Recognition: unknown
MemRouter: Memory-as-Embedding Routing for Long-Term Conversational Agents
Pith reviewed 2026-05-09 19:44 UTC · model grok-4.3
The pith
A lightweight embedding router decides which conversation turns to store, outperforming LLM-based memory management on accuracy while reducing latency by over 90 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemRouter encodes each conversation turn together with recent context through a frozen LLM backbone, projects the embeddings, and uses lightweight classification heads to predict whether the turn should be admitted to external memory. Only the 12M parameters in the projection layers and heads are trained while the backbone and downstream QA model stay frozen. Under identical retrieval, prompting, and Qwen2.5-7B conditions on LoCoMo, the router achieves 52.0 overall F1 versus 45.6 for an LLM-based memory manager with non-overlapping 95% confidence intervals and reduces p50 memory-management latency from 970 ms to 58 ms.
What carries the argument
The embedding-based routing policy that decouples memory admission from answer generation by classifying frozen-LLM projections of turn-plus-context embeddings with small heads.
Load-bearing premise
The embedding produced by the frozen LLM backbone plus recent context contains enough information for a lightweight classifier to make memory-admission decisions that are at least as good as those made by full autoregressive LLM generation.
What would settle it
A head-to-head test on a new dataset of longer or noisier conversations where the router's F1 score falls below the LLM manager's would falsify the claim that the embeddings suffice.
Figures



read the original abstract
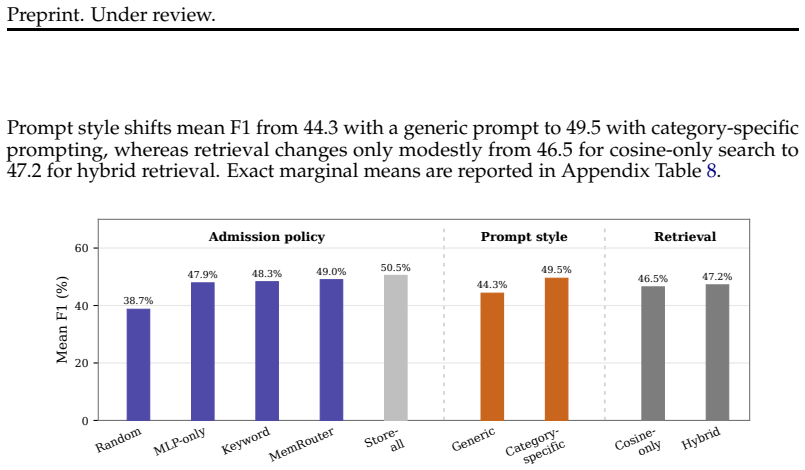
Long-term conversational agents must decide which turns to store in external memory, yet recent systems rely on autoregressive LLM generation at every turn to make that decision. We present MemRouter, a write-side memory router that decouples memory admission from the downstream answer backbone and replaces per-turn memory-management decoding with an embedding-based routing policy. MemRouter encodes each turn together with recent context, projects the resulting embeddings through a frozen LLM backbone, and predicts whether the turn should be stored using lightweight classification heads while training only 12M parameters. Under a controlled matched-harness comparison on LoCoMo, where the retrieval pipeline, answer prompts, and QA backbone (Qwen2.5-7B) are held identical, MemRouter outperforms an LLM-based memory manager on every question category (overall F1 52.0 vs 45.6, non-overlapping 95% CIs) while reducing memory-management p50 latency from 970ms to 58ms. Descriptive factorial averaging further shows that learned admission improves mean F1 by +10.3 over random storage, category-specific prompting adds +5.2 over a generic prompt, and retrieval contributes +0.7. These results suggest that write-side memory admission can be learned by a small supervised router, while answer generation remains a separate downstream component in long-horizon conversational QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MemRouter, a write-side memory router for long-term conversational agents that encodes each turn with recent context through a frozen LLM backbone (Qwen2.5-7B), projects the embeddings, and uses lightweight classification heads (12M trainable parameters) to predict memory admission. Under a controlled matched-harness evaluation on LoCoMo with identical retrieval pipeline, answer prompts, and QA backbone, it reports higher overall F1 (52.0 vs 45.6, non-overlapping 95% CIs) than an LLM-based memory manager while reducing p50 memory-management latency from 970 ms to 58 ms. A descriptive factorial analysis attributes +10.3 F1 to learned admission, +5.2 to category-specific prompting, and +0.7 to retrieval.
Significance. If the results hold, the work shows that memory admission decisions can be decoupled from answer generation and handled efficiently by a small supervised router using frozen embeddings, yielding both accuracy and latency gains in long-horizon conversational QA. The controlled experimental design with fixed downstream components and the reporting of confidence intervals strengthen causal attribution of the gains. The factorial decomposition of component contributions is a positive methodological feature that improves interpretability.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): The description of router training provides no information on training data construction or the provenance and quality of supervision labels for the memory-admission classification task. This is load-bearing for the central claim because the reported F1 advantage (52.0 vs 45.6) depends on the lightweight heads learning decisions at least as good as those of the autoregressive baseline; without details on label source (e.g., whether derived from the LLM manager, human annotation, or another procedure), it is impossible to exclude that observed gains are artifacts of the labeling process rather than evidence for embedding-based routing.
- [Abstract and §5] Abstract and §5 (Results): No ablation or analysis is presented on whether the frozen LLM embeddings retain decision-critical features such as long-range relevance signals, subtle contradictions, or multi-turn dependencies that the autoregressive LLM can access. This directly affects interpretation of the headline result, because the 12M-parameter heads can only succeed if the embedding projection plus recent context already encodes the necessary information; the absence of such a check leaves open the possibility that the F1 and latency improvements are specific to the particular label-generation regime rather than generally attributable to the proposed architecture.
minor comments (2)
- [Abstract] The abstract refers to 'descriptive factorial averaging' without specifying the exact procedure, assumptions, or statistical controls used; the main text should expand this to support reproducibility.
- [§5] Results tables reporting per-category F1 and confidence intervals should include the number of evaluation instances per category so readers can assess the reliability of the non-overlapping CIs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving methodological transparency and interpretability. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The description of router training provides no information on training data construction or the provenance and quality of supervision labels for the memory-admission classification task. This is load-bearing for the central claim because the reported F1 advantage (52.0 vs 45.6) depends on the lightweight heads learning decisions at least as good as those of the autoregressive baseline; without details on label source (e.g., whether derived from the LLM manager, human annotation, or another procedure), it is impossible to exclude that observed gains are artifacts of the labeling process rather than evidence for embedding-based routing.
Authors: We agree that the manuscript omits critical details on training data construction and the source of supervision labels, and that this information is necessary to fully support the central claims. The referee is correct that without it, alternative explanations for the F1 gains cannot be ruled out. In the revised manuscript we will add a dedicated subsection to §3 that fully describes the training data construction process, the procedure used to generate the memory-admission labels, and any steps taken to ensure label quality and independence from the LLM baseline. This addition will directly address the concern. revision: yes
-
Referee: [Abstract and §5] Abstract and §5 (Results): No ablation or analysis is presented on whether the frozen LLM embeddings retain decision-critical features such as long-range relevance signals, subtle contradictions, or multi-turn dependencies that the autoregressive LLM can access. This directly affects interpretation of the headline result, because the 12M-parameter heads can only succeed if the embedding projection plus recent context already encodes the necessary information; the absence of such a check leaves open the possibility that the F1 and latency improvements are specific to the particular label-generation regime rather than generally attributable to the proposed architecture.
Authors: We agree that an explicit analysis of the information retained in the frozen embeddings would improve the strength of the architectural claims. Although the controlled matched-harness evaluation and the factorial decomposition provide indirect support that the embeddings encode sufficient decision-relevant information, we acknowledge the gap identified by the referee. In the revised §5 we will add a targeted analysis that probes the embeddings for long-range relevance signals, sensitivity to contradictions, and multi-turn dependencies using both existing and synthetic examples. This will help clarify the contribution of the embedding-based approach. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are externally measured
full rationale
The paper reports an empirical system comparison on the LoCoMo benchmark under a matched-harness setup that fixes the retrieval pipeline, answer prompts, and QA backbone (Qwen2.5-7B). The headline metrics (F1 52.0 vs 45.6, latency 58ms vs 970ms) are direct experimental outcomes, not quantities obtained by fitting parameters inside the same system and then re-deriving them. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the provided text; the 12M trainable parameters are used only for the lightweight router heads, whose decisions are evaluated on held-out benchmark performance. The result is therefore self-contained against an external benchmark and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- 12M router parameters
axioms (1)
- domain assumption Embeddings from the frozen LLM backbone plus recent context contain sufficient signal for accurate memory-admission classification
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2402.11975. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory,
-
[2]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
URL https: //arxiv.org/abs/2504.19413. Xingbo Du, Loka Li, Duzhen Zhang, and Le Song. Memr 3: Memory retrieval via reflective reasoning for llm agents,
work page internal anchor Pith review arXiv
-
[3]
Memr3: Memory retrieval via reflective reasoning for llm agents.arXiv preprint arXiv:2512.20237,
URLhttps://arxiv.org/abs/2512.20237. Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hia- gent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. InProceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pp. 32779–327...
-
[4]
URL https://doi.org/10.18653/v1/2025.acl-long.1575
doi: 10.18653/v1/2025.acl-long.1575. URL https://doi.org/10.18653/v1/2025.acl-long.1575. 10 Preprint. Under review. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong...
-
[5]
Memory in the Age of AI Agents
URLhttps://arxiv.org/abs/2512.13564. Jiazheng Kang et al. MemoryOS: An operating system for llm agent long-term memory. arXiv preprint arXiv:2506.06326, 2025a. Minki Kang, Wei-Ning Chen, Dongge Han, Huseyin A. Inan, Lukas Wutschitz, Yanzhi Chen, Robert Sim, and Saravan Rajmohan. Acon: Optimizing context compression for long-horizon llm agents, 2025b. URLh...
work page internal anchor Pith review arXiv 2025
-
[6]
Hello Again! LLM -powered Personalized Agent for Long-term Dialogue
doi: 10.18653/v1/2025.naacl-long.272. URL https://aclanthology.org/2025.naacl-long.272/. Jun Liu, Zhenglun Kong, Changdi Yang, Fan Yang, Tianqi Li, Peiyan Dong, Joannah Nan- jekye, Hao Tang, Geng Yuan, Wei Niu, Wenbin Zhang, Pu Zhao, Xue Lin, Dong Huang, and Yanzhi Wang. Rcr-router: Efficient role-aware context routing for multi-agent llm systems with str...
-
[7]
Rcr- router: Efficient role-aware context routing for multi-agent LLM systems with structured memory
URLhttps://arxiv.org/abs/2508.04903. Mingfei Lu, Mengjia Wu, Feng Liu, Jiawei Xu, Weikai Li, Haoyang Wang, Zhengdong Hu, Ying Ding, Yizhou Sun, Jie Lu, and Yi Zhang. Choosing how to remember: Adaptive memory structures for llm agents,
-
[8]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang
URLhttps://arxiv.org/abs/2602.14038. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 13851–13870. Association for Computatio...
-
[9]
Evaluating very long-term conversational memory of LLM agents
18653/v1/2024.acl-long.747. URLhttps://doi.org/10.18653/v1/2024.acl-long.747. Jiayan Nan, Wenquan Ma, Wenlong Wu, and Yize Chen. Nemori: Self-organizing agent memory inspired by cognitive science,
-
[10]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
URLhttps://arxiv.org/abs/2508.03341. Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
MemGPT: Towards LLMs as Operating Systems
URL https: //arxiv.org/abs/2310.08560. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pp. 1–22. ACM,
work page internal anchor Pith review arXiv
-
[12]
doi: 10.1145/3586183.3606763. URL https://doi.org/10.1145/ 3586183.3606763. Mathis Pink, Qinyuan Wu, Vy Ai Vo, Javier Turek, Jianing Mu, Alexander Huth, and Mariya Toneva. Position: Episodic memory is the missing piece for long-term llm agents,
- [13]
-
[14]
URLhttps://arxiv.org/abs/2503.21760. 11 Preprint. Under review. Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture- of-experts layer,
-
[15]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
URLhttps://arxiv.org/abs/1701.06538. Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long T. Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, Anand Iyer, Tianlong Chen, Huan Liu, Chen-Yu Lee, and Tomas Pfister. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding
URL https://arxiv.org/abs/2503.08026. Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. Re- cursively summarizing enables long-term dialogue memory in large language mod- els.Neurocomputing, 639:130193, jul 2025a. doi: 10.1016/j.neucom.2025.130193. URL https://doi.org/10.1016/j.neucom.2025.130193. Weizhi Wang, Li Dong, Hao Chen...
-
[17]
URLhttps://doi.org/10.52202/075280-3259
doi: 10.52202/075280-3259. URLhttps://doi.org/10.52202/075280-3259. Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. Mem-α: Learning memory construction via reinforcement learning, 2025b. URLhttps://arxiv.org/abs/2509.25911. Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEv...
-
[18]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
URL https://arxiv.org/abs/2410.10813. Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-Pack: Packed resources for general chinese embeddings,
work page internal anchor Pith review arXiv
-
[19]
C-Pack: Packed Resources For General Chinese Embeddings
URL https: //arxiv.org/abs/2309.07597. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents,
work page internal anchor Pith review arXiv
-
[20]
URLhttps://arxiv.org/abs/2502.12110. Xun Xu. G-memllm: Gated latent memory augmentation for long-context reasoning in large language models,
work page internal anchor Pith review arXiv
-
[21]
URLhttps://arxiv.org/abs/2602.00015. Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, Volker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning,
-
[22]
URLhttps://arxiv.org/abs/2508.19828. Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents,
work page internal anchor Pith review arXiv
-
[23]
URLhttps://arxiv.org/abs/2601.01885. Guilin Zhang, Wei Jiang, Xiejiashan Wang, Aisha Behr, Kai Zhao, Jeffrey Friedman, Xu Chu, and Amine Anoun. Adaptive memory admission control for llm agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
URL https://arxiv.org/abs/2603.04549. Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model- based agents.ACM Transactions on Information Systems, 43(6):1–47, sep
-
[25]
ACM Transactions on Information Systems , year =
doi: 10.1145/ 3748302. URLhttps://doi.org/10.1145/3748302. Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhanc- ing large language models with long-term memory.Proceedings of the AAAI Conference on Artificial Intelligence, 38(17):19724–19731, mar
-
[26]
doi: 10.1609/aaai.v38i17.29946. URL https://doi.org/10.1609/aaai.v38i17.29946. 12 Preprint. Under review. A Experimental Details This appendix first summarizes the dataset, evaluation protocol, and implementation set- tings used throughout the paper. A.1 Dataset and Evaluation Details Benchmark.We evaluate on LoCoMo (Maharana et al., 2024), the standard b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.