Robust Lightweight Crack Classification for Real-Time UAV Bridge Inspection
Pith reviewed 2026-07-01 08:43 UTC · model grok-4.3
The pith
A lightweight CNN framework with attention and scene priors detects bridge cracks at 825 FPS using 11 million parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
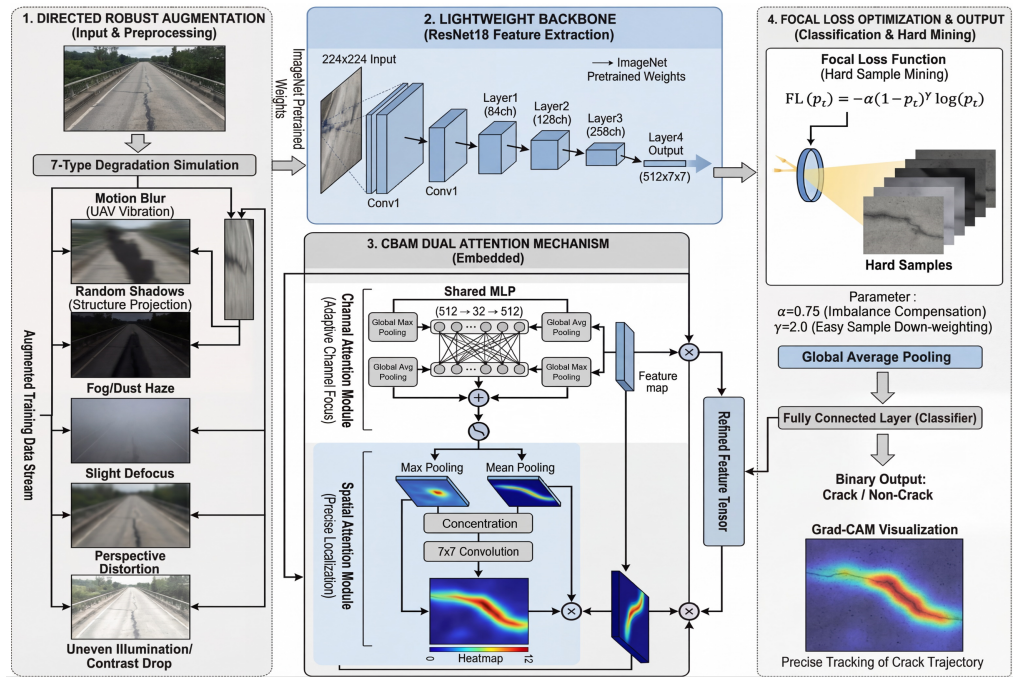
The unified lightweight convolutional neural network framework composed of a lightweight backbone network, a Convolutional Block Attention Module for channel and spatial enhancement, a directed robust augmentation strategy based on inspection-scene priors, and Focal Loss for hard-sample learning under class imbalance achieves an inference speed of 825 FPS with only 11.21M parameters and 1.82G FLOPs on the SDNET2018 dataset, improving the F1-score by 2.51% and recall by 3.95% over the baseline while shifting attention to crack trajectories.
What carries the argument
The synergistic four-component lightweight CNN framework consisting of a lightweight backbone, CBAM attention module, directed augmentation from inspection-scene priors, and Focal Loss.
If this is right
- Ground stations can receive crack classifications from live UAV video streams without heavy hardware.
- The attention module directs model focus along continuous crack trajectories rather than isolated patches.
- The augmentation and loss choices reduce the impact of class imbalance and degraded imaging on detection rates.
- The low parameter and FLOP count keeps the method feasible for assisted real-time UAV deployment.
Where Pith is reading between the lines
- The same modular stacking of backbone, attention, prior-based augmentation, and imbalance loss could transfer to other mobile-camera inspection tasks such as road or pipeline monitoring.
- Defining new scene priors for different environments would allow the augmentation step to adapt without retraining the entire network.
- Pairing the classifier with UAV flight controllers could enable on-the-fly route adjustments when crack density exceeds a threshold.
Load-bearing premise
The accuracy and speed gains arise from the interaction of the four listed components on the chosen dataset rather than from dataset-specific tuning or an under-specified baseline.
What would settle it
Evaluating the full framework and the baseline on an independent collection of UAV-captured bridge images that include stronger motion blur, different lighting angles, or new crack distributions and checking whether the F1-score and recall margins remain.
Figures









read the original abstract
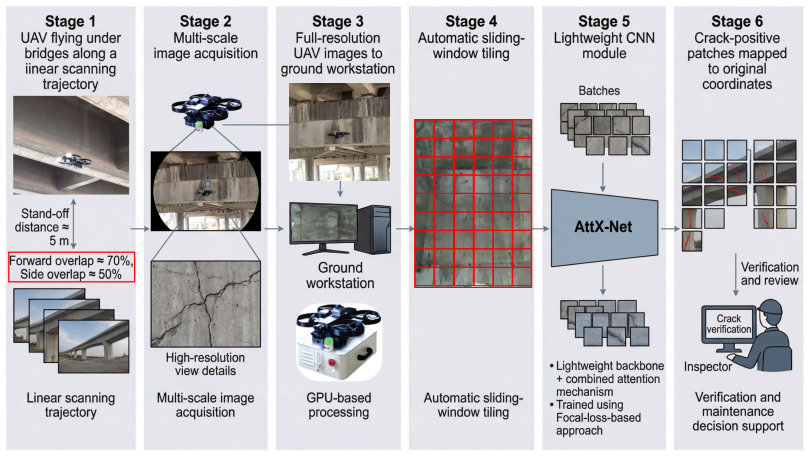
With the widespread application of Unmanned Aerial Vehicles (UAVs) in bridge structural health monitoring, deep learning-based automatic crack detection has become a major research focus. However, practical UAV inspections still face four key challenges: weak crack features, degraded imaging conditions, severe class imbalance, and limited computational resources for practical UAV inspection workflows. To address these issues, this paper proposes a unified lightweight convolutional neural network framework composed of four synergistic components: a lightweight backbone network, a Convolutional Block Attention Module (CBAM) for channel and spatial enhancement, a directed robust augmentation strategy based on inspection-scene priors, and Focal Loss for hard-sample learning under class imbalance. Experiments on the SDNET2018 bridge deck dataset show that the proposed method achieves an inference speed of 825 FPS with only 11.21M parameters and 1.82G FLOPs. Compared with the baseline model, the complete framework improves the F1-score by 2.51% and recall by 3.95%. In addition, Grad-CAM visualizations indicate that the introduced attention module shifts the model's focus from scattered regions to precise tracking along crack trajectories. Overall, this study achieves a strong balance among accuracy, speed, and robustness, providing a practical solution for ground-station assisted real-time deployment in UAV bridge inspections. The source code is available at: https://github.com/skylynf/AttXNet .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a lightweight CNN framework for real-time crack classification in UAV bridge inspections. It combines a lightweight backbone, CBAM attention, directed augmentation based on inspection priors, and Focal Loss to address weak features, degraded conditions, class imbalance, and compute limits. On SDNET2018, the model reaches 825 FPS at 11.21M parameters and 1.82G FLOPs, with +2.51% F1 and +3.95% recall over baseline; Grad-CAM shows improved crack focus. Code is released at the cited GitHub link.
Significance. If the performance gains hold under proper controls, the work would provide a deployable, efficient solution for ground-station-assisted UAV structural monitoring, directly tackling the four stated practical constraints. Public code release aids reproducibility and extension.
major comments (4)
- [Abstract, experiments] Abstract and experiments section: The central claim that the four components act synergistically to produce the 2.51% F1 and 3.95% recall gains is unsupported by any ablation tables or incremental results isolating the contribution of CBAM, directed augmentation, or Focal Loss relative to the baseline.
- [Dataset description, experiments] Dataset and evaluation: SDNET2018 consists of static bridge-deck photographs; the manuscript reports no experiments on data containing UAV-specific degradations (motion blur, vibration, altitude-induced lighting changes) despite claiming robustness to degraded imaging conditions.
- [Experiments] Experiments: Reported metrics lack error bars, standard deviations across multiple random seeds, or statistical significance tests, so it is impossible to determine whether the stated improvements exceed run-to-run variability.
- [Experiments] Baseline specification: The architecture, training protocol, and hyper-parameters of the 'baseline model' against which the 2.51% / 3.95% gains are measured are not described, preventing verification that the lift originates from the proposed additions rather than an under-tuned reference.
minor comments (2)
- [Abstract] The GitHub link should include a specific commit hash or release tag to ensure long-term reproducibility of the reported numbers.
- [Experiments] A comparison table of parameter count, FLOPs, and FPS against other lightweight backbones (e.g., MobileNetV2, EfficientNet-Lite) would strengthen the efficiency claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental validation and clarity. We will revise the manuscript to strengthen these elements while preserving the core contributions of the lightweight framework for UAV bridge inspection.
read point-by-point responses
-
Referee: [Abstract, experiments] Abstract and experiments section: The central claim that the four components act synergistically to produce the 2.51% F1 and 3.95% recall gains is unsupported by any ablation tables or incremental results isolating the contribution of CBAM, directed augmentation, or Focal Loss relative to the baseline.
Authors: We agree that ablation studies are required to substantiate the synergistic contributions. In the revised manuscript we will add a dedicated ablation table that incrementally introduces the lightweight backbone, CBAM, directed augmentation, and Focal Loss, reporting the corresponding F1 and recall changes relative to the baseline. revision: yes
-
Referee: [Dataset description, experiments] Dataset and evaluation: SDNET2018 consists of static bridge-deck photographs; the manuscript reports no experiments on data containing UAV-specific degradations (motion blur, vibration, altitude-induced lighting changes) despite claiming robustness to degraded imaging conditions.
Authors: SDNET2018 is the standard public benchmark for this task. The directed augmentation strategy was explicitly designed to emulate UAV degradations using inspection-scene priors. We will revise the dataset and discussion sections to clarify this distinction, explicitly state that real UAV-captured degraded imagery was not evaluated, and add a limitations paragraph acknowledging the gap. revision: partial
-
Referee: [Experiments] Experiments: Reported metrics lack error bars, standard deviations across multiple random seeds, or statistical significance tests, so it is impossible to determine whether the stated improvements exceed run-to-run variability.
Authors: We acknowledge the absence of variability measures. The revised experiments section will include results averaged over five independent random seeds with reported means and standard deviations; we will also add a brief note on statistical significance testing where feasible. revision: yes
-
Referee: [Experiments] Baseline specification: The architecture, training protocol, and hyper-parameters of the 'baseline model' against which the 2.51% / 3.95% gains are measured are not described, preventing verification that the lift originates from the proposed additions rather than an under-tuned reference.
Authors: We will expand the experimental setup subsection to fully specify the baseline architecture, training protocol, optimizer settings, learning-rate schedule, data splits, and all hyperparameters used for both baseline and proposed models. revision: yes
Circularity Check
No circularity: empirical metrics on external dataset
full rationale
The paper presents an empirical ML engineering contribution: a CNN framework with four components tested via direct measurement on the public SDNET2018 dataset. Reported figures (825 FPS, 11.21M params, 1.82G FLOPs, +2.51% F1, +3.95% recall) are observed outcomes, not quantities derived from internal fitted constants or self-referential equations. No mathematical derivation chain, uniqueness theorems, or ansatzes appear; the four components are combined and evaluated, with no step reducing a claimed prediction to a definition or prior self-citation by construction. This is the standard non-circular case for applied CV papers.
Axiom & Free-Parameter Ledger
free parameters (1)
- Network weights and training hyperparameters
axioms (1)
- domain assumption SDNET2018 images are representative of degraded UAV bridge inspection conditions
Reference graph
Works this paper leans on
-
[1]
mradermacher/ANITA-NEXT-24B-Dolphin-Mistral-UNCENSORED-ITA-GGUF51 (Anita 24B (Uncensored), part of the Advanced Natural-based interaction for the ITAlian language project, uncensored and fine-tuned version of Mistral Small 3.2); 13.Mistralai/Magistral-Small-2509 (Magistral Small)
-
[2]
mathematic
Mistralai/mistral-small-latest (Mistral Small 4, an effective 119B model with 6.5B active parameters, released on March 26 2026 and available via API). For what concerns the data generation workflow, each persona in MEDS was assigned a unique run_id and operated in one of two personification modes: human-like shadows or AI assistants (see Figure 2). In hu...
2026
-
[3]
Ict household survey 2025: Model questionnaire (2025)
Eurostat. Ict household survey 2025: Model questionnaire (2025). Question B5 lists examples including ChatGPT, Copilot, Gemini and LLaMA. 9.Eurostat. 64% of 16–24-year-olds used ai in 2025 (2026). Eurostat news article. 10.Wenger, E. & Kenett, Y . N. Large language models are homogeneously creative.PNAS nexus5, pgag042 (2026)
2025
-
[4]
for Comput
Zhang, T.et al.Benchmarking large language models for news summarization.Transactions Assoc. for Comput. Linguist. 12, 39–57 (2024)
2024
-
[5]
Chen, X., Zhou, L., Chen, J., Wang, G. & Li, X. How is language intelligence evolving? a multi-dimensional survey of large language models.Expert. Syst. with Appl.304, 130637, 10.1016/j.eswa.2025.130637 (2026)
- [6]
-
[7]
InFindings of the Association for Computational Linguistics: ACL 2024, 6884–6915 (2024)
Liu, H.et al.Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark. InFindings of the Association for Computational Linguistics: ACL 2024, 6884–6915 (2024)
2024
-
[8]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Balunovi´c, M., Dekoninck, J., Petrov, I., Jovanovi´c, N. & Vechev, M. Matharena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
InFindings of the Association for Computational Linguistics: EMNLP 2024, 11351–11368 (2024)
Benedetto, L.et al.Using llms to simulate students’ responses to exam questions. InFindings of the Association for Computational Linguistics: EMNLP 2024, 11351–11368 (2024)
2024
-
[10]
& MacLellan, C
Gupta, A., Reddig, J., Calo, T., Weitekamp, D. & MacLellan, C. J. Beyond final answers: Evaluating large language models for math tutoring. InInternational Conference on Artificial Intelligence in Education, 323–337 (Springer, 2025)
2025
-
[11]
Stöhr, C., Ou, A. W. & Malmström, H. Perceptions and usage of ai chatbots among students in higher education across genders, academic levels and fields of study.Comput. Educ. Artif. Intell.7, 100259 (2024)
2024
-
[12]
& Wei, Y
Wang, X. & Wei, Y . The influence of gen-ai assisted learning on primary school students’ math anxiety: An intervention study.Appl. Cogn. Psychol.39, e70088 (2025)
2025
-
[13]
Akheel, S. A. Guardrails for large language models: A review of techniques and challenges.J Artif Intell Mach Learn. & Data Sci3, 2504–2512 (2025)
2025
-
[14]
R., Mahadevan, R., Bare, R
Hopko, D. R., Mahadevan, R., Bare, R. L. & Hunt, M. K. The abbreviated math anxiety scale (amas) construction, validity, and reliability.Assessment10, 178–182 (2003)
2003
-
[15]
Nielsen, I. L. & Moore, K. A. Psychometric data on the mathematics self-efficacy scale.Educ. psychological measurement 63, 128–138 (2003). 23.May, D. K. Mathematics self-efficacy and anxiety questionnaire.PhD Diss. Univ. Ga.(2009)
2003
-
[16]
InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022)
Weidinger, L.et al.Taxonomy of risks posed by language models. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022)
2022
-
[17]
Australas
Mirriahi, N.et al.The relationship between students’ self-regulated learning skills and technology acceptance of genai. Australas. J. Educ. Technol.41, 16–33 (2025)
2025
-
[18]
& Siew, C
Stella, M., De Nigris, S., Aloric, A. & Siew, C. S. Forma mentis networks quantify crucial differences in stem perception between students and experts.PloS one14, e0222870 (2019)
2019
-
[19]
& Stella, M
Abramski, K., Citraro, S., Lombardi, L., Rossetti, G. & Stella, M. Cognitive network science reveals bias in gpt-3, gpt-3.5 turbo, and gpt-4 mirroring math anxiety in high-school students.Big Data Cogn. Comput.7, 124 (2023)
2023
- [20]
-
[21]
& Jurgens, D
Zheng, M., Pei, J., Logeswaran, L., Lee, M. & Jurgens, D. When” a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 15126–15154 (2024)
2024
-
[22]
Bergs, T.et al.The concept of digital twin and digital shadow in manufacturing.Procedia CIRP101, 81–84, 10.1016/j. procir.2021.02.010 (2021)
work page doi:10.1016/j 2021
-
[23]
A., Longo, A., Ficarella, A.et al.Digital twin (dt) in smart energy systems-systematic literature review of dt as a growing solution for energy internet of the things (eiot)
Ardebili, A. A., Longo, A., Ficarella, A.et al.Digital twin (dt) in smart energy systems-systematic literature review of dt as a growing solution for energy internet of the things (eiot). InE3S web of conferences, vol. 312, 1–18 (2021). 20/34
2021
-
[24]
Aghazadeh Ardebili, A., Zappatore, M., Ramadan, A. I. H. A., Longo, A. & Ficarella, A. Digital twins of smart energy systems: a systematic literature review on enablers, design, management and computational challenges.Energy Informatics 7, 94 (2024)
2024
-
[25]
Gaffinet, B., Al Haj Ali, J., Naudet, Y . & Panetto, H. Human digital twins: A systematic literature review and concept disambiguation for industry 5.0.Comput. Ind.166, 104230, https://doi.org/10.1016/j.compind.2024.104230 (2025). 34.Singh, M.et al.Digital twin: Origin to future.Appl. Syst. Innov.4, 36, 10.3390/asi4020036 (2021)
-
[26]
Aghazadeh Ardebili, A., Longo, A. & Ficarella, A. Digital twins bonds society with cyber-physical energy systems: a literature review. In2021 IEEE International Conferences on Internet of Things (iThings) and IEEE Green Computing &; Communications (GreenCom) and IEEE Cyber, Physical &; Social Computing (CP- SCom) and IEEE Smart Data (SmartData) and IEEE C...
-
[27]
Talk2AI: A Longitudinal Dataset of Human--AI Persuasive Conversations
Carrillo, A., Taietta, E., Ardebili, A. A., Veltri, G. A. & Stella, M. Talk2ai: A longitudinal dataset of human–ai persuasive conversations.arXiv preprint arXiv:2604.04354(2026). 37.John, O. The big-five trait taxonomy: History, measurement, and theoretical perspectives.Publ. as(1999)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [28]
-
[29]
De Duro, E. S., Veltri, G. A., Golino, H. & Stella, M. Measuring and identifying factors of individuals’ trust in large language models.arXiv preprint arXiv:2502.21028(2025)
-
[30]
Kranzler, J. H. & Pajares, F. An exploratory factor analysis of the mathematics self-efficacy scale—revised (mses-r).Meas. evaluation counseling development29, 215–228 (1997)
1997
-
[31]
Semeraro, A.et al.Emoatlas: An emotional network analyzer of texts that merges psychological lexicons, artificial intelligence, and network science.Behav. Res. Methods57, 10.3758/s13428-024-02553-7 (2025)
-
[32]
Jin, Z.et al.Logical fallacy detection. In Goldberg, Y ., Kozareva, Z. & Zhang, Y . (eds.)Findings of the Association for Com- putational Linguistics: EMNLP 2022, 7180–7198, 10.18653/v1/2022.findings-emnlp.532 (Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2022)
-
[33]
Stella, M., Hills, T. T. & Kenett, Y . N. Using cognitive psychology to understand gpt-like models needs to extend beyond human biases.Proc. Natl. Acad. Sci.120, e2312911120, 10.1073/pnas.2312911120 (2023). https://www.pnas.org/doi/pdf/ 10.1073/pnas.2312911120
-
[34]
Haim, E. & Stella, M. Cognitive networks for knowledge modeling: A gentle introduction for data-and cognitive scientists. Wiley Interdiscip. Rev. Cogn. Sci.17, e70026 (2026). 45.Yang, A.et al.Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025). 46.Liu, A.et al.Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024). 47.Abdin, M.et al.P...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Polignano, M., Basile, P. & Semeraro, G. Advanced natural-based interaction for the italian language: Llamantino-3-anita (2024). 2405.07101
-
[36]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding.CoRRabs/1810.04805(2018). 1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
& Kranzler, J
Pajares, F. & Kranzler, J. Self-efficacy beliefs and general mental ability in mathematical problem-solving.Contemp. educational psychology20, 426–443 (1995). 54.Binz, M.et al.A foundation model to predict and capture human cognition.Nature644, 1002–1009 (2025)
1995
-
[38]
Wulff, D. U. & Mata, R. Escaping the jingle-jangle jungle: Increasing conceptual clarity in psychology using large language models.Curr. Dir. Psychol. Sci.35, 59–65 (2026)
2026
-
[39]
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Liu, Y .et al.Trustworthy llms: a survey and guideline for evaluating large language models’ alignment.arXiv preprint arXiv:2308.05374(2023). 21/34 Correct Answer: C
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
The second is twice the first and the first is one-third of the other number
There are three numbers. The second is twice the first and the first is one-third of the other number. Their sum is 48. Find the largest number. A. 8 B. 12 C. 16 D. 24 E. 32 Correct Answer: D
-
[41]
T is next to G
Five points are on a line. T is next to G. K is next to H. C is next to T. H is next to G. Determine the positions of the points along the line. A. C, T, G, H, K B. C, G, T, H, K C. T, C, G, H, K D. C, T, H, G, K E. C, T, G, K, H Correct Answer: A
-
[42]
If y = 9 + x/5, find x when y = 10. A. 1 B. 3 C. 5 D. 10 E. 25 Correct Answer: C
-
[43]
This could be represented by 2/3
A baseball player got two hits for three times at bat. This could be represented by 2/3. Which decimal most closely represents this? A. 0.20 B. 0.33 C. 0.50 D. 0.67 E. 0.80 Correct Answer: D
-
[44]
If P = M + N, which of the following will be true? (a) N = P - M (b) P - N = M (c) N + M = P. A. Only (a) is true B. (a) and (b) only C. (a) and (c) only D. (b) and (c) only E. (a), (b), and (c) are all true Correct Answer: E
-
[45]
The hands of a clock form an obtuse angle at ____ o’clock. A. 1 o’clock B. 2 o’clock C. 3 o’clock D. 4 o’clock E. 6 o’clock Correct Answer: D
-
[46]
If there are 25 stamps in the packet, how many are 13-cent stamps? A
Bridget buys a packet containing 9-cent and 13-cent stamps for $2.65. If there are 25 stamps in the packet, how many are 13-cent stamps? A. 5 B. 8 C. 10 D. 12 E. 15 Correct Answer: C
-
[47]
On a certain map, 7/8 inch represents 200 miles. How far apart are two towns whose distance apart on the map is 3 half 25/34 Figure 10.Comparison of emotional profiles for the DeepSeek Chat model across Math Haters, Math Lovers, and LLM Figure 11.Comparison of emotional profiles for the Granite 4 Tiny model across Math Haters, Math Lovers, and LLM Figure ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.