Recognition: unknown
Towards Topology-Aware Very Large-Scale Photonic AI Accelerators
Pith reviewed 2026-05-10 09:16 UTC · model grok-4.3
The pith
Grid topology, not hardware size, limits performance in large photonic AI accelerators, with symmetric layouts offering up to 6 times better utilization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
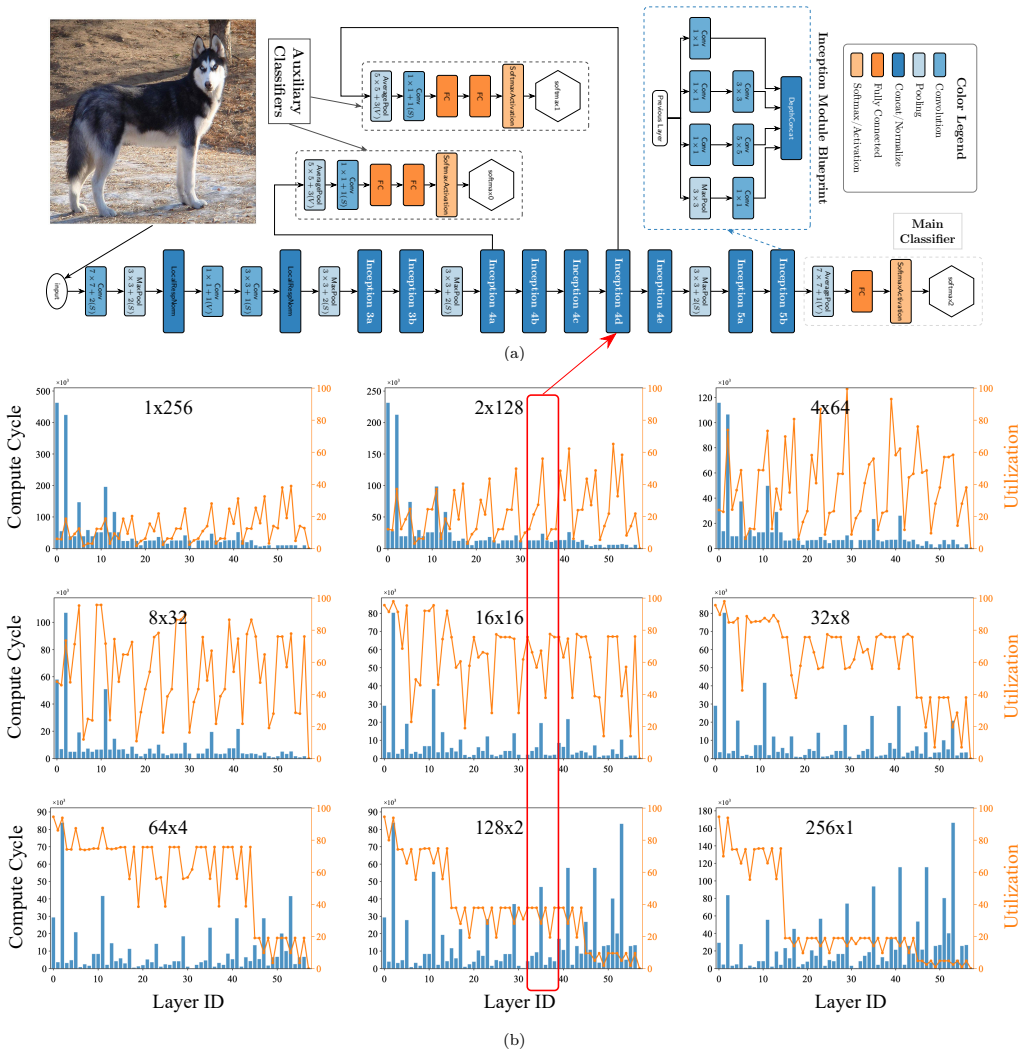
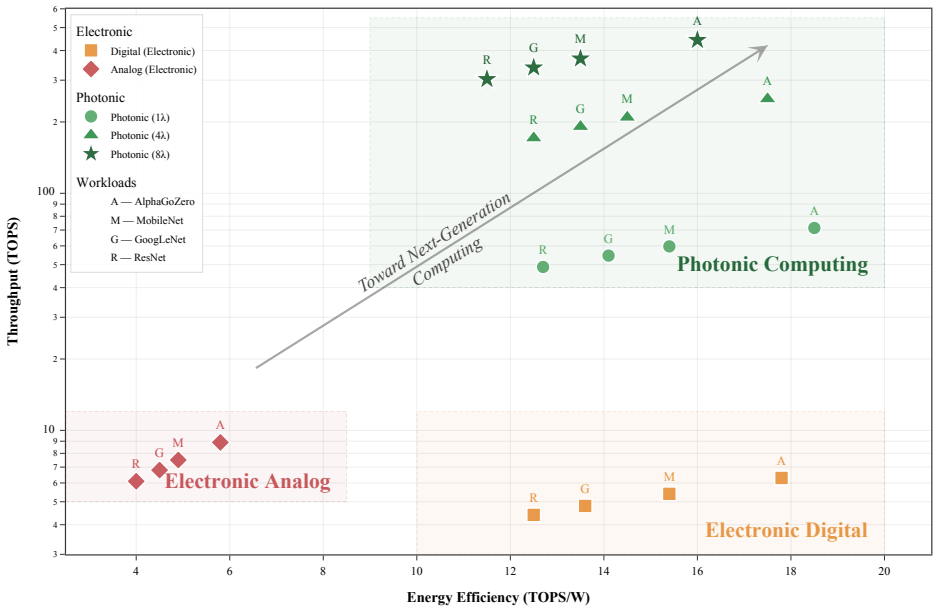
The paper establishes that in photonic AI accelerators, a topology-dominated scaling bottleneck called the Utilization Wall emerges, where performance is governed by grid topology rather than hardware size. Through evaluation on GoogleNet, ResNet-18, MobileNet, and AlphaGo Zero with up to 1024 processing elements, it demonstrates the Symmetric Grid Rule: symmetric topologies improve utilization by up to 6X while reducing memory access by over 40% compared to linear configurations.
What carries the argument
The Utilization Wall, a scaling bottleneck in photonic accelerators where grid topology governs performance instead of the number of processing elements, together with the Symmetric Grid Rule that favors balanced layouts for better hardware use.
If this is right
- Symmetric grid topologies achieve up to 6 times higher utilization in photonic DNN accelerators.
- Memory access requirements drop by more than 40 percent in symmetric versus linear grids.
- Topology-aware scaling becomes essential for energy-efficient large-scale photonic AI hardware.
- Modular 4x4 photonic tensor core units enable scalable architectures up to 1024 elements while respecting insertion loss and power limits.
Where Pith is reading between the lines
- Designers of future photonic chips should prioritize square or balanced grid arrangements over linear arrays to avoid wasting hardware capacity.
- This finding may extend to other parallel computing domains where signal fanout and loss create similar bottlenecks.
- Testing with additional workloads beyond the four studied networks could reveal whether the Utilization Wall appears in more general AI tasks.
Load-bearing premise
The analysis assumes insertion loss, fanout penalties, and laser power limits are the main constraints and that workloads like GoogleNet and ResNet-18 at 1024-PE scale represent practical deployments.
What would settle it
Fabricate or simulate a 1024-PE photonic accelerator in both linear and symmetric grid configurations, run ResNet-18 inference, and check whether the symmetric version shows approximately 6 times higher utilization and 40 percent less memory access.
Figures




read the original abstract
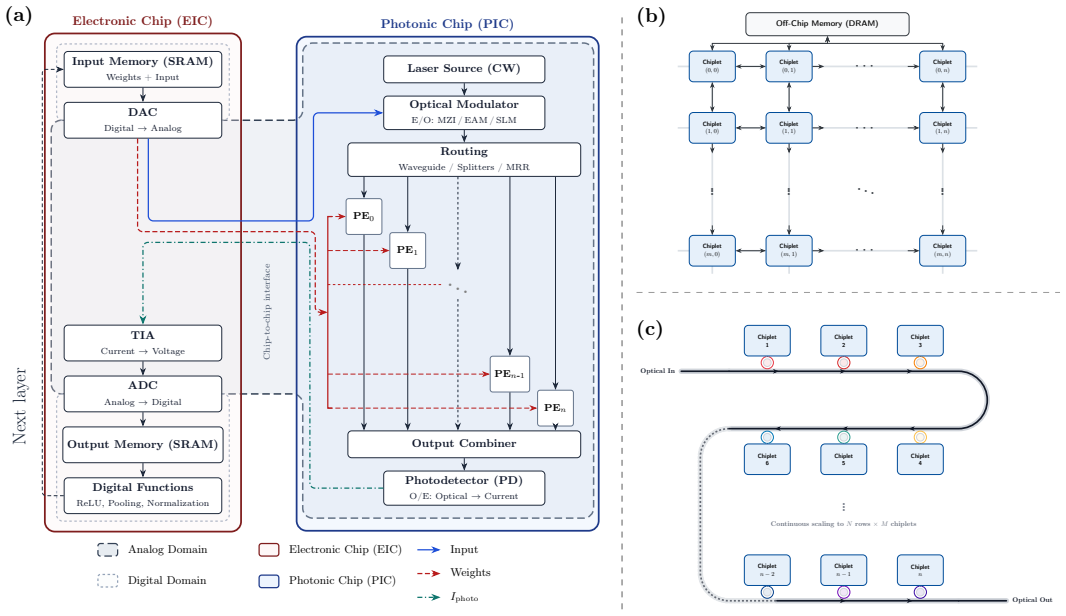
The rapid growth of deep neural networks (DNNs) has exposed fundamental limitations in electronic accelerators, where data movement dominates energy consumption, commonly referred to as the memory wall. Photonic accelerators offer a compelling alternative due to their inherent parallelism and high-speed matrix operations. However, existing research largely focuses on device-level innovations, leaving system-level scalability insufficiently explored. In this paper, we present a scalable photonic accelerator architecture based on a modular scale-out paradigm using 4 X 4 photonic tensor core units. We perform a systematic architectural analysis that incorporates the practical scaling limits of photonic hardware, including insertion loss, fanout penalties, and laser power limits, which restrict monolithic photonic scaling. Through evaluation on representative DNN workloads (GoogleNet, ResNet-18, MobileNet, and AlphaGo Zero) with up to 1024 processing elements, we identify a topology-dominated scaling bottleneck in the photonic domain, termed the Utilization Wall, where performance is governed by grid topology rather than hardware size. We further establish the Symmetric Grid Rule, demonstrating that symmetric topologies improve utilization by up to 6X while reducing memory access by over 40% compared to linear configurations, which reveal that topology-aware scaling is essential for achieving energy-efficient and high-performance photonic AI accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a scalable photonic accelerator architecture based on modular 4x4 photonic tensor core units. It conducts architectural analysis incorporating photonic hardware limits such as insertion loss, fanout penalties, and laser power. Through evaluations on DNN workloads including GoogleNet, ResNet-18, MobileNet, and AlphaGo Zero at scales up to 1024 processing elements, it identifies a topology-dominated scaling bottleneck called the Utilization Wall and establishes the Symmetric Grid Rule, which shows symmetric topologies can improve utilization by up to 6X and reduce memory access by over 40% compared to linear configurations.
Significance. If the simulation results hold, this work highlights the importance of topology in photonic AI accelerator scaling, showing that grid symmetry can substantially outperform size increases alone. The use of cycle-accurate simulations with explicit incorporation of insertion-loss, fanout, and laser-power models, along with clearly defined workloads and the 1024-PE scale, provides concrete, falsifiable metrics that strengthen the central claims and offer practical guidance for energy-efficient photonic designs.
minor comments (3)
- Abstract: the quantitative claims (6X utilization, 40% memory reduction) would be strengthened by an explicit cross-reference to the table or figure that reports these exact metrics for the symmetric vs. linear cases.
- Evaluation section: clarify the precise layer-to-core mapping strategy for the listed DNNs and how the different grid topologies (symmetric vs. linear) are instantiated at the 1024-PE scale.
- Methods: include a brief sensitivity discussion or error bars around the reported utilization numbers with respect to the 4x4 tensor-core size assumption, even if the central trend remains unchanged.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our work on topology-aware photonic AI accelerators. The recommendation for minor revision is noted, and we appreciate the recognition of our cycle-accurate simulations, workload evaluations, and the identification of the Utilization Wall and Symmetric Grid Rule.
Circularity Check
No significant circularity detected
full rationale
The paper derives its Utilization Wall and Symmetric Grid Rule from explicit cycle-accurate simulations of a modular 4x4 photonic tensor-core architecture. Workloads (GoogleNet, ResNet-18, MobileNet, AlphaGo Zero), scale (up to 1024 PEs), and constraints (insertion loss, fanout, laser power) are stated upfront as inputs. Reported utilization gains (up to 6X) and memory-access reductions (>40%) are direct outputs of those simulations under symmetric vs. linear topologies; they do not reduce to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. No equations or uniqueness theorems are invoked that collapse back to the paper's own definitions or prior author work. The derivation chain is therefore self-contained against the stated modeling assumptions.
Axiom & Free-Parameter Ledger
free parameters (1)
- 4x4 photonic tensor core size
axioms (1)
- domain assumption Photonic hardware scaling is restricted by insertion loss, fanout penalties, and laser power limits, preventing monolithic designs.
Reference graph
Works this paper leans on
-
[1]
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al., In-datacenter performance analysis of a tensor processing unit, ACM SIGARCH Computer Architecture News 45 (2) (2017) 1–12
2017
-
[2]
Jouppi, C
N. Jouppi, C. Young, N. Patil, D. Patterson, Motivation for and evaluation of the first tensor processing unit, ieee Micro 38 (3) (2018) 10–19
2018
-
[3]
Gholami, Z
A. Gholami, Z. Yao, S. Kim, C. Hooper, M. W. Mahoney, K. Keutzer, Ai and memory wall, IEEE Micro 44 (3) (2024) 33–39
2024
-
[4]
S. Ning, H. Zhu, C. Feng, J. Gu, D. Z. Pan, R. T. Chen, Hardware-efficient photonic tensor core: 13 accelerating deep neural networks with structured compression, Optica 12 (7) (2025) 1079–1089
2025
-
[5]
H. Zhou, J. Dong, J. Cheng, W. Dong, C. Huang, Y. Shen, Q. Zhang, M. Gu, C. Qian, H. Chen, et al., Photonic matrix multiplication lights up photonic accelerator and beyond, Light: Science & Applications 11 (1) (2022) 30
2022
-
[6]
S. Hua, E. Divita, S. Yu, B. Peng, C. Roques-Carmes, Z. Su, Z. Chen, Y. Bai, J. Zou, Y. Zhu, et al., An integrated large-scale photonic accelerator with ultralow latency, Nature 640 (8058) (2025) 361–367
2025
-
[7]
S. R. Ahmed, R. Baghdadi, M. Bernadskiy, N. Bowman, R. Braid, J. Carr, C. Chen, P. Ciccarella, M. Cole, J. Cooke, et al., Universal photonic artificial intelligence acceleration, Nature 640 (8058) (2025) 368–374
2025
-
[8]
A. N. Tait, M. A. Nahmias, B. J. Shastri, P. R. Prucnal, Broadcast and weight: an integrated network for scalable photonic spike processing, Journal of Lightwave Technology 32 (21) (2014) 3427–3439
2014
-
[9]
Al-Qadasi, L
M. Al-Qadasi, L. Chrostowski, B. Shastri, S. Shekhar, Scaling up silicon photonic-based accelerators: Challenges and opportunities, APL Photonics 7 (2) (2022)
2022
-
[10]
Jahannia, J
B. Jahannia, J. Ye, S. Altaleb, N. Peserico, N. Asadizanjani, E. Heidari, V. J. Sorger, H. Dalir, Low-latencyfullprecisionopticalconvolutionalneural network accelerator, in: AI and Optical Data Sciences V, Vol. 12903, SPIE, 2024, pp. 27–41
2024
-
[11]
Z. Yin, N. Gangi, M. Zhang, J. Zhang, R. Huang, J. Gu, Scatter: algorithm-circuit co-sparse photonic accelerator with thermal-tolerant, power-efficient in-situ light redistribution, in: Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024, pp. 1–9
2024
-
[12]
Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE signal processing magazine 29 (6) (2012) 141–142
L. Deng, The mnist database of handwritten digit images for machine learning research [best of the web], IEEE signal processing magazine 29 (6) (2012) 141–142
2012
-
[13]
Szegedy, W
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, Going deeper with convolutions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 1–9
2015
-
[14]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[15]
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications, arXiv preprint arXiv:1704.04861 (2017)
work page internal anchor Pith review arXiv 2017
-
[16]
Silver, J
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, et al., Mastering the game of go without human knowledge, nature 550 (7676) (2017) 354–359
2017
-
[17]
R. Raj, S. Banerjee, N. Chandra, Z. Wan, J. Tong, A. Samajdhar, T. Krishna, Scale-sim v3: A modular cycle-accurate systolic accelerator simulator for end-to-end system analysis, in: 2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), IEEE, 2025, pp. 186–200
2025
-
[18]
Zhang, Y
W. Zhang, Y. Yao, et al., Photonic neural networks: a survey, IEEE Journal of Selected Topics in Quantum Electronics 26 (5) (2020) 1–12
2020
-
[19]
Dalir, B
H. Dalir, B. M. Nouri, X. Ma, P. Nicola, B. J. Shastri, V. J. Sorger, High-density integrated photonic tensor processing unit with a matrix multiply compile, in: 2022 IEEE Photonics Conference (IPC), IEEE, 2022, pp. 1–2
2022
-
[20]
T. Wu, Q. Cai, J. Ye, B. Jahannia, M.-H. Liao, H. Dalir, E. Heidari, Highly energy-efficient photonic modulator based on exceptional point, in: CLEO: Science and Innovations, Optica Publishing Group, 2025, p. JPS100_169
2025
-
[21]
Tossoun, X
B. Tossoun, X. Xiao, S. Cheung, Y. Yuan, Y. Peng, S. Srinivasan, G. Giamougiannis, Z. Huang, P. Singaraju, Y. London, et al., Large-scale integrated photonic device platform for energy-efficient ai/ml accelerators, IEEE Journal of Selected Topics in Quantum Electronics 31 (3: AI/ML Integrated Opto-electronics) (2025) 1–26
2025
-
[22]
Q. Cai, B. Jahannia, T. Wu, J. Ye, A. Amirany, H. Dalir, E. Heidari, Tcsel: a novel high-power laser architecture with enhanced efficiency and beam control for next-generation lidar applications, in: Infrared Sensors, Devices, and Applications XV, Vol. 13613, SPIE, 2025, pp. 105–114
2025
-
[23]
Amirany, B
A. Amirany, B. Jahannia, B. Hayden, K. Karkheiran, E. Heidari, H. Dalir, Integrated pcm-based dac/adc design for energy-efficient photonic computing systems, in: Photonic Computing: From Materials and Devices to Systems and Applications II, Vol. 13581, SPIE, 2025, pp. 51–61
2025
-
[24]
Y. Song, Y. Hu, X. Zhu, K. Powell, L. Magalhães, F. Ye, H. K. Warner, S. Lu, X. Li, D. Renaud, 14 et al., Integrated electro-optic digital-to-analogue link for efficient computing and arbitrary waveform generation, Nature Photonics 19 (10) (2025) 1107–1115
2025
-
[25]
J. Kim, Q. Zhou, Z. Yu, Photonic systolic array for all-optical matrix–matrix multiplication, Laser & Photonics Reviews (2024) e01995
2024
-
[26]
R. Tang, M. Okano, C. Zhang, K. Toprasertpong, S. Takagi, M. Takenaka, Waveguide-multiplexed photonic matrix–vector multiplication processor using multiport photodetectors, Optica 12 (6) (2025) 812–820
2025
-
[27]
Youngblood, M
J.Feldmann, N. Youngblood, M. Karpov, H. Gehring, X. Li, M. Stappers, M. Le Gallo, X. Fu, A. Lukashchuk, A. S. Raja, et al., Parallel convolutional processing using an integrated photonic tensor core, Nature 589 (7840) (2021) 52–58
2021
-
[28]
X. Ma, N. Peserico, A. Khaled, Z. Guo, B. Nouri, H. Dalir, B. Shastri, V. Sorger, High-density integrated photonic tensor processing unit with a matrix multiply compiler, Research Square (2022)
2022
-
[29]
S. Wu, X. Mu, L. Cheng, S. Mao, H. Fu, State-of-the-art and perspectives on silicon waveguide crossings: Areview, Micromachines11 (3) (2020)326
2020
-
[30]
Shafiee, S
A. Shafiee, S. Banerjee, B. Charbonnier, S. Pasricha, M. Nikdast, Compact and low-loss pcm-based silicon photonic mzis for photonic neural networks, in: 2023 IEEE Photonics Conference (IPC), IEEE, 2023, pp. 1–2
2023
-
[31]
B. Dong, S. Aggarwal, W. Zhou, U. E. Ali, N. Farmakidis, J. S. Lee, Y. He, X. Li, D.-L. Kwong, C. Wright, et al., Higher-dimensional processing using a photonic tensor core with continuous-time data, Nature Photonics 17 (12) (2023) 1080–1088
2023
-
[32]
Y.-H. Chen, J. Emer, V. Sze, Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks, in: IEEE International Solid-State Circuits Conference (ISSCC), IEEE, 2016, pp. 262–263
2016
-
[33]
Sawant, A
R. Sawant, A. Albanese, A. Rogemont, G. Gonzalez-Cortes, Y. Brûlé, L. Karam, J.-b. Jager, S. Malhouitre, B. Charbonnier, A. Coillet, et al., High-endurance and energy-efficient all-optical programming of scalable silicon waveguides with integrated phase-change material patches, Advanced Optical Materials 13 (25) (2025) e00775
2025
-
[34]
Samajdar, J
A. Samajdar, J. M. Joseph, Y. Zhu, P. Whatmough, M. Mattina, T. Krishna, A systematic methodology for characterizing scalability of dnn accelerators using scale-sim, IEEEComputerArchitectureLetters19(2) (2020) 114–117
2020
-
[35]
F. Tu, Y. Wang, Z. Wu, L. Liang, Y. Ding, B. Kim, L. Liu, S. Wei, Y. Xie, S. Yin, A 28nm 29.2 tflops/w bf16 and 36.5 tops/w int8 reconfigurable digital cim processor with unified fp/int pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration, in: 2022 IEEE International Solid-State Circuits Conference (ISSCC), Vol. 65, IEE...
2022
-
[36]
Le Gallo, R
M. Le Gallo, R. Khaddam-Aljameh, M. Stanisavljevic, A. Vasilopoulos, B. Kersting, M. Dazzi, G. Karunaratne, M. Brändli, A. Singh, S. M. Mueller, et al., A 64-core mixed-signal in-memory compute chip based on phase-change memory for deep neural network inference, Nature Electronics 6 (9) (2023) 680–693
2023
-
[37]
A. C. Yüzügüler, C. Sönmez, M. Drumond, Y. Oh, B.Falsafi, P.Frossard, Scale-outsystolicarrays, ACM Transactions on Architecture and Code Optimization 20 (2) (2023) 1–25
2023
-
[38]
M. Stepanovsky, A comparative review of mems-based optical cross-connects for all-optical networks from the past to the present day, IEEE Communications Surveys & Tutorials 21 (3) (2019) 2928–2946
2019
-
[39]
Parra, J
J. Parra, J. Navarro-Arenas, P. Sanchis, Silicon thermo-optic phase shifters: a review of configurations and optimization strategies, Advanced Photonics Nexus 3 (4) (2024) 044001–044001
2024
-
[40]
Farmakidis, N
N. Farmakidis, N. Youngblood, X. Li, J. Tan, J. L. Swett, Z. Cheng, C. D. Wright, W. H. Pernice, H. Bhaskaran, Plasmonic nanogap enhanced phase-change devices with dual electrical-optical functionality, Science advances 5 (11) (2019) eaaw2687
2019
-
[41]
Aadhi, L
A. Aadhi, L. Di Lauro, B. Fischer, P. Dmitriev, I. Alamgir, C. Mazoukh, N. Perron, E. Viktorov, A. Kovalev, A. Eshaghi, et al., Scalable photonic reservoir computing for parallel machine learning tasks, Nature Communications (2025)
2025
-
[42]
Shekhar, W
S. Shekhar, W. Bogaerts, L. Chrostowski, J. E. Bowers, M. Hochberg, R. Soref, B. J. Shastri, Roadmapping the next generation of silicon photonics, Nature Communications 15 (1) (2024) 751
2024
-
[43]
W. Tian, Y. Wang, H. Dang, H. Hou, Y. Xi, Photonic integrated circuits: research advances and challenges in interconnection and packaging technologies, in: Photonics, Vol. 12, MDPI, 2025, p. 821. 15
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.