthesis for the V oicePrivacy 2022 Chal- lenge ,” in2nd Symposium on Security and Privacy in Speech Communication, 2022
2022
-
[24]
Preserving spoken con- tent in voice anonymisation with character-level vocoder condi- tioning,
M. Panariello, M. Todisco, and N. Evans, “Preserving spoken con- tent in voice anonymisation with character-level vocoder condi- tioning,” in4th Symposium on Security and Privacy in Speech Communication, 2024, pp. 12–16
2024
-
[25]
Speaker Anonymization Using X-vector and Neural Waveform Models,
F. Fang, X. Wang, J. Yamagishi, I. Echizen, M. Todisco, N. Evans, and J.-F. Bonastre, “Speaker Anonymization Using X-vector and Neural Waveform Models,” in10th ISCA Workshop on Speech Synthesis (SSW 10), 2019, pp. 155–160
2019
-
[26]
Are disentangled represen- tations all you need to build speaker anonymization systems?
C. Pierre, A. Larcher, and D. Jouvet, “Are disentangled represen- tations all you need to build speaker anonymization systems?” in Interspeech 2022, 2022, pp. 2793–2797
2022
-
[27]
V oice Privacy - Investigating V oice Conversion Architecture with Different Bot- tleneck Features,
S. Akti, T. N. Nguyen, Y . Liu, and A. Waibel, “V oice Privacy - Investigating V oice Conversion Architecture with Different Bot- tleneck Features,” in4th Symposium on Security and Privacy in Speech Communication, 2024, pp. 44–49
2024
-
[28]
DiffVC+: Improving Diffusion- based V oice Conversion for Speaker Anonymization,
F. Huang, K. Zeng, and W. Zhu, “DiffVC+: Improving Diffusion- based V oice Conversion for Speaker Anonymization,” inInter- speech 2024, 2024, pp. 4453–4457
2024
-
[29]
Prosody is not identity: A speaker anonymization approach us- ing prosody cloning,
S. Meyer, F. Lux, J. Koch, P. Denisov, P. Tilli, and N. T. Vu, “Prosody is not identity: A speaker anonymization approach us- ing prosody cloning,” inICASSP 2023 - 2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[30]
V oice privacy using time-scale and pitch modification,
D. K. Singh, G. P. Prajapati, and H. A. Patil, “V oice privacy using time-scale and pitch modification,”SN Computer Science, vol. 5, no. 2, p. 243, Jan 2024. [Online]. Available: https://doi.org/10.1007/s42979-023-02549-8
-
[31]
Private kNN- VC: Interpretable Anonymization of Converted Speech,
C. Franzreb, A. Das, T. Polzehl, and S. M ¨oller, “Private kNN- VC: Interpretable Anonymization of Converted Speech,” inInter- speech 2025, 2025, pp. 3224–3228
2025
-
[32]
HLTCOE JHU Submission to the V oice Privacy Challenge 2024,
H. L. Xinyuan, Z. Cai, A. Garg, K. Duh, L. P. Garc ´ıa-Perera, S. Khudanpur, N. Andrews, and M. Wiesner, “HLTCOE JHU Submission to the V oice Privacy Challenge 2024,” in4th Sym- posium on Security and Privacy in Speech Communication, 2024, pp. 61–66
2024
-
[33]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. [Online]. Available: https://openreview.net/forum?id=qw8AKxfYbI
2021
-
[34]
Speechtokenizer: Unified speech tokenizer for speech lan- guage models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtokenizer: Unified speech tokenizer for speech lan- guage models,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=AF9Q8Vip84
2024
-
[35]
An overview of text-independent speaker recognition: From features to supervectors,
T. Kinnunen and H. Li, “An overview of text-independent speaker recognition: From features to supervectors,”Speech Communica- tion, vol. 52, no. 1, pp. 12–40, 2010. [Online]. Available: https:// www.sciencedirect.com/science/article/pii/S0167639309001289
2010
-
[36]
Prosodic Struc- ture Beyond Lexical Content: A Study of Self-Supervised Learn- ing,
S. Wallbridge, C. Minixhofer, C. Lai, and P. Bell, “Prosodic Struc- ture Beyond Lexical Content: A Study of Self-Supervised Learn- ing,” inInterspeech 2025, 2025, pp. 4723–4727
2025
-
[37]
Freevc: Towards high-quality text-free one-shot voice conversion,
J. Li, W. Tu, and L. Xiao, “Freevc: Towards high-quality text-free one-shot voice conversion,” inICASSP 2023 - 2023 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[38]
System description: Speaker anonymization system with sentiment transfer and feature interpolation,
T. Tan, S. Liu, Y . Duan, S. Zhao, and X. Shao, “System description: Speaker anonymization system with sentiment transfer and feature interpolation,” 2024. [Online]. Available: voiceprivacychallenge.org,
2024
-
[39]
Npu-ntu system for voice privacy 2024 chal- lenge
J. Yao, N. Kuzmin, Q. Wang, P. Guo, Z. Ning, D. Guo, K. A. Lee, E.-S. Chng, and L. Xie, “Npu-ntu system for voice privacy 2024 challenge,” 2025. [Online]. Available: https://arxiv.org/abs/2409.04173
-
[40]
Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,
K. Shen, Z. Ju, X. Tan, E. Liu, Y . Leng, L. He, T. Qin, sheng zhao, and J. Bian, “Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,” inThe Twelfth International Conference on Learning Representations,
-
[41]
Available: https://openreview.net/forum?id= Rc7dAwVL3v
[Online]. Available: https://openreview.net/forum?id= Rc7dAwVL3v
-
[42]
WaveNet: A Generative Model for Raw Audio
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio,” 2016. [Online]. Available: https://arxiv.org/abs/1609.03499
work page internal anchor Pith review arXiv 2016
-
[43]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech,” inInterspeech 2019, 2019, pp. 1526–1530
2019
-
[44]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview. net/forum?id=St1giarCHLP
2021
-
[45]
Open-source conversational ai with speechbrain 1.0,
M. Ravanelli, T. Parcollet, A. Moumen, S. de Langen, C. Subakan, P. Plantinga, Y . Wang, P. Mousavi, L. D. Libera, A. Ploujnikov, F. Paissan, D. Borra, S. Zaiem, Z. Zhao, S. Zhang, G. Karakasidis, S.-L. Yeh, P. Champion, A. Rouhe, R. Braun, F. Mai, J. Zuluaga- Gomez, S. M. Mousavi, A. Nautsch, H. Nguyen, X. Liu, S. Sagar, J. Duret, S. Mdhaffar, G. Laperri...
2024
-
[46]
Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,
L. Pepino, P. Riera, and L. Ferrer, “Emotion Recognition from Speech Using wav2vec 2.0 Embeddings,” inInterspeech 2021, 2021, pp. 3400–3404
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.