Recognition: unknown
Adaptive Transform Coding for Semantic Compression
Pith reviewed 2026-05-07 12:50 UTC · model grok-4.3
The pith
Gaussian mixture models enable adaptive transforms that improve semantic feature compression performance
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
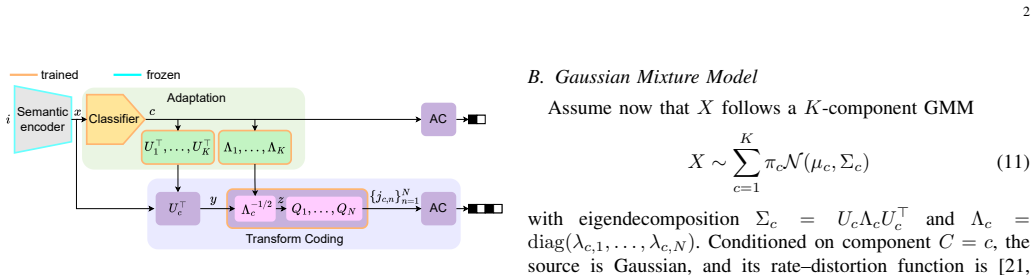
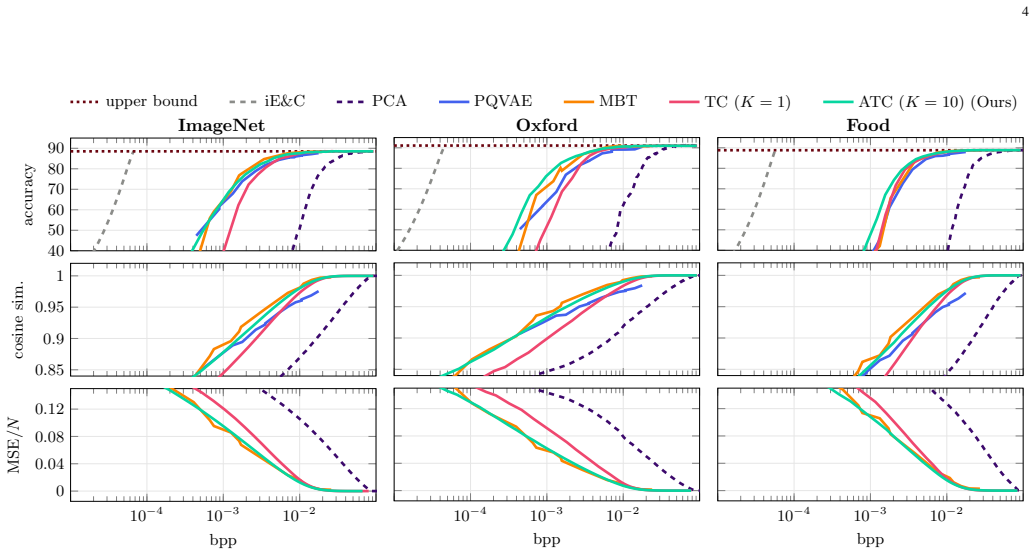
The proposed adaptive transform-coding method for semantic-feature compression is motivated by the conditional rate-distortion function of a Gaussian mixture model. It employs mode-dependent transforms and quantizers chosen according to the inferred source component, which allows more efficient coding of heterogeneous feature distributions. Evaluations demonstrate that this outperforms or matches state-of-the-art neural compression methods on features from vision backbones and foundation models, all while maintaining flexibility and interpretability.
What carries the argument
Mode-dependent transforms and quantizers selected by the inferred component of a Gaussian mixture model modeling the semantic features.
If this is right
- Improved rate-distortion performance for heterogeneous semantic feature distributions.
- Competitive or superior results compared to neural compression on various vision model features.
- Retention of flexibility and interpretability in the compression process.
- Direct applicability to semantic embeddings from multiple backbone and foundation models.
Where Pith is reading between the lines
- The approach could inspire similar adaptive classical methods for other learned embeddings beyond vision.
- Explicit mixture modeling might offer advantages in scenarios requiring explainable compression decisions.
- It opens the door to combining this with learned components for even better performance in future hybrids.
Load-bearing premise
The semantic features extracted by vision models can be well-represented by a Gaussian mixture model where different components correspond to distinct modes that benefit from separate transforms.
What would settle it
Demonstrating that a non-adaptive transform coding or a standard neural compressor consistently achieves lower bitrates at the same distortion level on the evaluated semantic features would disprove the claimed advantage.
Figures

read the original abstract
Visual data compression is shifting from human-centered reconstruction to machine-oriented representation coding. In this setting, an image is often mapped to a compact semantic embedding, which is then compressed and transmitted for downstream inference. We propose an adaptive transform-coding method for semantic-feature compression motivated by the conditional rate-distortion function of a Gaussian mixture model. The scheme uses mode-dependent transforms and quantizers selected according to the inferred source component, enabling more efficient coding of heterogeneous feature distributions. Evaluations on features from widely used vision backbones and foundation models show that the proposed method outperforms or is competitive with state-of-the-art neural compression methods while preserving flexibility and interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adaptive transform-coding scheme for compressing semantic features extracted from vision backbones and foundation models. Motivated by the conditional rate-distortion function of a Gaussian mixture model, the method infers the source component for each feature vector and selects a mode-dependent linear transform and quantizer pair. Evaluations claim that this approach outperforms or matches state-of-the-art neural compression methods on rate-distortion performance while retaining flexibility and interpretability.
Significance. If the reported gains are robust and attributable to the adaptive mechanism, the work is significant for providing a principled, interpretable bridge between classical transform coding and semantic representations. The GMM-based motivation offers a clear theoretical grounding that many learned compressors lack, and the emphasis on flexibility could aid deployment in heterogeneous machine-to-machine settings.
major comments (3)
- [§3.2] §3.2: The GMM fitting procedure, posterior inference of component indices, and the overhead of conveying the mode index to the decoder are described only at a high level without explicit equations or complexity analysis. In high-dimensional feature spaces this is load-bearing, as poor covariance conditioning or non-negligible side information could erase any conditional RD gain.
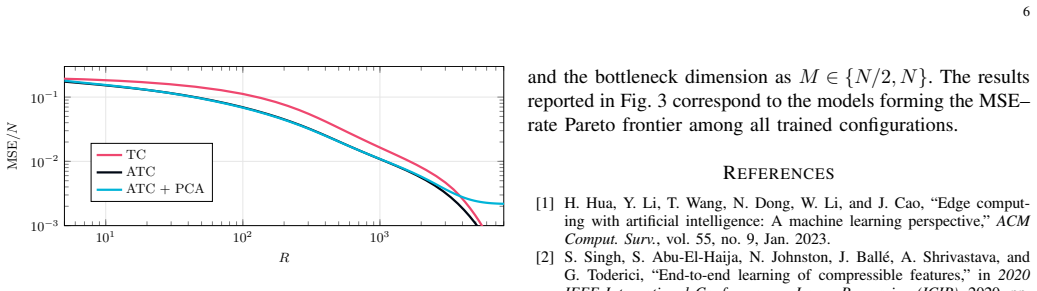
- [§4.3] §4.3, Table 2: No ablation is presented that replaces the mode-dependent transforms with a single fixed transform (e.g., global KLT) while keeping all other elements identical. Without this control experiment the central claim that adaptivity improves RD performance cannot be isolated from other implementation choices.
- [§4.1] §4.1: The manuscript provides no diagnostic on the fitted GMM (e.g., component separation, eigenvalue spread of covariances, or posterior entropy). In 256–2048-dimensional embeddings such diagnostics are necessary to substantiate that distinct modes justify separate transforms rather than collapsing to a single effective transform.
minor comments (2)
- [Abstract] Abstract: The claim of 'outperforms or is competitive' should be accompanied by concrete metrics (BD-rate, PSNR at fixed rate) and a list of the exact neural baselines and feature extractors used.
- [§2] §2: A table of symbols would clarify the notation for feature vectors, GMM parameters, and transform matrices.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive major comments, which help improve the clarity and rigor of our presentation. We respond to each point below, committing to revisions where appropriate to address the concerns about the GMM details, ablations, and diagnostics.
read point-by-point responses
-
Referee: [§3.2] The GMM fitting procedure, posterior inference of component indices, and the overhead of conveying the mode index to the decoder are described only at a high level without explicit equations or complexity analysis. In high-dimensional feature spaces this is load-bearing, as poor covariance conditioning or non-negligible side information could erase any conditional RD gain.
Authors: We agree that more explicit details are needed in §3.2. In the revised manuscript, we will expand this section with the EM algorithm equations for GMM parameter estimation, the formula for posterior probabilities p(k|x) = [π_k N(x; μ_k, Σ_k)] / sum, and the rate overhead calculation for the mode index (⌈log2(K)⌉ bits per vector). We will also provide a complexity analysis, noting that for typical K=4-8 and feature dims 256-2048, the side information is small (e.g., <0.1 bpp equivalent) and does not offset the RD gains. Covariance conditioning will be addressed by mentioning the use of diagonal loading or shrinkage estimators during fitting to ensure positive definiteness and numerical stability. revision: yes
-
Referee: [§4.3] No ablation is presented that replaces the mode-dependent transforms with a single fixed transform (e.g., global KLT) while keeping all other elements identical. Without this control experiment the central claim that adaptivity improves RD performance cannot be isolated from other implementation choices.
Authors: This is a valid point for isolating the contribution of adaptivity. We will add an ablation in the revised §4.3 and Table 2, comparing the full adaptive method (K>1) against a non-adaptive baseline using a single global transform (equivalent to K=1 GMM, i.e., standard KLT). This control will keep the quantizer design and other elements identical, allowing direct attribution of any RD improvements to the mode-dependent selection. We expect this to confirm the benefits of adaptivity as motivated by the conditional RD function. revision: yes
-
Referee: [§4.1] The manuscript provides no diagnostic on the fitted GMM (e.g., component separation, eigenvalue spread of covariances, or posterior entropy). In 256–2048-dimensional embeddings such diagnostics are necessary to substantiate that distinct modes justify separate transforms rather than collapsing to a single effective transform.
Authors: We concur that empirical diagnostics on the GMM are important to validate the modeling assumptions. In the revision, we will augment §4.1 with GMM diagnostics, including: (i) measures of component separation such as the average posterior probability or Bhattacharyya distance between components; (ii) eigenvalue spreads or condition numbers of the covariance matrices to demonstrate they are distinct and well-conditioned; and (iii) the entropy of the posterior distributions to show that the component assignments are not uniform but informative. These will be presented for the feature dimensions used (256–2048), supporting that multiple modes are justified. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained.
full rationale
The paper motivates its adaptive transform-coding scheme from the conditional rate-distortion function of a Gaussian mixture model and selects mode-dependent transforms based on inferred components. However, the provided abstract and reader's assessment contain no equations, fitting procedures, or self-citations that reduce the claimed RD gains or outperformance to inputs by construction. Performance claims rest on empirical evaluations against neural compression baselines rather than any fitted-parameter renaming or ansatz smuggling. The central claim therefore retains independent empirical content and does not collapse into a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic features from vision models follow a Gaussian mixture model whose components enable effective selection of mode-dependent transforms and quantizers.
Reference graph
Works this paper leans on
-
[1]
Edge comput- ing with artificial intelligence: A machine learning perspective,
H. Hua, Y . Li, T. Wang, N. Dong, W. Li, and J. Cao, “Edge comput- ing with artificial intelligence: A machine learning perspective,”ACM Comput. Surv., vol. 55, no. 9, Jan. 2023
2023
-
[2]
End-to-end learning of compressible features,
S. Singh, S. Abu-El-Haija, N. Johnston, J. Ball ´e, A. Shrivastava, and G. Toderici, “End-to-end learning of compressible features,” in2020 IEEE International Conference on Image Processing (ICIP), 2020, pp. 3349–3353
2020
-
[3]
Supervised compression for resource-constrained edge computing systems,
Y . Matsubara, R. Yang, M. Levorato, and S. Mandt, “Supervised compression for resource-constrained edge computing systems,” in2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, pp. 923–933
2022
-
[4]
Feature compression for rate constrained object detection on the edge,
Z. Yuan, S. Rawlekar, S. Garg, E. Erkip, and Y . Wang, “Feature compression for rate constrained object detection on the edge,” in 2022 IEEE 5th International Conference on Multimedia Information Processing and Retrieval (MIPR), 2022, pp. 1–6
2022
-
[5]
Taskonomy: Disentangling task transfer learning,
A. R. Zamir, A. Sax, W. Shen, L. Guibas, J. Malik, and S. Savarese, “Taskonomy: Disentangling task transfer learning,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 3712–3722
2018
-
[6]
Pareto-optimal bit allocation for collabora- tive intelligence,
S. R. Alvar and I. V . Baji ´c, “Pareto-optimal bit allocation for collabora- tive intelligence,”IEEE Transactions on Image Processing, vol. 30, pp. 3348–3361, 2021
2021
-
[7]
A multi-task supervised compression model for split computing,
Y . Matsubara, M. Mendula, and M. Levorato, “A multi-task supervised compression model for split computing,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025, pp. 4913–4922
2025
-
[8]
Which tasks should be compressed together? a causal dis- covery approach for efficient multi-task representation compression,
S. Guo, J. Chen, Z. Hu, Z. Chen, W. Yang, Y . Lin, X. Jiang, and L. DUAN, “Which tasks should be compressed together? a causal dis- covery approach for efficient multi-task representation compression,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
The jpeg ai standard: Providing efficient human and machine visual data consumption,
J. Ascenso, E. Alshina, and T. Ebrahimi, “The jpeg ai standard: Providing efficient human and machine visual data consumption,”IEEE MultiMedia, vol. 30, no. 1, pp. 100–111, 2023
2023
-
[10]
Jpeg ai: The first international standard for image coding based on an end-to-end learning-based approach,
E. Alshina, J. Ascenso, and T. Ebrahimi, “Jpeg ai: The first international standard for image coding based on an end-to-end learning-based approach,”IEEE MultiMedia, vol. 31, no. 4, pp. 60–69, 2024
2024
-
[11]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, ...
2021
-
[12]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” in Advances in Neural Information Processing Systems, A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 34 892–34 916
2023
-
[13]
Compression beyond pixels: Semantic compression with multimodal foundation models,
R. Shen, H. Wu, W. Zhang, J. Hu, and D. Gunduz, “Compression beyond pixels: Semantic compression with multimodal foundation models,” in 2025 IEEE 35th International Workshop on Machine Learning for Signal Processing (MLSP), 2025, pp. 1–6
2025
-
[14]
Theoretical foundations of transform coding,
V . Goyal, “Theoretical foundations of transform coding,”IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 9–21, 2001
2001
-
[15]
The jpeg still picture compression standard,
G. Wallace, “The jpeg still picture compression standard,”IEEE Trans- actions on Consumer Electronics, vol. 38, no. 1, pp. xviii–xxxiv, 1992
1992
-
[16]
The jpeg 2000 still im- age compression standard,
A. Skodras, C. Christopoulos, and T. Ebrahimi, “The jpeg 2000 still im- age compression standard,”IEEE Signal Processing Magazine, vol. 18, no. 5, pp. 36–58, 2001
2000
-
[17]
Optimally adaptive transform coding,
R. Dony and S. Haykin, “Optimally adaptive transform coding,”IEEE Transactions on Image Processing, vol. 4, no. 10, pp. 1358–1370, 1995
1995
-
[18]
From mixtures of mixtures to adaptive transform coding,
C. Archer and T. K. Leen, “From mixtures of mixtures to adaptive transform coding,” inProceedings of the 14th International Conference on Neural Information Processing Systems, ser. NIPS’00. Cambridge, MA, USA: MIT Press, 2000, p. 886–892
2000
-
[19]
A generalized lloyd-type algorithm for adaptive transform coder design,
C. Archer and T. Leen, “A generalized lloyd-type algorithm for adaptive transform coder design,”IEEE Transactions on Signal Processing, vol. 52, no. 1, pp. 255–264, 2004
2004
-
[20]
Berger,Rate Distortion Theory: A Mathematical Basis for Data Com- pression, ser
T. Berger,Rate Distortion Theory: A Mathematical Basis for Data Com- pression, ser. Prentice-Hall Series in Information and System Sciences. Englewood Cliffs, NJ: Prentice-Hall, 1971. 7
1971
-
[21]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. Hoboken, NJ: Wiley-Interscience, 2006
2006
-
[22]
Conditional rate-distortion theory,
R. M. Gray, “Conditional rate-distortion theory,” Stanford University, Electronics Laboratories, Stanford, CA, Tech. Rep. Technical Report 6502-2, Oct. 1972
1972
-
[23]
I. T. Jolliffe,Principal Component Analysis. Springer New York, NY , 2002
2002
-
[24]
Least squares quantization in pcm,
S. P. Lloyd, “Least squares quantization in pcm,”IEEE Transactions on Information Theory, vol. 28, no. 2, pp. 129–137, Mar. 1982
1982
-
[25]
Joint autoregressive and hier- archical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. Toderici, “Joint autoregressive and hier- archical priors for learned image compression,” inAdvances in Neural Information Processing Systems 31, 2018
2018
-
[26]
Nonlinear transform coding,
J. Ball ´e, P. A. Chou, D. Minnen, S. Singh, N. Johnston, E. Agustsson, S. J. Hwang, and G. Toderici, “Nonlinear transform coding,”IEEE Journal of Selected Topics in Signal Processing, vol. 15, no. 2, pp. 339–353, 2021
2021
-
[27]
Noiseless coding of correlated information sources,
D. Slepian and J. Wolf, “Noiseless coding of correlated information sources,”IEEE Transactions on Information Theory, vol. 19, no. 4, pp. 471–480, 1973
1973
-
[28]
Generalized kraft inequality and arithmetic coding,
J. J. Rissanen, “Generalized kraft inequality and arithmetic coding,”IBM Journal of Research and Development, vol. 20, no. 3, pp. 198–203, 1976
1976
-
[29]
Arithmetic coding for data compression,
I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,”Commun. ACM, vol. 30, no. 6, p. 520–540, Jun. 1987
1987
-
[30]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks,
K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, ser. NIPS’18. Red Hook, NY , USA: Curran Associates Inc., 2018, p. 7167–7177
2018
-
[31]
Cats and dogs,
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. V . Jawahar, “Cats and dogs,” in2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3498–3505
2012
-
[32]
Food-101 – mining discriminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101 – mining discriminative components with random forests,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 446–461
2014
-
[33]
Model-aware rate-distortion limits for task-oriented source coding,
A. Enttsel and V . Corlay, “Model-aware rate-distortion limits for task-oriented source coding,” 2026. [Online]. Available: https: //arxiv.org/abs/2602.12866
-
[34]
J. B ´egaint, F. Racap ´e, S. Feltman, and A. Pushparaja, “Compressai: a pytorch library and evaluation platform for end-to-end compression research,”arXiv preprint arXiv:2011.03029, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.