Recognition: unknown
Symbolic Execution Meets Multi-LLM Orchestration: Detecting Memory Vulnerabilities in Incomplete Rust CVE Snippets
Pith reviewed 2026-05-09 20:01 UTC · model grok-4.3
The pith
A four-agent LLM system synthesizes symbolic execution harnesses from incomplete Rust CVE snippets that defeat existing tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
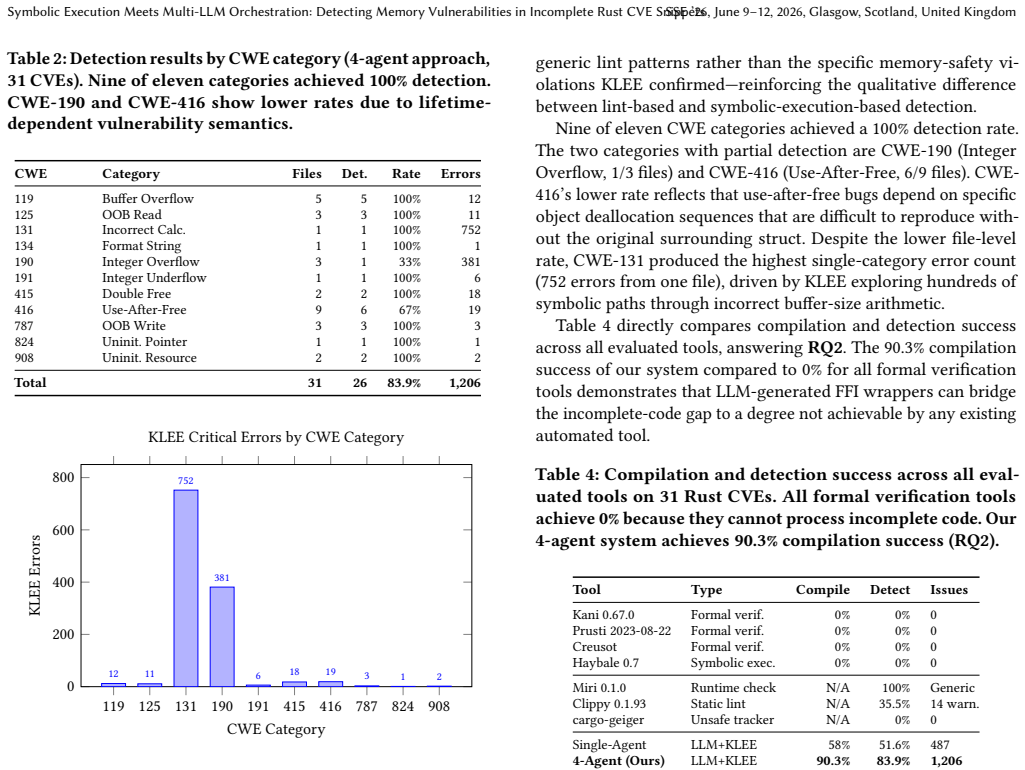
The paper claims that a multi-agent LLM architecture with four distinct roles collaboratively produces compilable symbolic execution harnesses from otherwise unbuildable Rust CVE fragments, reaching 90.3 percent wrapper success on 31 real cases spanning 11 weakness categories and surfacing 1,206 critical errors in 26 files while a single-agent version yields only 487 errors and conventional linters produce far fewer warnings.
What carries the argument
The four-agent multi-LLM architecture that plans analysis, checks safety, generates interface wrappers, and optimizes execution to turn incomplete code fragments into analyzable harnesses whose results feed a graph database of vulnerabilities.
If this is right
- Compilation success for incomplete CVE fragments rises above 90 percent where prior tools achieve none.
- Detected critical errors more than double when role specialization replaces a single general model.
- A graph database connects individual files, weakness types, error categories, and execution paths to support structured cross-report queries.
- The same fragments that produce zero output from standard verification now yield measurable error data for security analysis.
Where Pith is reading between the lines
- The orchestration pattern could apply to partial code in languages other than Rust whenever full context is missing from reports.
- The resulting vulnerability graph might enable automated grouping of CVEs that share similar root causes across different projects.
- If wrapper quality can be checked against complete code when it later becomes available, the method gains an empirical reliability test.
- Security teams could shift from waiting for full reproducible projects to extracting signals directly from the snippets that vendors already publish.
Load-bearing premise
The wrappers built by the agents preserve the original behavior of the snippets without adding or hiding memory issues that were not present in the reported code.
What would settle it
Independent review of the generated wrappers against the original CVE descriptions and any available full code to determine whether the reported execution errors match actual vulnerabilities rather than synthesis artifacts.
Figures



read the original abstract
This paper presents a system combining symbolic execution (KLEE) with a 4-agent multi-LLM architecture for detecting memory vulnerabilities in Rust unsafe code. A central challenge we address is the incomplete-code problem: CVE database entries provide only isolated code snippets that lack struct definitions, imports, and Cargo manifests, causing all existing formal verification tools to fail at compilation with zero output. Our system resolves this through four specialized agents -- an Oracle/Validator for strategic planning, a Safety Checker for vulnerability analysis, a Code Specialist for FFI wrapper generation, and a Fast Filter for execution optimization -- that collaboratively synthesize KLEE-compatible harnesses from otherwise uncompilable fragments. KLEE's output is then ingested by graph_klee.py, which constructs a Graph Database linking CVE files, CWE categories, error types, and symbolic execution paths as typed nodes and labelled edges, enabling structured cross-CVE vulnerability queries. We evaluated our system on 31 real-world Rust CVEs spanning 11 CWE categories, achieving 90.3% wrapper compilation success where all state-of-the-art formal verification tools achieve 0%. Our system detected 1,206 critical errors across 26 files (83.9% detection rate), compared to 14 warnings across 11 files for Clippy (35.5%) and generic labels for Miri. The 4-agent architecture reduced wrapper compilation failures from 42% (single-agent baseline) to 9.7% and increased detected errors from 487 to 1,206, confirming that role specialization and structured context passing produce measurably better results than a single general-purpose model. Our replication package is publicly available at https://github.com/Zeyad-Ab/Symbolic-Execution-with-Multi-LLM-Architecture-for-Rust-Security
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a 4-agent multi-LLM system (Oracle/Validator, Safety Checker, Code Specialist, Fast Filter) that synthesizes KLEE-compatible harnesses from incomplete Rust CVE snippets, enabling symbolic execution where standard tools fail at compilation. It reports 90.3% wrapper success on 31 CVEs, detection of 1,206 critical errors in 26 files (83.9% rate), a graph database for cross-CVE queries, and improvements over a single-agent baseline (9.7% vs 42% failures, 1206 vs 487 errors) plus comparisons to Clippy and Miri.
Significance. If the synthesized harnesses are semantically faithful and the KLEE errors are true positives, the work addresses a practical barrier in analyzing real-world incomplete security disclosures. The public replication package strengthens reproducibility and allows independent inspection of the agent orchestration and graph construction pipeline.
major comments (2)
- [Evaluation (as summarized in the abstract)] The headline quantitative results (1,206 errors, 83.9% detection rate, 90.3% compilation success) are load-bearing for the central claim yet rest on an unverified assumption that LLM-generated harnesses preserve the original snippet semantics. No manual audit of detected errors, no comparison against independently completed versions of the same CVEs, and no false-positive measurement on KLEE output are described, so it is unclear whether flagged memory violations reflect genuine vulnerabilities or artifacts from invented struct definitions, imports, FFI wrappers, or altered control flow.
- [Evaluation (as summarized in the abstract)] The single-agent baseline comparison demonstrates that role specialization increases compilable harnesses and reported errors, but does not test whether the additional detections are semantically correct rather than spurious paths introduced by the multi-agent synthesis process.
minor comments (2)
- The role of graph_klee.py and the resulting Graph Database (nodes for CVEs, CWEs, error types, paths; labelled edges) would benefit from a concrete schema diagram or example query to clarify how structured cross-CVE analysis is performed.
- [Abstract] The abstract states that all state-of-the-art formal verification tools achieve 0% success; a brief enumeration of the specific tools attempted and the exact compilation failure modes would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledge the points where our current evaluation is limited, and commit to specific revisions that strengthen the claims without misrepresenting the existing results.
read point-by-point responses
-
Referee: [Evaluation (as summarized in the abstract)] The headline quantitative results (1,206 errors, 83.9% detection rate, 90.3% compilation success) are load-bearing for the central claim yet rest on an unverified assumption that LLM-generated harnesses preserve the original snippet semantics. No manual audit of detected errors, no comparison against independently completed versions of the same CVEs, and no false-positive measurement on KLEE output are described, so it is unclear whether flagged memory violations reflect genuine vulnerabilities or artifacts from invented struct definitions, imports, FFI wrappers, or altered control flow.
Authors: We agree that semantic fidelity of the generated harnesses is a critical assumption underlying the reported error counts. The manuscript demonstrates that the 4-agent system produces compilable harnesses at 90.3% where all prior tools achieve 0%, and that these harnesses enable KLEE to surface 1,206 errors; however, we did not include a manual audit of harness correctness, a comparison to independently completed CVE versions, or a false-positive analysis of KLEE outputs. In the revised manuscript we will add a dedicated subsection to the Evaluation that reports: (1) manual review of a random sample of 50 harnesses for semantic alignment with the original CVE snippets, (2) KLEE results on any CVEs for which independently completed versions can be obtained, and (3) a qualitative assessment of a subset of reported errors to identify potential artifacts. These additions will be reflected in the abstract and conclusion as well. revision: yes
-
Referee: [Evaluation (as summarized in the abstract)] The single-agent baseline comparison demonstrates that role specialization increases compilable harnesses and reported errors, but does not test whether the additional detections are semantically correct rather than spurious paths introduced by the multi-agent synthesis process.
Authors: The single-agent baseline was included to quantify the benefit of role specialization on compilation success (42% failures reduced to 9.7%) and on the number of KLEE-detected errors (487 to 1,206). We acknowledge that this comparison does not verify whether the additional errors are semantically valid rather than artifacts of the multi-agent harness synthesis. The manual audit and fidelity checks described in our response to the first comment will be applied equally to both the multi-agent and single-agent outputs on the sampled CVEs. This will allow us to report whether the increase in detections corresponds to more true positives or to additional spurious paths, and we will add this comparative analysis to the revised Evaluation section. revision: yes
Circularity Check
No circularity: empirical results rest on external tool comparisons and real CVE data
full rationale
The paper's claims rest on an empirical evaluation of a 4-agent LLM system synthesizing KLEE harnesses for 31 incomplete Rust CVE snippets, reporting concrete metrics (90.3% compilation success, 1206 detected errors, 83.9% detection rate) obtained by running the pipeline and comparing outputs against Clippy (14 warnings) and Miri on the same inputs. No equations, fitted parameters, or first-principles derivations are present; the improvement from single-agent (42% failure, 487 errors) to 4-agent baseline is measured directly rather than defined into existence. No self-citations, uniqueness theorems, or ansatzes appear in the provided text, and the replication package is offered for external verification. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can accurately generate KLEE-compatible harnesses and FFI wrappers from incomplete code snippets
invented entities (4)
-
Oracle/Validator agent
no independent evidence
-
Safety Checker agent
no independent evidence
-
Code Specialist agent
no independent evidence
-
Fast Filter agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vytautas Astrauskas, Christoph Matheja, Federico Poli, Peter Müller, and Alexan- der J Summers. 2019. Leveraging Rust Types for Modular Specification and Verification. InProceedings of the ACM on Programming Languages, Vol. 3. ACM, 1–30
2019
-
[2]
James Bornholt. 2020. Haybale: Symbolic Execution of Rust Programs. https: //github.com/PLSysSec/haybale
2020
-
[3]
Cristian Cadar, Daniel Dunbar, and Dawson Engler. 2008. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs. InProceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 209–224
2008
-
[4]
Jia Chen et al. 2023. Detecting Rust Unrecoverable Panics via Symbolic Execution. InProceedings of the International Symposium on Software Testing and Analysis. ACM
2023
-
[5]
Mark Chen et al . 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Yinghao Chen et al . 2023. ChatUniTest: A Framework for LLM-Based Test Generation. InProceedings of the 32nd ACM International Symposium on Software Testing and Analysis (ISSTA)
2023
-
[7]
Vitaly Chipounov, Volodymyr Kuznetsov, and George Candea. 2011. S2E: A Platform for In-Vivo Multi-Path Analysis of Software Systems. InProceedings of the 16th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2011
-
[8]
Gelei Deng et al. 2024. PentestGPT: A GPT-Empowered Automatic Penetration Testing Tool. InProceedings of the 33rd USENIX Security Symposium
2024
-
[9]
Yinlin Deng et al. 2023. TitanFuzz: Black-Box Fuzzing of Deep-Learning Libraries via Large Language Models.Proceedings of the 45th International Conference on Software Engineering (ICSE)(2023)
2023
-
[10]
Xavier Denis, Jacques-Henri Jourdan, and Claude Marché. 2022. Creusot: A Foundry for the Deductive Verification of Rust Programs.Lecture Notes in Com- puter Science13047 (2022), 90–105
2022
-
[11]
Patrice Godefroid, Nils Klarlund, and Koushik Sen. 2005. DART: Directed Au- tomated Random Testing. InProceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI). 213–223
2005
-
[12]
Patrice Godefroid, Michael Y Levin, and David Molnar. 2008. Automated White- box Fuzz Testing. InProceedings of the 15th Network and Distributed System Security Symposium (NDSS)
2008
-
[13]
Sirui Hong et al. 2023. MetaGPT: Meta Programming for a Multi-Agent Collabo- rative Framework.arXiv preprint arXiv:2308.00352(2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Bo Jiang et al. 2024. Crabtree: LLM-Guided Fuzz Driver Generation for Rust. In Proceedings of the 33rd USENIX Security Symposium
2024
-
[15]
2019.The Rust Programming Language
Steve Klabnik and Carol Nichols. 2019.The Rust Programming Language. No Starch Press
2019
-
[16]
Martin Larsson. 2019. cargo-geiger: Detects unsafe Rust Code. https://github. com/rust-secure-code/cargo-geiger
2019
-
[17]
Peng Liu et al. 2020. Targeted Symbolic Execution for Use-After-Free Detection. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering
2020
- [18]
-
[19]
Nicholas D Matsakis and Felix S Klock. 2014. The Rust Programming Language. ACM SIGAda Ada Letters34, 3 (2014), 103–104
2014
-
[20]
Scott Olson, Oliver Günther, et al. 2018. Miri: An Interpreter for Rust’s Mid-level Intermediate Representation. https://github.com/rust-lang/miri
2018
-
[21]
Chen Qian et al. 2024. ChatDev: Communicative Agents for Software Develop- ment. InProceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics
2024
-
[22]
Koushik Sen, Darko Marinov, and Gul Agha. 2005. CUTE: A Concolic Unit Testing Engine for C. InProceedings of the 13th ACM SIGSOFT Symposium on Foundations of Software Engineering. 263–272
2005
-
[23]
Yan Shoshitaishvili, Ruoyu Wang, Christopher Hauser, Christopher Kruegel, and Giovanni Vigna. 2015. Concretely Mapped Memory for Symbolic Execution. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security
2015
-
[24]
Yuqiang Sun et al. 2024. LLM4Vuln: A Unified Evaluation Framework for Decou- pling and Enhancing LLMs’ Vulnerability Reasoning. InProceedings of the 33rd USENIX Security Symposium
2024
-
[25]
Michele Tufano et al. 2022. AthenaTest: Unit Test Generation Using LLMs. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering
2022
-
[26]
Alexa VanHattum, Daniel Schwartz-Narbonne, Nathan Chong, and Adrian Samp- son. 2022. Kani: Catching Bugs, Automatically, in Safe Rust. InProceedings of the International Conference on Software Engineering: Software Engineering in Practice. ACM, 138–149
2022
- [27]
-
[28]
Zhun Xu et al. 2024. AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks. InWorkshop on Large Language Models for Code at ICLR
2024
-
[29]
He Ye, Matias Martinez, and Martin Monperrus. 2022. VulnFix: Fast Patch Vali- dation via Symbolic Execution. InProceedings of the 37th IEEE/ACM International Symbolic Execution Meets Multi-LLM Orchestration: Detecting Memory Vulnerabilities in Incomplete Rust CVE Snippets SSE ’26, June 9–12, 2026, Glasgow, Scotland, United Kingdom Conference on Automated ...
2022
-
[30]
Jian Zhang et al. 2024. Multi-Agent Software Engineering: A Survey. InProceed- ings of the ACM/IEEE International Conference on Software Engineering. ACM
2024
-
[31]
Yaojie Zheng et al. 2023. Large Language Models for Test Input Generation in Symbolic Execution. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.