Recognition: unknown
Rethinking Network Topologies for Cost-Effective Mixture-of-Experts LLM Serving
Pith reviewed 2026-05-09 19:29 UTC · model grok-4.3
The pith
Lower-cost switchless topologies outperform scale-up networks in cost-effectiveness for Mixture-of-Experts LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
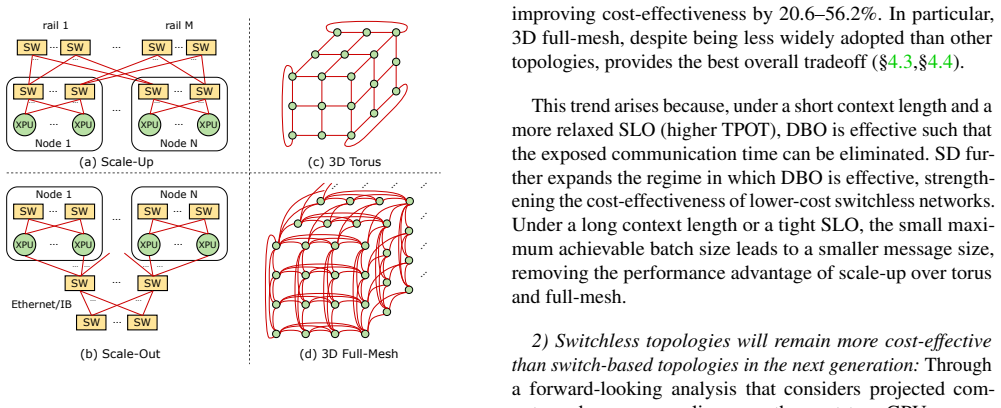
Lower-cost switchless topologies are more cost-effective than the scale-up topology across all serving scenarios explored, improving cost-effectiveness by 20.6-56.2%. In particular, the 3D full-mesh topology is Pareto-optimal in terms of the performance-cost tradeoff. Current scale-up link bandwidths are over-provisioned: reducing the link bandwidth improves throughput per cost by up to 27%. A forward-looking analysis of upcoming GPU generations indicates that the cost-performance advantage of switchless networks will likely persist.
What carries the argument
Cross-layer analysis of four representative XPU topologies (scale-up, scale-out, 3D torus, 3D full-mesh) using combined performance and hardware cost models for MoE LLM serving workloads.
If this is right
- Industry investments in scale-up networks for MoE serving can be redirected toward lower-cost switchless alternatives without sacrificing performance.
- Reducing over-provisioned scale-up link bandwidths can raise throughput per dollar by up to 27 percent.
- The 3D full-mesh topology delivers the strongest performance-cost balance among the options studied.
- The cost advantage of switchless designs is expected to remain as future GPU generations increase device counts and communication demands.
- Network topology choice becomes a first-order factor in overall MoE serving efficiency because communication dominates runtime.
Where Pith is reading between the lines
- Workloads with similar all-to-all expert communication patterns, such as certain sparse training jobs, may see comparable savings from switchless topologies.
- Hardware roadmaps could shift emphasis toward denser, lower-cost mesh interconnects rather than high-radix switches.
- Software layers for collective communication could be retuned specifically for mesh routing to capture additional gains beyond the hardware-level analysis.
Load-bearing premise
The cost and performance models accurately capture real MoE communication patterns, hardware costs, and workload behaviors for the topologies compared.
What would settle it
Direct measurement of end-to-end serving throughput and total cost of ownership on production-scale clusters running identical MoE models over both scale-up and 3D full-mesh interconnects under representative request patterns.
Figures















read the original abstract
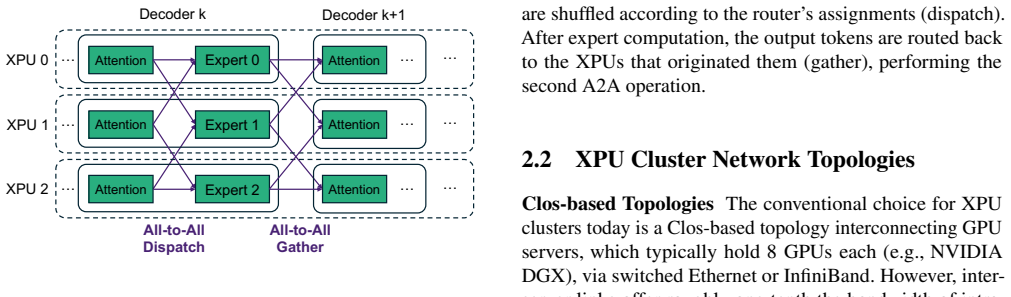
Mixture-of-experts (MoE) architectures have turned LLM serving into a cluster-scale workload in which communication consumes a considerable portion of LLM serving runtime. This has prompted industry to invest heavily in expensive high-bandwidth scale-up networks. We question whether such costly infrastructure is strictly necessary. We present the first systematic cross-layer analysis of network cost-effectiveness for MoE LLM serving, comparing four representative XPU (e.g., GPU/TPU) topologies (scale-up, scale-out, 3D torus, and 3D full-mesh). We find that lower-cost switchless topologies are more cost-effective than the scale-up topology across all serving scenarios explored, improving cost-effectiveness by 20.6-56.2%. In particular, the 3D full-mesh topology is Pareto-optimal in terms of the performance-cost tradeoff. We also find that current scale-up link bandwidths are over-provisioned: reducing the link bandwidth improves throughput per cost by up to 27%. A forward-looking analysis of upcoming GPU generations indicates that the cost-performance advantage of switchless networks will likely persist.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic cross-layer analysis comparing four XPU network topologies (scale-up, scale-out, 3D torus, and 3D full-mesh) for Mixture-of-Experts LLM serving. It claims that lower-cost switchless topologies outperform the high-bandwidth scale-up topology in cost-effectiveness by 20.6-56.2% across explored scenarios, with the 3D full-mesh being Pareto-optimal; it further claims that current scale-up link bandwidths are over-provisioned (reducing them improves throughput per cost by up to 27%) and that the switchless advantage will persist for future GPU generations.
Significance. If the analytical models are accurate, the results would be significant for data-center design of LLM serving clusters, as they challenge the prevailing investment in expensive scale-up fabrics and suggest simpler, lower-cost switchless topologies can deliver better performance-cost tradeoffs for MoE workloads.
major comments (2)
- [Section 4] The cross-layer performance model (Section 4) for dynamic all-to-all MoE token dispatching under reduced-bandwidth switchless fabrics (3D torus and 3D full-mesh) lacks any hardware calibration, trace-driven validation, or sensitivity analysis for congestion and tail latency at realistic expert counts and batch sizes. This directly undermines the central 20.6-56.2% cost-effectiveness gains and Pareto-optimality claim for 3D full-mesh, as the ranking versus scale-up could reverse if the model underestimates latency.
- [Section 5] The cost model (Section 5) that ranks hardware + cabling + power and concludes scale-up links are over-provisioned (27% throughput-per-cost gain from bandwidth reduction) provides no explicit equations or parameter sources for link costs and power; without these, the percentage improvements and topology rankings cannot be independently verified or falsified.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise statement of the workload traces, cost parameters, and validation approach used, as these are currently absent and hinder immediate assessment of the claims.
- [Figures 3-5] Figure captions and topology diagrams should explicitly label the assumed link bandwidths, cable lengths, and power figures to allow readers to trace the cost-effectiveness calculations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, proposing revisions to improve transparency and robustness where appropriate.
read point-by-point responses
-
Referee: [Section 4] The cross-layer performance model (Section 4) for dynamic all-to-all MoE token dispatching under reduced-bandwidth switchless fabrics (3D torus and 3D full-mesh) lacks any hardware calibration, trace-driven validation, or sensitivity analysis for congestion and tail latency at realistic expert counts and batch sizes. This directly undermines the central 20.6-56.2% cost-effectiveness gains and Pareto-optimality claim for 3D full-mesh, as the ranking versus scale-up could reverse if the model underestimates latency.
Authors: Our performance model in Section 4 is an analytical formulation that computes end-to-end latency from per-link bandwidth, hop count, and all-to-all communication volume specific to each topology and MoE dispatch pattern. It incorporates a conservative congestion factor derived from standard queueing analysis rather than empirical traces. We acknowledge the absence of hardware calibration or trace-driven validation in the submitted version. In the revision we will add a dedicated sensitivity analysis subsection that varies expert count (8–128), batch size, and congestion multiplier to quantify impact on tail latency and confirm that the reported 20.6–56.2 % cost-effectiveness advantage and Pareto optimality of 3D full-mesh remain stable under these perturbations. revision: partial
-
Referee: [Section 5] The cost model (Section 5) that ranks hardware + cabling + power and concludes scale-up links are over-provisioned (27% throughput-per-cost gain from bandwidth reduction) provides no explicit equations or parameter sources for link costs and power; without these, the percentage improvements and topology rankings cannot be independently verified or falsified.
Authors: We agree that explicit documentation is required for reproducibility. The revised manuscript will include the complete set of cost equations (hardware acquisition, cabling, and power) together with the exact parameter values and their sources (vendor datasheets, industry reports, and published power models). This addition will allow independent verification of the 27 % throughput-per-cost improvement obtained by reducing scale-up link bandwidth. revision: yes
Circularity Check
No circularity detected; claims derive from cross-layer models without self-referential reduction.
full rationale
The provided abstract and text contain no equations, derivations, fitted parameters renamed as predictions, or self-citations that bear the central load. Cost-effectiveness percentages and Pareto-optimality statements are presented as outputs of topology comparisons, but no specific reduction (e.g., Eq. X defined in terms of Y) is exhibited. Per hard rules, circularity requires quotable evidence of constructional equivalence; none is present, so the derivation chain is treated as self-contained against external benchmarks. This aligns with the reader's assessment of no detectable circularity from available text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vidur: A large-scale simulation framework for llm inference.Proceedings of Machine Learning and Systems, 6:351–366, 2024
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S Gulavani, Ramachan- dran Ramjee, and Alexey Tumanov. Vidur: A large-scale simulation framework for llm inference.Proceedings of Machine Learning and Systems, 6:351–366, 2024
2024
-
[2]
Claude 3.7 sonnet and claude code
Anthropic. Claude 3.7 sonnet and claude code. https: //www.anthropic.com/news/claude-3-7-sonnet , 2025
2025
-
[3]
Inter-node collective communications with aws neuron
AWS. Inter-node collective communications with aws neuron. AWS Neuron Documentation https://awsdocs-neuron.readthedocs-hosted. com/en/latest/neuron-runtime/explore/ internode-collective-comm.html, 2026
2026
-
[4]
Intra-node collective communications with aws neuron
AWS. Intra-node collective communications with aws neuron. AWS Neuron Documentation https://awsdocs-neuron.readthedocs-hosted. com/en/latest/neuron-runtime/explore/ intranode-collective-comm.html, 2026
2026
-
[5]
Longwriter: Unleashing 10,000+ word generation from long context llms, 2024
Yushi Bai, Jiajie Zhang, Xin Lv, Linzhi Zheng, Siqi Zhu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longwriter: Unleashing 10,000+ word generation from long context llms.arXiv preprint arXiv:2408.07055, 2024
-
[6]
Efficient all-to-all collective communication schedules for direct- connect topologies
Prithwish Basu, Liangyu Zhao, Jason Fantl, Siddharth Pal, Arvind Krishnamurthy, and Joud Khoury. Efficient all-to-all collective communication schedules for direct- connect topologies. InProceedings of the 33rd Inter- national Symposium on High-Performance Parallel and Distributed Computing, HPDC ’24, page 28–41, New York, NY , USA, 2024. Association for ...
2024
-
[7]
Nvidia vera rubin pod: Seven chips, five rack-scale systems, one ai supercomputer, March 2026
Rohil Bhargava, Taylor Allison, and Harry Petty. Nvidia vera rubin pod: Seven chips, five rack-scale systems, one ai supercomputer, March 2026. NVIDIA Technical Blog
2026
-
[8]
Scale-Up Ethernet Framework Specifi- cation
Broadcom Inc. Scale-Up Ethernet Framework Specifi- cation. Technical Report Scale-Ethernet-RM104, Broad- com, September 2025. Revision History: September 26, 2025
2025
-
[9]
Bruck, Ching-Tien Ho, S
J. Bruck, Ching-Tien Ho, S. Kipnis, E. Upfal, and D. Weathersby. Efficient algorithms for all-to-all communications in multiport message-passing systems. IEEE Transactions on Parallel and Distributed Systems, 8(11):1143–1156, 1997
1997
-
[10]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Sim- ple llm inference acceleration framework with multiple decoding heads, 2024
2024
-
[11]
Llmservingsim: A hw/sw co- simulation infrastructure for llm inference serving at scale
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, and Jongse Park. Llmservingsim: A hw/sw co- simulation infrastructure for llm inference serving at scale. In2024 IEEE International Symposium on Work- load Characterization (IISWC), pages 15–29. IEEE, 2024
2024
-
[12]
Swing: short-cutting rings for higher bandwidth allreduce
Daniele De Sensi, Tommaso Bonato, David Saam, and Torsten Hoefler. Swing: short-cutting rings for higher bandwidth allreduce. InProceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation, NSDI’24, USA, 2024. USENIX Asso- ciation
2024
-
[13]
Expert parallelism load balancer
DeepSeek. Expert parallelism load balancer. https: //github.com/deepseek-ai/eplb, 2025. 13
2025
-
[14]
Profiling data in deepseek infra
DeepSeek. Profiling data in deepseek infra. https: //github.com/deepseek-ai/profile-data, 2025
2025
-
[15]
DeepSeek-V3
deepseek-ai. DeepSeek-V3. https://huggingface. co/deepseek-ai/DeepSeek-V3. [Accessed 23-04- 2026]
2026
-
[16]
Zhang, Han Bao, Han- wei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingx- uan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Han- wei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, ...
2025
-
[17]
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W. Mahoney, and Kurt Keutzer. Ai and memory wall, 2024. arXiv:2403.14123
-
[18]
TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference
Raja Gond, Nipun Kwatra, and Ramachandran Ram- jee. Tokenweave: Efficient compute-communication overlap for distributed llm inference.arXiv preprint arXiv:2505.11329, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Efficient indirect all-to-all personalized com- munication on rings and 2-d tori.Journal of Computer Science and Technology, 16(5):480–483, 2001
Naijie Gu. Efficient indirect all-to-all personalized com- munication on rings and 2-d tori.Journal of Computer Science and Technology, 16(5):480–483, 2001
2001
-
[20]
Brighten Godfrey
Vipul Harsh, Sangeetha Abdu Jyothi, and P. Brighten Godfrey. Spineless data centers. InProceedings of the 19th ACM Workshop on Hot Topics in Networks, HotNets ’20, page 67–73, New York, NY , USA, 2020. Association for Computing Machinery
2020
-
[21]
Nvidia nvl72 ai factory: Nvidia enterprise reference architecture with nvidia gb300 nvl72 and nvidia spectrum-x network- ing platform
Richard Hastie and Shashank Sabhlok. Nvidia nvl72 ai factory: Nvidia enterprise reference architecture with nvidia gb300 nvl72 and nvidia spectrum-x network- ing platform. Nvidia enterprise reference architecture, NVIDIA Corporation, 2026
2026
-
[22]
Hennessy and David A
John L. Hennessy and David A. Patterson.Computer Architecture, Sixth Edition: A Quantitative Approach. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 6th edition, 2017
2017
-
[23]
Roger W. Hockney. The communication challenge for mpp: Intel paragon and meiko cs-2.Parallel Comput., 20(3):389–398, March 1994
1994
-
[24]
Mad-max beyond single-node: Enabling large machine learning model acceleration on distributed systems
Samuel Hsia, Alicia Golden, Bilge Acun, Newsha Ardalani, Zachary DeVito, Gu-Yeon Wei, David Brooks, and Carole-Jean Wu. Mad-max beyond single-node: Enabling large machine learning model acceleration on distributed systems. InProceedings of the 51st An- nual International Symposium on Computer Architec- ture, ISCA ’24, page 818–833. IEEE Press, 2025
2025
-
[25]
Megascale: scaling large language model training to more than 10,000 gpus
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin J...
2024
-
[26]
14 Improving all-to-many personalized communication in two-phase i/o
Qiao Kang, Robert Ross, Robert Latham, Sunwoo Lee, Ankit Agrawal, Alok Choudhary, and Wei-keng Liao. 14 Improving all-to-many personalized communication in two-phase i/o. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–13, 2020
2020
-
[28]
Superserve: fine-grained inference serving for unpredictable work- loads
Alind Khare, Dhruv Garg, Sukrit Kalra, Snigdha Grandhi, Ion Stoica, and Alexey Tumanov. Superserve: fine-grained inference serving for unpredictable work- loads. InProceedings of the 22nd USENIX Sympo- sium on Networked Systems Design and Implementation, NSDI ’25, USA, 2025. USENIX Association
2025
-
[29]
Speculative decoding with big little de- coder
Sehoon Kim, Karttikeya Mangalam, Suhong Moon, Ji- tendra Malik, Michael W Mahoney, Amir Gholami, and Kurt Keutzer. Speculative decoding with big little de- coder. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural In- formation Processing Systems, volume 36, pages 39236– 39256. Curran Associates, Inc., 2023
2023
-
[30]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[31]
Huang, and P
Chi Chung Lam, C.-H. Huang, and P. Sadayappan. Op- timal algorithms for all-to-all personalized communi- cation on rings and two dimensional tori.Journal of Parallel and Distributed Computing, 43(1):3–13, 1997
1997
-
[32]
Supermesh: Energy-efficient collective communications for accelerators
Sabuj Laskar, Pranati Majhi, Abdullah Muzahid, and Eun Jung Kim. Supermesh: Energy-efficient collective communications for accelerators. InProceedings of the 58th IEEE/ACM International Symposium on Microar- chitecture, MICRO ’25, page 1640–1655, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[33]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Confer- ence on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 1...
2023
-
[34]
Eagle: Speculative sampling requires rethinking feature uncertainty, 2025
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty, 2025
2025
-
[35]
UB-Mesh: A Hierarchically Localized nD- FullMesh Data Center Network Architecture .IEEE Micro, 45(05):20–29, September 2025
Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, Jianbing Wang, Xiangyu Chen, Peng Dong, Rui Meng, Wenjie Liu, Zhe Zhou, Ziyang Zhang, Yuhang Gai, Cunle Qian, Yi Xiong, Zhongwu Cheng, Jing Xia, Yuli Ma, Xi Chen, Wenhua Du, Shizhong Xiao, Chungang Li, Yong Qin, Liudong Xiong, Zhou Yu, Lv Chen, Lei Chen, Buyun Wang, Pei Wu, Junen Gao, X...
2025
-
[36]
Mixnet: A runtime reconfigurable optical-electrical fab- ric for distributed mixture-of-experts training
Xudong Liao, Yijun Sun, Han Tian, Xinchen Wan, Yilun Jin, Zilong Wang, Zhenghang Ren, Xinyang Huang, Wenxue Li, Kin Fai Tse, Zhizhen Zhong, Guyue Liu, Ying Zhang, Xiaofeng Ye, Yiming Zhang, and Kai Chen. Mixnet: A runtime reconfigurable optical-electrical fab- ric for distributed mixture-of-experts training. InPro- ceedings of the ACM SIGCOMM 2025 Confere...
2025
-
[37]
Apex: An extensible and dynamism-aware simulator for automated parallel execution in llm serving,
Yi-Chien Lin, Woosuk Kwon, Ronald Pineda, and Fanny Nina Paravecino. Apex: An extensible and dynamism-aware simulator for automated parallel exe- cution in llm serving.arXiv preprint arXiv:2411.17651, 2024
-
[39]
Rethinking machine learn- ing collective communication as a multi-commodity flow problem
Xuting Liu, Behnaz Arzani, Siva Kesava Reddy Kakarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth Kandula, and Luke Marshall. Rethinking machine learn- ing collective communication as a multi-commodity flow problem. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, page 16–37, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[40]
Characterizing LLM inference energy-performance tradeoffs across workloads and GPU scaling,
Paul Joe Maliakel, Shashikant Ilager, and Ivona Brandic. Characterizing llm inference energy-performance trade- offs across workloads and gpu scaling.arXiv preprint arXiv:2501.08219, 2026
-
[41]
MLPerf Inference 5.1: Benchmarking Small LLMs with Llama3.1-8B, September 2025
MLCommons. MLPerf Inference 5.1: Benchmarking Small LLMs with Llama3.1-8B, September 2025
2025
-
[42]
Mlperf inference rules, section 3: Scenarios
MLCommons. Mlperf inference rules, section 3: Scenarios. Github Repository https://github. com/mlcommons/inference_policies/blob/ 15 96edf999d5691a15e92a9e7c0af74e72c01ab403/ inference_rules.adoc#scenarios, March 2026. Commit 96edf999d5691a15e92a9e7c0af74e72c01ab403
2026
-
[43]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebas- tian Nowozin, Pushmeet Kohli, and Matej Balog. Al- phaevolve: A coding agent for scientific and ...
work page internal anchor Pith review arXiv 2025
-
[44]
Nvidia dynamo: A low-latency distributed inference framework for scaling reasoning ai models, 2026
NVIDIA Corporation. Nvidia dynamo: A low-latency distributed inference framework for scaling reasoning ai models, 2026. NVIDIA Technical Blog
2026
-
[45]
Accelerating the next phase of AI
OpenAI. Accelerating the next phase of AI. https://openai.com/index/ accelerating-the-next-phase-ai/ , March 2026
2026
-
[46]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
2024
-
[47]
Alibaba hpn: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao Wang, Peng Wang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Yao, Ennan Zhai, and Dennis Cai. Alibaba hpn: A data center network for large language model training. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, p...
2024
-
[48]
Optimizing all-to-all collective com- munication with fault tolerance on torus networks
Le Qin, Junwei Cui, Weilin Cai, Meng Niu, Yan Yang, and Jiayi Huang. Optimizing all-to-all collective com- munication with fault tolerance on torus networks. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, MICRO ’25, page 659–674, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[49]
Themis: a net- work bandwidth-aware collective scheduling policy for distributed training of dl models
Saeed Rashidi, William Won, Sudarshan Srinivasan, Srinivas Sridharan, and Tushar Krishna. Themis: a net- work bandwidth-aware collective scheduling policy for distributed training of dl models. InProceedings of the 49th Annual International Symposium on Computer Architecture, ISCA ’22, page 581–596, New York, NY , USA, 2022. Association for Computing Machinery
2022
-
[50]
Utility-driven spec- ulative decoding for mixture-of-experts.arXiv preprint arXiv:2506.20675, 2025
Anish Saxena, Po-An Tsai, Hritvik Taneja, Aamer Jaleel, and Moinuddin Qureshi. Utility-driven spec- ulative decoding for mixture-of-experts.arXiv preprint arXiv:2506.20675, 2025
-
[51]
Amd “helios”: Advancing openness in ai in- frastructure built on meta’s 2025 ocp open rack for ai design.AMD Blog, 2025
Ronak Shah, Mahesh Balasubramanian, and Vince Hache. Amd “helios”: Advancing openness in ai in- frastructure built on meta’s 2025 ocp open rack for ai design.AMD Blog, 2025
2025
-
[52]
Arman Shehabi, Andrew Newkirk, Sarah Smith, Aimee Hubbard, N. Lei, M. Siddik, et al. 2024 united states data center energy usage report. Tech- nical Report LBNL-2001637, Lawrence Berke- ley National Laboratory, 2024. Retrieved from https://escholarship.org/uc/item/32d6m0d1
2024
-
[53]
Brighten Godfrey
Ankit Singla, Chi-Yao Hong, Lucian Popa, and P. Brighten Godfrey. Jellyfish: Networking data centers randomly. In9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12), pages 225–238, San Jose, CA, April 2012. USENIX Associa- tion
2012
-
[54]
Valamanchili
Young-Joo Suh and S. Valamanchili. All to-all commu- nication with minimum start-up costs in 2d/3d tori and meshes.IEEE Transactions on Parallel and Distributed Systems, 9(5):442–458, 1998
1998
-
[55]
Kimi Team, Yifan Bai, Yiping Bao, Y . Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Ji- ahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Ke- lin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizho...
work page internal anchor Pith review arXiv 2026
-
[56]
Deploying DeepSeek with PD Dis- aggregation and Large-Scale Expert Parallelism on 96 H100 GPUs
The SGLang Team. Deploying DeepSeek with PD Dis- aggregation and Large-Scale Expert Parallelism on 96 H100 GPUs. LMSYS Blog https://www.lmsys.org/ blog/2025-05-05-large-scale-ep/ . [Accessed 21- 04-2026]
2025
-
[57]
Optimization of collective communication operations in mpich.IJHPCA, 19:49–66, 01 2005
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. Optimization of collective communication operations in mpich.IJHPCA, 19:49–66, 01 2005
2005
-
[58]
Xpander: Towards optimal- performance datacenters
Asaf Valadarsky, Gal Shahaf, Michael Dinitz, and Michael Schapira. Xpander: Towards optimal- performance datacenters. InProceedings of the 12th International on Conference on Emerging Network- ing EXperiments and Technologies, CoNEXT ’16, page 205–219, New York, NY , USA, 2016. Association for Computing Machinery
2016
-
[59]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Asso- ciates Inc
2017
-
[60]
Overlap communication with dependent computation via decomposition in large deep learning models
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, et al. Overlap communication with dependent computation via decomposition in large deep learning models. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Langua...
2022
-
[61]
Rail-only: A low-cost high-performance network for training llms with tril- lion parameters
Weiyang Wang, Manya Ghobadi, Kayvon Shakeri, Ying Zhang, and Naader Hasani. Rail-only: A low-cost high-performance network for training llms with tril- lion parameters. In2024 IEEE Symposium on High- Performance Interconnects (HOTI), pages 1–10, 2024
2024
-
[62]
{TopoOpt}: Co- optimizing network topology and parallelization strategy for distributed training jobs
Weiyang Wang, Moein Khazraee, Zhizhen Zhong, Manya Ghobadi, Zhihao Jia, Dheevatsa Mudigere, Ying Zhang, and Anthony Kewitsch. {TopoOpt}: Co- optimizing network topology and parallelization strategy for distributed training jobs. In20th USENIX Sympo- sium on Networked Systems Design and Implementation (NSDI 23), pages 739–767, 2023
2023
-
[63]
Hyperscaler capex > $600 bn in 2026: a 36% increase over 2025 while global spend- ing on cloud infrastructure services skyrockets
Alan Weissberger. Hyperscaler capex > $600 bn in 2026: a 36% increase over 2025 while global spend- ing on cloud infrastructure services skyrockets. IEEE ComSoc Technology Blog, 2025
2026
-
[64]
Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
Samuel Williams, Andrew Waterman, and David Patter- son. Roofline: an insightful visual performance model for multicore architectures.Communications of the ACM, 52(4):65–76, 2009
2009
-
[65]
Tacos: Topology-aware collective algorithm synthesizer for distributed machine learning
William Won, Midhilesh Elavazhagan, Sudarshan Srini- vasan, Swati Gupta, and Tushar Krishna. Tacos: Topology-aware collective algorithm synthesizer for distributed machine learning. InProceedings of the 2024 57th IEEE/ACM International Symposium on Mi- croarchitecture, MICRO ’24, page 856–870. IEEE Press, 2024
2024
-
[66]
Yiting Xia, Xiaoye Steven Sun, Simbarashe Dzina- marira, Dingming Wu, Xin Sunny Huang, and T. S. Eu- gene Ng. A tale of two topologies: Exploring convertible data center network architectures with flat-tree. InPro- ceedings of the Conference of the ACM Special Interest Group on Data Communication, SIGCOMM ’17, page 295–308, New York, NY , USA, 2017. Assoc...
2017
-
[67]
Autoccl: automated collective communication tuning for accelerating dis- tributed and parallel dnn training
Guanbin Xu, Zhihao Le, Yinhe Chen, Zhiqi Lin, Zewen Jin, Youshan Miao, and Cheng Li. Autoccl: automated collective communication tuning for accelerating dis- tributed and parallel dnn training. InProceedings of the 22nd USENIX Symposium on Networked Systems Design and Implementation, NSDI ’25, USA, 2025. USENIX Association
2025
-
[68]
Efficient all-to- all broadcast in all-port mesh and torus networks
Yuanyuan Yang and Jianchao Wang. Efficient all-to- all broadcast in all-port mesh and torus networks. In Proceedings Fifth International Symposium on High- Performance Computer Architecture, pages 290–299, 1999. 17
1999
-
[69]
Rethinking llm inference bottlenecks: Insights from latent attention and mixture-of-experts, 2026
Sungmin Yun, Seonyong Park, Hwayong Nam, Youn- joo Lee, Gunjun Lee, Kwanhee Kyung, Sangpyo Kim, Nam Sung Kim, Jongmin Kim, Hyungyo Kim, Juhwan Cho, Seungmin Baek, and Jung Ho Ahn. Rethinking llm inference bottlenecks: Insights from latent attention and mixture-of-experts, 2026. arXiv:2507.15465
-
[70]
Janus: Disaggregating Attention and Experts for Scalable MoE Inference
Zhexiang Zhang, Ye Wang, Xiangyu Wang, Yumiao Zhao, Jingzhe Jiang, Qizhen Weng, Shaohuai Shi, Yin Chen, and Minchen Yu. Janus: Disaggregating attention and experts for scalable moe inference.arXiv preprint arXiv:2512.13525, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
WildChat : 1M ChatGPT Interaction Logs in the Wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chat- gpt interaction logs in the wild.arXiv preprint arXiv:2405.01470, 2024
-
[72]
Dist- serve: Disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- serve: Disaggregating prefill and decoding for goodput- optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024
2024
-
[73]
Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems, 35:7103–7114, 2022
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al. Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems, 35:7103–7114, 2022
2022
-
[74]
{NanoFlow}: Towards opti- mal large language model serving throughput
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Zihao Ye, Keisuke Kama- hori, Chien-Yu Lin, et al. {NanoFlow}: Towards opti- mal large language model serving throughput. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 749–765, 2025
2025
-
[75]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. Megascale- infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism. InPro...
2025
-
[76]
Resiliency at scale: managing google’s tpuv4 machine learning supercomputer
Yazhou Zu, Alireza Ghaffarkhah, Hoang-Vu Dang, Brian Towles, Steven Hand, Safeen Huda, Adekunle Bello, Alexander Kolbasov, Arash Rezaei, Dayou Du, Steve Lacy, Hang Wang, Aaron Wisner, Chris Lewis, and Henri Bahini. Resiliency at scale: managing google’s tpuv4 machine learning supercomputer. InProceed- ings of the 21st USENIX Symposium on Networked Sys- te...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.