Recognition: unknown
Alethia: A Foundational Encoder for Voice Deepfakes
Pith reviewed 2026-05-09 19:25 UTC · model grok-4.3
The pith
Alethia is the first foundational audio encoder for voice deepfake detection and localization, created by a new pretraining recipe of bottleneck masked embedding prediction combined with flow-matching spectrogram reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By pretraining on the combination of bottleneck masked embedding prediction and flow-matching based spectrogram reconstruction, Alethia becomes the first foundational audio encoder that can be applied to various voice deepfake detection and localization tasks, significantly outperforming state-of-the-art speech foundation models on 56 benchmark datasets across 5 tasks, with better robustness to real-world perturbations and zero-shot generalization to unseen domains like singing deepfakes.
What carries the argument
Bottleneck masked embedding prediction combined with flow-matching spectrogram reconstruction as the joint pretraining objective that captures deepfake artifacts in continuous representations.
Load-bearing premise
The particular pretraining combination of bottleneck masked embedding prediction with flow-matching spectrogram reconstruction is what allows better capture of deepfake artifacts than previous approaches.
What would settle it
If Alethia fails to outperform existing models on a new independent test set of voice deepfakes with perturbations, the superiority and generalization claims would not hold.
Figures





read the original abstract
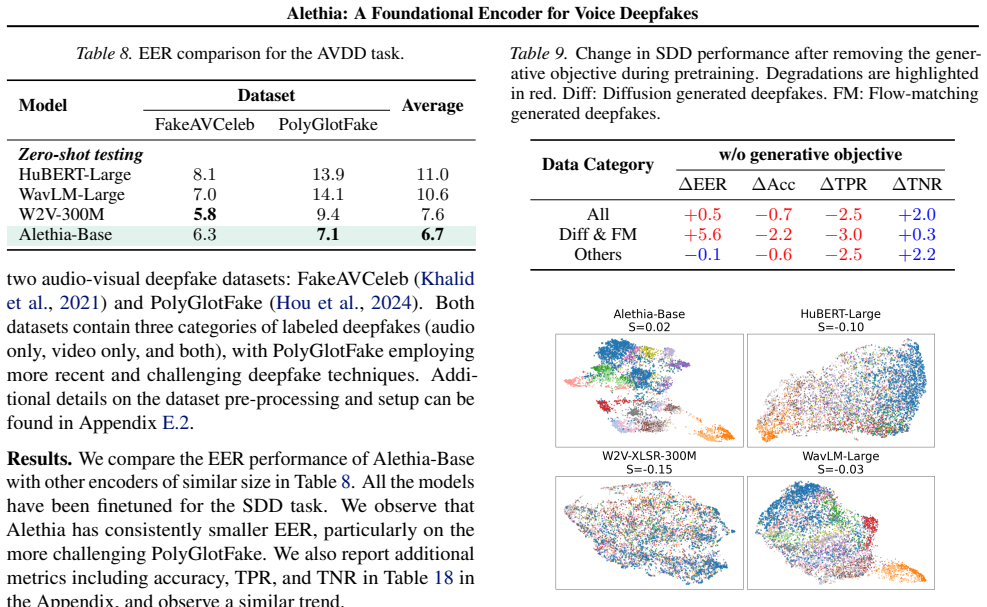
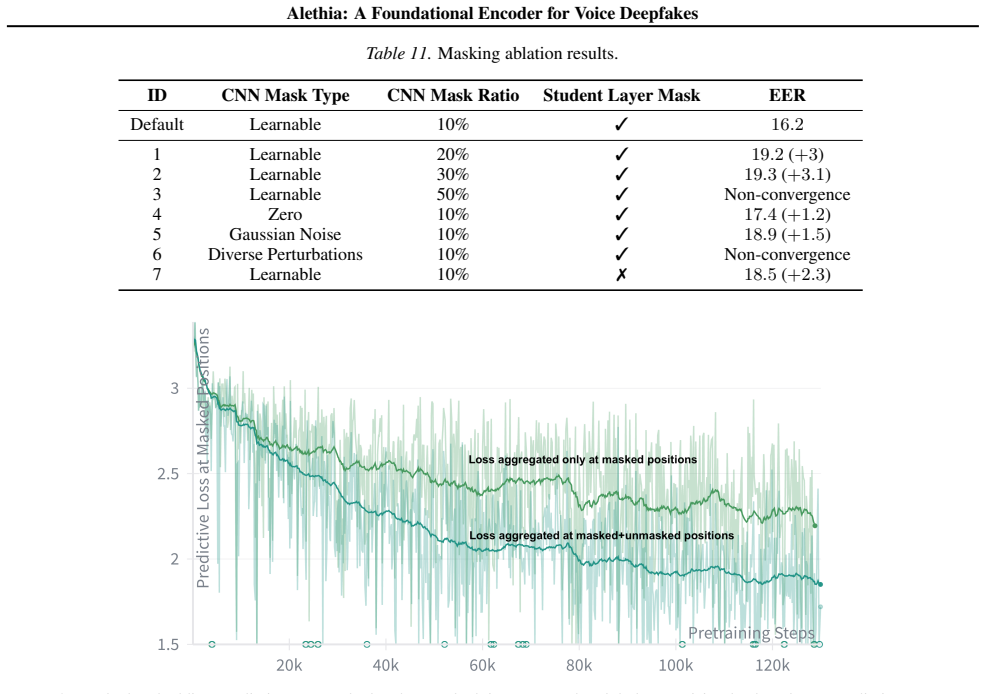
Existing voice deepfake detection and localization models rely heavily on representations extracted from speech foundation models (SFMs). However, downstream finetuning has now reached a state of diminishing returns. In this paper, we shift the focus to pretraining and propose a novel recipe that combines bottleneck masked embedding prediction with flow-matching based spectrogram reconstruction. The outcome, Alethia, is the first foundational audio encoder for various voice deepfake detection and localization tasks. We evaluate on $5$ different tasks with $56$ benchmark datasets, and note Alethia significantly outperforms state-of-the-art SFMs with superior robustness to real-world perturbations and zero-shot generalization to unseen domains (e.g., singing deepfakes). We also demonstrate the limitation of discrete targets in masked token prediction, and show the importance of continuous embedding prediction and generative pretraining for capturing deepfake artifacts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Alethia, the first foundational audio encoder designed specifically for voice deepfake detection and localization tasks. By combining bottleneck masked embedding prediction with flow-matching based spectrogram reconstruction in pretraining, Alethia is said to capture deepfake artifacts more effectively than existing speech foundation models (SFMs). The evaluation spans 5 tasks and 56 benchmark datasets, with claims of significant outperformance, superior robustness to perturbations, and zero-shot generalization to unseen domains such as singing deepfakes. The work also argues against discrete targets in masked prediction in favor of continuous embeddings and generative pretraining.
Significance. Should the empirical findings be confirmed with rigorous, unbiased evaluation, this contribution would be significant for the field of audio forensics and deepfake detection. It provides a new direction by focusing on specialized pretraining rather than continued finetuning of general SFMs, potentially leading to more robust systems. The scale of the evaluation across 56 datasets is commendable and, if the selection is transparent and pre-specified, offers compelling evidence for improved generalization capabilities.
major comments (2)
- The abstract asserts superior performance and generalization but supplies no experimental details, baselines, statistical tests, or ablation results; claims rest on unevaluated assertions. This is load-bearing as the performance numbers are the sole empirical support for both the 'first foundational encoder' and 'significantly outperforms' assertions.
- §4 (Experiments): The evaluation on 56 datasets across 5 tasks does not specify pre-specified inclusion criteria or a protocol for avoiding post-hoc selection. This risks making the zero-shot generalization claim (e.g., to singing deepfakes) circular if datasets were curated after training to emphasize strengths of the bottleneck masked embedding prediction plus flow-matching combination.
minor comments (1)
- The acronym 'SFMs' should be defined on first use as 'speech foundation models' for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The comments highlight important aspects of transparency in our presentation of results and experimental design. We have revised the manuscript to address both major comments by expanding the abstract and adding explicit documentation of our dataset selection protocol. Our responses to each point are provided below.
read point-by-point responses
-
Referee: The abstract asserts superior performance and generalization but supplies no experimental details, baselines, statistical tests, or ablation results; claims rest on unevaluated assertions. This is load-bearing as the performance numbers are the sole empirical support for both the 'first foundational encoder' and 'significantly outperforms' assertions.
Authors: We agree that the abstract should provide sufficient context to substantiate its claims without requiring the reader to immediately consult the full text. In the revised manuscript we have updated the abstract to briefly reference the primary baselines (WavLM, HuBERT, and other SFMs), the evaluation scope (5 tasks across 56 datasets), and the use of statistical significance testing via paired t-tests over multiple random seeds. All supporting details, including complete baseline comparisons, ablation studies, and robustness analyses, remain in §4 and the appendix. This change makes the abstract more informative while preserving its concise nature. revision: yes
-
Referee: §4 (Experiments): The evaluation on 56 datasets across 5 tasks does not specify pre-specified inclusion criteria or a protocol for avoiding post-hoc selection. This risks making the zero-shot generalization claim (e.g., to singing deepfakes) circular if datasets were curated after training to emphasize strengths of the bottleneck masked embedding prediction plus flow-matching combination.
Authors: We recognize the validity of this concern regarding potential selection bias. The 56 datasets were assembled according to a protocol established prior to any training: all publicly released voice deepfake detection and localization corpora from major benchmarks (ASVspoof 2019/2021, WaveFake, FakeAVCeleb, and related sources) available at the start of the project, partitioned into the five task categories, with singing-voice deepfake datasets deliberately added to evaluate zero-shot generalization to unseen domains. We have inserted a new subsection in §4.1 that explicitly states this pre-specified inclusion criteria, lists all datasets with sources, and explains the rationale for the singing-voice test set. This documentation removes any ambiguity about post-hoc curation. revision: yes
Circularity Check
No significant circularity; empirical claims with no derivation chain
full rationale
The paper proposes a pretraining recipe (bottleneck masked embedding prediction combined with flow-matching spectrogram reconstruction) and reports empirical results on 5 tasks across 56 datasets, claiming superior performance and zero-shot generalization. No equations, derivations, or mathematical steps are present in the provided text. Claims do not reduce to self-definitions, fitted inputs renamed as predictions, or self-citation chains; the 'first foundational encoder' status is asserted based on experimental outcomes rather than tautological construction. Dataset selection is described without pre-specified criteria, but this is an experimental design issue rather than a circular reduction of any derivation to its inputs. The work is self-contained as an empirical contribution without load-bearing self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked embedding prediction and flow-matching reconstruction are effective for learning representations that expose deepfake artifacts.
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review arXiv
-
[2]
Transferring audio deepfake detection capabil- ity across languages
Ba, Z., Wen, Q., Cheng, P., Wang, Y ., Lin, F., Lu, L., and Liu, Z. Transferring audio deepfake detection capabil- ity across languages. InProceedings of the ACM Web Conference 2023, pp. 2033–2044,
2023
-
[3]
Balestriero, R. and LeCun, Y . Learning by reconstruction produces uninformative features for perception.arXiv preprint arXiv:2402.11337,
-
[4]
Bhagtani, K., Yadav, A. K. S., Bestagini, P., and Delp, E. J. DiffSSD: A diffusion-based dataset for speech forensics. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[5]
Chandra, N. A., Murtfeldt, R., Qiu, L., Karmakar, A., Lee, H., Tanumihardja, E., Farhat, K., Caffee, B., Paik, S., Lee, C., et al. Deepfake-eval-2024: A multi-modal in-the- wild benchmark of deepfakes circulated in 2024.arXiv preprint arXiv:2503.02857,
-
[6]
CoLLD: Contrastive layer-to-layer distil- lation for compressing multilingual pre-trained speech encoders
Chang, H.-J., Dong, N., Mavlyutov, R., Popuri, S., and Chung, Y .-A. CoLLD: Contrastive layer-to-layer distil- lation for compressing multilingual pre-trained speech encoders. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 10801–10805. IEEE,
2024
- [7]
-
[8]
Demir¨ors, M., Ozbayoglu, A
Accessed: 2026-01-22. Demir¨ors, M., Ozbayoglu, A. M., and Akg ¨un, T. Future- proofing multilingual fake speech detection. InCS & IT Conference Proceedings, volume
2026
-
[9]
Trident of poseidon: A generalized approach for detecting deepfake voices
Doan, T.-P., Dinh-Xuan, H., Ryu, T., Kim, I., Lee, W., Hong, K., and Jung, S. Trident of poseidon: A generalized approach for detecting deepfake voices. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 2222–2235,
2024
-
[10]
T., Manrique, R., and Nunes, B
Fl´orez, P. T., Manrique, R., and Nunes, B. P. HABLA: A dataset of latin american spanish accents for voice anti-spoofing. InProc. Interspeech, volume 2023, pp. 1963–1967,
2023
-
[11]
9 Alethia: A Foundational Encoder for Voice Deepfakes Garg, A., Cai, Z., Zhang, L., Xinyuan, H. L., Garc´ıa-Perera, L. P., Duh, K., Khudanpur, S., Wiesner, M., and Andrews, N. ShiftySpeech: A large-scale synthetic speech dataset with distribution shifts.arXiv preprint arXiv:2502.05674,
-
[12]
Post- training for deepfake speech detection.arXiv preprint arXiv:2506.21090,
Ge, W., Wang, X., Liu, X., and Yamagishi, J. Post- training for deepfake speech detection.arXiv preprint arXiv:2506.21090,
-
[13]
ReMASC: Realistic replay attack corpus for voice controlled systems.arXiv preprint arXiv:1904.03365,
Gong, Y ., Yang, J., Huber, J., MacKnight, M., and Poellabauer, C. ReMASC: Realistic replay attack corpus for voice controlled systems.arXiv preprint arXiv:1904.03365,
-
[14]
R., Pimentel, A., Avila, A
Guimar˜aes, H. R., Pimentel, A., Avila, A. R., Reza- gholizadeh, M., Chen, B., and Falk, T. H. Robustdis- tiller: Compressing universal speech representations for enhanced environment robustness. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[15]
Guimar˜aes, H. R., Pimentel, A., Avila, A. R., Reza- gholizadeh, M., Chen, B., and Falk, T. H. An efficient end-to-end approach to noise invariant speech features via multi-task learning.arXiv preprint arXiv:2403.08654,
-
[16]
Hao, Y ., Chen, Y ., Xu, M., Zhan, J., He, L., Fang, L., Fang, S., and Liu, L. Wav2df-tsl: Two-stage learning with efficient pre-training and hierarchical experts fu- sion for robust audio deepfake detection.arXiv preprint arXiv:2509.04161,
-
[17]
Manipulated re- gions localization for partially deepfake audio: A survey
He, J., Yi, J., Tao, J., Zeng, S., and Gu, H. Manipulated re- gions localization for partially deepfake audio: A survey. arXiv preprint arXiv:2506.14396,
-
[18]
Huzaifah, M., Lin, G., Liu, T., Sailor, H
URLhttps://arxiv.org/abs/2507.21463. Huzaifah, M., Lin, G., Liu, T., Sailor, H. B., Tan, K. M., Vangani, T. K., Wang, Q., Wong, J. H., Wu, J., Chen, N. F., et al. MERaLiON-SpeechEncoder: Towards a speech foundation model for singapore and beyond.arXiv preprint arXiv:2412.11538,
-
[19]
UniCodec: Unified audio codec with single domain-adaptive codebook.arXiv preprint arXiv:2502.20067,
Jiang, Y ., Chen, Q., Ji, S., Xi, Y ., Wang, W., Zhang, C., Yue, X., Zhang, S., and Li, H. UniCodec: Unified audio codec with single domain-adaptive codebook.arXiv preprint arXiv:2502.20067,
-
[20]
S., et al
Jung, J.-w., Wu, Y ., Wang, X., Kim, J.-H., Maiti, S., Mat- sunaga, Y ., Shim, H.-j., Tian, J., Evans, N., Chung, J. S., et al. SpoofCeleb: Speech deepfake detection and SASV in the wild.IEEE Open Journal of Signal Processing, 2025a. Jung, J.-W., Zhang, W., Maiti, S., Wu, Y ., Wang, X., KIM, J., Matsunaga, Y ., Um, S., Tian, J., Shim, H.-J., et al. The Te...
2025
-
[21]
Source tracing of audio deepfake systems.arXiv preprint arXiv:2407.08016,
Klein, N., Chen, T., Tak, H., Casal, R., and Khoury, E. Source tracing of audio deepfake systems.arXiv preprint arXiv:2407.08016,
-
[22]
IndieFake dataset: A benchmark dataset for audio deepfake detection.arXiv preprint arXiv:2506.19014,
Kumar, A., Verma, K., and More, O. IndieFake dataset: A benchmark dataset for audio deepfake detection.arXiv preprint arXiv:2506.19014,
-
[23]
A survey on speech deepfake detection.ACM Computing Surveys, 57 (7):1–38, 2025a
Li, M., Ahmadiadli, Y ., and Zhang, X.-P. A survey on speech deepfake detection.ACM Computing Surveys, 57 (7):1–38, 2025a. Li, X., Li, K., Zheng, Y ., Yan, C., Ji, X., and Xu, W. Safeear: Content privacy-preserving audio deepfake detection. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 3585–3599,
2024
-
[24]
Measuring the ro- bustness of audio deepfake detectors,
Li, X., Chen, P.-Y ., and Wei, W. Measuring the ro- bustness of audio deepfake detectors.arXiv preprint arXiv:2503.17577, 2025b. Li, Y ., Yuan, R., Zhang, G., Ma, Y ., Chen, X., Yin, H., Xiao, C., Lin, C., Ragni, A., Benetos, E., et al. Mert: Acoustic music understanding model with large-scale self- supervised training.arXiv preprint arXiv:2306.00107,
-
[25]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
H., Le, M., Vyas, A., Shi, B., Tjandra, A., and Hsu, W.-N
10 Alethia: A Foundational Encoder for Voice Deepfakes Liu, A. H., Le, M., Vyas, A., Shi, B., Tjandra, A., and Hsu, W.-N. Generative pre-training for speech with flow matching.arXiv preprint arXiv:2310.16338,
-
[27]
A., and Chng, E
Luong, H.-T., Li, H., Zhang, L., Lee, K. A., and Chng, E. S. Llamapartialspoof: An llm-driven fake speech dataset simulating disinformation generation. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[28]
Mahapatra, A., Ulgen, I. R., Naini, A. R., Busso, C., and Sisman, B. Can emotion fool anti-spoofing?arXiv preprint arXiv:2505.23962,
-
[29]
Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274, 2025
Mousavi, P., Maimon, G., Moumen, A., Petermann, D., Shi, J., Wu, H., Yang, H., Kuznetsova, A., Ploujnikov, A., Marxer, R., et al. Discrete audio tokens: More than a survey!arXiv preprint arXiv:2506.10274,
-
[30]
T., Pizzi, K., Wagner, A., and Sperl, P
M¨uller, N., Kawa, P., Choong, W.-H., Stan, A., Bukkapat- nam, A. T., Pizzi, K., Wagner, A., and Sperl, P. Replay attacks against audio deepfake detection.arXiv preprint arXiv:2505.14862,
-
[31]
M., Dieckmann, F., Czempin, P., Canals, R., B¨ottinger, K., and Williams, J
M¨uller, N. M., Dieckmann, F., Czempin, P., Canals, R., B¨ottinger, K., and Williams, J. Speech is silver, silence is golden: What do ASVspoof-trained models really learn? arXiv preprint arXiv:2106.12914,
-
[32]
H., Vest- man, V ., Todisco, M., Delgado, H., Sahidullah, M., Yam- agishi, J., and Lee, K
Nautsch, A., Wang, X., Evans, N., Kinnunen, T. H., Vest- man, V ., Todisco, M., Delgado, H., Sahidullah, M., Yam- agishi, J., and Lee, K. A. ASVspoof 2019: Spoofing coun- termeasures for the detection of synthesized, converted and replayed speech.IEEE Transactions on Biometrics, Behavior, and Identity Science, 3(2):252–265,
2019
-
[33]
Accessed: 2026-01-22. Park, K. and Mulc, T. CSS10: A collection of single speaker speech datasets for 10 languages. InProc. Interspeech 2019, pp. 1566–1570,
2026
-
[34]
V oxCeleb: A Large-Scale Speaker Identification Dataset
doi: 10.21437/Interspeech. 2019-1500. Pasad, A., Chou, J.-C., and Livescu, K. Layer-wise analysis of a self-supervised speech representation model. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 914–921. IEEE,
-
[35]
SRC4VC: Smartphone-recorded corpus for voice conversion bench- mark.arXiv preprint arXiv:2406.07254,
Saito, Y ., Igarashi, T., Seki, K., Takamichi, S., Yamamoto, R., Tachibana, K., and Saruwatari, H. SRC4VC: Smartphone-recorded corpus for voice conversion bench- mark.arXiv preprint arXiv:2406.07254,
-
[36]
JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis
Sonobe, R., Takamichi, S., and Saruwatari, H. JSUT corpus: free large-scale japanese speech corpus for end-to-end speech synthesis.arXiv preprint arXiv:1711.00354,
-
[37]
Rawboost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing
Tak, H., Kamble, M., Patino, J., Todisco, M., and Evans, N. Rawboost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6382–6386. IEEE,
2022
-
[38]
JMD: Japanese multi-dialect corpus for speech synthesis
11 Alethia: A Foundational Encoder for Voice Deepfakes Takamichi, S. JMD: Japanese multi-dialect corpus for speech synthesis. https://sites.google.com/ site/shinnosuketakamichi/publication/ research-topics/jmd_corpus, 2021a. Ac- cessed: 2026-01-22. Takamichi, S. Tri-jek: Japanese-English-Korean tri-lingual speech corpus. https://sites. google.com/site/shi...
2026
-
[39]
Takamichi, S., Komachi, M., Tanji, N., and Saruwatari, H
Accessed: 2026-01-22. Takamichi, S., Komachi, M., Tanji, N., and Saruwatari, H. JSSS: free japanese speech corpus for summarization and simplification.arXiv preprint arXiv:2010.01793, 2020a. Takamichi, S., Sonobe, R., Mitsui, K., Saito, Y ., Koriyama, T., Tanji, N., and Saruwatari, H. JSUT and JVS: Free japanese voice corpora for accelerating speech synth...
-
[40]
ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,
Wang, X., Delgado, H., Tak, H., Jung, J.-w., Shim, H.- j., Todisco, M., Kukanov, I., Liu, X., Sahidullah, M., Kinnunen, T., et al. ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale.arXiv preprint arXiv:2408.08739,
-
[41]
Wu, H., Tseng, Y ., and Lee, H.-y. Codecfake: Enhanc- ing anti-spoofing models against deepfake audios from codec-based speech synthesis systems.arXiv preprint arXiv:2406.07237,
-
[42]
Xie, Y ., Lu, Y ., Fu, R., Wen, Z., Wang, Z., Tao, J., Qi, X., Wang, X., Liu, Y ., Cheng, H., et al. The codecfake dataset and countermeasures for the universally detection of deepfake audio.IEEE Transactions on Audio, Speech and Language Processing, 2025a. Xie, Y ., Wang, X., Wang, Z., Fu, R., Wen, Z., Cao, S., Ma, L., Li, C., Cheng, H., and Ye, L. Neura...
-
[43]
A., Kinnunen, T., Evans, N., et al
Yamagishi, J., Wang, X., Todisco, M., Sahidullah, M., Patino, J., Nautsch, A., Liu, X., Lee, K. A., Kinnunen, T., Evans, N., et al. ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection.arXiv preprint arXiv:2109.00537,
-
[44]
Yang, Q., Zuo, J., Su, Z., Jiang, Z., Li, M., Zhao, Z., Chen, F., Wang, Z., and Huai, B. Mscenespeech: A multi-scene speech dataset for expressive speech synthesis.arXiv preprint arXiv:2407.14006,
-
[45]
Yang, S.-w., Chi, P.-H., Chuang, Y .-S., Lai, C.-I. J., Lakho- tia, K., Lin, Y . Y ., Liu, A. T., Shi, J., Chang, X., Lin, G.-T., et al. Superb: Speech processing universal performance benchmark.arXiv preprint arXiv:2105.01051,
-
[46]
Yang, X., Yang, Y ., Jin, Z., Cui, Z., Wu, W., Li, B., Zhang, C., and Woodland, P. SPEAR: A unified ssl framework for learning speech and audio representations.arXiv preprint arXiv:2510.25955,
-
[47]
Half-truth: A partially fake audio detection dataset.arXiv preprint arXiv:2104.03617,
Yi, J., Bai, Y ., Tao, J., Ma, H., Tian, Z., Wang, C., Wang, T., and Fu, R. Half-truth: A partially fake audio detection dataset.arXiv preprint arXiv:2104.03617,
-
[48]
Singfake: Singing voice deepfake detection
Zang, Y ., Zhang, Y ., Heydari, M., and Duan, Z. Singfake: Singing voice deepfake detection. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 12156–12160. IEEE,
2024
-
[49]
Audio deepfake detection: What has been achieved and what lies ahead.Sensors (Basel, Switzerland), 25(7):1989,
Zhang, B., Cui, H., Nguyen, V ., and Whitty, M. Audio deepfake detection: What has been achieved and what lies ahead.Sensors (Basel, Switzerland), 25(7):1989,
1989
-
[50]
SVDD 2024: The inaugural singing voice deepfake detection challenge
Zhang, Y ., Zang, Y ., Shi, J., Yamamoto, R., Toda, T., and Duan, Z. SVDD 2024: The inaugural singing voice deepfake detection challenge. InProc. IEEE Spoken Language Technology Workshop (SLT),
2024
-
[51]
Zhu, Y ., Guimar ˜aes, H. R., Pimentel, A., and Falk, T. AUDDT: Audio unified deepfake detection benchmark toolkit.arXiv preprint arXiv:2509.21597,
-
[52]
13 Alethia: A Foundational Encoder for Voice Deepfakes A. POC Experiment Setup We follow a similar setup as the base versions of Wave2vec2 and HuBERT, where the pretraining data are identical to the downstream finetuning data (Baevski et al., 2020; Hsu et al., 2021). We curate 1k hours of real and fake speech, where the real speech data are sourced from C...
2020
-
[53]
all-step
B. Alethia Architecture and Pretraining Details Table 10 summarizes the architectural hyperparameters of Alethia-Base and Alethia-Large. One thing to note is that while the teacher model WavLM-Large adopts PostLN, the student Alethia-Base uses PreLN, with which we found better convergence. Regarding pretraining setup, we utilize the AdamW optimizer with a...
2020
-
[54]
Other Tasks PFSL.For dataset configuration and model inference, we adapt the framework provided by Luong et al
E.2. Other Tasks PFSL.For dataset configuration and model inference, we adapt the framework provided by Luong et al. (2025).1. While the original framework supports multi-scale evaluation across six temporal resolutions ( units∈ {0.02,0.04,0.08,0.16,0.32,0.64} seconds), we evaluate exclusively at the 20ms scale (units= 0.02 ). This choice is 1https://gith...
2025
-
[55]
A VDD.For this task, we adapt code from the FakeA VCeleb repository2
is included in the pretraining of Alethia, which could lead to biased evaluation. A VDD.For this task, we adapt code from the FakeA VCeleb repository2. We segmented the videos into 3 second chunks to handle variable durations, and treat the chunks as independent samples while calculating metrics. The audio stream is extracted from the videos and resampled...
2021
-
[56]
For all experimental conditions, we performed quality control and class balancing for each training dataset. While this significantly reduces the total training volume, it helps to avoid the effects of confounding factors, such as prolonged silence and class imbalance, which may otherwise lead to spurious correlations (M¨uller et al., 2021). For the other...
2021
-
[57]
preprocessed
Datasets subjected to our quality control pipeline are denoted with the “preprocessed” suffix, whereas those labeled “raw” remain in their original state. To facilitate a direct comparison with prior literature, we specifically utilize the raw versions of standard benchmarks, including the ASVspoof series (Nautsch et al., 2021; Yamagishi et al., 2021; Wan...
2021
-
[58]
37,314 Deepfake eval 2024 preprocessed (Chandra et al.,
2024
-
[59]
4,700 KSS preprocessed (Park, 2019; Park & Mulc,
2019
-
[60]
Other Experimental Results G.1
98,411 G. Other Experimental Results G.1. SDD Model Comparison Table 16 and 17 provide per-dataset EER and accuracy of Alethia-Large and W1V-1B along with their performance difference under the EXPANDED-AUGand EXPANDEDcondition, respectively. For both conditions, Alethia-large shows better performance with significantly fewer datasets with accuracies belo...
1934
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.