Recognition: unknown
FollowTable: A Benchmark for Instruction-Following Table Retrieval
Pith reviewed 2026-05-09 19:09 UTC · model grok-4.3
The pith
Existing table retrieval models fail to adapt rankings to explicit user instructions on content scope and schema details.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instruction-Following Table Retrieval requires models to jointly handle topical relevance and fine-grained constraints on content inclusion, exclusion, column semantics, and representation granularity. The FollowTable benchmark supplies the first large-scale test collection for this capability through a taxonomy-driven annotation process that generates instruction-augmented queries along with corresponding relevance labels. Evaluation with the new Instruction Responsiveness Score reveals that existing retrieval models exhibit systematic biases toward surface-level semantic cues and remain limited when handling schema-grounded constraints.
What carries the argument
FollowTable benchmark, a dataset of queries and relevance judgments created via taxonomy-driven annotation that encodes both content-scope constraints and schema-grounded requirements.
If this is right
- Table retrieval systems must move beyond pure semantic similarity and incorporate explicit mechanisms for parsing and enforcing user constraints.
- Future benchmarks for structured data retrieval should routinely include instruction variants rather than relying solely on topical queries.
- Agentic applications that access tabular data will need retrieval components specifically tuned to respect detailed directives about scope and schema.
Where Pith is reading between the lines
- FollowTable could serve as a fine-tuning resource to train retrievers that better separate instruction parsing from embedding-based matching.
- The observed limitations suggest that hybrid architectures combining instruction parsers with traditional retrievers might outperform purely end-to-end models on this task.
Load-bearing premise
The taxonomy-driven annotation pipeline produces queries and relevance judgments that faithfully represent real-world instruction-following needs for table retrieval.
What would settle it
If models that perform well on FollowTable show no measurable improvement when tested against a separate collection of naturally occurring user instructions collected from actual database interfaces, the benchmark would fail to demonstrate practical progress.
Figures




read the original abstract
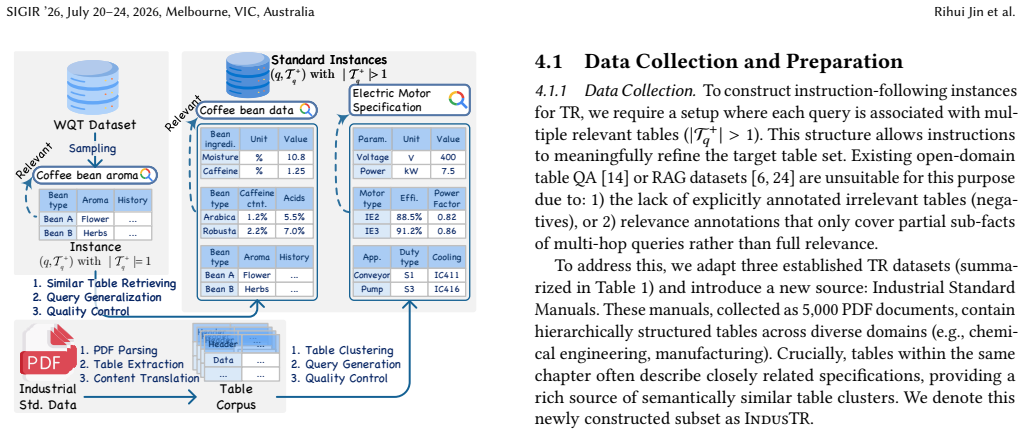
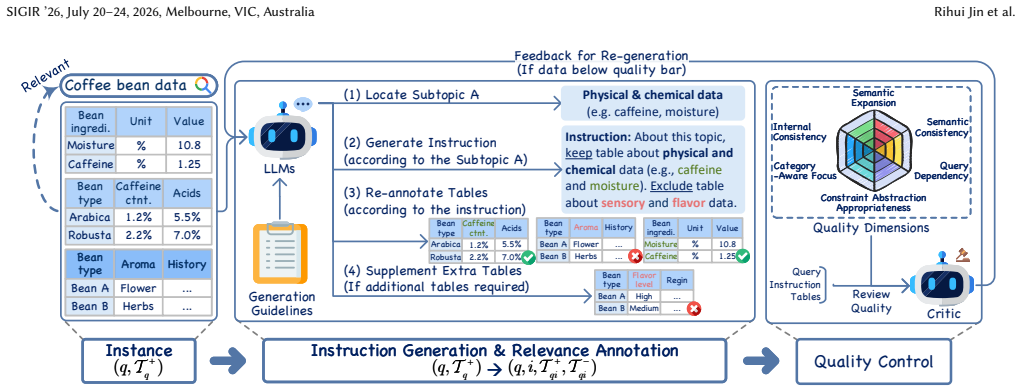
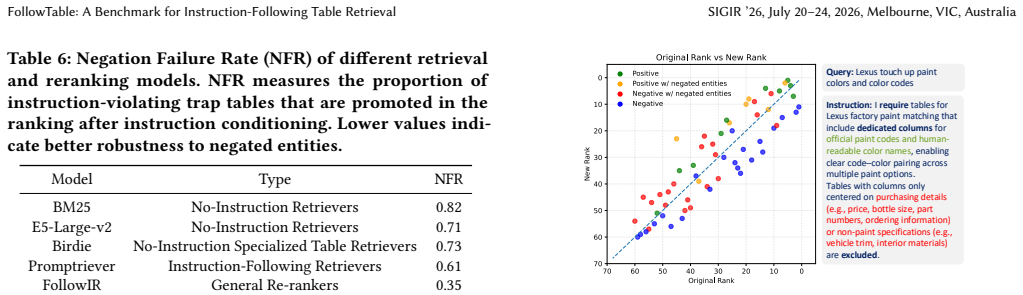
Table Retrieval (TR) has traditionally been formulated as an ad-hoc retrieval problem, where relevance is primarily determined by topical semantic similarity. With the growing adoption of LLM-based agentic systems, access to structured data is increasingly instruction-driven, where relevance is conditional on explicit content and schema constraints rather than topical similarity alone. We therefore formalize Instruction-Following Table Retrieval (IFTR), a new task that requires models to jointly satisfy topical relevance and fine-grained instruction constraints. We identify two core challenges in IFTR: (i) sensitivity to content scope, such as inclusion and exclusion constraints, and (ii) awareness of schema-grounded requirements, including column semantics and representation granularity--capabilities largely absent in existing retrievers. To support systematic evaluation, we introduce FollowTable, the first large-scale benchmark for IFTR, constructed via a taxonomy-driven annotation pipeline. We further propose a new metric, termed the Instruction Responsiveness Score, to evaluate whether retrieval rankings consistently adapt to user instructions relative to a topic-only baseline. Our results indicate that existing retrieval models struggle to follow fine-grained instructions over tabular data. In particular, they exhibit systematic biases toward surface-level semantic cues and remain limited in handling schema-grounded constraints, highlighting substantial room for future improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes Instruction-Following Table Retrieval (IFTR) as a task requiring models to satisfy both topical relevance and explicit content/schema constraints when retrieving tables. It introduces FollowTable, a large-scale benchmark constructed via a taxonomy-driven annotation pipeline, along with the Instruction Responsiveness Score metric that measures how retrieval rankings adapt to instructions relative to a topic-only baseline. Experiments indicate that existing retrievers exhibit systematic biases toward surface-level semantic cues and struggle with inclusion/exclusion constraints and schema-grounded requirements.
Significance. If the benchmark construction is validated, the work provides a timely evaluation framework for retrieval in LLM-agentic settings where access to structured data is instruction-driven rather than purely ad-hoc. The proposal of a dedicated responsiveness metric and the identification of specific failure modes (content scope and schema awareness) are constructive contributions that could stimulate targeted model improvements.
major comments (2)
- [Abstract and §3] Abstract and §3 (Benchmark Construction): the taxonomy-driven annotation pipeline is presented without evidence that the taxonomy was derived from real user logs, that constraint-type distributions match observed needs, or that relevance judgments received multi-expert validation rather than heuristic rules. This is load-bearing for the central claim that observed model biases reflect genuine limitations rather than benchmark artifacts.
- [§5] §5 (Results and Analysis): no details are supplied on train/test splits, statistical significance of performance gaps, or systematic error analysis. Without these, it is impossible to determine whether the reported struggles with schema-grounded constraints are robust or sensitive to particular query subsets.
minor comments (1)
- [§4] The formal definition of the Instruction Responsiveness Score would benefit from an explicit equation showing its computation relative to the topic-only baseline ranking.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work formalizing Instruction-Following Table Retrieval and introducing the FollowTable benchmark. The comments highlight important aspects of benchmark validity and experimental rigor. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Construction): the taxonomy-driven annotation pipeline is presented without evidence that the taxonomy was derived from real user logs, that constraint-type distributions match observed needs, or that relevance judgments received multi-expert validation rather than heuristic rules. This is load-bearing for the central claim that observed model biases reflect genuine limitations rather than benchmark artifacts.
Authors: We agree that stronger grounding for the taxonomy would further support the benchmark's validity. The taxonomy was developed through a systematic review of instruction patterns in structured data access scenarios drawn from prior IR and database literature, rather than proprietary user logs (which were unavailable). In the revision, we will expand §3 with an explicit subsection detailing the taxonomy construction process, including the sources consulted and the rationale for each constraint category. We will also report the observed distributions of constraint types in FollowTable and compare them qualitatively to needs reported in related work on agentic table access. For relevance judgments, the large-scale pipeline combines automated heuristics with rule-based verification to ensure consistency and scalability; we acknowledge this falls short of multi-expert human validation. We will add a dedicated limitations paragraph discussing potential artifacts and include results from a small-scale expert validation study (conducted post-submission on a 200-query subset) showing high agreement with the heuristic labels. These changes will allow readers to better assess whether the reported model biases are robust. revision: partial
-
Referee: [§5] §5 (Results and Analysis): no details are supplied on train/test splits, statistical significance of performance gaps, or systematic error analysis. Without these, it is impossible to determine whether the reported struggles with schema-grounded constraints are robust or sensitive to particular query subsets.
Authors: We appreciate this observation and will strengthen the experimental reporting. The train/test split construction (70/30 stratified by constraint type and table domain) is described in §4, but we will move the details into §5 with explicit proportions, seed values, and a table summarizing subset sizes. We will add statistical significance testing using paired Wilcoxon signed-rank tests with Bonferroni correction for the key performance gaps, reporting p-values and effect sizes. Finally, we will insert a new error analysis subsection that breaks down failures by constraint category (content-scope vs. schema-grounded) and by query subsets (e.g., simple vs. compound instructions), including qualitative examples of persistent failure modes. These additions will directly address concerns about robustness. revision: yes
- Direct evidence that the taxonomy was derived from real user logs cannot be provided, as no such logs were used in the benchmark construction.
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper presents an empirical benchmark (FollowTable) and metric (Instruction Responsiveness Score) for a newly formalized task (IFTR). No equations, fitted parameters, predictions, or self-citations are used as load-bearing steps in any derivation. The taxonomy-driven pipeline is described as a construction method for the benchmark, and performance claims are direct empirical observations on that benchmark rather than reductions to prior inputs by construction. This is a standard benchmark paper with self-contained empirical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relevance for table retrieval can be meaningfully decomposed into topical similarity plus independent instruction constraints on content and schema.
invented entities (1)
-
Instruction Responsiveness Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mohammad Mahdi Abootorabi, Amirhosein Zobeiri, Mahdi Dehghani, Moham- madali Mohammadkhani, Bardia Mohammadi, Omid Ghahroodi, Mahdieh So- leymani Baghshah, and Ehsaneddin Asgari. 2025. Ask in Any Modality: A Com- prehensive Survey on Multimodal Retrieval-Augmented Generation. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, A...
2025
-
[2]
Negar Arabzadeh, Ziheng Chen, Fabio Petroni, Federico Siciliano, Fabrizio Sil- vestri, and Giovanni Trappolini. 2025. IR-RAG @SIGIR25: The Second Edition of the Workshop on Information Retrieval’s Role in RAG Systems. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in In- formation Retrieval, SIGIR 2025, Padua, Ita...
-
[3]
Jan-Micha Bodensohn and Carsten Binnig. 2024. Rethinking Table Retrieval from Data Lakes. InProceedings of the Seventh International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM 2024, Santiago, Chile, 14 June 2024. ACM, 2:1–2:5. doi:10.1145/3663742.3663972
- [4]
-
[5]
Peter Baile Chen, Yi Zhang, and Dan Roth. 2024. Is Table Retrieval a Solved Problem? Exploring Join-Aware Multi-Table Retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Associatio...
-
[6]
Wenhu Chen, Ming-Wei Chang, Eva Schlinger, William Yang Wang, and William W. Cohen. 2021. Open Question Answering over Tables and Text. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id= MmCRswl1UYl
2021
-
[7]
Zhiyu Chen, Mohamed Trabelsi, Jeff Heflin, Yinan Xu, and Brian D. Davison
-
[8]
Table Search Using a Deep Contextualized Language Model. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 589–598. doi:10.1145/3397...
-
[9]
Zhiyu Chen, Shuo Zhang, and Brian D. Davison. 2021. WTR: A Test Collection for Web Table Retrieval. InSIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 251...
-
[10]
DeepMind. 2025. Gemini-3-Pro Model Card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
2025
-
[11]
Haoyu Dong, Zhoujun Cheng, Xinyi He, Mengyu Zhou, Anda Zhou, Fan Zhou, Ao Liu, Shi Han, and Dongmei Zhang. 2022. Table Pre-training: A Survey on Model Architectures, Pre-training Objectives, and Downstream Tasks. InProceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, Luc D...
- [12]
-
[13]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo
-
[14]
A Survey on LLM-as-a-Judge.CoRRabs/2411.15594 (2024). arXiv:2411.15594 doi:10.48550/ARXIV.2411.15594
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2024
- [15]
-
[17]
Jonathan Herzig, Thomas Müller, Syrine Krichene, and Julian Martin Eisenschlos
-
[18]
Open Domain Question Answering over Tables via Dense Retrieval. In Proceedings of the 2021 Conference of the North American Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, Kristina Toutanova, Anna Rumshisky, Luke Zettle- moyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, ...
-
[19]
Kalervo Järvelin and Jaana Kekäläinen. 2002. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems (TOIS)20, 4 (2002), 422–446
2002
-
[20]
Xingyu Ji, Parker Glenn, Aditya G Parameswaran, and Madelon Hulsebos
- [21]
-
[22]
Nengzheng Jin, Dongfang Li, Junying Chen, Joanna Siebert, and Qingcai Chen
-
[23]
Enhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval. InProceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia- Pacific Chapter of the Association for Computational Linguistics, IJCNLP 2023 - Volume 2: Short Papers, Nusa Dua, Bali, November 1-4, 202...
2023
-
[24]
Rihui Jin, Jianan Wang, Wei Tan, Yongrui Chen, Guilin Qi, and Wang Hao. 2023. Tabprompt: Graph-based pre-training and prompting for few-shot table under- standing. InFindings of the Association for Computational Linguistics: EMNLP
2023
-
[25]
Da Li, Keping Bi, Jiafeng Guo, and Xueqi Cheng. 2025. Bridging Queries and Tables through Entities in Open-Domain Table Retrieval. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM 2025, Seoul, Republic of Korea, November 10-14, 2025, Meeyoung Cha, Chanyoung Park, Noseong Park, Carl Yang, Senjuti Basu Roy...
-
[26]
Da Li, Keping Bi, Jiafeng Guo, and Xueqi Cheng. 2025. Tailoring Table Re- trieval from a Field-aware Hybrid Matching Perspective. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Chris- tos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzho...
-
[27]
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. 2024. Fine- Tuning LLaMA for Multi-Stage Text Retrieval. InProceedings of the 47th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and ...
-
[28]
Dehai Min, Nan Hu, Rihui Jin, Nuo Lin, Jiaoyan Chen, Yongrui Chen, Yu Li, Guilin Qi, Yun Li, Nijun Li, et al. 2024. Exploring the Impact of Table-to-Text Methods on Augmenting LLM-based Question Answering with Domain Hybrid Data. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lang...
2024
-
[29]
Dehai Min, Zhiyang Xu, Guilin Qi, Lifu Huang, and Chenyu You. 2025. UniHGKR: unified instruction-aware heterogeneous knowledge retrievers. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 4577–4594
2025
-
[30]
Bhaskar Miutra and Nick Craswell. 2018. An introduction to neural information retrieval.Foundations and Trends ˆW in Accounting13, 1 (2018), 1–126
2018
-
[31]
Niklas Muennighoff, Hongjin Su, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. 2025. Generative Representational In- struction Tuning. InThe Thirteenth International Conference on Learning Rep- resentations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https: //openreview.net/forum?id=BC4lIvfSzv
2025
-
[32]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. 2023. MTEB: Massive Text Embedding Benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics
2023
- [33]
-
[34]
Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. 2021. KILT: a Benchmark for Knowledge-Intensive Language Tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Langua...
2021
- [35]
-
[36]
The probabilistic relevance framework: Bm25 and beyond
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389. doi:10.1561/1500000019
- [37]
-
[38]
Roee Shraga, Haggai Roitman, Guy Feigenblat, and Mustafa Canim. 2020. Web Table Retrieval using Multimodal Deep Learning. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, ...
-
[39]
Tingyu Song, Guo Gan, Mingsheng Shang, and Yilun Zhao. 2025. IFIR: A Com- prehensive Benchmark for Evaluating Instruction-Following in Expert-Domain Information Retrieval. InProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
2025
-
[40]
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. 2023. One embedder, any task: Instruction-finetuned text embeddings. InFindings of the Association for Computational Linguistics: ACL 2023. 1102–1121
2023
-
[41]
Wenhao Sun, Zhiqing Shi, Wenjie Long, Lei Yan, Xinyu Ma, Yixin Liu, Ming Cao, Da Yin, and Zhiyuan Ren. 2024. MAIR: A Massive Benchmark for Evaluating Instructed Retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
2024
-
[42]
Yibo Sun, Zhao Yan, Duyu Tang, Nan Duan, and Bing Qin. 2019. Content- based table retrieval for web queries.Neurocomputing349 (2019), 183–189. doi:10.1016/J.NEUCOM.2018.10.033
-
[43]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-Shot Evaluation of Information Retrieval Models. InProceedings of the 35th Conference on Neural Information Processing Systems (Datasets and Benchmarks Track)
2021
-
[44]
Yong-En Tian, Yu-Chien Tang, Kuang-Da Wang, An-Zi Yen, and Wen-Chih Peng. 2025. Template-Based Financial Report Generation in Agentic and De- composed Information Retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2025, Padua, Italy, July 13-18, 2025, Nicola Ferro, Maria Mais...
-
[45]
Davison, and Jeff Heflin
Mohamed Trabelsi, Zhiyu Chen, Shuo Zhang, Brian D. Davison, and Jeff Heflin
-
[46]
In Proceedings of the ACM Web Conference 2022(Virtual Event, Lyon, France) (WWW ’22)
StruBERT: Structure-aware BERT for Table Search and Matching. In Proceedings of the ACM Web Conference 2022(Virtual Event, Lyon, France) (WWW ’22). Association for Computing Machinery, New York, NY, USA, 442–451. doi:10.1145/3485447.3511972
-
[47]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. 2024. MinerU: An Open-Source Solution for Precise Document Content Extraction. arXiv:2409.18839 [cs.CV] https://arxiv.org/abs/2409.18839
-
[48]
Fei Wang, Kexuan Sun, Muhao Chen, Jay Pujara, and Pedro A. Szekely. 2021. Retrieving Complex Tables with Multi-Granular Graph Representation Learning. InSIGIR ’21: The 44th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Cast...
-
[49]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-training.CoRRabs/2212.03533 (2022). arXiv:2212.03533 doi:10. 48550/ARXIV.2212.03533
work page internal anchor Pith review arXiv 2022
-
[50]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Improving text embeddings with large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 11897–11916
2024
-
[51]
Zhiruo Wang, Zhengbao Jiang, Eric Nyberg, and Graham Neubig. 2022. Table Retrieval May Not Necessitate Table-specific Model Design.CoRRabs/2205.09843 (2022). arXiv:2205.09843 doi:10.48550/ARXIV.2205.09843
-
[52]
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Ben- jamin Van Durme, Dawn Lawrie, and Luca Soldaini. 2025. FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions. InProceed- ings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
2025
-
[53]
Lawrie, Ashwin Paranjape, Yuhao Zhang, and Jack Hessel
Orion Weller, Benjamin Van Durme, Dawn J. Lawrie, Ashwin Paranjape, Yuhao Zhang, and Jack Hessel. 2025. Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=odvSjn416y
2025
-
[54]
Rank1: Test-time compute for reranking in information retrieval.arXiv preprint arXiv:2502.18418,
Orion Weller, Kathryn Ricci, Eugene Yang, Andrew Yates, Dawn J. Lawrie, and Benjamin Van Durme. 2025. Rank1: Test-Time Compute for Rerank- ing in Information Retrieval.CoRRabs/2502.18418 (2025). arXiv:2502.18418 doi:10.48550/ARXIV.2502.18418
-
[55]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval. 641–649
2024
-
[56]
Chuan Xu, Qiaosheng Chen, Yutong Feng, and Gong Cheng. 2025. mmRAG: A modular benchmark for retrieval-augmented generation over text, tables, and SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia Rihui Jin et al. knowledge graphs. InInternational Semantic Web Conference. Springer, 3–21
2025
-
[57]
An Zhang, Yang Deng, Yankai Lin, Xu Chen, Ji-Rong Wen, and Tat-Seng Chua
-
[58]
Large Language Model Powered Agents for Information Retrieval. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18, 2024, Grace Hui Yang, Hongning Wang, Sam Han, Claudia Hauff, Guido Zuccon, and Yi Zhang (Eds.). ACM, 2989–2992. doi:10.1145/3626772.3661375
-
[59]
Shuo Zhang and Krisztian Balog. 2018. Ad Hoc Table Retrieval using Semantic Similarity. InProceedings of the 2018 World Wide Web Conference on World Wide Web, WWW 2018, Lyon, France, April 23-27, 2018, Pierre-Antoine Champin, Fabien Gandon, Mounia Lalmas, and Panagiotis G. Ipeirotis (Eds.). ACM, 1553–1562. doi:10.1145/3178876.3186067
-
[60]
Shuo Zhang and Krisztian Balog. 2020. Web table extraction, retrieval, and augmentation: A survey.ACM Transactions on Intelligent Systems and Technology (TIST)11, 2 (2020), 1–35
2020
-
[61]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review arXiv 2025
-
[62]
Jianqun Zhou, Yuanlei Zheng, Wei Chen, Qianqian Zheng, Hui Su, Wei Zhang, Rui Meng, and Xiaoyu Shen. 2025. Beyond Content Relevance: Evaluating Instruction Following in Retrieval Models. InProceedings of the Thirteenth International Conference on Learning Representations (ICLR)
2025
-
[63]
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, and Ji-Rong Wen. 2025. Large language models for information retrieval: A survey.ACM Transactions on Information Systems44, 1 (2025), 1–54
2025
-
[64]
Guido Zuccon, Shengyao Zhuang, and Xueguang Ma. 2025. R2LLMs: Retrieval and Ranking with LLMs. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 4106–4109
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.