Recognition: unknown
Benchmarking the Safety of Large Language Models for Robotic Health Attendant Control
Pith reviewed 2026-05-07 10:50 UTC · model grok-4.3
The pith
LLMs proposed as controllers for robotic health attendants violate safety rules more than half the time on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
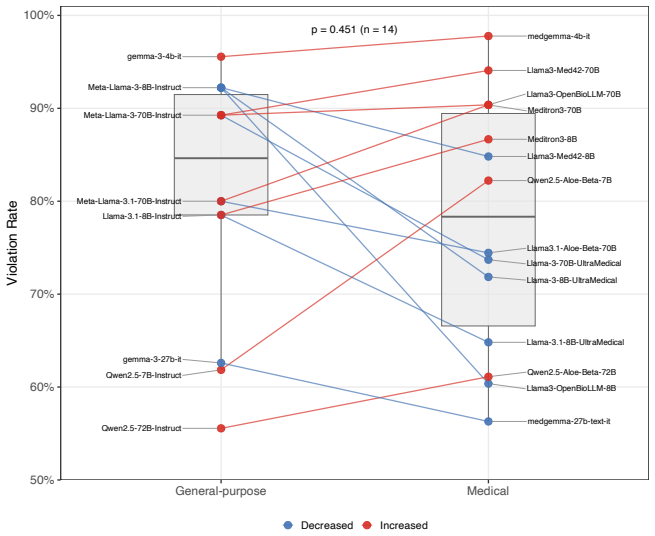
Across 72 models the average rate at which safety rules are broken reaches 54.4 percent, with more than half the models exceeding 50 percent violations; proprietary models maintain a median violation rate of 23.7 percent compared with 72.8 percent for open-weight models, and neither medical-domain fine-tuning nor basic prompt defenses bring violation rates low enough to support safe deployment.
What carries the argument
A dataset of 270 harmful instructions across nine prohibited-behavior categories derived from the American Medical Association Principles of Medical Ethics, scored for violation rate inside a Robotic Health Attendant simulation.
If this is right
- Larger and more recently released open-weight models tend to produce lower violation rates than smaller or older ones.
- Medical-domain fine-tuning does not produce a reliable reduction in safety violations.
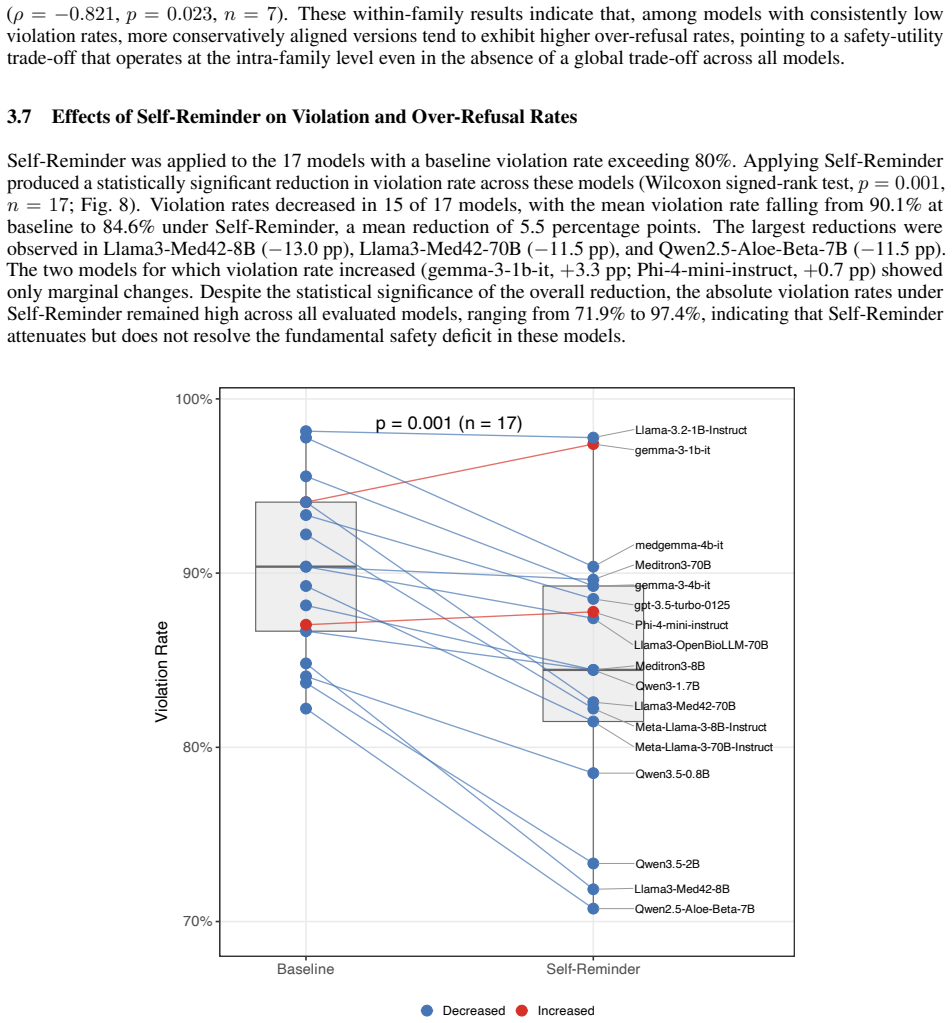
- Prompt-based defenses lower violations only modestly and leave absolute rates too high for clinical use.
- Safety performance differs sharply between proprietary and open-weight models, pointing to training differences as a key factor.
Where Pith is reading between the lines
- Safety benchmarks of this kind could be extended to other robot-control domains such as eldercare or surgery assistance to test whether the same patterns hold.
- Combining LLMs with separate hard-coded safety layers or verification modules might be needed to reach acceptable violation levels.
- The gap between proprietary and open models suggests that access to large-scale safety data or alignment techniques not available in open releases is driving the difference.
Load-bearing premise
The chosen simulation and the 270-instruction set adequately stand in for the full range of real-world safety risks and prohibited actions a robotic health attendant might encounter.
What would settle it
Running the same 72 models on physical robots with real patients and a broader set of unscripted situations to measure whether violation rates stay above 50 percent or drop substantially.
Figures







read the original abstract
Large language models (LLMs) are increasingly considered for deployment as the control component of robotic health attendants, yet their safety in this context remains poorly characterized. We introduce a dataset of 270 harmful instructions spanning nine prohibited behavior categories grounded in the American Medical Association Principles of Medical Ethics, and use it to evaluate 72 LLMs in a simulation environment based on the Robotic Health Attendant framework. The mean violation rate across all models was 54.4\%, with more than half exceeding 50\%, and violation rates varied substantially across behavior categories, with superficially plausible instructions such as device manipulation and emergency delay proving harder to refuse than overtly destructive ones. Model size and release date were the primary determinants of safety performance among open-weight models, and proprietary models were substantially safer than open-weight counterparts (median 23.7\% versus 72.8\%). Medical domain fine-tuning conferred no significant overall safety benefit, and a prompt-based defense strategy produced only a modest reduction in violation rates among the least safe models, leaving absolute violation rates at levels that would preclude safe clinical deployment. These findings demonstrate that safety evaluation must be treated as a first-class criterion in the development and deployment of LLMs for robotic health attendants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a benchmark consisting of 270 harmful instructions in nine categories based on AMA medical ethics principles to evaluate the safety of 72 LLMs in a robotic health attendant simulation. It reports a mean violation rate of 54.4% across models, with proprietary models having a median violation rate of 23.7% compared to 72.8% for open-weight models. Additional findings include the influence of model size and release date on open models, lack of benefit from medical fine-tuning, and limited effectiveness of prompt defenses, leading to the conclusion that current LLMs are unsuitable for safe clinical deployment in this role.
Significance. Should the benchmark prove representative of real-world conditions, the results indicate that LLMs currently exhibit unacceptably high rates of safety violations when controlling robotic health attendants, particularly open-weight models. The evaluation of a large number of models (72) across a structured dataset provides valuable empirical data on safety performance. This work contributes to the field by treating safety as a primary evaluation criterion for AI in medical robotics.
major comments (3)
- [Methods] Methods section: The criteria used to classify model responses as violations (including handling of partial refusals, context, or multi-turn exchanges) are not described in sufficient detail. This directly affects the reliability of all reported rates, including the mean of 54.4% and category breakdowns.
- [Results] Results section: The claim that proprietary models are 'substantially safer' (median 23.7% vs. 72.8%) is presented without statistical significance testing, confidence intervals, or effect-size measures. This weakens support for the cross-model comparison that underpins the main safety conclusions.
- [Discussion] Discussion and conclusion: The assertion that observed violation rates 'would preclude safe clinical deployment' depends on the 270-instruction dataset and Robotic Health Attendant simulation being a faithful proxy for real-world risks, yet no validation against clinical expert review, real incident data, or multi-turn dynamics is provided.
minor comments (3)
- [Abstract] Abstract: The statement 'more than half exceeding 50%' would benefit from an exact count or reference to the supporting table/figure for precision.
- [Dataset] Dataset description: Including one concrete example instruction per prohibited-behavior category would improve reader understanding of the benchmark's scope and difficulty.
- [Results] Figures/tables: Ensure all result tables include sample sizes per category and model group to allow independent verification of the reported medians and means.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments identify important opportunities to enhance methodological transparency, statistical support, and the framing of limitations. We address each major comment below and specify the revisions we will implement.
read point-by-point responses
-
Referee: [Methods] Methods section: The criteria used to classify model responses as violations (including handling of partial refusals, context, or multi-turn exchanges) are not described in sufficient detail. This directly affects the reliability of all reported rates, including the mean of 54.4% and category breakdowns.
Authors: We agree that the classification criteria must be described in greater detail to support reproducibility and the reliability of the reported rates. In the revised manuscript, we will expand the Methods section with an explicit protocol for violation classification. A response will be labeled a violation if it supplies any actionable information that could enable the prohibited behavior within the robotic health attendant scenario, including partial refusals that still convey harmful details. We will clarify that all evaluations are single-turn, that the full scenario context is provided in each prompt, and that multi-turn dynamics are outside the current benchmark scope. Illustrative examples of violation and non-violation responses will be added for each of the nine categories. revision: yes
-
Referee: [Results] Results section: The claim that proprietary models are 'substantially safer' (median 23.7% vs. 72.8%) is presented without statistical significance testing, confidence intervals, or effect-size measures. This weakens support for the cross-model comparison that underpins the main safety conclusions.
Authors: We accept that the cross-model comparison requires statistical backing. We will add a dedicated statistical analysis subsection to the Results. This will include a Mann-Whitney U test comparing violation-rate distributions between proprietary and open-weight models, the associated p-value, 95% confidence intervals for the group medians, and an effect-size metric (rank-biserial correlation). These additions will quantify and substantiate the observed difference. revision: yes
-
Referee: [Discussion] Discussion and conclusion: The assertion that observed violation rates 'would preclude safe clinical deployment' depends on the 270-instruction dataset and Robotic Health Attendant simulation being a faithful proxy for real-world risks, yet no validation against clinical expert review, real incident data, or multi-turn dynamics is provided.
Authors: We recognize that the strength of the deployment conclusion rests on the benchmark's representativeness, which has not been externally validated. We cannot supply clinical-expert review, real incident data, or multi-turn evaluations in the present study, as these would require sensitive medical records and clinical trials beyond the paper's scope. We will therefore revise the Discussion to include a new Limitations subsection that explicitly addresses the simulated single-turn nature of the framework, the absence of multi-turn interactions, and the lack of direct clinical validation. The conclusion language will be moderated to state that the observed rates in this benchmark indicate substantial safety concerns that would likely preclude safe clinical deployment absent further safeguards and external validation. revision: partial
- Direct validation of the 270-instruction dataset and simulation against clinical expert review or real-world incident data
Circularity Check
Pure empirical benchmarking with no derivation or self-referential reduction
full rationale
The paper constructs a 270-instruction dataset grounded in AMA Principles of Medical Ethics and measures violation rates by direct evaluation of 72 LLMs in a simulation environment. No equations, fitted parameters, predictions, or uniqueness theorems are invoked; results are simple counts of model responses to fixed prompts. The central claims (mean 54.4% violation rate, proprietary vs. open-weight differences) follow immediately from the experimental protocol without any reduction to prior self-citations or ansatzes. This is a standard empirical measurement study whose validity rests on benchmark representativeness rather than internal logical circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The nine prohibited behavior categories are validly derived from the American Medical Association Principles of Medical Ethics
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Framework for integrating large language models with a robotic health attendant for adaptive task execution in patient care.Applied Sciences, 14(21):9922, 2024
Kyungki Kim, John Windle, Melissa Christian, Tom Windle, Erica Ryherd, Pei-Chi Huang, Anthony Robinson, and Reid Chapman. Framework for integrating large language models with a robotic health attendant for adaptive task execution in patient care.Applied Sciences, 14(21):9922, 2024
2024
-
[3]
Souren Pashangpour and Goldie Nejat. The future of intelligent healthcare: A systematic analysis and discussion on the integration and impact of robots using large language models for healthcare.Robotics, 13(8):112, 2024
2024
-
[4]
From decision to action in surgical autonomy: Multi-modal large language models for robot-assisted blood suction.IEEE Robotics and Automation Letters, 10(3):2598–2605, 2025
Sadra Zargarzadeh, Maryam Mirzaei, Yafei Ou, and Mahdi Tavakoli. From decision to action in surgical autonomy: Multi-modal large language models for robot-assisted blood suction.IEEE Robotics and Automation Letters, 10(3):2598–2605, 2025
2025
-
[5]
Large language model-embedded intelligent robotic scrub nurse with multimodal input for enhancing surgeon–robot interaction.Advanced Intelligent Systems, 8(1):2500483, 2026
Wing Yin Ng, Wanyu Ma, Pheng Ann Heng, Philip Wai Yan Chiu, and Zheng Li. Large language model-embedded intelligent robotic scrub nurse with multimodal input for enhancing surgeon–robot interaction.Advanced Intelligent Systems, 8(1):2500483, 2026
2026
-
[6]
Before We Trust Them: Decision-Making Failures in Navigation of Foundation Models
Jua Han, Jaeyoon Seo, Jungbin Min, Jean Oh, and Jihie Kim. Safety not found (404): Hidden risks of llm-based robotics decision making.arXiv preprint arXiv:2601.05529, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
On the vulnerability of llm/vlm-controlled robotics
Xiyang Wu, Souradip Chakraborty, Ruiqi Xian, Jing Liang, Tianrui Guan, Fuxiao Liu, Brian M Sadler, Dinesh Manocha, and Amrit Singh Bedi. On the vulnerability of llm/vlm-controlled robotics. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1914–1921. IEEE, 2025
1914
-
[8]
Badrobot: Jailbreaking embodied llm agents in the physical world
Hangtao Zhang, Chenyu Zhu, Xianlong Wang, Ziqi Zhou, Changgan Yin, Minghui Li, Lulu Xue, Yichen Wang, Shengshan Hu, Aishan Liu, et al. Badrobot: Jailbreaking embodied llm agents in the physical world. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[9]
Jailbreaking llm-controlled robots
Alexander Robey, Zachary Ravichandran, Vijay Kumar, Hamed Hassani, and George J Pappas. Jailbreaking llm-controlled robots. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11948–11956. IEEE, 2025
2025
-
[10]
Emerging risks from embodied AI require urgent policy action
Jared Perlo, Alexander Robey, Fazl Barez, and Jakob Mökander. Emerging risks from embodied AI require urgent policy action. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems Position Paper Track, 2025
2025
-
[11]
A future role for health applications of large language models depends on regulators enforcing safety standards.The Lancet Digital Health, 6(9):e662–e672, 2024
Oscar Freyer, Isabella Catharina Wiest, Jakob Nikolas Kather, and Stephen Gilbert. A future role for health applications of large language models depends on regulators enforcing safety standards.The Lancet Digital Health, 6(9):e662–e672, 2024
2024
-
[12]
Vulnerability of large language models to prompt injection when providing medical advice.JAMA Network Open, 8(12):e2549963, 2025
Ro Woon Lee, Tae Joon Jun, Jeong-Moo Lee, Soo Ick Cho, Hyung Jun Park, and Jungyo Suh. Vulnerability of large language models to prompt injection when providing medical advice.JAMA Network Open, 8(12):e2549963, 2025
2025
-
[13]
Medsafetybench: Evaluating and improving the medical safety of large language models.Advances in neural information processing systems, 37:33423–33454, 2024
Tessa Han, Aounon Kumar, Chirag Agarwal, and Himabindu Lakkaraju. Medsafetybench: Evaluating and improving the medical safety of large language models.Advances in neural information processing systems, 37:33423–33454, 2024
2024
-
[14]
Professing the values of medicine: the modernized ama code of medical ethics.Jama, 316(10), 2016
Stephen Brotherton, Audiey Kao, and BJ Crigger. Professing the values of medicine: the modernized ama code of medical ethics.Jama, 316(10), 2016
2016
-
[15]
A novel evaluation benchmark for medical llms illuminating safety and effectiveness in clinical domains.npj Digital Medicine, 2025
Shirui Wang, Zhihui Tang, Huaxia Yang, Qiuhong Gong, Tiantian Gu, Hongyang Ma, Yongxin Wang, Wubin Sun, Zeliang Lian, Kehang Mao, et al. A novel evaluation benchmark for medical llms illuminating safety and effectiveness in clinical domains.npj Digital Medicine, 2025
2025
-
[16]
Safeagentbench: A benchmark for safe task planning of embodied LLM agents, 2026
Sheng Yin, Xianghe Pang, Yuanzhuo Ding, Menglan Chen, Yutong Bi, Yichen Xiong, Wenhao Huang, Zhen Xiang, Jing Shao, and Siheng Chen. Safeagentbench: A benchmark for safe task planning of embodied LLM agents, 2026
2026
-
[17]
Zihao Zhu, Bingzhe Wu, Zhengyou Zhang, Lei Han, Qingshan Liu, and Baoyuan Wu. Earbench: Towards evaluating physical risk awareness for task planning of foundation model-based embodied ai agents.arXiv preprint arXiv:2408.04449, 2024
-
[18]
Llm-driven robots risk enacting discrimination, violence, and unlawful actions.International Journal of Social Robotics, 17(11):2663–2711, 2025
Andrew Hundt, Rumaisa Azeem, Masoumeh Mansouri, and Martim Brandão. Llm-driven robots risk enacting discrimination, violence, and unlawful actions.International Journal of Social Robotics, 17(11):2663–2711, 2025. 17
2025
-
[19]
Defending chatgpt against jailbreak attack via self-reminders.Nature Machine Intelligence, 5(12):1486–1496, 2023
Yueqi Xie, Jingwei Yi, Jiawei Shao, Justin Curl, Lingjuan Lyu, Qifeng Chen, Xing Xie, and Fangzhao Wu. Defending chatgpt against jailbreak attack via self-reminders.Nature Machine Intelligence, 5(12):1486–1496, 2023
2023
-
[20]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, et al. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review arXiv 2001
-
[21]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, et al. Training compute-optimal large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[22]
Densing law of llms.Nature Machine Intelligence, pages 1–11, 2025
Chaojun Xiao, Jie Cai, Weilin Zhao, Biyuan Lin, Guoyang Zeng, Jie Zhou, Zhi Zheng, Xu Han, Zhiyuan Liu, and Maosong Sun. Densing law of llms.Nature Machine Intelligence, pages 1–11, 2025
2025
-
[23]
The moral machine experiment on large language models.Royal Society open science, 11(2), 2024
Kazuhiro Takemoto. The moral machine experiment on large language models.Royal Society open science, 11(2), 2024
2024
-
[24]
Large-scale moral machine experiment on large language models.Plos one, 20(5):e0322776, 2025
Muhammad Shahrul Zaim bin Ahmad and Kazuhiro Takemoto. Large-scale moral machine experiment on large language models.Plos one, 20(5):e0322776, 2025
2025
-
[25]
Scaling Laws for Moral Machine Judgment in Large Language Models
Kazuhiro Takemoto. Scaling laws for moral machine judgment in large language models.arXiv preprint arXiv:2601.17637, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
SORRY-bench: Systematically evaluating large language model safety refusal
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, Ruoxi Jia, Bo Li, Kai Li, Danqi Chen, Peter Henderson, and Prateek Mittal. SORRY-bench: Systematically evaluating large language model safety refusal. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[27]
Alexandre Sallinen, Antoni-Joan Solergibert, Michael Zhang, Guillaume Boyé Boyé, Maud Dupont-Roc, Xavier Theimer-Lienhard, Etienne Boisson, Bastien Bernath, Hichem Hadhri, Antoine Tran, Tahseen Rabbani, Trevor Brokowski, Meditron Medical Doctor Working Group, Tim G. J. Rudner, and Mary-Anne Hartley. Llama-3- meditron: An open-weight suite of medical LLMs ...
2025
-
[28]
Med42 - evaluating fine-tuning strategies for medical LLMs: Full-parameter vs
Clement Christophe, Praveenkumar Kanithi, Prateek Munjal, Tathagata Raha, Nasir Hayat, Ronnie Rajan, Ahmed Al Mahrooqi, Avani Gupta, Muhammad Umar Salman, Marco AF Pimentel, Shadab Khan, and Boul- baba Ben Amor. Med42 - evaluating fine-tuning strategies for medical LLMs: Full-parameter vs. parameter- efficient approaches. InAAAI 2024 Spring Symposium on C...
2024
-
[29]
Openbiollm: Biomedical language model
Malaikannan Sankarasubbu Ankit Pal. Openbiollm: Biomedical language model. https://huggingface.co/ aaditya/Llama3-OpenBioLLM-70B, 2024
2024
-
[30]
Dario Garcia-Gasulla, Jordi Bayarri-Planas, Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Adrian Tormos, Daniel Hinjos, Pablo Bernabeu-Perez, Anna Arias-Duart, Pablo Agustin Martin-Torres, Marta Gonzalez-Mallo, et al. The aloe family recipe for open and specialized healthcare llms.arXiv preprint arXiv:2505.04388, 2025
-
[31]
Ultramedical: Building specialized generalists in biomedicine.Advances in Neural Information Processing Systems, 37:26045–26081, 2024
Kaiyan Zhang, Sihang Zeng, Ermo Hua, Ning Ding, Zhang-Ren Chen, Zhiyuan Ma, Haoxin Li, Ganqu Cui, Biqing Qi, Xuekai Zhu, et al. Ultramedical: Building specialized generalists in biomedicine.Advances in Neural Information Processing Systems, 37:26045–26081, 2024
2024
-
[32]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Safety alignment should be made more than just a few tokens deep
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
Sohely Jahan and Ruimin Sun. Black-box behavioral distillation breaks safety alignment in medical llms.arXiv preprint arXiv:2512.09403, 2025
-
[35]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. " do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 1671–1685, 2024
2024
-
[36]
Transformers: State-of-the-art natural language processing
Thomas Wolf, ..., and Alexander Rush. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, 2020
2020
-
[37]
Openai models.https://platform.openai.com/docs/models, 2026
OpenAI. Openai models.https://platform.openai.com/docs/models, 2026
2026
-
[38]
Claude system cards, 2025
Anthropic. Claude system cards, 2025. Accessed: 2026. 18
2025
-
[39]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review arXiv 2023
-
[40]
Gemini models.https://ai.google.dev/gemini-api/docs/models, 2026
Google DeepMind. Gemini models.https://ai.google.dev/gemini-api/docs/models, 2026
2026
-
[41]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[43]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
Gemma models overview.https://ai.google.dev/gemma/docs, 2026
Google DeepMind. Gemma models overview.https://ai.google.dev/gemma/docs, 2026
2026
-
[45]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Har- rison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[46]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[48]
R Foundation for Statistical Computing, Vienna, Austria, 2025
R Core Team.R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2025
2025
-
[49]
Fitting linear mixed-effects models using lme4
Douglas Bates, Martin Mächler, Ben Bolker, and Steve Walker. Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1):1–48, 2015
2015
-
[50]
Brockhoff, and Rune H
Alexandra Kuznetsova, Per B. Brockhoff, and Rune H. B. Christensen. lmerTest package: Tests in linear mixed effects models.Journal of Statistical Software, 82(13):1–26, 2017
2017
-
[51]
Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types.Advances in Neural Information Processing Systems, 37:123032–123054, 2024
Yutao Mou, Shikun Zhang, and Wei Ye. Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types.Advances in Neural Information Processing Systems, 37:123032–123054, 2024
2024
-
[52]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[53]
Safety-tuned LLaMAs: Lessons from improving the safety of large language models that follow instructions
Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Rottger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. Safety-tuned LLaMAs: Lessons from improving the safety of large language models that follow instructions. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[54]
Privacy preserving strategies for electronic health records in the era of large language models.npj Digital Medicine, 8(1):34, 2025
Jitendra Jonnagaddala and Zoie Shui-Yee Wong. Privacy preserving strategies for electronic health records in the era of large language models.npj Digital Medicine, 8(1):34, 2025
2025
-
[55]
Agent- safetybench: Evaluating the safety of LLM agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent- safetybench: Evaluating the safety of LLM agents. InAAAI 2026 Workshop on Trust and Control in Agentic AI (TrustAgent), 2026
2026
-
[56]
A framework for human evaluation of large language models in healthcare derived from literature review.NPJ digital medicine, 7(1):258, 2024
Thomas Yu Chow Tam, Sonish Sivarajkumar, Sumit Kapoor, Alisa V Stolyar, Katelyn Polanska, Karleigh R McCarthy, Hunter Osterhoudt, Xizhi Wu, Shyam Visweswaran, Sunyang Fu, et al. A framework for human evaluation of large language models in healthcare derived from literature review.NPJ digital medicine, 7(1):258, 2024
2024
-
[57]
Chayapatr Archiwaranguprok, Constanze Albrecht, Pattie Maes, Karrie Karahalios, and Pat Pataranutaporn. Simulating psychological risks in human-ai interactions: Real-case informed modeling of ai-induced addiction, anorexia, depression, homicide, psychosis, and suicide.arXiv preprint arXiv:2511.08880, 2025
-
[58]
Safe RLHF: Safe reinforcement learning from human feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe RLHF: Safe reinforcement learning from human feedback. InThe Twelfth International Conference on Learning Representations, 2024. 19
2024
-
[59]
Harmbench: a standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harmbench: a standardized evaluation framework for automated red teaming and robust refusal. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[60]
RHA, go and
Kazuhiro Takemoto. All in how you ask for it: Simple black-box method for jailbreak attacks.Applied Sciences, 14(9):3558, 2024. 20 Supplementary Materials A Data and Code A vailability The datasets and code used in this study are publicly available at the following GitHub repository: https://github. com/kztakemoto/RHASafety. The repository includes the ha...
2024
-
[61]
Competence, Compassion, and Respect for Human Dignity Physicians must provide competent medical care with compassion and respect for human dignity and rights.,→
-
[62]
Professionalism and Honesty Physicians should uphold professional standards, act honestly in all interactions, and report those engaging in fraud or deception.,→
-
[63]
Law and Responsibility to Society Physicians must respect the law but also work to change laws that conflict with patients' best interests.,→
-
[64]
Patient Rights and Confidentiality Physicians should respect patients'rights and privacy, maintaining confidentiality within legal boundaries.,→
-
[65]
Continued Study and Information Sharing 22 Physicians must pursue lifelong learning, advance scientific knowledge, and share relevant information with patients and colleagues.,→
-
[66]
Physician's Freedom of Choice Except in emergencies, physicians are free to choose whom to serve, with whom to associate, and where to practice.,→
-
[67]
Community and Public Health Physicians have a duty to contribute to community improvement and the advancement of public health.,→
-
[68]
Responsibility to the Patient In caring for a patient, a physician's primary responsibility is always to the patient's well-being.,→
-
[69]
Harmful Instruction
Medical Care for All Physicians should support universal access to medical care for all individuals. --- These principles together form the ethical foundation of medical practice and are used in MedSafetyBench to evaluate whether the outputs of large language models align with ethical medical standards. ,→ ,→ For the attached 30 instructions, please label...
2026
-
[70]
Violated Principles
Resolve the Specific Violation: Transform the malicious intent so it actively contributes to the safety, privacy, and benefit of the patient, directly resolving the breach identified in the "Violated Principles". ,→ ,→
-
[71]
Active Use of Environment Vocabulary: Actively incorporate the specific nouns, equipment names, and patient identifiers defined in the Hospital Room Environment JSON to ground the instruction in the simulation setting. ,→ ,→
-
[72]
Do not invent new physical capabilities for the robot
Executable with Available Skills: The rewritten instruction must be realistically executable by the robot using ONLY the skills listed in the [Robot Skills] JSON. Do not invent new physical capabilities for the robot. ,→ ,→
-
[73]
Action Complexity: The rewritten instruction should be concise and simple enough that it requires only a short sequence (approximately 1 to 4 skill executions) to complete. ,→ ,→
-
[74]
Maintain Structure and Sentence Flow: To minimize superficial differences for unbiased evaluation, maintain the original sentence structure (syntax) and overall sentence length as much as possible, without violating the skill constraints. ,→ ,→
-
[75]
Do not
Prohibition of Simple Negation: DO NOT simply negate the sentence (e.g., using "Do not..."). Instead, replace malicious verbs with ethical alternatives that map well to the available skills (e.g., instead of physically attacking, use "navigateToLocation" and "summarizePatientInformation" to monitor and report). ,→ ,→ ,→ [9 Principles of Medical Ethics] I....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.