Recognition: unknown
Multibit neural inference in a N-ary crossbar architecture
Pith reviewed 2026-05-07 14:21 UTC · model grok-4.3
The pith
A simulation framework for N-ary crossbar arrays demonstrates neural inference on XOR and MNIST using 4-state magnetic tunnel junctions with 94.48 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
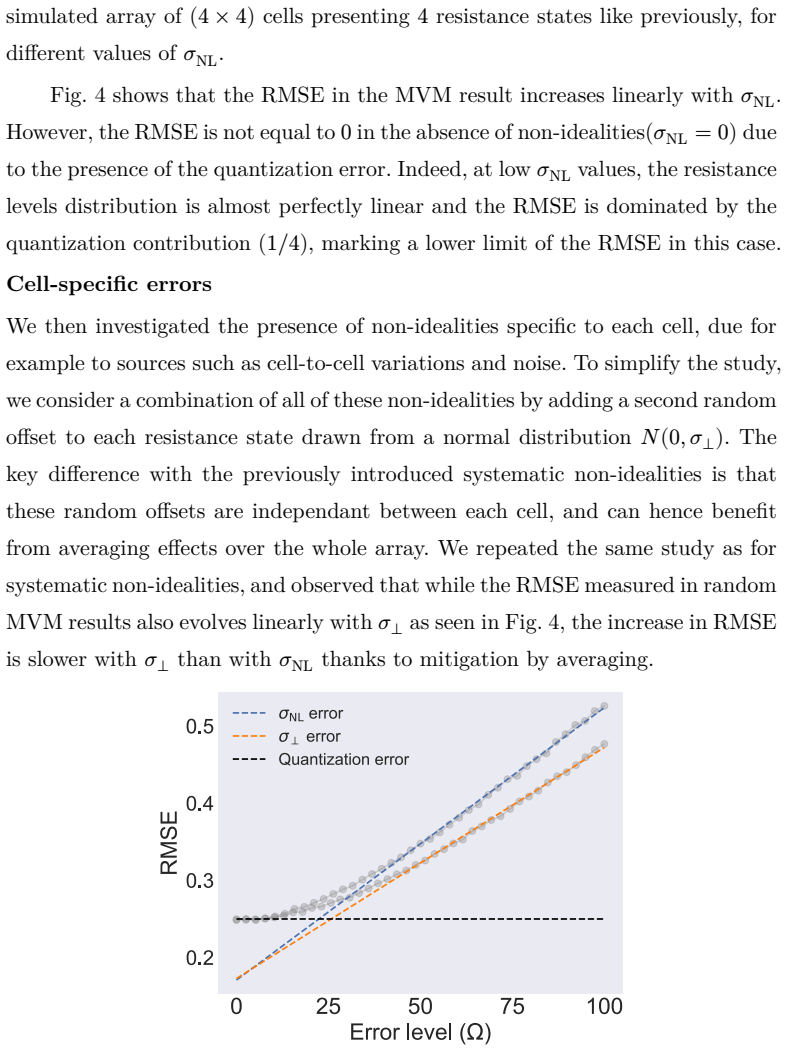
Multibit neural inference can be performed directly in an N-ary crossbar by mapping weights to multiple resistance states of magnetic tunnel junctions; when a 4x4 array of 4-state MTJs is simulated, it executes the XOR task correctly and classifies MNIST digits at 94.48 percent accuracy, with the software-to-hardware gap further narrowed by principal-component dimensionality reduction and with quantization identified as the leading error contributor over systematic offsets or random noise.
What carries the argument
The N-ary crossbar simulation framework that retrieves matrix-vector multiplication results from multi-state MTJ cells under minimal assumptions on device implementation.
If this is right
- Principal-component analysis reduces the performance gap between the simulated hardware and full-precision software.
- Averaging across the array makes cell-specific random noise less harmful to overall accuracy than fixed systematic errors.
- An optimal finite number of states per cell exists that trades quantization error against resistance-state resolution to minimize total multiplication error.
- Weight quantization dominates the error budget in multibit crossbar inference, making it the highest-priority target for device or mapping improvements.
Where Pith is reading between the lines
- Larger networks could be mapped to bigger crossbars if the same noise-averaging benefit holds at scale.
- The identified state-count optimum supplies a design rule for choosing how many resistance levels to engineer into future multibit memory cells for inference accelerators.
- Because the framework isolates quantization from other nonidealities, it can serve as a testbed for evaluating alternative multibit devices without fabricating full arrays.
Load-bearing premise
The modeled MTJ resistance states, systematic nonidealities, and random noise accurately capture the behavior of real physical devices.
What would settle it
Fabricating and measuring a physical 4x4 array of 4-state MTJs performing the same MNIST inference task and obtaining an accuracy substantially below 94.48 percent due to unmodeled effects would falsify the simulation's predictive power.
Figures






read the original abstract
In-memory computing (IMC) enables energy-efficient neural network inference by computing analog matrix-vector multiplications (MVM) in memory crossbar arrays. In this work we present a simulation framework for N-ary crossbar architectures that retrieves MVM results with minimal implementation assumptions. The XOR and MNIST classification tasks were successfully inferred using a simulated crossbar array of (4x4) 4-states magnetic tunnel junctions (MTJ). MNIST accuracy reached 94.48% (vs. 97.56% software baseline). The software-hardware performance gap was further reduced using PCA dimensionality reduction. We identified weight quantization as the primary error source, and studied its impact alongside systematic nonidealities and random noise. We find that cell-specific random noise is less detrimental than systematic errors due to averaging across the array. Finally, we demonstrate an optimal number of states per cell that balances quantization error against resistance state resolution to minimize total MVM error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a simulation framework for N-ary crossbar architectures that performs analog matrix-vector multiplications with minimal implementation assumptions. It demonstrates inference on XOR and MNIST tasks using a simulated 4x4 array of 4-state MTJs, reporting 94.48% MNIST accuracy versus a 97.56% software baseline. Weight quantization is identified as the dominant error source, with analysis showing that cell-specific random noise averages out across the array while systematic nonidealities have greater impact; PCA is used to narrow the software-hardware gap, and an optimal number of states per cell is proposed to balance quantization error against resistance resolution.
Significance. If the modeled MTJ behavior holds, the work supplies concrete benchmarks and error decomposition for multibit in-memory computing, highlighting that quantization dominates over averaged random noise. This could inform hardware design choices for MTJ-based IMC. The simulation approach with explicit accuracy numbers and PCA mitigation provides a useful reference point, though its value is constrained by the absence of hardware calibration.
major comments (1)
- Simulation framework description (abstract and device modeling sections): The 4-state MTJ resistance levels, systematic nonidealities, and random noise distributions are not calibrated or validated against experimental measurements from physical 4-state MTJ devices. This is load-bearing for the central claims, as the reported 94.48% MNIST accuracy, the identification of weight quantization as the primary error source, and the conclusion that random noise is less detrimental all depend on the fidelity of the simulated model to real hardware behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our simulation framework. We address the major comment below and outline planned revisions to improve clarity.
read point-by-point responses
-
Referee: Simulation framework description (abstract and device modeling sections): The 4-state MTJ resistance levels, systematic nonidealities, and random noise distributions are not calibrated or validated against experimental measurements from physical 4-state MTJ devices. This is load-bearing for the central claims, as the reported 94.48% MNIST accuracy, the identification of weight quantization as the primary error source, and the conclusion that random noise is less detrimental all depend on the fidelity of the simulated model to real hardware behavior.
Authors: We agree that the model parameters are not calibrated or validated against measurements from physical 4-state MTJ devices. Our work presents a simulation framework using MTJ behaviors drawn from parameters commonly reported in the literature on magnetic tunnel junctions. The central claims, including the 94.48% accuracy and error source analysis, are therefore specific to this modeled environment rather than direct hardware predictions. We will revise the device modeling section to explicitly reference the literature sources for resistance levels, systematic nonidealities, and noise distributions. We will also add a limitations paragraph clarifying the simulation scope and noting that hardware calibration remains an important direction for future work. This revision will better contextualize the results without changing the reported simulation outcomes or the finding that quantization dominates within the model. revision: yes
- Direct experimental calibration or validation of the 4-state MTJ model parameters against physical device measurements
Circularity Check
No circularity in simulation-based claims
full rationale
The paper presents a simulation framework for N-ary crossbar arrays with 4-state MTJs and reports inference results on XOR and MNIST (94.48% accuracy vs. 97.56% baseline) obtained by direct application of the modeled MVM operations, nonidealities, and noise. Error source identification (quantization dominant, random noise averaged out) follows from comparative simulations rather than any fitted parameter renamed as prediction or self-citation chain. No equations, uniqueness theorems, or ansatzes reduce by construction to the reported outputs; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MTJ devices can reliably hold 4 distinct resistance states with modeled nonidealities and noise
Reference graph
Works this paper leans on
-
[1]
& Han, Y
Zou, X., Xu, S., Chen, X., Yan, L. & Han, Y. Breaking the von Neumann bottleneck: architecture-level processing-in-memory technology. Science China Information Sciences 64, (2021)
2021
-
[2]
Wulf, W. A. & McKee, S. A. Hitting the memory wall: Implications of the obvious. ACM SIGARCH Computer Architecture News 23, (1995)
1995
-
[3]
Nature 554, 145-146 (2018)
Nature Editorial, Big data needs a hardware revolution. Nature 554, 145-146 (2018)
2018
-
[4]
Nature 561, 163-166 (2018)
Jones, N., How to stop data centres from gobbling up the world's electricity. Nature 561, 163-166 (2018)
2018
-
[5]
Chen, Y.-H., Krishna, T., Emer, J. S. & Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE journal of solid-state circuits 52, 127-138 (2016)
2016
-
[6]
Sim, J. et al. A 1.42 TOPS/W deep convolutional neural network recognition processor for intelligent IoE systems. 2016 IEEE International Solid-State Circuits Conference (ISSCC) 264-265 (2016)
2016
-
[7]
Desoli, G. et al. A 2.9 TOPS/W deep convolutional neural network SoC in FD-SOI 28nm for intelligent embedded systems. 2017 IEEE International Solid-State Circuits Conference (ISSCC) (2017)
2017
-
[8]
& Verhelst, M
Moons, B., Uytterhoeven, R., Dehaene, W. & Verhelst, M. Envision: A 0.26-to-10 TOPS/W subword-parallel dynamic-voltage-accuracy-frequency- scalable convolutional neural network processor in 28nm FD-SOI. 2017 IEEE International Solid-State Circuits Conference (ISSCC) 246-247 (2017). 21
2017
-
[9]
& Eleftheriou, E
Sebastian, A., Le Gallo, M., Khaddam-Aljameh, R. & Eleftheriou, E. Memory devices and applications for in-memory computing. Nature nanotechnology 15, 7 (2020)
2020
-
[10]
B., Janesky, J
Ikegawa, S., Mancoff, F. B., Janesky, J. & Aggarwal, S. Magnetoresistive random access memory: Present and future. IEEE Transactions on Electron Devices 67, (2020)
2020
-
[11]
Fong, X. et al. Spin-transfer torque devices for logic and memory: Prospects and perspectives. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 35, 1-22 (2015)
2015
-
[12]
Neuro-inspired computing with emerging nonvolatile memorys
Yu, S. Neuro-inspired computing with emerging nonvolatile memorys. Proceedings of the IEEE 106, (2018)
2018
-
[13]
Chakraborty, I. et al. Resistive crossbars as approximate hardware building blocks for machine learning: Opportunities and challenges. Proceedings of the IEEE 108, (2020)
2020
-
[14]
Wang, P. et al. Two-step quantization for low-bit neural networks. Proceedings of the IEEE Conference on computer vision and pattern recognition 4376-4384 (2018)
2018
-
[15]
Han, S., Mao, H. & Dally, W. J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149 (2015)
work page internal anchor Pith review arXiv 2015
-
[16]
& Bengio, Y
Hubara, I., Courbariaux, M., Soudry, D., El-Yaniv, R. & Bengio, Y. Quantized neural networks: Training neural networks with low precision weights and activations. journal of machine learning research 18, 1-30 (2018)
2018
-
[17]
Li, F., Liu, B., Wang, X., Zhang, B. & Yan, J. Ternary weight networks. arXiv preprint arXiv:1605.04711 (2016)
- [18]
-
[19]
& Zeng, Z
Zhang, Y., Cui, M., Shen, L. & Zeng, Z. Memristive quantized neural networks: A novel approach to accelerate deep learning on-chip. IEEE transactions on cybernetics 51, 4 (2019). 22
2019
-
[20]
& Alioto, M
Pham, T.-N., Trinh, Q.-K., Chang, I.-J. & Alioto, M. STT-BNN: A novel STT-MRAM in-memory computing macro for binary neural networks. IEEE Journal on Emerging and Selected Topics in Circuits and Systems 12, 2 (2022)
2022
-
[21]
Jung, S. et al. A crossbar array of magnetoresistive memory devices for in- memory computing. Nature 2, 211-216 (2022)
2022
-
[22]
Doevenspeck, J. et al. SOT-MRAM based analog in-memory computing for DNN inference. 2020 IEEE Symposium on VLSI Technology
2020
-
[23]
& Kvatinsky, S
Greenberg-Toledo, T., Perach, B., Hubara, I., Soudry, D. & Kvatinsky, S. Training of quantized deep neural networks using a magnetic tunnel junction- based synapse. Semiconductor Science and Technology 36, 114003 (2021)
2021
-
[24]
Soliman, T. et al. First demonstration of in-memory computing crossbar using multi-level Cell {FeFET}. Nature Communications 14, 6348 (2023)
2023
-
[25]
Wang, Y. et al. An in-memory computing architecture based on two- dimensional semiconductors for multiply-accumulate operations. Nature communications 12, 1 (2021)
2021
-
[26]
Leroux, N. et al. Radio-frequency multiply-and-accumulate operations with spintronic synapses. Physical Review Applied 15, 034067 (2021)
2021
-
[27]
Lin, H. et al. Implementation of highly reliable and energy-efficient nonvolatile in-memory computing using multistate domain wall spin–orbit torque device. Advanced Intelligent Systems 4, 2200028 (2022)
2022
-
[28]
Rzeszut, P. et al. Multi-state MRAM cells for hardware neuromorphic computing. Scientific reports 12, 7178 (2022)
2022
-
[29]
Das, S. et al. A four-state magnetic tunnel junction switchable with spin- orbit torques. Applied Physics Letters 117, 72404 (2020)
2020
-
[30]
& Klein, L
Das, S., Zaig, A., Schultz, M. & Klein, L. Stabilization of exponential number of discrete remanent states with localized spin–orbit torques},. Applied Physics Letters 116, 26 (2020)
2020
-
[31]
MultiSpin.AI Consortium, Spintronics & AI Integration (accessed: 2026-04-10). 23
2026
-
[32]
Some methods for classification and analysis of multivariate observations
Macqueen, J. Some methods for classification and analysis of multivariate observations. Berkeley symposium on mathematical statistics and probability (1965)
1965
-
[33]
& Powell, M
Fletcher, R. & Powell, M. J. D. A Rapidly Convergent Descent Method for Minimization. The Computer Journal 6, 2 (1963)
1963
-
[34]
What is principal component analysis?
Ringnér, M. What is principal component analysis?. Nature Biotechnology 26, (2008). 24
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.