Recognition: unknown
Not All Memories Age the Same: Autodiscovery of Adaptive Decay in Knowledge Graphs
Pith reviewed 2026-05-09 23:56 UTC · model grok-4.3
The pith
Knowledge graphs should replace uniform decay with a learned hierarchical surface driven by observation velocity and value volatility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
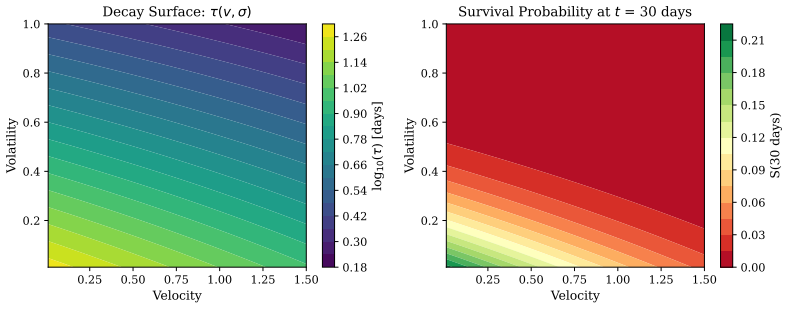
Uniform decay is misspecified for knowledge graphs because different knowledge types exhibit distinct temporal dynamics. The proposed hierarchical framework parameterizes a decay surface by two orthogonal signals, velocity and volatility, and decomposes it into domain-level, context-level, and entity-level parameters. All parameters are recovered from data alone via survival analysis on value-supersession events, without predefined taxonomies. Experiments confirm that the learned clusters recover planted structure and that heterogeneous decay produces large gains over uniform baselines on both synthetic graphs and real Wikipedia and clinical records.
What carries the argument
A three-level hierarchical decay surface parameterized by velocity (observation frequency) and volatility (embedding-distance change between successive values), with parameters emerging from survival analysis on supersession lifetimes.
If this is right
- Predicates naturally separate into permanent and transient groups without manual taxonomy construction.
- Retrieval ranking can weight each edge by its individually estimated survival probability at query time.
- The Lindy effect emerges automatically across learned clusters, with longer-surviving values showing lower future decay rates.
- Adding each successive hierarchy level produces measurable improvement in matching observed value lifetimes.
Where Pith is reading between the lines
- The same velocity-volatility decomposition could be applied to other timestamped structured data such as version histories or event streams.
- If the supersession signal proves robust, the method offers a route to make static knowledge bases in language-model retrieval systems dynamically age their contents.
- The approach implies that indexes in temporal databases might benefit from storing not only timestamps but also learned decay surfaces per relation type.
Load-bearing premise
Value supersession can be reliably separated from mere re-observation using only embedding distance, so that survival analysis on the resulting lifetimes yields the true decay parameters without any domain rules.
What would settle it
If independent human labels of fact persistence on the same Wikipedia or EHR data show no alignment with the velocity-volatility clusters recovered by the model, the claim that the hierarchy discovers meaningful adaptive decay would be falsified.
Figures

read the original abstract
Knowledge graphs used for retrieval treat all facts as equally current. Existing temporal approaches apply uniform decay, using a single forgetting curve regardless of knowledge type. We show this is fundamentally misspecified: different knowledge types exhibit different temporal dynamics, and the core retrieval problem is not latency or throughput but identifying what is important at query time. We propose a hierarchical framework that replaces uniform decay with a continuous decay surface parameterized by two orthogonal signals: velocity (how frequently a concept is observed) and volatility (how much the value changes between observations, measured via embedding distance). The decay surface is decomposed into three learnable levels: domain-level parameters capture universal patterns (some predicates are inherently permanent, others inherently transient), context-level parameters capture setting-dependent variation, and entity-level adaptation personalizes decay to specific subjects. All parameters emerge from data through survival analysis on observed value lifetimes, requiring no predefined taxonomies or domain expertise. We formulate edge lifetime as a survival problem where the event is value supersession (a meaningfully different value replacing the current one), distinct from mere re-observation. Experiments on synthetic temporal knowledge graphs demonstrate recovery of planted hierarchical parameters (HDBSCAN ARI = 1.0). Validation on 107 Wikipedia articles and 1,163 patient records from the Synthea clinical EHR simulator shows that velocity-volatility clusters emerge naturally, align with observable persistence patterns, and near-universally exhibit the Lindy effect (Weibull shape k < 1). Uniform decay performs 18x worse than no temporal weighting. Heterogeneous decay recovers from this, with each hierarchy level contributing measurable improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that uniform decay functions in knowledge graphs are misspecified because different knowledge types exhibit distinct temporal dynamics; it introduces a hierarchical velocity-volatility decay surface (domain-, context-, and entity-level parameters) learned via survival analysis on value supersession events detected by embedding distance, shows perfect recovery of planted parameters on synthetic data (HDBSCAN ARI=1.0), and reports that real data from Wikipedia and clinical records exhibit the Lindy effect with heterogeneous decay yielding an 18x improvement over uniform decay.
Significance. If the central results hold after validation, the work offers a data-driven alternative to manual taxonomies for adaptive forgetting in temporal retrieval, with the observed Lindy-effect Weibull fits and hierarchical gains providing a concrete, falsifiable basis for improving query-time importance ranking in dynamic KGs.
major comments (2)
- [Abstract (survival analysis formulation)] The proxy for value supersession events (embedding distance between successive observations) is untested against ground truth and is load-bearing for the claim that parameters emerge purely from data without domain expertise or predefined taxonomies; if the distance metric misclassifies re-observations as supersessions (e.g., due to synonym swaps or minor rephrasing), the recovered clusters, Lindy-effect fits, and reported gains become artifacts of the embedding model rather than true dynamics.
- [Abstract (experimental validation)] The 18x improvement claim and the statement that 'each hierarchy level contributing measurable improvement' lack error bars, statistical tests, or ablation details, undermining verifiability of the superiority over uniform decay (which itself is reported as 18x worse than no temporal weighting).
minor comments (2)
- [Abstract] Abstract provides no mention of confidence intervals, p-values, or sample sizes for the real-data results, reducing clarity on the strength of the Lindy-effect and improvement claims.
- [Abstract] Notation for the 'velocity-volatility decay surface' and the three-level decomposition could be formalized earlier with an equation to aid reproducibility.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address the major comments point by point below, providing clarifications and indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: The proxy for value supersession events (embedding distance between successive observations) is untested against ground truth and is load-bearing for the claim that parameters emerge purely from data without domain expertise or predefined taxonomies; if the distance metric misclassifies re-observations as supersessions (e.g., due to synonym swaps or minor rephrasing), the recovered clusters, Lindy-effect fits, and reported gains become artifacts of the embedding model rather than true dynamics.
Authors: We agree that the embedding-based proxy for supersession events is a key component and that it has not been validated against explicit ground-truth labels on real data, as such labels are typically unavailable. The synthetic data experiments, however, provide strong evidence that the method correctly recovers the underlying hierarchical parameters when the supersession events are known by design. On the real datasets, the discovered clusters correspond to semantically meaningful distinctions in temporal behavior, supporting that the approach captures genuine dynamics rather than artifacts. To address the concern, we will include in the revision a discussion of the proxy's limitations and an analysis of sensitivity to the choice of embedding model (e.g., comparing different pre-trained embeddings). This maintains the data-driven claim while acknowledging the measurement role of embeddings. revision: partial
-
Referee: The 18x improvement claim and the statement that 'each hierarchy level contributing measurable improvement' lack error bars, statistical tests, or ablation details, undermining verifiability of the superiority over uniform decay (which itself is reported as 18x worse than no temporal weighting).
Authors: The referee correctly identifies that the experimental results would be strengthened by additional statistical details. In the revised manuscript, we will add error bars to the reported performance metrics, conduct appropriate statistical tests to confirm the significance of the improvements, and expand the ablation studies to explicitly show the contribution of each level in the hierarchy. We will also provide more context on the baseline comparisons, including the uniform decay and no temporal weighting cases. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation learns decay-surface parameters from survival analysis on observed lifetimes, where the supersession event is defined via embedding distance and the hierarchy is a fixed structural decomposition into domain/context/entity levels. Synthetic experiments recover planted parameters with HDBSCAN ARI = 1.0, and real-data validation shows emergent clusters and Lindy-effect Weibull fits without any reported step that equates the final performance gains or autodiscovery claims to the input definitions by construction. The comparison to uniform decay and the per-level ablation improvements are measured outcomes rather than tautological renamings or fitted-input predictions. The framework is therefore self-contained against its external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- domain-level parameters
- context-level parameters
- entity-level parameters
axioms (2)
- domain assumption Value supersession (meaningfully different replacement) is the survival event, distinct from re-observation
- domain assumption Lindy effect (Weibull shape k < 1) holds for knowledge persistence
invented entities (1)
-
velocity-volatility decay surface
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Variational inference for dirichlet process mixtures
David M Blei and Michael I Jordan. Variational inference for dirichlet process mixtures. Bayesian Analysis, 1(1):121–143, 2006
2006
-
[2]
An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance
Sebastian Bruch, Shuguang Han, Michael Bendersky, and Marc Najork. An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance. InProceedings of the 2019 ACM SIGIR International Conference on Theory of Information Retrieval, pages 75–78, 2019
2019
-
[3]
Temporal knowledge graph completion: A survey
Borui Cai, Yong Xiang, Longxiang Gao, He Zhang, Yunfeng Li, and Jianxin Li. Temporal knowledge graph completion: A survey. InProceedings of the 32nd International Joint Conference on Artificial Intelligence (IJCAI), pages 6545–6553, 2023. 18
2023
-
[4]
Density-based clustering based on hierarchical density estimates
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. Density-based clustering based on hierarchical density estimates. InPacific-Asia Conference on Knowledge Discovery and Data Mining, pages 160–172. Springer, 2013
2013
-
[5]
Regression models and life-tables.Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–220, 1972
David R Cox. Regression models and life-tables.Journal of the Royal Statistical Society: Series B (Methodological), 34(2):187–220, 1972
1972
-
[6]
lifelines: survival analysis in python.Journal of Open Source Software, 4(40):1317, 2019
Cameron Davidson-Pilon. lifelines: survival analysis in python.Journal of Open Source Software, 4(40):1317, 2019
2019
-
[7]
FOREVER: Forgetting Curve-Inspired Memory Replay for Language Model Continual Learning
Yujie Feng, Hao Wang, Jian Li, Xu Chu, Zhaolu Kang, Yiran Liu, Yasha Wang, Philip S. Yu, and Xiao-Ming Wu. Forever: Forgetting curve-inspired memory replay for language model continual learning.arXiv preprint arXiv:2601.03938, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Chapman and Hall/CRC, 3rd edition, 2013
Andrew Gelman, John B Carlin, Hal S Stern, David B Dunson, Aki Vehtari, and Donald B Rubin.Bayesian Data Analysis. Chapman and Hall/CRC, 3rd edition, 2013
2013
-
[9]
Cambridge University Press, 2006
Andrew Gelman and Jennifer Hill.Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press, 2006
2006
-
[10]
How to mitigate information loss in knowledge graphs for graphrag: Leveraging triple context restoration and query-driven feedback
Manzong Huang, Chenyang Bu, Yi He, and Xindong Wu. How to mitigate information loss in knowledge graphs for graphrag: Leveraging triple context restoration and query-driven feedback. InProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2025
2025
-
[11]
Springer Series in Statistics
Joseph G Ibrahim, Ming-Hui Chen, and Debajyoti Sinha.Bayesian Survival Analysis. Springer Series in Statistics. Springer, 2001
2001
-
[12]
Cumulated gain-based evaluation of ir techniques.ACM Transactions on Information Systems, 20(4):422–446, 2002
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of ir techniques.ACM Transactions on Information Systems, 20(4):422–446, 2002
2002
-
[13]
Springer, 2012
David G Kleinbaum and Mitchel Klein.Survival Analysis: A Self-Learning Text. Springer, 2012
2012
-
[14]
Temporal knowledge graph reasoning based on evolutional representation learning
Zixuan Li, Xiaolong Jin, Wei Li, Saiping Guan, Jiafeng Guo, Huawei Shen, Yuanzhuo Wang, and Xueqi Cheng. Temporal knowledge graph reasoning based on evolutional representation learning. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 408–417, 2021
2021
-
[15]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InPro- ceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023
2023
-
[16]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing Systems, 2019
2019
-
[17]
Probabilistic programming in python using pymc3.PeerJ Computer Science, 2:e55, 2016
John Salvatier, Thomas V Wiecki, and Christopher Fonnesbeck. Probabilistic programming in python using pymc3.PeerJ Computer Science, 2:e55, 2016
2016
-
[18]
Random House, 2012
Nassim Nicholas Taleb.Antifragile: Things That Gain from Disorder. Random House, 2012
2012
-
[19]
Jason Walonoski, Mark Kramer, Joseph Nichols, Andre Quina, Chris Moesel, Dylan Hall, Carlton Duffett, Kudakwashe Dube, Thomas Gallagher, and Scott McLachlan. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record.Journal of the American Medical Informatics Association, 25(3):2...
2018
-
[20]
What is Patient A’s current status?
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory.Proceedings of the AAAI Conference on Artificial Intelligence, 2024. 19 Appendix A Temporal Retrieval in Practice We walk through a concrete example showing how hierarchical temporal decay affects retrieval from a clinical knowl...
2024
-
[21]
BRAF V600E(score 0.477): genetic mutation, 160 days old but still fresh because its shelf life is 10+ years
-
[22]
pembrolizumab (score 0.219): old treatment, partially decayed
-
[23]
Blood pressure
Blood pressure readings (score 0.000): completely stale, suppressed A.5 What Uniform Decay Gets Wrong A system using a single shelf life for all facts (say,τ= 90days) would produce: Edge Fact Uniform freshness Sim Uniform score 6 nivo+ipi 0.90 0.80.716 1–3 BP readings 0.31 0.70.218 5 pembrolizumab 0.24 0.8 0.189 4 BRAF V600E 0.17 0.5 0.084 Table 12: Retri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.