Recognition: unknown
FreeOcc: Training-Free Embodied Open-Vocabulary Occupancy Prediction
Pith reviewed 2026-05-07 05:49 UTC · model grok-4.3
The pith
FreeOcc predicts open-vocabulary 3D occupancy from video without any training, 3D labels, or known camera poses by combining SLAM, dense Gaussian maps, and vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
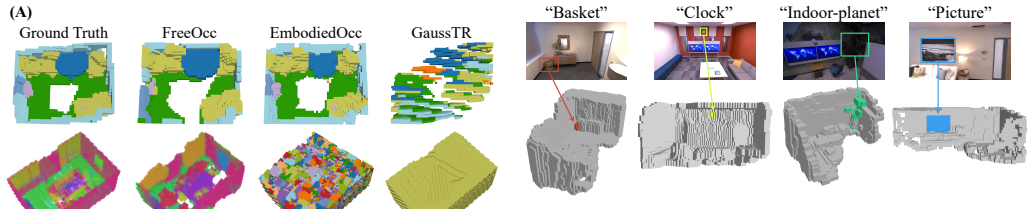
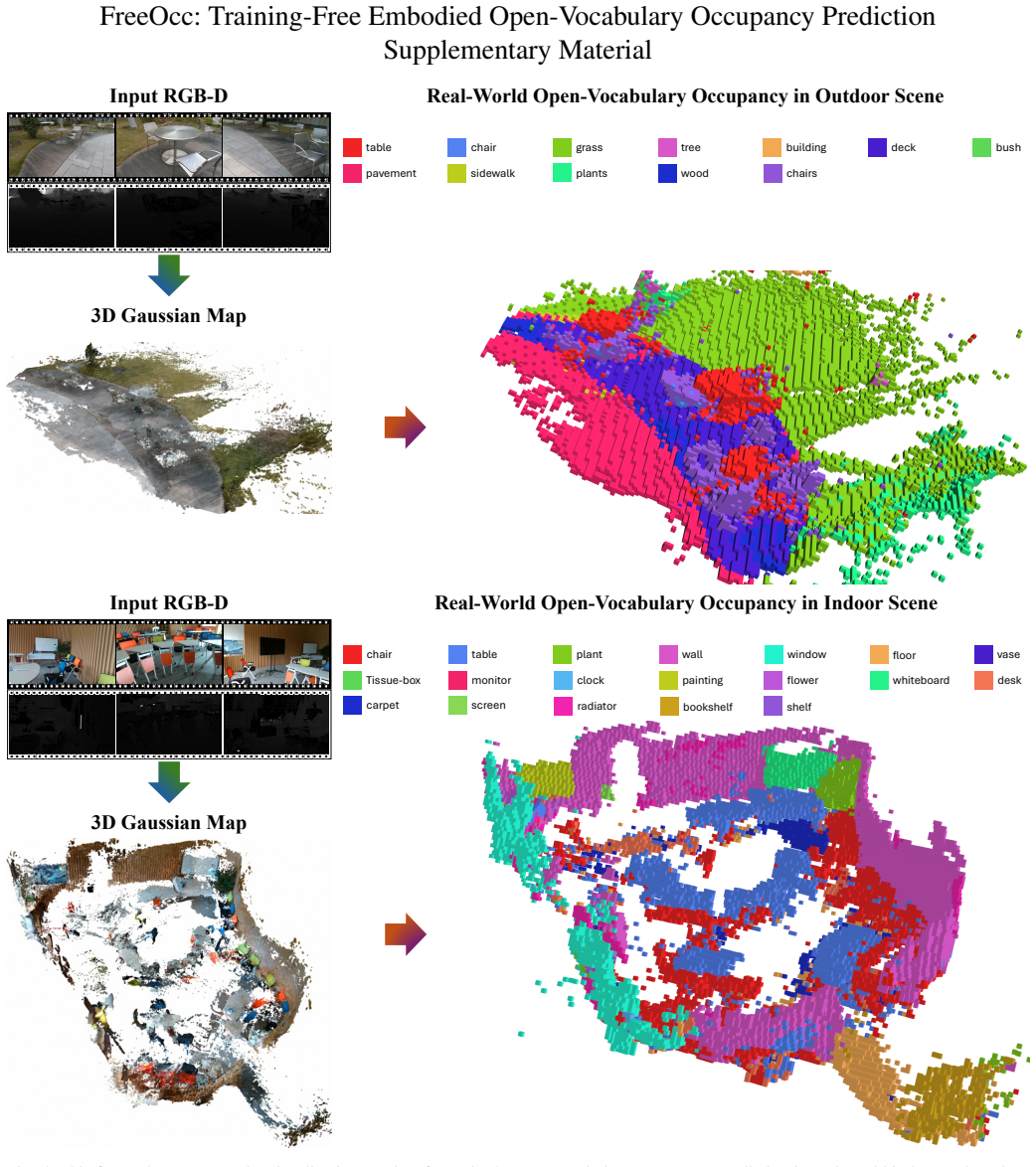
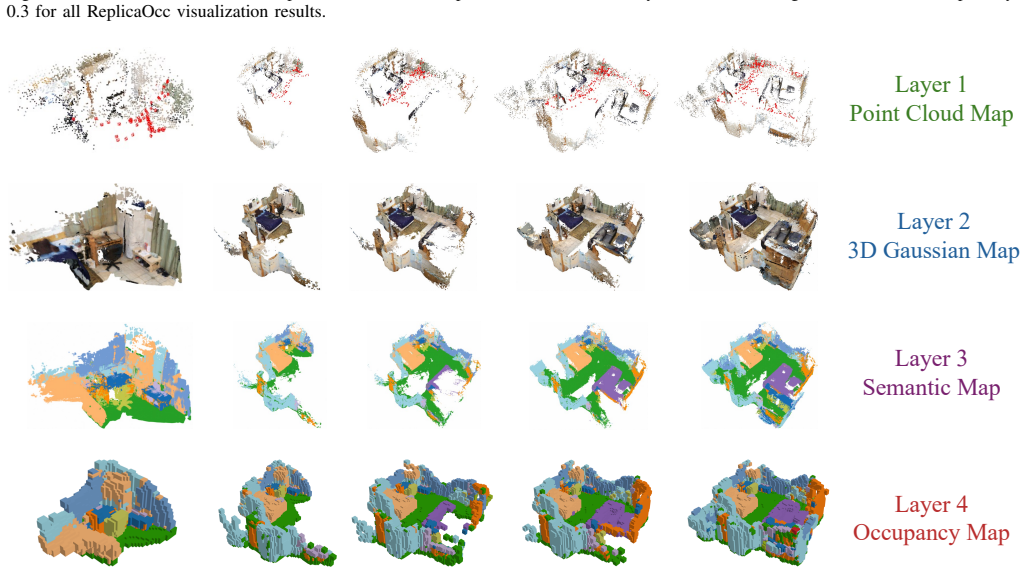
FreeOcc incrementally builds a globally consistent occupancy map from monocular or RGB-D sequences without training or pose supervision. A SLAM backbone supplies poses and sparse geometry; geometrically consistent updates then produce a dense 3D Gaussian map; open-vocabulary semantics from vision-language models are associated with the Gaussian primitives; and probabilistic projection converts the map into dense voxel occupancy. On EmbodiedOcc-ScanNet this yields more than twice the IoU and mIoU of prior self-supervised methods. The work also introduces the ReplicaOcc benchmark and shows that the same pipeline transfers zero-shot to novel indoor environments while outperforming both trained,
What carries the argument
The central mechanism is the association of vision-language model outputs with 3D Gaussian primitives, followed by probabilistic Gaussian-to-occupancy projection, all constructed on top of SLAM-derived poses and sparse geometry.
If this is right
- Occupancy maps with open-vocabulary semantics can be generated in real time from standard camera streams without collecting environment-specific 3D annotations.
- The same pipeline supports both monocular video and RGB-D input and produces globally consistent maps across long sequences.
- Zero-shot transfer to entirely new indoor scenes is possible, with performance exceeding that of methods trained on the target environment.
- A new benchmark, ReplicaOcc, is provided to enable standardized comparison of open-vocabulary occupancy methods in indoor settings.
- No voxel-level supervision or pose ground truth is required at any stage of training or inference.
Where Pith is reading between the lines
- Modular composition of existing SLAM and vision-language tools may replace end-to-end learned models for many geometric perception tasks in robotics.
- Substituting stronger off-the-shelf SLAM or grounding components into the same four-layer structure could raise accuracy without redesigning the pipeline.
- The Gaussian representation may directly support downstream tasks such as obstacle avoidance or semantic navigation without converting to voxels first.
- Deployment in varied real-world settings becomes feasible because no 3D data collection or per-environment retraining is needed.
Load-bearing premise
An off-the-shelf SLAM system must supply sufficiently accurate poses and sparse geometry, and unmodified vision-language models must correctly label the 3D Gaussian primitives, all without domain adaptation or ground-truth supervision.
What would settle it
If a controlled test on ReplicaOcc shows that a supervised baseline trained with full 3D labels on the same scenes achieves higher mIoU than FreeOcc under identical evaluation conditions, the claim that training-free methods can substantially outperform supervised ones would be contradicted.
Figures




read the original abstract
Existing learning-based occupancy prediction methods rely on large-scale 3D annotations and generalize poorly across environments. We present FreeOcc, a training-free framework for open-vocabulary occupancy prediction from monocular or RGB-D sequences. Unlike prior approaches that require voxel-level supervision and ground-truth camera poses, FreeOcc operates without 3D annotations, pose ground truth, or any learning stage. FreeOcc incrementally builds a globally consistent occupancy map via a four-layer pipeline: a SLAM backbone estimates poses and sparse geometry; a geometrically consistent Gaussian update constructs dense 3D Gaussian maps; open-vocabulary semantics from off-the-shelf vision-language models are associated with Gaussian primitives; and a probabilistic Gaussian-to-occupancy projection produces dense voxel occupancy. Despite being entirely training-free and pose-agnostic, FreeOcc achieves over $2\times$ improvements in IoU and mIoU on EmbodiedOcc-ScanNet compared to prior self-supervised methods. We further introduce ReplicaOcc, a benchmark for indoor open-vocabulary occupancy prediction, and show that FreeOcc transfers zero-shot to novel environments, substantially outperforming both supervised and self-supervised baselines. Project page: https://the-masses.github.io/freeocc-web/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FreeOcc, a training-free and pose-agnostic framework for embodied open-vocabulary occupancy prediction from monocular or RGB-D sequences. It builds a globally consistent occupancy map via a four-layer pipeline: an off-the-shelf SLAM backbone for poses and sparse geometry, a geometrically consistent Gaussian update to construct dense 3D Gaussian maps, association of open-vocabulary semantics from vision-language models to the Gaussian primitives, and a probabilistic Gaussian-to-occupancy projection to obtain dense voxel labels. The central claims are over 2× gains in IoU and mIoU on EmbodiedOcc-ScanNet versus prior self-supervised methods, introduction of the ReplicaOcc benchmark, and strong zero-shot transfer to novel environments that outperforms both supervised and self-supervised baselines.
Significance. If the performance claims are substantiated with proper validation, the result would be significant for robotics and 3D perception: it removes the requirement for large-scale 3D annotations and any training stage, potentially enabling rapid deployment and better cross-environment generalization. The ReplicaOcc benchmark is a constructive addition that could standardize evaluation for open-vocabulary occupancy. The approach's modularity with pre-trained components is attractive, but its success hinges on the untested accuracy of those components in the target domains.
major comments (2)
- [Abstract] Abstract: the claim of 'over 2× improvements in IoU and mIoU on EmbodiedOcc-ScanNet compared to prior self-supervised methods' is presented without naming the baselines, reporting their exact scores, or stating FreeOcc's precise metric values. This detail is load-bearing for the central superiority claim and must be supplied with a clear comparison table.
- [Section 3] Section 3 (Pipeline description): the method assumes the SLAM backbone supplies sufficiently accurate incremental poses and sparse geometry so that the Gaussian update yields reliable 3D primitives, and that VLM outputs can be reliably associated with those primitives for the probabilistic projection step. No pose-error statistics, association precision-recall figures, or ablation that removes the projection are provided; any drift or label noise would directly corrupt the occupancy map with no correction mechanism, directly threatening the no-training and zero-shot claims.
minor comments (2)
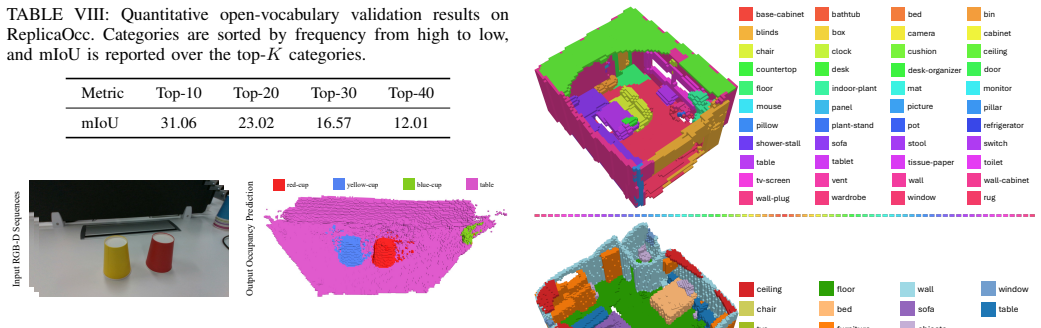
- [Experiments] The ReplicaOcc benchmark introduction would benefit from explicit statistics on scene count, diversity, and annotation protocol to support reproducibility.
- [Method] Notation for the probabilistic projection (e.g., how Gaussian covariances are mapped to voxel occupancy probabilities) should be formalized with an equation to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for clarification and strengthening of the quantitative claims and robustness analysis. We address each major comment below and will incorporate revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'over 2× improvements in IoU and mIoU on EmbodiedOcc-ScanNet compared to prior self-supervised methods' is presented without naming the baselines, reporting their exact scores, or stating FreeOcc's precise metric values. This detail is load-bearing for the central superiority claim and must be supplied with a clear comparison table.
Authors: We agree that the abstract's high-level summary of the 'over 2×' gains would benefit from explicit quantitative grounding. In the revised manuscript, we will update the abstract to name the specific prior self-supervised baselines used in our experiments, report FreeOcc's exact IoU and mIoU values alongside those of the baselines, and add a clear comparison table (new Table 1 in Section 4) that lists all relevant metrics, dataset splits, and methods. The abstract will then reference this table to support the superiority claim while preserving brevity. revision: yes
-
Referee: [Section 3] Section 3 (Pipeline description): the method assumes the SLAM backbone supplies sufficiently accurate incremental poses and sparse geometry so that the Gaussian update yields reliable 3D primitives, and that VLM outputs can be reliably associated with those primitives for the probabilistic projection step. No pose-error statistics, association precision-recall figures, or ablation that removes the projection are provided; any drift or label noise would directly corrupt the occupancy map with no correction mechanism, directly threatening the no-training and zero-shot claims.
Authors: We acknowledge the importance of validating the intermediate components, particularly given the training-free nature of the approach. While the strong end-to-end results—including zero-shot transfer to ReplicaOcc that outperforms supervised baselines—provide indirect evidence of robustness, we will strengthen Section 3 and the Experiments section with additional analysis. Specifically, we will report pose-error statistics (ATE/RPE) from the SLAM backbone on both EmbodiedOcc-ScanNet and ReplicaOcc; include qualitative and quantitative examples of VLM-to-Gaussian association; and add an ablation comparing the full probabilistic projection against a direct voxelization baseline. These additions rely on post-processing of existing outputs and do not require retraining or new data collection. revision: yes
Circularity Check
No circularity: pipeline composes independent external modules
full rationale
The paper presents FreeOcc as a four-layer pipeline that chains an off-the-shelf SLAM backbone for poses and sparse geometry, a geometrically consistent Gaussian update, association of open-vocabulary VLM outputs to Gaussian primitives, and a probabilistic Gaussian-to-occupancy projection. None of these steps reduce by construction to fitted parameters from the evaluation data, self-referential definitions, or load-bearing self-citations. The claimed 2× IoU/mIoU gains and zero-shot transfer are reported as empirical outcomes of applying this composition to EmbodiedOcc-ScanNet and ReplicaOcc, not as quantities forced by the inputs themselves. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a way that collapses the derivation chain. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Off-the-shelf SLAM backbones can produce sufficiently accurate camera poses and sparse geometry from monocular or RGB-D sequences for global map consistency
- domain assumption Pre-trained vision-language models can assign reliable open-vocabulary semantics to 3D Gaussian primitives in a geometrically consistent manner
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Langocc: Open vocabulary occupancy estimation via volume rendering
Simon Boeder, Fabian Gigengack, and Benjamin Risse. Langocc: Open vocabulary occupancy estimation via volume rendering. InInternational Conference on 3D Vision 2025, 2025
2025
-
[3]
Gaussianflowocc: Sparse and weakly supervised occu- pancy estimation using gaussian splatting and temporal flow, 2025
Simon Boeder, Fabian Gigengack, and Benjamin Risse. Gaussianflowocc: Sparse and weakly supervised occu- pancy estimation using gaussian splatting and temporal flow, 2025
2025
-
[4]
Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses
Eric Brachmann, Tommaso Cavallari, and Victor Adrian Prisacariu. Accelerated coordinate encoding: Learning to relocalize in minutes using rgb and poses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[5]
Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age.IEEE Transactions on robotics, 32(6):1309–1332, 2017
Cesar Cadena, Luca Carlone, Henry Carrillo, Yasir Latif, Davide Scaramuzza, Jos ´e Neira, Ian Reid, and John J Leonard. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age.IEEE Transactions on robotics, 32(6):1309–1332, 2017
2017
-
[6]
Monoscene: Monocular 3d semantic scene completion
Anh-Quan Cao and Raoul De Charette. Monoscene: Monocular 3d semantic scene completion. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3991–4001, 2022
2022
-
[7]
Representation, display, and manipulation of 3d digital scenes and their medical applications.Computer Vision, Graphics, and Image Processing, 48(2):190–216, 1989
Lih-Shyang Chen and Marc R Sontag. Representation, display, and manipulation of 3d digital scenes and their medical applications.Computer Vision, Graphics, and Image Processing, 48(2):190–216, 1989
1989
-
[8]
Chang, Manolis Savva, Ma- ciej Halber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Ma- ciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2017
2017
-
[9]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[10]
What is the best 3d scene representation for robotics? from geometric to foundation models, 2026
Tianchen Deng, Yue Pan, Shenghai Yuan, Dong Li, Chen Wang, Mingrui Li, Long Chen, Lihua Xie, Danwei Wang, Jingchuan Wang, Javier Civera, Hesheng Wang, and Weidong Chen. What is the best 3d scene representation for robotics? from geometric to foundation models, 2026
2026
-
[11]
3d gaussian splatting as new era: A survey.IEEE Transactions on Visualization and Computer Graphics, 2024
Ben Fei, Jingyi Xu, Rui Zhang, Qingyuan Zhou, Wei- dong Yang, and Ying He. 3d gaussian splatting as new era: A survey.IEEE Transactions on Visualization and Computer Graphics, 2024
2024
-
[12]
Ef- ficient prediction of dense visual embeddings via distil- lation and rgb-d transformers
S ¨ohnke Benedikt Fischedick, Daniel Seichter, Benedict Stephan, Robin Schmidt, and Horst-Michael Gross. Ef- ficient prediction of dense visual embeddings via distil- lation and rgb-d transformers. In2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems, pages 2400–2407. IEEE, 2025
2025
-
[13]
Back- to-front display of voxel based objects.IEEE Computer Graphics and Applications, 5(01):52–60, 1985
Gideon Frieder, Dan Gordon, and R Reynolds. Back- to-front display of voxel based objects.IEEE Computer Graphics and Applications, 5(01):52–60, 1985
1985
-
[14]
Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting
Wanshui Gan, Fang Liu, Hongbin Xu, Ningkai Mo, and Naoto Yokoya. Gaussianocc: Fully self-supervised and efficient 3d occupancy estimation with gaussian splatting. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[15]
Yuhang Gao, Xiang Xiang, Sheng Zhong, and Guoyou Wang. Loc: A general language-guided framework for open-set 3d occupancy prediction.arXiv preprint arXiv:2510.22141, 2025
-
[16]
evo: Python package for the evaluation of odometry and slam
Michael Grupp. evo: Python package for the evaluation of odometry and slam. https://github.com/MichaelGrupp/ evo, 2017
2017
-
[17]
Rgbd gs- icp slam
Seongbo Ha, Jiung Yeon, and Hyeonwoo Yu. Rgbd gs- icp slam. InEuropean Conference on Computer Vision, page 180–197. Springer, 2020
2020
-
[18]
Droid-splat combining end-to-end slam with 3d gaussian splatting
Christian Homeyer, Leon Begiristain, and Christoph Schn¨orr. Droid-splat combining end-to-end slam with 3d gaussian splatting. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision Workshops, 2025
2025
-
[19]
Wurm, Maren Bennewitz, Cyrill Stachniss, and Wolfram Burgard
Armin Hornung, Kai M. Wurm, Maren Bennewitz, Cyrill Stachniss, and Wolfram Burgard. OctoMap: An ef- ficient probabilistic 3D mapping framework based on octrees.Autonomous Robots, 2013. doi: 10.1007/ s10514-012-9321-0
2013
-
[20]
Yan Song Hu, Nicolas Abboud, Muhammad Qasim Ali, Adam Srebrnjak Yang, Imad Elhajj, Daniel Asmar, Yuhao Chen, and John S. Zelek. Mgso: Monocular real-time photometric slam with efficient 3d gaussian splatting. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11061–11067,
-
[21]
doi: 10.1109/ICRA55743.2025.11127380
-
[22]
Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular stereo and rgb- d cameras
Huajian Huang, Longwei Li, Hui Cheng, and Sai-Kit Yeung. Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular stereo and rgb- d cameras. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[23]
Tri-perspective view for vision- based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for vision- based 3d semantic occupancy prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9223–9232, 2023
2023
-
[24]
Selfocc: Self-supervised vision-based 3d occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Borui Zhang, Jie Zhou, and Jiwen Lu. Selfocc: Self-supervised vision-based 3d occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[25]
Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction
Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. In European Conference on Computer Vision, pages 376–
-
[26]
Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction
Yuanhui Huang, Amonnut Thammatadatrakoon, Wen- zhao Zheng, Yunpeng Zhang, Dalong Du, and Jiwen Lu. Gaussianformer-2: Probabilistic gaussian superposition for efficient 3d occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27477–27486, 2025
2025
-
[27]
Yiming Ji, Yang Liu, Guanghu Xie, Boyu Ma, Zongwu Xie, and Hong Liu. Neds-slam: A neural explicit dense semantic slam framework using 3d gaussian splat- ting.IEEE Robotics and Automation Letters, 9(10): 8778–8785, October 2024. ISSN 2377-3774. doi: 10.1109/lra.2024.3451390
-
[28]
Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding
Haoyi Jiang, Liu Liu, Tianheng Cheng, Xinjie Wang, Tianwei Lin, Zhizhong Su, Wenyu Liu, and Xinggang Wang. Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2025
2025
-
[29]
Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding
Haoyi Jiang, Liu Liu, Tianheng Cheng, Xinjie Wang, Tianwei Lin, Zhizhong Su, Wenyu Liu, and Xinggang Wang. Gausstr: Foundation model-aligned gaussian transformer for self-supervised 3d spatial understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[30]
Splatam: Splat track & map 3d gaussians for dense rgb-d slam
Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallab- hula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon Luiten. Splatam: Splat track & map 3d gaussians for dense rgb-d slam. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[31]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139– 1, 2023
2023
-
[32]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[33]
Gaussian-lic: Real-time photo-realistic slam with gaus- sian splatting and lidar-inertial-camera fusion
Xiaolei Lang, Laijian Li, Chenming Wu, Chen Zhao, Lina Liu, Yong Liu, Jiajun Lv, and Xingxing Zuo. Gaussian-lic: Real-time photo-realistic slam with gaus- sian splatting and lidar-inertial-camera fusion. In2025 International Conference on Robotics and Automation. IEEE, 2025
2025
-
[34]
Gaussian-lic2: Lidar-inertial-camera gaussian splatting slam.arXiv preprint arXiv:2507.04004, 2025
Xiaolei Lang, Jiajun Lv, Kai Tang, Laijian Li, Jianxin Huang, Lina Liu, Yong Liu, and Xingxing Zuo. Gaussian-lic2: Lidar-inertial-camera gaussian splatting slam.arXiv preprint arXiv:2507.04004, 2025
-
[35]
Self-supervised multi-future occupancy forecasting for autonomous driving.Robotics: Science and Systems, 2025
Bernard Lange, Masha Itkina, Jiachen Li, and Mykel Kochenderfer. Self-supervised multi-future occupancy forecasting for autonomous driving.Robotics: Science and Systems, 2025
2025
-
[36]
Pg-slam: Photo- realistic and geometry-aware rgb-d slam in dynamic environments.IEEE Transactions on Robotics, 2025
Haoang Li, Xiangqi Meng, Xingxing Zuo, Zhe Liu, Hesheng Wang, and Daniel Cremers. Pg-slam: Photo- realistic and geometry-aware rgb-d slam in dynamic environments.IEEE Transactions on Robotics, 2025
2025
-
[37]
Gs3lam: Gaussian semantic splatting slam
Linfei Li, Lin Zhang, Zhong Wang, and Ying Shen. Gs3lam: Gaussian semantic splatting slam. InPro- ceedings of the 32nd ACM International Conference on Multimedia, MM ’24, page 3019–3027, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[38]
Sgs- slam: Semantic gaussian splatting for neural dense slam
Mingrui Li, Shuhong Liu, Heng Zhou, Guohao Zhu, Na Cheng, Tianchen Deng, and Hongyu Wang. Sgs- slam: Semantic gaussian splatting for neural dense slam. InEuropean Conference on Computer Vision, pages 163–
-
[39]
Ago: Adaptive grounding for open world 3d occupancy prediction
Peizheng Li, Shuxiao Ding, You Zhou, Qingwen Zhang, Onat Inak, Larissa Triess, Niklas Hanselmann, Marius Cordts, and Andreas Zell. Ago: Adaptive grounding for open world 3d occupancy prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8645–8655, October 2025
2025
-
[40]
Enhancing indoor occupancy prediction via sparse query-based multi-level consistent knowledge distillation.IEEE Robotics and Automation Letters, 2025
Xiang Li, Yupeng Zheng, Pengfei Li, Yilun Chen, Ya-Qin Zhang, and Wenchao Ding. Enhancing indoor occupancy prediction via sparse query-based multi-level consistent knowledge distillation.IEEE Robotics and Automation Letters, 2025
2025
-
[41]
V oxformer: Sparse voxel trans- former for camera-based 3d semantic scene completion
Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M Alvarez, Sanja Fidler, Chen Feng, and Anima Anandkumar. V oxformer: Sparse voxel trans- former for camera-based 3d semantic scene completion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9087–9098, 2023
2023
-
[42]
Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, and Jose M Alvarez. FB-OCC: 3D occupancy prediction based on forward-backward view transformation.arXiv:2307.01492, 2023
-
[43]
Octreeocc: Efficient and multi-granularity occupancy prediction using octree queries.Advances in Neural Information Processing Systems, 37:79618–79641, 2024
Yuhang Lu, Xinge Zhu, Tai Wang, and Yuexin Ma. Octreeocc: Efficient and multi-granularity occupancy prediction using octree queries.Advances in Neural Information Processing Systems, 37:79618–79641, 2024
2024
-
[44]
Clins: Continuous-time trajectory estimation for lidar-inertial system
Jiajun Lv, Kewei Hu, Jinhong Xu, Yong Liu, Xiushui Ma, and Xingxing Zuo. Clins: Continuous-time trajectory estimation for lidar-inertial system. In2021 IEEE/RSJ International Conference on Intelligent Robots and Sys- tems, pages 6657–6663. IEEE, 2021
2021
-
[45]
Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.Advances in Neural Information Processing Systems, 39, 2025
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.Advances in Neural Information Processing Systems, 39, 2025
2025
-
[46]
Hidenobu Matsuki, Riku Murai, Paul H. J. Kelly, and Andrew J. Davison. Gaussian Splatting SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[47]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: representing scenes as neural radiance fields for view synthesis.Commun. ACM, 65(1):99–106, December
- [48]
-
[49]
Ra ´ul Mur-Artal and Juan D. Tard ´os. ORB-SLAM2: an open-source SLAM system for monocular, stereo and RGB-D cameras.IEEE Transactions on Robotics, 33 (5):1255–1262, 2017. doi: 10.1109/TRO.2017.2705103
-
[50]
Riku Murai, Eric Dexheimer, and Andrew J. Davison. MASt3R-SLAM: Real-time dense SLAM with 3D re- construction priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[51]
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fer- nandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El- Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Pa...
2024
-
[52]
Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision
Mingjie Pan, Jiaming Liu, Renrui Zhang, Peixiang Huang, Xiaoqi Li, Hongwei Xie, Bing Wang, Li Liu, and Shanghang Zhang. Renderocc: Vision-centric 3d occupancy prediction with 2d rendering supervision. In 2024 IEEE International Conference on Robotics and Automation, pages 12404–12411. IEEE, 2024
2024
-
[53]
Pings: Gaussian splatting meets distance fields within a point- based implicit neural map.Robotics: Science and Sys- tems, 2025
Yue Pan, Xingguang Zhong, Liren Jin, Louis Wiesmann, Marija Popovic, Jens Behley, and Cyrill Stachniss. Pings: Gaussian splatting meets distance fields within a point- based implicit neural map.Robotics: Science and Sys- tems, 2025
2025
-
[54]
Rtg-slam: Real- time 3d reconstruction at scale using gaussian splatting
Zhexi Peng, Tianjia Shao, Liu Yong, Jingke Zhou, Yin Yang, Jingdong Wang, and Kun Zhou. Rtg-slam: Real- time 3d reconstruction at scale using gaussian splatting. ACM SIGGRAPH Conference Proceedings, Denver , CO, United States, July 28 - August 1, 2024, 2024
2024
-
[55]
Mason Peterson, Yixuan Jia, Yulun Tian, Annika Thomas, and Jonathan P. How. Roman: Open-set object map alignment for robust view-invariant global localiza- tion.Robotics: Science and Systems, 2025
2025
-
[56]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InEuropean conference on computer vision, pages 194–210. Springer, 2020
2020
-
[57]
Self-evolving depth-supervised 3d gaussian splatting from rendered stereo pairs, 2024
Matteo Poggi, Fabio Tosi, Fatma G ¨uney, and Sadra Safadoust. Self-evolving depth-supervised 3d gaussian splatting from rendered stereo pairs, 2024
2024
-
[58]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021
2021
-
[59]
Structure-from-motion revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[60]
Language embedded 3d gaussians for open- vocabulary scene understanding
Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao- Hua Guan. Language embedded 3d gaussians for open- vocabulary scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5333–5343, 2024
2024
-
[61]
Occupancy as set of points
Yiang Shi, Tianheng Cheng, Qian Zhang, Wenyu Liu, and Xinggang Wang. Occupancy as set of points. In European Conference on Computer Vision, pages 72–87. Springer, 2024
2024
-
[62]
Yuheng Shi, Minjing Dong, and Chang Xu. Harnessing vision foundation models for high-performance, training- free open vocabulary segmentation.arXiv preprint arXiv:2411.09219, 2024
-
[63]
Semantic scene completion from a single depth image.arXiv preprint arXiv:1611.08974, 2016
Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image.arXiv preprint arXiv:1611.08974, 2016
-
[64]
Semantic scene completion from a single depth image
Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1746–1754, 2017
2017
-
[65]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur- Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review arXiv 1906
-
[66]
LoFTR: Detector-free local fea- ture matching with transformers.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. LoFTR: Detector-free local fea- ture matching with transformers.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[67]
Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction
Pin Tang, Zhongdao Wang, Guoqing Wang, Jilai Zheng, Xiangxuan Ren, Bailan Feng, and Chao Ma. Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15035–15044, 2024
2024
-
[68]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean Conference on Computer Vision, pages 402–419. Springer, 2020
2020
-
[69]
DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras.Ad- vances in neural information processing systems, 2021
Zachary Teed and Jia Deng. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras.Ad- vances in neural information processing systems, 2021
2021
-
[70]
The interpretation of structure from motion.Proceedings of the Royal Society of London
Shimon Ullman. The interpretation of structure from motion.Proceedings of the Royal Society of London. Series B. Biological Sciences, 203(1153):405–426, 1979
1979
-
[71]
Sags: Structure-aware 3d gaussian splatting
Evangelos Ververas, Rolandos Alexandros Potamias, Jifei Song, Jiankang Deng, and Stefanos Zafeiriou. Sags: Structure-aware 3d gaussian splatting. InEuropean Con- ference on Computer Vision, pages 221–238. Springer, 2024
2024
-
[72]
Pop-3d: Open-vocabulary 3d occupancy prediction from images.Advances in Neural Information Processing Systems, 36:50545–50557, 2023
Antonin V obecky, Oriane Sim´eoni, David Hurych, Spyri- don Gidaris, Andrei Bursuc, Patrick P ´erez, and Josef Sivic. Pop-3d: Open-vocabulary 3d occupancy prediction from images.Advances in Neural Information Processing Systems, 36:50545–50557, 2023
2023
-
[73]
Semantic scene completion with cleaner self
Fengyun Wang, Dong Zhang, Hanwang Zhang, Jinhui Tang, and Qianru Sun. Semantic scene completion with cleaner self. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 867– 877, 2023
2023
-
[74]
Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regularization and uncertainty sampler
Hao Wang, Xiaobao Wei, Xiaoan Zhang, Jianing Li, Chengyu Bai, Ying Li, Ming Lu, Wenzhao Zheng, and Shanghang Zhang. Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regularization and uncertainty sampler. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 925–934, New York, NY , USA, 2025. Association for...
2025
-
[75]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 21729–21740, 2023
2023
-
[76]
Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding
Yuqi Wu, Wenzhao Zheng, Sicheng Zuo, Yuanhui Huang, Jie Zhou, and Jiwen Lu. Embodiedocc: Embodied 3d occupancy prediction for vision-based online scene understanding. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), pages 26360–26370, October 2025
2025
-
[77]
Gs-slam: Dense visual slam with 3d gaussian splatting
Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li. Gs-slam: Dense visual slam with 3d gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[78]
Opengs-slam: Open-set dense semantic slam with 3d gaussian splatting for object-level scene understanding, 2025
Dianyi Yang, Yu Gao, Xihan Wang, Yufeng Yue, Yi Yang, and Mengyin Fu. Opengs-slam: Open-set dense semantic slam with 3d gaussian splatting for object-level scene understanding, 2025
2025
-
[79]
Ndc-scene: Boost monocular 3d semantic scene completion in normalized device coordinates space
Jiawei Yao, Chuming Li, Keqiang Sun, Yingjie Cai, Hao Li, Wanli Ouyang, and Hongsheng Li. Ndc-scene: Boost monocular 3d semantic scene completion in normalized device coordinates space. In2023 IEEE/CVF Inter- national Conference on Computer Vision, pages 9421– 9431, 2023
2023
-
[80]
Monocular occupancy prediction for scalable indoor scenes
Hongxiao Yu, Yuqi Wang, Yuntao Chen, and Zhaoxiang Zhang. Monocular occupancy prediction for scalable indoor scenes. InEuropean Conference on Computer Vision, pages 38–54. Springer, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.