Recognition: unknown
MIFair: A Mutual-Information Framework for Intersectionality and Multiclass Fairness
Pith reviewed 2026-05-07 07:24 UTC · model grok-4.3
The pith
MIFair uses mutual information to define fairness as statistical independence and enforce it via regularization for intersectional and multiclass settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIFair defines group fairness as the statistical independence between prediction-derived variables and sensitive attributes, quantified by mutual information. It supplies a flexible metric template and an in-processing mitigation method that adds a mutual-information penalty to the training loss, inspired by the Prejudice Remover. Equivalences are established between this mutual-information condition and the classic fairness criteria of independence and separation. The same formulation naturally extends to intersectional subgroups, arbitrary numbers of sensitive attributes, and multiclass prediction without requiring separate case handling.
What carries the argument
Mutual information between sensitive attributes and model outputs or derived variables, serving simultaneously as the fairness metric and the regularization term that is minimized during training to enforce independence.
If this is right
- A single training objective can replace multiple separate fairness methods, enabling direct comparison of different bias notions on the same model.
- Intersectional and multi-attribute fairness become default capabilities rather than special cases requiring custom code.
- Multiclass problems receive the same treatment as binary ones, removing the need for one-versus-rest fairness adjustments.
- Regularization strength becomes a tunable knob that trades predictive performance against the chosen fairness metric in a controlled way.
Where Pith is reading between the lines
- The information-theoretic view may make it easier to combine fairness constraints with other information-based regularizers such as privacy or robustness terms.
- Because the metric is differentiable, gradient-based optimization can be applied to fairness objectives that were previously non-differentiable.
- Auditors could use the same mutual-information quantities to rank which sensitive attributes or subgroups contribute most to bias before mitigation begins.
Load-bearing premise
That enforcing mutual-information independence by regularization during training will produce a fairness guarantee that holds on new data and does not trade off against unmeasured forms of bias or model reliability.
What would settle it
Apply MIFair regularization to a dataset containing documented intersectional bias, measure whether the mutual information between predictions and the sensitive attributes falls to near zero while test accuracy stays within a few percent of an unconstrained baseline; failure on either count would falsify the practical utility claim.
Figures
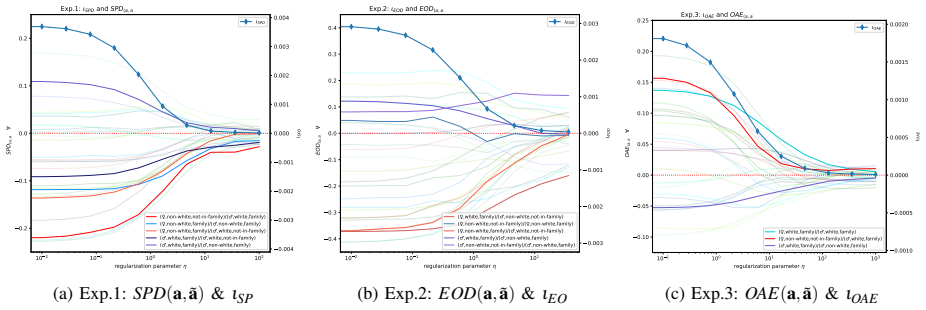
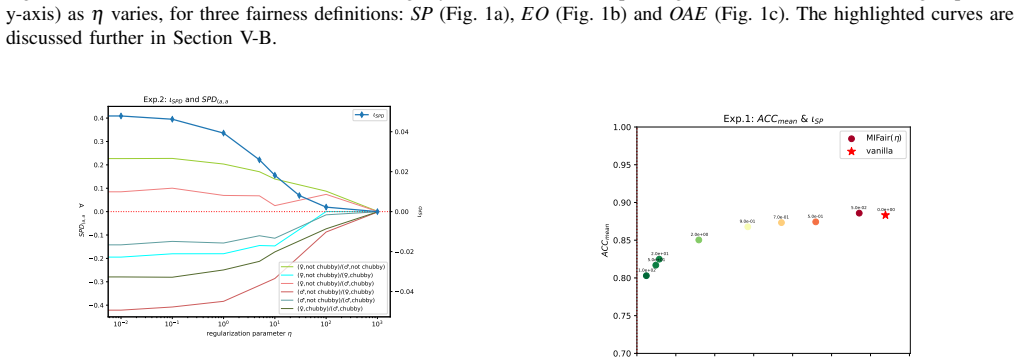


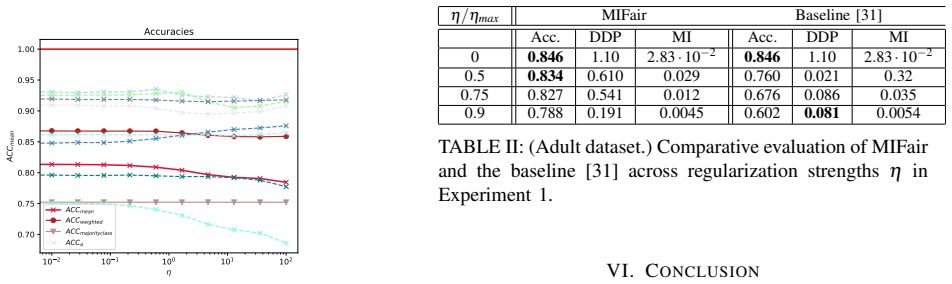
read the original abstract
Fairness in machine learning remains challenging due to its ethical complexity, the absence of a universal definition, and the need for context-specific bias metrics. Existing methods still struggle with intersectionality, multiclass settings, and limited flexibility and generality. To address these gaps, we introduce MIFair, a unified framework for bias assessment and mitigation based on mutual information. MIFair provides a flexible metric template and an in-processing mitigation method inspired by the Prejudice Remover, defining group fairness as statistical independence between prediction-derived variables and sensitive attributes. We further strengthen its information-theoretic foundation by establishing equivalences with widely used fairness notions such as independence and separation. MIFair naturally supports intersectionality, complex subgroup structures, and multiclass classification and employs regularization-based training to reduce bias according to the selected metric. Its key advantage is its versatility: it consolidates diverse fairness requirements into a single coherent framework, enabling consistent benchmarking and simplifying practical use. Experiments on real-world tabular and image datasets show that MIFair effectively reduces bias, including previously unaddressed multi-attribute scenarios, while maintaining strong predictive performance across the evaluated settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIFair, a mutual-information framework for assessing and mitigating bias in machine learning. It defines a flexible metric template based on MI between prediction-derived variables (such as Ŷ) and sensitive attributes (including joint attributes for intersectionality), establishes equivalences between MI=0 conditions and standard fairness notions (independence via I(Ŷ;A)=0 and separation via I(Ŷ;A|Y)=0), and proposes an in-processing regularization method inspired by Prejudice Remover to minimize the chosen MI term during training. The framework is positioned as naturally supporting multiclass classification and complex subgroup structures. Experiments on real-world tabular and image datasets are reported to show effective bias reduction, including in multi-attribute scenarios, while preserving predictive performance.
Significance. If the regularization method reliably drives the population-level MI to zero and the equivalences are rigorously derived, MIFair would offer a coherent, extensible unification of fairness criteria under information theory. This could simplify benchmarking across definitions and enable consistent handling of intersectionality without ad-hoc metric switching. The empirical demonstration on both tabular and image data is a strength, as is the explicit support for multiclass settings. However, the significance is limited by the lack of finite-sample analysis for the MI estimator in sparse intersectional cells, which directly affects whether the claimed practical fairness guarantees hold beyond the specific evaluated datasets.
major comments (3)
- [§3.2] §3.2, the definition of the MIFair metric and the stated equivalences: the claim that I(Ŷ;A)=0 is equivalent to independence and I(Ŷ;A|Y)=0 to separation is presented as a strengthened information-theoretic foundation, yet these are direct consequences of the definition of mutual information (I(X;Y)=0 iff X ⊥ Y). The manuscript should either provide a non-definitional derivation or clarify that this is a restatement, as the central claim of consolidating 'diverse fairness requirements' depends on whether new equivalences or merely a rephrasing are being offered.
- [§4.2] §4.2, the regularization-based training objective: the in-processing method approximates MI (via histogram, kernel, or neural estimator) and adds it as a regularizer, but supplies no finite-sample bounds, bias/variance analysis, or adaptive estimator for the low-count regimes that arise when intersectional subgroups are encoded as a single joint sensitive variable. This is load-bearing for the claim of a 'practically useful fairness guarantee,' because estimator variance in small cells can prevent the regularizer from driving population MI to zero even when the optimization converges.
- [§5.1–5.3] §5.1–5.3, experimental evaluation: the reported bias reductions on tabular and image datasets include no error bars on the fairness metrics, no description of train/validation/test splits or cross-validation procedure, and no statistical significance tests. Without these, it is impossible to determine whether the observed improvements over baselines are robust or could be artifacts of particular data partitions or MI estimator choices, undermining the claim that MIFair 'effectively reduces bias' across settings.
minor comments (3)
- [Abstract] The abstract asserts that MIFair addresses 'previously unaddressed multi-attribute scenarios' without citing the specific prior works that left them unaddressed; adding 1–2 targeted references would clarify the novelty.
- [§3] Notation for prediction-derived variables (Ŷ, etc.) and the precise form of the MI estimator used in training should be introduced explicitly in §3 rather than assumed from context.
- [Figures and Tables] Figure captions and table footnotes should explicitly state the MI estimator (e.g., histogram binning width or neural architecture) employed for each reported metric to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity, rigor, and completeness.
read point-by-point responses
-
Referee: [§3.2] §3.2, the definition of the MIFair metric and the stated equivalences: the claim that I(Ŷ;A)=0 is equivalent to independence and I(Ŷ;A|Y)=0 to separation is presented as a strengthened information-theoretic foundation, yet these are direct consequences of the definition of mutual information (I(X;Y)=0 iff X ⊥ Y). The manuscript should either provide a non-definitional derivation or clarify that this is a restatement, as the central claim of consolidating 'diverse fairness requirements' depends on whether new equivalences or merely a rephrasing are being offered.
Authors: We agree that the equivalences I(Ŷ;A)=0 ⇔ Ŷ ⊥ A and I(Ŷ;A|Y)=0 ⇔ Ŷ ⊥ A|Y follow directly from the definition of mutual information. The manuscript does not claim novel mathematical derivations but rather uses these well-known properties to define a single, flexible metric template that unifies standard fairness notions. This enables consistent handling of intersectionality (via joint attributes) and multiclass settings without switching between disparate metrics. In the revised manuscript, we will explicitly clarify in §3.2 that the equivalences are direct consequences of the MI definition and emphasize that the contribution lies in the unified template and its practical extensibility rather than new equivalences. revision: partial
-
Referee: [§4.2] §4.2, the regularization-based training objective: the in-processing method approximates MI (via histogram, kernel, or neural estimator) and adds it as a regularizer, but supplies no finite-sample bounds, bias/variance analysis, or adaptive estimator for the low-count regimes that arise when intersectional subgroups are encoded as a single joint sensitive variable. This is load-bearing for the claim of a 'practically useful fairness guarantee,' because estimator variance in small cells can prevent the regularizer from driving population MI to zero even when the optimization converges.
Authors: The referee correctly notes the absence of finite-sample bounds or detailed bias/variance analysis for the MI estimators, especially in sparse intersectional cells. Providing rigorous theoretical guarantees for all estimator choices in low-count regimes would require substantial additional work beyond the scope of this paper, which focuses on the framework definition and empirical validation. In the revision, we will add a limitations subsection in §4 discussing the known properties and practical considerations of the histogram, kernel, and neural MI estimators, including their sensitivity to sample size in rare subgroups, and we will recommend using sufficiently large datasets or alternative estimators when intersectional cells are very small. Our experiments demonstrate effective bias reduction on the evaluated datasets, but we acknowledge the theoretical gap for strict population-level guarantees. revision: partial
-
Referee: [§5.1–5.3] §5.1–5.3, experimental evaluation: the reported bias reductions on tabular and image datasets include no error bars on the fairness metrics, no description of train/validation/test splits or cross-validation procedure, and no statistical significance tests. Without these, it is impossible to determine whether the observed improvements over baselines are robust or could be artifacts of particular data partitions or MI estimator choices, undermining the claim that MIFair 'effectively reduces bias' across settings.
Authors: We apologize for these omissions in the initial submission. The revised manuscript will include error bars on all fairness and accuracy metrics (computed across multiple random seeds), a complete description of the train/validation/test splits and any cross-validation or repeated-run procedure, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing MIFair results to baselines. These additions will allow readers to assess the robustness of the reported improvements. revision: yes
- Finite-sample bounds, bias/variance analysis, or adaptive estimators for MI in sparse intersectional regimes
Circularity Check
Equivalences to standard fairness notions are immediate from the definition of mutual information
specific steps
-
self definitional
[Abstract]
"defining group fairness as statistical independence between prediction-derived variables and sensitive attributes. We further strengthen its information-theoretic foundation by establishing equivalences with widely used fairness notions such as independence and separation."
The paper defines fairness as independence and then claims to 'establish' that I(Ŷ;A)=0 corresponds to independence fairness and I(Ŷ;A|Y)=0 to separation. These are tautological: mutual information is zero precisely when the variables are independent, which is how the target fairness notions are defined. No separate proof or first-principles derivation is supplied; the unification is therefore a re-labeling of the definition rather than a derived result.
full rationale
The paper defines group fairness directly as statistical independence (I(Ŷ;A)=0 or I(Ŷ;A|Y)=0) and then presents the 'establishment' of equivalences to independence and separation as strengthening the foundation. These equivalences hold by the standard definition of mutual information and require no additional derivation or assumptions from the paper. The regularization method reduces the chosen MI term by construction of the objective, but the central unification claim rests on this definitional restatement rather than an independent result. No self-citations, fitted predictions on data subsets, or uniqueness theorems appear in the provided text. The practical support for intersectionality via joint attributes and multiclass handling has independent engineering content, keeping the circularity moderate.
Axiom & Free-Parameter Ledger
free parameters (1)
- regularization strength
axioms (2)
- domain assumption Group fairness equals statistical independence between prediction-derived variables and sensitive attributes
- standard math Mutual information is a valid quantitative measure of statistical dependence
invented entities (1)
-
MIFair metric template
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Machine learning fairness notions: Bridging the gap with real-world applications,
K. Makhlouf, S. Zhioua, and C. Palamidessi, “Machine learning fairness notions: Bridging the gap with real-world applications,” Information Processing & Management, 2021
2021
-
[2]
Prediction-based decisions and fairness: A catalogue of choices, assumptions, and definitions,
S. Mitchell, E. Potash, S. Barocas, A. D’Amour, and K. Lum, “Prediction-based decisions and fairness: A catalogue of choices, assumptions, and definitions,”arXiv:1811.07867, 2018
-
[3]
A survey on bias and fairness in machine learning,
N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman, and A. Galstyan, “A survey on bias and fairness in machine learning,”ACM Computing Surveys (CSUR), 2021
2021
-
[4]
Towards the right kind of fairness in AI,
B. Ruf and M. Detyniecki, “Towards the right kind of fairness in AI,” arXiv preprint arXiv:2102.08453, 2021
-
[5]
Barocas, M
S. Barocas, M. Hardt, and A. Narayanan,Fairness and machine learning: Limitations and opportunities. MIT Press, 2023
2023
-
[6]
Al- gorithmic decision making with conditional fairness,
R. Xu, P. Cui, K. Kuang, B. Li, L. Zhou, Z. Shen, and W. Cui, “Al- gorithmic decision making with conditional fairness,” inProceedings of the 26th ACM SIGKDD, 2020
2020
-
[7]
Fairness- aware classifier with prejudice remover regularizer,
T. Kamishima, S. Akaho, H. Asoh, and J. Sakuma, “Fairness- aware classifier with prejudice remover regularizer,” inECML PKDD. Springer, 2012
2012
-
[8]
Fairness in super- vised learning: An information theoretic approach,
A. Ghassami, S. Khodadadian, and N. Kiyavash, “Fairness in super- vised learning: An information theoretic approach,” inIEEE ISIT, 2018
2018
-
[9]
A fair classifier using mutual information,
J. Cho, G. Hwang, and C. Suh, “A fair classifier using mutual information,” inIEEE ISIT, 2020
2020
-
[10]
Enforcing conditional independence for fair representation learning and causal image generation,
J. Hwa, Q. Zhao, A. Lahiri, A. Masood, B. Salimi, and E. Adeli, “Enforcing conditional independence for fair representation learning and causal image generation,” inIEEE/CVF, 2024
2024
-
[11]
Mitigating unwanted biases with adversarial learning,
B. H. Zhang, B. Lemoine, and M. Mitchell, “Mitigating unwanted biases with adversarial learning,” inAAAI/ACM AIES, 2018
2018
-
[12]
Predict responsibly: improving fairness and accuracy by learning to defer,
D. Madras, T. Pitassi, and R. Zemel, “Predict responsibly: improving fairness and accuracy by learning to defer,”NeurIPS, 2018
2018
-
[13]
Adafair: Cumulative fairness adaptive boosting,
V . Iosifidis and E. Ntoutsi, “Adafair: Cumulative fairness adaptive boosting,” inACM CIKM, 2019
2019
-
[14]
Adaptive sensitive reweighting to mitigate bias in fairness- aware classification,
E. Krasanakis, E. Spyromitros-Xioufis, S. Papadopoulos, and Y . Kom- patsiaris, “Adaptive sensitive reweighting to mitigate bias in fairness- aware classification,” inWWW, 2018
2018
-
[15]
Identifying and correcting label bias in machine learning,
H. Jiang and O. Nachum, “Identifying and correcting label bias in machine learning,” inAISTATS, 2020
2020
-
[16]
Wasserstein fair classification,
R. Jiang, A. Pacchiano, T. Stepleton, H. Jiang, and S. Chiappa, “Wasserstein fair classification,” inUAI. PMLR, 2020
2020
-
[17]
Fair generalized linear models with a convex penalty,
H. Do, P. Putzel, A. S. Martin, P. Smyth, and J. Zhong, “Fair generalized linear models with a convex penalty,” inICML. PMLR, 2022
2022
-
[18]
Fairness with overlapping groups; a probabilistic perspective,
F. Yang, M. Cisse, and S. Koyejo, “Fairness with overlapping groups; a probabilistic perspective,”NeurIPS, 2020
2020
-
[19]
Gender shades: Intersectional accuracy disparities in commercial gender classification,
J. Buolamwini and T. Gebru, “Gender shades: Intersectional accuracy disparities in commercial gender classification,” inConference on fairness, accountability and transparency. PMLR, 2018
2018
-
[20]
Improved adversarial learning for fair classification,
L. E. Celis and V . Keswani, “Improved adversarial learning for fair classification,”arXiv preprint arXiv:1901.10443, 2019
-
[21]
Data preprocessing techniques for clas- sification without discrimination,
F. Kamiran and T. Calders, “Data preprocessing techniques for clas- sification without discrimination,”KAIS, 2012
2012
-
[22]
Fairness through awareness,
C. Dwork, M. Hardt, T. Pitassi, O. Reingold, and R. Zemel, “Fairness through awareness,” inProceedings of the 3rd innovations in theoret- ical computer science conference, 2012
2012
-
[23]
Equality of opportunity in supervised learning,
M. Hardt, E. Price, and N. Srebro, “Equality of opportunity in supervised learning,”NeurIPS, 2016
2016
-
[24]
Algorithmic decision making and the cost of fairness,
S. Corbett-Davies, E. Pierson, A. Feller, S. Goel, and A. Huq, “Algorithmic decision making and the cost of fairness,” inProceedings of the 23rd ACM SIGKDD, 2017
2017
-
[25]
Fairness in criminal justice risk assessments: The state of the art,
R. Berk, H. Heidari, S. Jabbari, M. Kearns, and A. Roth, “Fairness in criminal justice risk assessments: The state of the art,”Sociological Methods & Research, 2021
2021
-
[26]
Preventing fairness gerrymandering: Auditing and learning for subgroup fairness,
M. Kearns, S. Neel, A. Roth, and Z. S. Wu, “Preventing fairness gerrymandering: Auditing and learning for subgroup fairness,” in ICML, 2018
2018
-
[27]
Mutual information neural estimation,
M. I. Belghazi, A. Baratin, S. Rajeshwar, S. Ozair, Y . Bengio, A. Courville, and D. Hjelm, “Mutual information neural estimation,” inICML. PMLR, 2018
2018
-
[28]
Becker and R
B. Becker and R. Kohavi, “Adult,”UCI Mach. Learning Repository, 1996
1996
-
[29]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inIEEE ICCV, 2015
2015
-
[30]
Aequitas: A Bias and Fairness Audit Toolkit
P. Saleiro, B. Kuester, L. Hinkson, J. London, A. Stevens, A. Anisfeld, K. T. Rodolfa, and R. Ghani, “Aequitas: A bias and fairness audit toolkit,” 2019. [Online]. Available: https://arxiv.org/abs/1811.05577
work page Pith review arXiv 2019
-
[31]
A fair classifier using kernel density estimation,
J. Cho, G. Hwang, and C. Suh, “A fair classifier using kernel density estimation,”Advances in NeurIPS, 2020
2020
-
[32]
Beyond base metric: The critical and overlooked role of meta-metrics in intersectional fairness,
J. Monnier, T. George, F. Guyard, C. Tarnec, and M. Kountouris, “Beyond base metric: The critical and overlooked role of meta-metrics in intersectional fairness,” in2026 ACM Conference on Fairness Accountability and Transparency, ser. FAccT ’26. ACM, 2026. [Online]. Available: https://doi.org/10.1145/3805689.3812417 VII. APPENDIX A. Proofs of equivalence ...
-
[33]
vanilla model
Adult:We use a two-layer fully connected neural network with one hidden layer of 16 neurons and a softmax output, trained using cross-entropy loss. Training runs for up to 500 epochs, using the full training set as a single batch to ensure adequate subgroup representation. We employ SGD with momentumµ=0.8 and an L2 weight decay of 0.1. For the regularizat...
-
[34]
CelebA:CelebA contains 202,600 face images with metadata providing numerous attributes, including sensitive ones. We consider two binary sensitive attributes—Maleand Chubby—and predict theSmilingattribute in Task 1 and Blond Hair,Brown HairandBlack Hairattributes that we encode in one multi categorical attributeHair colorin Task
-
[35]
The dataset is highly imbalanced across demographic groups; for example, theFemale,Non−Chubbysubgroup has hundreds of times more samples than theFemale,Chubbysubgroup
We fine-tune a ResNet18 model from PyTorch for 15 epochs, using 8,000 training images per epoch. The dataset is highly imbalanced across demographic groups; for example, theFemale,Non−Chubbysubgroup has hundreds of times more samples than theFemale,Chubbysubgroup
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.