Recognition: 1 theorem link
· Lean TheoremTalk2AI: A Longitudinal Dataset of Human--AI Persuasive Conversations
Pith reviewed 2026-05-10 20:14 UTC · model grok-4.3
The pith
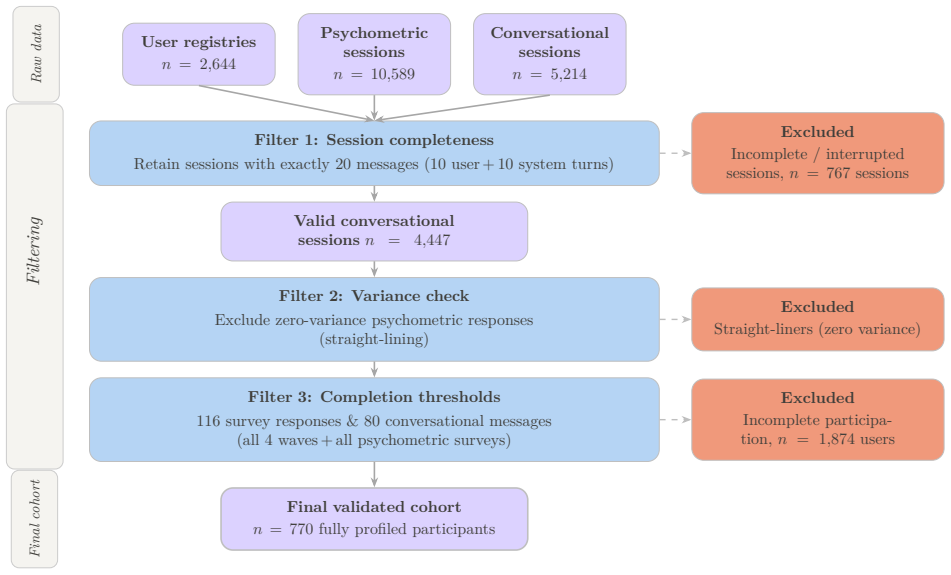
Talk2AI is a dataset of 3,080 human-AI conversations collected over four weeks to study persuasion and opinion change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Talk2AI is a large-scale longitudinal dataset of 3,080 conversations (totaling 30,800 turns) between human participants and Large Language Models (LLMs), designed to support research on persuasion, opinion change, and human-AI interaction. The corpus was collected from 770 profiled Italian adults across four weekly sessions in Spring 2025, using a within-subject design in which each participant conversed with a single model (GPT-4o, Claude Sonnet 3.7, DeepSeek-chat V3, or Mistral Large) on three socially relevant topics: climate change, math anxiety, and health misinformation. Each conversation is linked to rich contextual data, including sociodemographic characteristics and psychometric on
What carries the argument
The within-subject longitudinal design that assigns each participant to one LLM model across four sessions on three topics while collecting linked psychometric profiles and post-session self-reports on opinion change.
If this is right
- Researchers can track trajectories of opinion change across multiple weekly sessions for the same individuals.
- The data enables direct comparisons of persuasive impact between GPT-4o, Claude Sonnet 3.7, DeepSeek-chat V3, and Mistral Large on identical topics.
- Sociodemographic and psychometric variables can be tested as moderators of AI-driven attitude shifts.
- Links between perceived humanness of the AI and reported conviction stability become measurable over time.
- Behavioral intention reports after each session provide material for modeling downstream actions following AI dialogue.
Where Pith is reading between the lines
- The dataset could support experiments that add objective behavioral logs, such as follow-up web searches or real-world actions, to test whether self-reports predict observable outcomes.
- Extending the design to non-Italian populations or additional topics would allow tests of cultural generalizability of AI persuasion patterns.
- Analyses of conviction stability across sessions might reveal whether repeated AI exposure produces lasting or reversible attitude changes.
- The resource opens the possibility of training models to detect early signs of opinion drift in ongoing conversations.
Load-bearing premise
Self-reported opinion changes, conviction stability, and behavioral intentions accurately reflect genuine shifts induced by the AI conversations rather than demand characteristics or social desirability bias.
What would settle it
An independent study that measures objective behaviors such as actual donations to climate causes or clicks on health misinformation links and finds no statistical link to the self-reported opinion shifts in the dataset.
Figures

read the original abstract
Talk2AI is a large-scale longitudinal dataset of 3,080 conversations (totaling 30,800 turns) between human participants and Large Language Models (LLMs), designed to support research on persuasion, opinion change, and human-AI interaction. The corpus was collected from 770 profiled Italian adults across four weekly sessions in Spring 2025, using a within-subject design in which each participant conversed with a single model (GPT-4o, Claude Sonnet 3.7, DeepSeek-chat V3, or Mistral Large) on three socially relevant topics: climate change, math anxiety, and health misinformation. Each conversation is linked to rich contextual data, including sociodemographic characteristics and psychometric profiles. After each session, participants reported on opinion change, conviction stability, perceived humanness of the AI, and behavioral intentions, enabling fine-grained longitudinal analysis of how AI-mediated dialogue shapes beliefs and attitudes over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Talk2AI, a large-scale longitudinal dataset of 3,080 human-AI conversations (30,800 turns) collected from 770 Italian adults over four weekly sessions. Participants interacted with one of four LLMs (GPT-4o, Claude Sonnet 3.7, DeepSeek-chat V3, or Mistral Large) on three topics (climate change, math anxiety, health misinformation) in a within-subject design, providing sociodemographic, psychometric, and post-session self-report data on opinion change, conviction stability, perceived humanness, and behavioral intentions.
Significance. If the self-reported measures of opinion change are reliable and not unduly influenced by demand characteristics, this dataset would be a valuable resource for studying longitudinal effects of AI persuasion across models and topics, with its scale, multi-model comparison, and rich participant profiling enabling analyses not feasible with smaller or cross-sectional datasets. The within-subject longitudinal structure is particularly promising for tracking attitude dynamics over time.
major comments (2)
- The abstract describes the collection protocol and within-subject structure but supplies no information on data validation, inter-annotator checks, handling of dropouts, or statistical power; without the full methods section the central claim that the dataset supports fine-grained longitudinal analysis of persuasion and opinion change cannot be fully evaluated.
- The within-subject longitudinal design with repeated self-reports on the same topics makes the data especially susceptible to demand characteristics and social desirability bias, yet the collection protocol provides no objective corroboration (e.g., knowledge quizzes, implicit measures, or delayed behavioral follow-ups) to validate that reported opinion shifts reflect genuine AI-induced effects rather than participant expectations.
minor comments (1)
- The abstract states 3,080 conversations totaling 30,800 turns (implying an average of exactly 10 turns per conversation); clarify whether conversation length was capped or naturally varied and how this affects longitudinal comparability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the Talk2AI dataset manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: The abstract describes the collection protocol and within-subject structure but supplies no information on data validation, inter-annotator checks, handling of dropouts, or statistical power; without the full methods section the central claim that the dataset supports fine-grained longitudinal analysis of persuasion and opinion change cannot be fully evaluated.
Authors: The full manuscript includes a detailed Methods section that covers participant recruitment, session completion rates (with dropouts excluded to yield the final N=770), any annotation procedures and associated reliability checks, and sample-size justification tied to detectable effect sizes for opinion-change measures. The abstract was kept brief to comply with length constraints, but we agree it should better signal these elements. We will revise the abstract to include a concise statement on validation, dropout handling, and the dataset's suitability for longitudinal analysis. revision: yes
-
Referee: The within-subject longitudinal design with repeated self-reports on the same topics makes the data especially susceptible to demand characteristics and social desirability bias, yet the collection protocol provides no objective corroboration (e.g., knowledge quizzes, implicit measures, or delayed behavioral follow-ups) to validate that reported opinion shifts reflect genuine AI-induced effects rather than participant expectations.
Authors: We concur that repeated self-reports in a within-subject design are vulnerable to demand characteristics and social-desirability effects, a well-known limitation in persuasion research. The dataset consists exclusively of self-reported opinion change, conviction stability, perceived humanness, and behavioral intentions; we make no claim that these equate to objective attitude or behavior change. In the revision we will expand the Limitations section to discuss these biases explicitly and to note that the resource is intended to enable study of reported persuasion dynamics, with users free to pair it with external validation measures in future work. revision: partial
- The absence of objective corroboration (knowledge quizzes, implicit measures, or behavioral follow-ups) is inherent to the collected data and cannot be remedied by revision; new data collection would be required.
Circularity Check
Empirical dataset paper exhibits no circularity
full rationale
The paper presents an empirical dataset of human-AI conversations collected via a within-subject longitudinal protocol. No derivation chain, mathematical predictions, fitted parameters, or first-principles results are claimed. The contribution is the corpus itself (3,080 conversations with linked psychometric and opinion-change self-reports), which does not reduce to any self-referential input by construction. Self-citations, if present, are not load-bearing for any claimed result. This is a standard non-circular data-release paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Talk2AI is a large-scale longitudinal dataset of 3,080 conversations... designed to support research on persuasion, opinion change, and human-AI interaction.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Math Education Digital Shadows for facilitating learning with LLMs: Math performance, anxiety and confidence in simulated students and AIs
MEDS is a dataset of 28,000 LLM personas performing high-school math tasks alongside psychometric tests and cognitive networks that capture math anxiety, self-efficacy, and confidence to support safer AI tutors.
-
LLMs can persuade only psychologically susceptible humans on societal issues, via trust in AI and emotional appeals, amid logical fallacies
LLMs persuade only psychologically susceptible humans on societal issues through trust in AI and emotional appeals, while both sides rely on logical fallacies in roughly one out of every six conversational turns.
Reference graph
Works this paper leans on
-
[1]
C.et al.The potential of generative ai for personalized persuasion at scale.Scientific Reports14, 4692 (2024)
Matz, S. C.et al.The potential of generative ai for personalized persuasion at scale.Scientific Reports14, 4692 (2024)
2024
-
[2]
Carrasco-Farre, C. Large language models are as persuasive as humans, but how? about the cognitive effort and moral-emotional language of llm arguments.arXiv preprint arXiv:2404.09329(2024)
-
[3]
G., Muldowney, S., Eichstaedt, J
Bai, H., Voelkel, J. G., Muldowney, S., Eichstaedt, J. C. & Willer, R. Llm-generated messages can persuade humans on policy issues.Nature Communications16, 6037 (2025)
2025
-
[4]
A., Chao, J., Grossman, S., Stamos, A
Goldstein, J. A., Chao, J., Grossman, S., Stamos, A. & Tomz, M. How persuasive is ai- generated propaganda?PNAS nexus3, pgae034 (2024)
2024
-
[5]
& West, R
Salvi, F., Horta Ribeiro, M., Gallotti, R. & West, R. On the conversational persuasiveness of gpt-4.Nature Human Behaviour1–9 (2025)
2025
-
[6]
Argyle, L. P.et al.Leveraging ai for democratic discourse: Chat interventions can improve online political conversations at scale.Proceedings of the National Academy of Sciences120, e2311627120 (2023)
2023
-
[7]
Thepersuasiveeffectsofpoliticalmicrotargeting in the age of generative artificial intelligence.PNAS nexus3, pgae035 (2024)
Simchon, A., Edwards, M.&Lewandowsky, S. Thepersuasiveeffectsofpoliticalmicrotargeting in the age of generative artificial intelligence.PNAS nexus3, pgae035 (2024)
2024
- [8]
- [9]
-
[10]
P.et al.Testing theories of political persuasion using ai.Proceedings of the National Academy of Sciences122, e2412815122 (2025)
Argyle, L. P.et al.Testing theories of political persuasion using ai.Proceedings of the National Academy of Sciences122, e2412815122 (2025)
2025
-
[11]
& Segal, S
Watson, J., Valsesia, F. & Segal, S. Assessing AI receptivity through a persuasion knowledge lens.Current Opinion in Psychology58, 101834 (2024)
2024
-
[12]
& Wang, S
Huang, G. & Wang, S. Is artificial intelligence more persuasive than humans? a meta-analysis. Journal of Communication73, 552–562 (2023)
2023
-
[13]
Brady, O., Nulty, P., Zhang, L., Ward, T. E. & McGovern, D. P. Dual-process theory and decision-making in large language models.Nature Reviews Psychology1–16 (2025)
2025
-
[14]
L., Machacek, M
Blankenship, K. L., Machacek, M. G. & Standefer, J. Resistance strategies and attitude certainty in persuasion: bolstering vs. counterarguing.Frontiers in Psychology14, 1191293 (2023). 15
2023
-
[15]
OpenAIet al.Gpt-4o system card (2024). URLhttps://arxiv.org/abs/2410.21276. 2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Claude 3.7 sonnet system card
Anthropic. Claude 3.7 sonnet system card. Tech. Rep., Anthropic (2025). URLhttps: //www-cdn.anthropic.com/9ff93dfa8f445c932415d335c88852ef47f1201e.pdf. Accessed: 2025-02-24
2025
-
[17]
Liu, A.et al.Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Mistral large: Our new flagship model
Mistral AI. Mistral large: Our new flagship model. Mistral AI Blog (2024). URLhttps: //mistral.ai/news/mistral-large. Accessed: 2025-02-24
2024
-
[19]
E., Epel, E
Adler, N. E., Epel, E. S., Castellazzo, G. & Ickovics, J. R. Relationship of subjective and objective social status with psychological and physiological functioning: Preliminary data in healthy, white women.Health Psychology19, 586–592 (2000). URLhttps://doi.org/10.1 037/0278-6133.19.6.586
2000
- [20]
-
[21]
de Holanda Coelho, G. L., Hanel, P. H. P. & Wolf, L. J. The very efficient assessment of need for cognition: Developing a six-item version*.Assessment27, 1870–1885 (2020). URL https://doi.org/10.1177/1073191118793208. PMID: 30095000,https://doi.org/10.1 177/1073191118793208
-
[22]
& John, O
Rammstedt, B. & John, O. P. Measuring personality in one minute or less: A 10-item short version of the big five inventory in english and german.Journal of Research in Personality 41, 203–212 (2007). URLhttps://www.sciencedirect.com/science/article/pii/S00926 56606000195
2007
-
[23]
Cartwright, E. & Thompson, A. Using dictator game experiments to learn about charitable giving.VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations34, 185–191 (2023). URLhttps://doi.org/10.1007/s11266-022-00490-7. Acknowledgements The authors acknowledge Salvatore Citraro for preparing the CSV files for the data translations. Author Co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.