Recognition: unknown
A High-Throughput Compute-Efficient POMDP Hide-And-Seek-Engine (HASE) for Multi-Agent Operations
Pith reviewed 2026-05-07 10:22 UTC · model grok-4.3
The pith
A C++ engine for Dec-POMDPs reaches 33 million simulation steps per second on standard hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
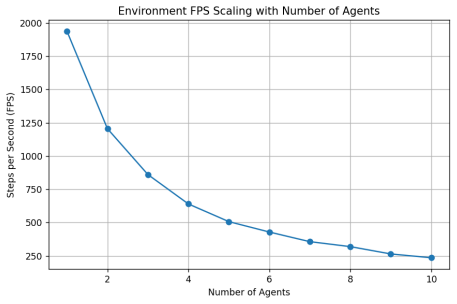
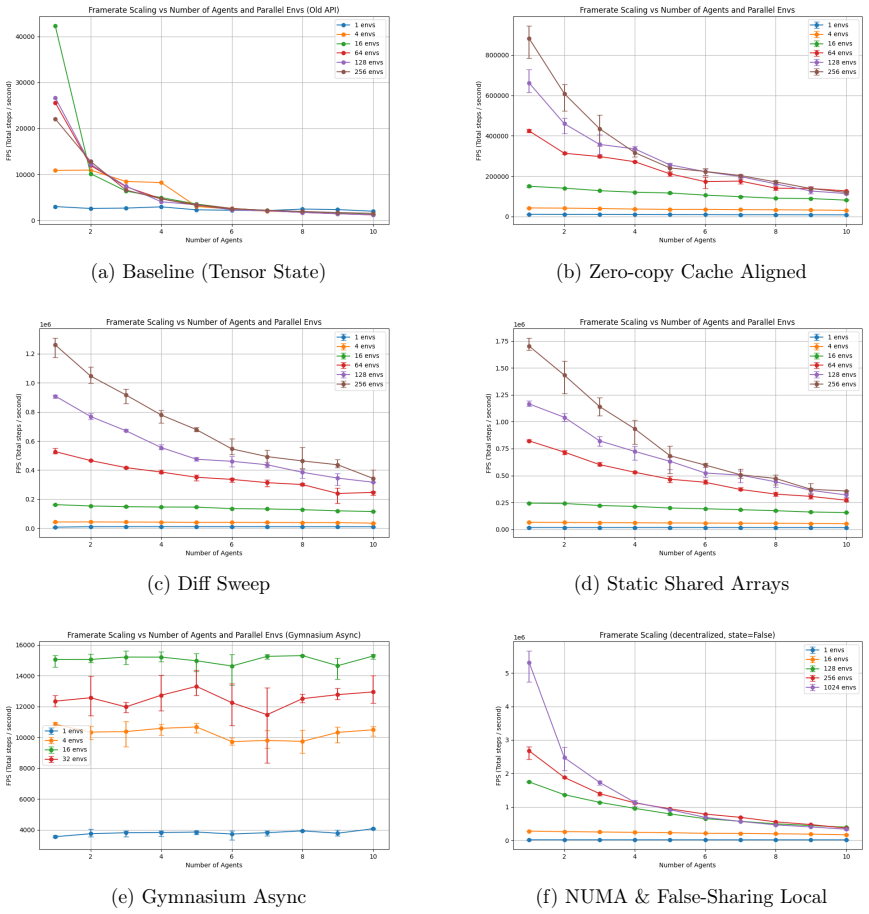
The Hide-And-Seek-Engine sustains throughput of up to 33,000,000 steps per second in a single-agent setup with 1024 environments and decentralized observations on a 16-core processor. Throughput falls to 7 million steps per second when ten agents are active, with random action generation accounting for roughly one-third of runtime. The implementation delivers an approximately 3,500-fold speedup over a single-threaded vectorized NumPy baseline while training cooperative multi-agent policies with PPO, DQN, and SAC in minutes.
What carries the argument
The Hide-And-Seek-Engine, built around data-oriented design, explicit 64-byte cache-line alignment to eliminate false sharing, and a zero-copy PyTorch bridge that uses pinned memory together with direct memory access.
If this is right
- Multi-agent policy training with PPO, DQN, and SAC completes in minutes on commodity hardware.
- Decentralized observation handling remains viable at scale without custom GPU kernels.
- Throughput stays orders of magnitude above Python baselines even as agent count rises to ten.
- The same architecture supports both single-agent and cooperative multi-agent Dec-POMDP workloads.
Where Pith is reading between the lines
- Similar low-level memory optimizations could shorten iteration cycles for other high-sample RL domains that currently rely on slower simulators.
- Real-time multi-agent decision systems might become practical if the engine's step rate is maintained when coupled to live sensors.
- The design choices suggest a template for porting other grid or discrete POMDP environments to achieve comparable speedups.
Load-bearing premise
The measured throughput numbers reflect sustained real performance under the described conditions without hidden implementation bottlenecks or measurement artifacts.
What would settle it
Reproduce the exact benchmark on an AMD Ryzen 9950X with 1024 parallel environments, measuring steps per second for both the single-agent case and the ten-agent case using the released engine code.
Figures








read the original abstract
Reinforcement Learning (RL) algorithms exhibit high sample complexity, particularly when applied to Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs). As a response, projects such as SampleFactory, EnvPool, Brax, and IsaacLab migrate parallel execution of classic environments such as MuJoCo and Atari into C++ thread pools or the GPU to decrease the computational cost of environment steps. We are interested in optimizing the decision-level of human-AI joint operations, so we introduce a compute-efficient Dec-POMDP engine natively architected in C++ called Hide-And-Seek-Engine. By employing Data-Oriented Design (DOD) principles, explicit 64-byte cache-line alignment to remove false sharing, and a zero-copy PyTorch memory bridge using pinned memory and Direct Memory Access (DMA), our engine sustains throughput of up to 33,000,000 steps per second (SPS) in a single-agent, 1024-environment, decentralized observations on an AMD Ryzen 9950X (16 cores). Ten agents reduces FPS to 7M SPS with generating random actions contributing 1/3rd the total runtime for reference. The engine achieves a throughput increase of approximately 3,500$\times$ over the baseline single threaded vectorized NumPy implementation and successfully trains cooperative multi-agent policies via PPO, DQN, and SAC in minutes, validating both its performance and generality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hide-And-Seek-Engine (HASE), a C++ Dec-POMDP simulator for multi-agent hide-and-seek operations. It applies Data-Oriented Design, explicit 64-byte cache-line alignment to avoid false sharing, and a zero-copy PyTorch bridge via pinned memory and DMA. The central empirical claims are a peak throughput of 33 million steps per second (SPS) for single-agent, 1024-environment, decentralized-observation configurations on a 16-core AMD Ryzen 9950X, scaling to 7 million SPS at 10 agents (with random-action generation accounting for one-third of runtime), a 3500× speedup versus a single-threaded vectorized NumPy baseline, and successful training of cooperative policies with PPO, DQN, and SAC in minutes.
Significance. If the throughput numbers and scaling behavior are reproducible under documented conditions, the engine would constitute a practical contribution to high-sample-rate simulation for Dec-POMDPs, directly addressing the sample-complexity barrier in multi-agent RL for operational domains. The combination of DOD, cache alignment, and zero-copy GPU bridging is a concrete engineering approach that could be adopted by other simulators; the reported training times provide initial evidence of end-to-end usability.
major comments (3)
- [Abstract] Abstract: The 33 M SPS and 7 M SPS figures are load-bearing for the entire contribution, yet the manuscript supplies no description of the timing harness. It is unclear whether each measurement includes (a) per-agent decentralized observation construction, (b) pinned-memory DMA round-trips to PyTorch, (c) action sampling inside or outside the engine, or (d) only a bare env.step() call. Without this, it is impossible to determine whether the quoted rates represent sustained usable throughput for an RL trainer.
- [Abstract] Abstract: No benchmark methodology, number of independent runs, standard deviation, warm-up protocol, or precise hardware configuration (core count utilization, NUMA topology, compiler flags) is reported. The claim of a 3500× improvement over the NumPy baseline therefore cannot be evaluated for fairness or reproducibility.
- [Abstract] Abstract: The statement that random-action generation accounts for one-third of runtime at ten agents implies partial cost accounting, but the paper does not indicate whether the 33 M SPS figure was measured with or without this component, undermining direct comparison to RL training loops that must supply actions.
minor comments (2)
- [Abstract] Abstract: The sentence 'Ten agents reduces FPS to 7M SPS' mixes FPS and SPS terminology; standardize on steps per second throughout.
- The manuscript should include at least one table or figure that tabulates throughput versus number of agents, environments, and observation type, together with the corresponding baseline numbers, to make the scaling claims verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on improving the clarity and reproducibility of our performance claims. We address each major comment below and commit to revising the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 33 M SPS and 7 M SPS figures are load-bearing for the entire contribution, yet the manuscript supplies no description of the timing harness. It is unclear whether each measurement includes (a) per-agent decentralized observation construction, (b) pinned-memory DMA round-trips to PyTorch, (c) action sampling inside or outside the engine, or (d) only a bare env.step() call. Without this, it is impossible to determine whether the quoted rates represent sustained usable throughput for an RL trainer.
Authors: We agree that a precise description of the timing harness is necessary. The reported throughput figures measure the complete C++ environment step, which includes per-agent decentralized observation construction and state transitions. Random actions are generated internally within the engine for these benchmarks. The zero-copy PyTorch bridge using pinned memory and DMA is not included in the SPS timing because it operates asynchronously with negligible overhead. We will revise the manuscript to include an explicit description of the timing harness and what components are measured. revision: yes
-
Referee: [Abstract] Abstract: No benchmark methodology, number of independent runs, standard deviation, warm-up protocol, or precise hardware configuration (core count utilization, NUMA topology, compiler flags) is reported. The claim of a 3500× improvement over the NumPy baseline therefore cannot be evaluated for fairness or reproducibility.
Authors: The current manuscript does not provide these methodological details, limiting the ability to reproduce and evaluate the speedup claim. We will add a dedicated 'Benchmarking and Reproducibility' subsection that specifies the number of independent runs, reports standard deviations, describes the warm-up protocol, details the hardware configuration including core utilization and compiler flags, and provides the exact implementation of the NumPy baseline for fair comparison. revision: yes
-
Referee: [Abstract] Abstract: The statement that random-action generation accounts for one-third of runtime at ten agents implies partial cost accounting, but the paper does not indicate whether the 33 M SPS figure was measured with or without this component, undermining direct comparison to RL training loops that must supply actions.
Authors: To clarify, the 33 M SPS measurement for the single-agent configuration includes internal random action generation, as does the 7 M SPS at ten agents where it constitutes approximately one-third of the runtime. This setup is intended to reflect a realistic throughput for RL training where actions must be provided. We will update the manuscript to explicitly state this and include a breakdown of runtime components. revision: yes
Circularity Check
No circularity: empirical implementation benchmarks with no derivation chain
full rationale
The paper presents a C++ engine implementation using Data-Oriented Design, 64-byte alignment, and zero-copy PyTorch DMA, then reports measured throughput (33M SPS single-agent, 7M SPS at 10 agents) and training times for PPO/DQN/SAC. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing claims appear. The central contribution is an engineering artifact whose performance numbers are externally verifiable via replication rather than internally forced by definition or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices, Inc., March 2022
Advanced Micro Devices, Inc.High Performance Computing (HPC) Tuning Guide for AMD EPYC 7003 Series Processors. Advanced Micro Devices, Inc., March 2022. Document 70574; Revision 1.0
2022
-
[2]
Gabriel M Arantes, Richard F Pinto, Bruno L Dalmazo, Eduardo N Borges, Giancarlo Lucca, Vi- viane LD de Mattos, Fabian C Cardoso, and Rafael A Berri. Impact of data-oriented and object-oriented designonperformanceandcacheutilizationwithartificialintelligencealgorithmsinmulti-threadedcpus. arXiv preprint arXiv:2512.07841, 2025
-
[3]
Dota 2 with Large Scale Deep Reinforcement Learning
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak, Christy Den- nison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review arXiv 1912
-
[4]
The complexity of de- centralized control of markov decision processes.Mathematics of operations research, 27(4):819–840, 2002
Daniel S Bernstein, Robert Givan, Neil Immerman, and Shlomo Zilberstein. The complexity of de- centralized control of markov decision processes.Mathematics of operations research, 27(4):819–840, 2002
2002
-
[5]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & cus- tomizable reinforcement learning environments for goal-oriented tasks.CoRR, abs/2306.13831, 2023
-
[6]
arXiv preprint arXiv:2502.03349 (2025)
MarcoCusumano-Towner, DavidHafner, AlexHertzberg, BrodyHuval, AlekseiPetrenko, Eugene Vinit- sky, Erik Wijmans, Taylor Killian, Stuart Bowers, Ozan Sener, et al. Robust autonomy emerges from self-play.arXiv preprint arXiv:2502.03349, 2025
-
[7]
Distributed prioritized experience replay
Horgan Dan, J Quan, D Budden, et al. Distributed prioritized experience replay. InProc. 5th Int. Conf. Learning Representations (ICLR, Vancouver, BC, Canada, 2018), 2018
2018
-
[8]
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 36:37567–37593, 2023
Benjamin Ellis, Jonathan Cook, Skander Moalla, Mikayel Samvelyan, Mingfei Sun, Anuj Mahajan, Jakob Foerster, and Shimon Whiteson. Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 36:37567–37593, 2023
2023
-
[9]
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. InInternational conference on machine learning, pages 1407–1416. PMLR, 2018
2018
-
[10]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax - a differentiable physics engine for large scale rigid body simulation, 2021
2021
-
[11]
Simplifying deep temporal difference learning.arXiv preprint arXiv:2407.04811, 2024
Matteo Gallici, Mattie Fellows, Benjamin Ellis, Bartomeu Pou, Ivan Masmitja, Jakob Nicolaus Foerster, and Mario Martin. Simplifying deep temporal difference learning.arXiv preprint arXiv:2407.04811, 2024
-
[12]
Bandwidth-aware page placement in numa
David Gureya, Joao Neto, Reza Karimi, Joao Barreto, Pramod Bhatotia, Vivien Quema, Rodrigo Rodrigues, Paolo Romano, and Vladimir Vlassov. Bandwidth-aware page placement in numa. In2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 546–556. IEEE, 2020
2020
-
[13]
Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy max- imum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[14]
pybind11 – seamless operability between c++11 and python, 2017
Wenzel Jakob, Jason Rhinelander, and Dean Moldovan. pybind11 – seamless operability between c++11 and python, 2017. https://github.com/pybind/pybind11
2017
-
[15]
Sample-efficient reinforcement learn- ing of undercomplete POMDPs
Chi Jin, Sham Kakade, Akshay Krishnamurthy, and Qinghua Liu. Sample-efficient reinforcement learn- ing of undercomplete POMDPs. InAdvances in Neural Information Processing Systems, volume 33, pages 18530–18539, 2020. 19
2020
-
[16]
Unity: A general platform for intelligent agents.arXiv:1809.02627, 2018
Arthur Juliani, Vincent-Pierre Berges, Ervin Teng, Andrew Cohen, Jonathan Harper, Chris Elion, Chris Goy, Yuan Gao, Hunter Henry, Marwan Mattar, et al. Unity: A general platform for intelligent agents. arXiv preprint arXiv:1809.02627, 2018
-
[17]
Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453, 2019
Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, Vinicius Zambaldi, Satyaki Upadhyay, Julien Pérolat, Sriram Srinivasan, Finbarr Timbers, Karl Tuyls, Shayegan Omidshafiei, et al. Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453, 2019
-
[18]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano- Munoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Asynchronous methods for deep reinforcement learning
Volodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational conference on machine learning, pages 1928–1937. PmLR, 2016
1928
-
[20]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[21]
OpenMP application program interface version 3.0, May 2008
OpenMP Architecture Review Board. OpenMP application program interface version 3.0, May 2008
2008
-
[22]
A review of cooperative multi-agent deep reinforcement learning.Applied Intelligence, 53(11):13677–13722, 2023
Afshin Oroojlooy and Davood Hajinezhad. A review of cooperative multi-agent deep reinforcement learning.Applied Intelligence, 53(11):13677–13722, 2023
2023
-
[23]
Pytorch: An imperative style, high- performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high- performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[24]
Sample factory: Egocentric 3d control from pixels at 100,000 fps with a single gpu
Aleksei Petrenko, Zhehui Huang, Tushar Kumar, Gaurav Sukhatme, and Vladlen Koltun. Sample factory: Egocentric 3d control from pixels at 100,000 fps with a single gpu. InInternational Conference on Machine Learning, pages 7654–7663. PMLR, 2020
2020
-
[25]
arXiv preprint arXiv:1902.04043 , year=
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nantas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge.arXiv preprint arXiv:1902.04043, 2019
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[27]
An extensible, data-oriented architecture for high-performance, many-world simulation.ACM Transactions on Graphics (TOG), 42(4):1–14, 2023
Brennan Shacklett, Lucis Zhan, Hao Chen, Mingfei Sun, Dieter Fox, and Kayvon Fatahalian. An extensible, data-oriented architecture for high-performance, many-world simulation.ACM Transactions on Graphics (TOG), 42(4):1–14, 2023
2023
-
[28]
Joseph Suarez. Pufferlib: Making reinforcement learning libraries and environments play nice.arXiv preprint arXiv:2406.12905, 2024
-
[29]
Action branching architectures for deep reinforce- ment learning
Arash Tavakoli, Fabio Pardo, and Petar Kormushev. Action branching architectures for deep reinforce- ment learning. InProceedings of the aaai conference on artificial intelligence, volume 32, 2018
2018
-
[30]
Pettingzoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032– 15043, 2021
J Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Pettingzoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032– 15043, 2021
2021
-
[31]
Falsesharingandspatiallocalityinmultiprocessor caches.IEEE Transactions on Computers, 43(6):651–663, 1994
JosepTorrellas, MonicaSLam, andJohnLHennessy. Falsesharingandspatiallocalityinmultiprocessor caches.IEEE Transactions on Computers, 43(6):651–663, 1994. 20
1994
-
[32]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments.arXiv preprint arXiv:2407.17032, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Grandmaster level in starcraft ii using multi-agent reinforcement learning.nature, 575(7782):350–354, 2019
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning.nature, 575(7782):350–354, 2019
2019
-
[34]
Envpool: A highly parallel reinforcement learning environment execution engine.Advances in Neural Information Processing Systems, 35:22409–22421, 2022
Jiayi Weng, Min Lin, Shengyi Huang, Bo Liu, Denys Makoviichuk, Viktor Makoviychuk, Zichen Liu, Yu- fan Song, Ting Luo, Yukun Jiang, et al. Envpool: A highly parallel reinforcement learning environment execution engine.Advances in Neural Information Processing Systems, 35:22409–22421, 2022
2022
-
[35]
The sur- prising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The sur- prising effectiveness of ppo in cooperative multi-agent games.Advances in neural information processing systems, 35:24611–24624, 2022. 21
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.