Recognition: unknown
State Beyond Appearance: Diagnosing and Improving State Consistency in Dial-Based Measurement Reading
Pith reviewed 2026-05-07 11:41 UTC · model grok-4.3
The pith
Multimodal models read dials inconsistently because they track visual appearance instead of the underlying state value.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing MLLMs not only achieve unsatisfactory accuracy on dial-based readout but suffer sharp performance drops under viewpoint and illumination changes even when the underlying dial state remains fixed. Probing reveals that same-state samples under appearance variation are not consistently clustered and neighboring states fail to preserve local structure implied by continuous dial values. The paper therefore proposes TriSCA, which applies state-distance-aware representation alignment, metadata-grounded observation-to-state supervision, and state-aware objective alignment, and demonstrates gains on controlled clock and gauge benchmarks plus an external real-world benchmark.
What carries the argument
TriSCA, the tri-level state-consistent alignment framework that enforces representation organization by intrinsic dial state rather than by visual appearance.
If this is right
- Accuracy on dial readout remains stable when viewpoint or illumination changes while the physical state is unchanged.
- Internal representations group samples by true measurement value rather than by superficial visual features.
- Each of the three alignment components contributes measurably to the observed gains according to ablation results.
- The method transfers to an external real-world dial benchmark beyond the controlled training data.
Where Pith is reading between the lines
- Similar consistency constraints could be applied to other continuous estimation problems such as reading thermometers or analog meters.
- The diagnosis points to a general shortcut bias in MLLMs that may affect any task where geometry or invariants matter more than appearance.
- One could test whether the same tri-level alignment improves robustness in video sequences where dial states evolve over time.
Load-bearing premise
That controlled clock and gauge benchmarks together with feature-space probing accurately reflect how the models will behave on uncontrolled real-world dial images.
What would settle it
Collect a new test set of dial images that vary in background, angle, and lighting while keeping the true reading fixed; if models trained with TriSCA still show accuracy drops and poor state clustering comparable to baseline models, the claim of improved state consistency would be refuted.
Figures


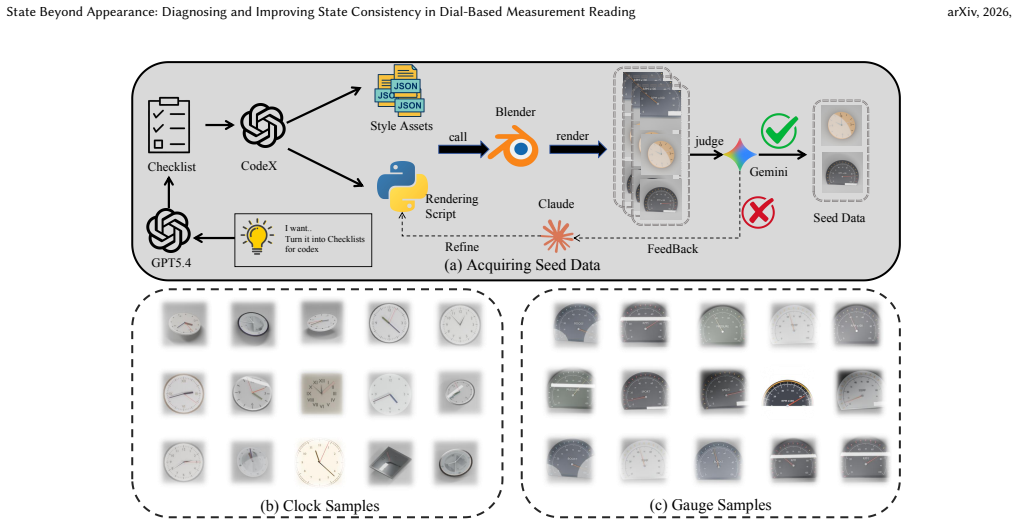



read the original abstract
Multimodal large language models (MLLMs) have achieved impressive progress on general multimodal tasks, yet they remain brittle on dial-based measurement reading. In this paper, we study this problem through controlled benchmarks and feature-space probing, and show that current MLLMs not only achieve unsatisfactory accuracy on dial-based readout, but also suffer sharp performance drops under viewpoint and illumination changes even when the underlying dial state remains fixed. Our probing analysis further reveals that same-state samples under appearance variation are not consistently clustered, while neighboring states fail to preserve the local structure implied by continuous dial values. These findings suggest that existing MLLMs largely ignore the intrinsic state geometry of dial measurement tasks and instead rely on superficial appearance cues. Motivated by this diagnosis, we propose TriSCA, a tri-level state-consistent alignment framework for dial-based measurement reading. Specifically, TriSCA consists of state-distance-aware representation alignment, metadata-grounded observation-to-state supervision, and state-aware objective alignment. Extensive ablation studies and evaluation experiments on controlled clock and gauge benchmarks, together with evaluation on an external real-world benchmark, demonstrate the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current multimodal large language models (MLLMs) are brittle on dial-based measurement reading because they ignore intrinsic state geometry and rely on superficial appearance cues. This is diagnosed via controlled clock/gauge benchmarks showing accuracy drops under viewpoint/illumination shifts with fixed states, plus feature-space probing revealing inconsistent clustering of same-state samples and broken local continuity for neighboring states. Motivated by the diagnosis, the authors introduce TriSCA, a tri-level state-consistent alignment framework with state-distance-aware representation alignment, metadata-grounded observation-to-state supervision, and state-aware objective alignment. Ablations and evaluations on the controlled benchmarks plus an external real-world benchmark are presented to demonstrate effectiveness.
Significance. If the central diagnosis and gains hold, the work would be significant for improving MLLM robustness on geometry-sensitive measurement tasks common in industrial, medical, and scientific applications. The combination of controlled benchmarks, feature probing for diagnosis, and a concrete tri-level alignment method with ablations and external validation is a strength; it provides both insight into failure modes and a practical mitigation strategy. The approach could influence future work on state-aware multimodal representations beyond dials.
major comments (2)
- [Probing analysis section] Probing analysis (feature-space clustering results): the claim that models ignore state geometry rather than encoding it in an appearance-entangled subspace rests on the assumption that the probed features (unspecified layer/pooling in the vision encoder) isolate internal state representations. Without layer-wise ablations or controls that vary only dial angle while holding low-level appearance statistics fixed, the evidence cannot distinguish the two, directly affecting the motivation for TriSCA's three alignment terms.
- [Experiments and benchmarks section] Controlled benchmarks and evaluation: the reported accuracy drops under viewpoint/illumination changes and the post-TriSCA gains are load-bearing for the central claim, yet the manuscript does not detail data splits, exact generation of appearance variations, or whether the same-state samples were generated with matched low-level statistics. This leaves open the possibility that benchmark design influences the diagnosis and claimed improvements.
minor comments (2)
- [Method section] The three components of TriSCA are described at a high level in the abstract and method; explicit equations or pseudocode for the loss terms (especially state-distance-aware alignment and state-aware objective) would improve reproducibility.
- [Figures] Figure captions for probing visualizations should specify the dimensionality reduction technique, distance metric, and which encoder layer is used.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of experimental rigor and probing analysis that we have addressed through revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Probing analysis section] Probing analysis (feature-space clustering results): the claim that models ignore state geometry rather than encoding it in an appearance-entangled subspace rests on the assumption that the probed features (unspecified layer/pooling in the vision encoder) isolate internal state representations. Without layer-wise ablations or controls that vary only dial angle while holding low-level appearance statistics fixed, the evidence cannot distinguish the two, directly affecting the motivation for TriSCA's three alignment terms.
Authors: We acknowledge that the original manuscript did not explicitly specify the probed layer and pooling operation. In the revised version, we have added: (i) explicit details that features are taken from the final layer of the vision encoder with global average pooling; (ii) new layer-wise probing ablations across intermediate and final layers, confirming that inconsistent clustering of same-state samples and broken local continuity persist regardless of layer; (iii) expanded description of the benchmark synthesis process (fixed dial angle/state with independent randomization of viewpoint, illumination, and low-level appearance statistics such as texture and lighting). These controls ensure appearance variations are decoupled from state, supporting that the observed inconsistencies reflect a lack of robust state geometry encoding rather than mere entanglement in a subspace. This bolsters the motivation for TriSCA. revision: yes
-
Referee: [Experiments and benchmarks section] Controlled benchmarks and evaluation: the reported accuracy drops under viewpoint/illumination changes and the post-TriSCA gains are load-bearing for the central claim, yet the manuscript does not detail data splits, exact generation of appearance variations, or whether the same-state samples were generated with matched low-level statistics. This leaves open the possibility that benchmark design influences the diagnosis and claimed improvements.
Authors: We agree that the original manuscript lacked sufficient detail on benchmark construction, which could raise questions about potential confounds. The revised manuscript now includes a dedicated subsection with: (i) full specification of the synthetic data generation pipeline (parameterized camera poses, lighting models, and texture randomization in Blender while holding dial state fixed); (ii) exact train/validation/test splits (70/15/15, ensuring no state or appearance leakage); (iii) explicit confirmation and examples that same-state samples are generated with deliberately unmatched low-level statistics (varied backgrounds, shadows, and color distributions). We have also made the benchmark generation code publicly available. These additions demonstrate that the accuracy drops and TriSCA gains arise from state inconsistency under appearance shifts, not from benchmark artifacts. revision: yes
Circularity Check
No circularity: diagnosis and method are independent of each other
full rationale
The paper's chain proceeds from controlled benchmarks and feature-space probing (accuracy drops under appearance shifts; clustering failures for same-state samples) to a diagnosis that models ignore state geometry, then to proposing TriSCA's three alignment terms. No equations, fitted parameters, or self-citations are shown that reduce the claimed improvement or the diagnosis to a quantity defined by the same inputs. The probing observations and the subsequent alignment framework remain distinct; the former supplies empirical motivation while the latter supplies an independent architectural response. This satisfies the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review arXiv 2025
-
[2]
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. 2023. Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv:2306.15195 [cs.CV] https://arxiv.org/abs/2306.15195 State Beyond Appearance: Diagnosing and Improving State Consistency in Dial-Based Measurement Reading arXiv, 2026, Table 4: Continuous-state evaluation on...
work page internal anchor Pith review arXiv 2023
-
[3]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. 2023. ShareGPT4V: Improving Large Multi-Modal Models with Better Captions. arXiv:2311.12793 [cs.CV] https://arxiv.org/abs/2311.12793
work page internal anchor Pith review arXiv 2023
- [4]
- [5]
-
[6]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. https://lmsys.org/blog/2023-03-30-vicuna/
2023
- [7]
- [8]
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al
-
[11]
InProceedings of the Computer Vision and Pattern Recognition Conference
Molmo and pixmo: Open weights and open data for state-of-the-art vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference. 91–104
-
[12]
Tairan Fu, Miguel González, Javier Conde, Elena Merino-Gómez, and Pedro Reviriego. 2025. Have Multimodal Large Language Models (MLLMs) Really Learned to Tell the Time on Analog Clocks?IEEE Internet Computing(2025)
2025
-
[13]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. 2024. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision. Springer, 148–166
2024
- [14]
-
[15]
Hulingxiao He, Zijun Geng, and Yuxin Peng. [n. d.]. Fine-R1: Make Multi-modal LLMs Excel in Fine-Grained Visual Recognition by Chain-of-Thought Reasoning. InThe Fourteenth International Conference on Learning Representations
- [16]
- [17]
-
[18]
Aditya Sanjiv Kanade and Tanuja Ganu. 2026. Do you see me: A multidimensional benchmark for evaluating visual perception in multimodal llms. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 7285–7326
2026
-
[19]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. Supervised contrastive learning.Advances in neural information processing systems33 (2020), 18661– 18673
2020
- [20]
- [21]
-
[22]
Juan Leon-Alcazar, Yazeed Alnumay, Cheng Zheng, Hassane Trigui, Sahejad Patel, and Bernard Ghanem. 2024. Learning to read analog gauges from synthetic data. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 8616–8625
2024
- [23]
- [24]
-
[25]
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang
-
[26]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruc- tion Tuning. arXiv:2306.14565 [cs.CV] https://arxiv.org/abs/2306.14565
work page internal anchor Pith review arXiv
-
[27]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. 2024. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences67, 12 (2024), 220102
2024
-
[28]
Maurits Reitsma, Julian Keller, Kenneth Blomqvist, and Roland Siegwart. 2024. Under pressure: learning-based analog gauge reading in the wild. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 14–20
2024
-
[29]
Gabriel Salomon, Rayson Laroca, and David Menotti. 2020. Deep learning for image-based automatic dial meter reading: Dataset and baselines. In2020 Inter- national joint conference on neural networks (IJCNN). IEEE, 1–8
2020
-
[30]
Gabriel Salomon, Rayson Laroca, and David Menotti. 2022. Image-based auto- matic dial meter reading in unconstrained scenarios.Measurement204 (2022), 112025
2022
- [31]
-
[32]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition. 815–823
2015
-
[33]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[34]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review arXiv 2017
-
[35]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv, 2026, Hu et al. arXiv:2402.03300(2024)
work page internal anchor Pith review arXiv 2024
-
[36]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8317–8326
2019
- [37]
-
[38]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review arXiv 2024
-
[39]
Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. 2023. CogVLM: Visual Expert for Pretrained Language Models. arXiv:2311.03079 [cs.CV] https://arxiv.org/abs/2311.03079
- [40]
-
[41]
Charig Yang, Weidi Xie, and Andrew Zisserman. 2022. It’s about time: Analog clock reading in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2508–2517
2022
- [42]
-
[43]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9556–9567
2024
-
[44]
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. 2025. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wa...
2025
-
[45]
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023. Multimodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923(2023)
work page internal anchor Pith review arXiv 2023
-
[46]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv:2304.10592 [cs.CV] https://arxiv.org/abs/2304.10592
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.