Recognition: unknown
How to Do Statistical Evaluations in ECE/CS Papers: A Practical Playbook for Defensible Results
Pith reviewed 2026-05-09 19:36 UTC · model grok-4.3
The pith
Strong experimental results in ECE/CS depend on a full chain of design, measurement, analysis, and validation choices rather than any single number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Strong experimental papers in ECE/CS rest on a chain of design, measurement, analysis, and validation choices that, taken together, make a result believable. This tutorial is a compact, example-driven guide to that chain organized as an evaluation workflow of claim, hypothesis, unit of analysis, baseline, regime sweep, uncertainty estimate, validation check, and reporting. It covers classical statistical foundations including descriptive statistics, the central limit theorem, confidence intervals, t-tests, ANOVA, chi-squared tests, correlation, and regression alongside modern distribution-free techniques such as the bootstrap, Wilcoxon and Mann-Whitney tests, and Cliff's delta. A running job
What carries the argument
The evaluation workflow sequencing claim formulation through reporting while applying classical and distribution-free statistical techniques to quantify uncertainty and perform validation checks.
Where Pith is reading between the lines
- The same workflow structure could be adapted for empirical work in other engineering fields facing similar measurement challenges.
- Incorporating the playbook into research training might reduce common errors in experimental reporting over time.
- Widespread adoption could encourage journals to require explicit documentation of each workflow step for experimental submissions.
Load-bearing premise
That the classical and modern statistical techniques described, when applied via the workflow and running example, will be sufficient to produce defensible results across the diverse experimental settings in systems, networking, and applied machine learning.
What would settle it
An experimental paper that follows the entire workflow yet produces conclusions later contradicted by independent replication or additional data would show the approach does not always yield defensible results.
Figures






read the original abstract
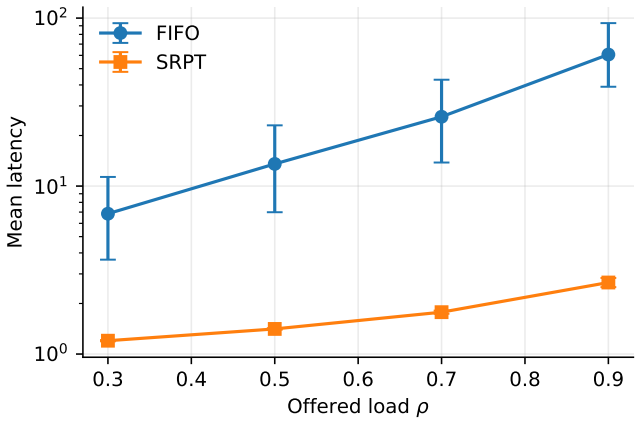
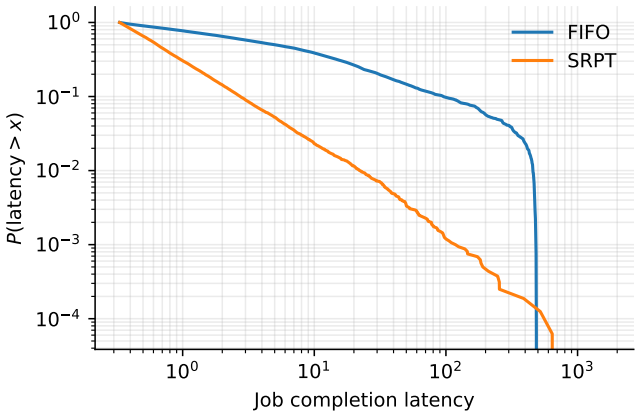
Strong experimental papers in electrical and computer engineering and computer science (ECE/CS), especially in systems, networking, and applied machine learning, rest on more than a single impressive number. They rest on a chain of design, measurement, analysis, and validation choices that, taken together, make a result believable. This tutorial is a compact, example-driven guide to that chain for beginning researchers. We organize it as an evaluation workflow: claim, hypothesis, unit of analysis, baseline, regime sweep, uncertainty estimate, validation check, and reporting. Within that workflow we cover the classical statistical foundations (descriptive statistics, the central limit theorem, normal- and $t$-based confidence intervals, Student's $t$-test, ANOVA, chi-squared and Pearson correlation, linear regression) alongside the modern, distribution-free techniques (the bootstrap, Wilcoxon and Mann--Whitney tests, Cliff's delta) that are usually preferred for ECE/CS data. We also discuss factorial design, randomization and blocking, multiple-comparison correction, latency-specific pitfalls, simulation verification and validation, equivalence-style claims, and reproducibility. A running example, a comparison of two job-scheduling algorithms on simulated workloads with truncated heavy-tailed job sizes, threads through the tutorial, with Python snippets the reader can paste and adapt. The paper closes with a pre-submission checklist; companion student-facing material (project-type translation tables, an evaluation-plan worksheet, exercises, and a worked ``bad evaluation autopsy'') is collected in a separate workbook released alongside this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a compact, example-driven tutorial for statistical evaluations in ECE/CS experimental work (systems, networking, applied ML). It organizes the process into an eight-step workflow—claim, hypothesis, unit of analysis, baseline, regime sweep, uncertainty estimate, validation check, and reporting—and interleaves classical tools (CLT, t-intervals, t-tests, ANOVA, chi-squared, Pearson correlation, linear regression) with distribution-free methods (bootstrap, Wilcoxon/Mann-Whitney, Cliff’s delta). A running example comparing two job schedulers on simulated truncated heavy-tailed workloads threads through the text, accompanied by paste-and-adapt Python snippets; the paper also covers factorial design, randomization/blocking, multiple-comparison correction, latency pitfalls, simulation V&V, equivalence claims, reproducibility, and ends with a pre-submission checklist.
Significance. If adopted, the playbook could materially improve the defensibility of experimental claims in ECE/CS by supplying a field-tailored, accessible synthesis of established statistical practice. Its strengths include the explicit integration of modern non-parametric techniques suited to the heavy-tailed, high-variance data common in the domain, the provision of runnable code, and the companion workbook materials. Because the paper introduces no new derivations and relies only on textbook-correct methods, its value lies in reducing the gap between statistical knowledge and day-to-day experimental practice.
major comments (2)
- [uncertainty estimate / running example] Section on uncertainty estimates and the running example: the bootstrap procedure for truncated heavy-tailed job sizes is presented without explicit guidance on the minimum number of replicates or on bias-correction choices when the truncation point is close to the sample maximum; this detail is load-bearing for the claim that the workflow reliably produces defensible intervals in the very settings the example is meant to illustrate.
- [simulation verification and validation] Section on simulation verification and validation: the distinction between verification and validation is stated, yet the running example demonstrates only internal consistency checks and does not illustrate an external validation step against real-system traces; this omission weakens the applicability of the workflow to simulation-heavy ECE/CS studies.
minor comments (3)
- [pre-submission checklist] The pre-submission checklist is useful but would be more actionable if each item were cross-referenced to the corresponding workflow step or Python snippet.
- [modern distribution-free techniques] Notation for effect-size measures (Cliff’s delta) is introduced without a brief reminder of its range and interpretation; a one-sentence parenthetical would aid readers unfamiliar with non-parametric effect sizes.
- [Python snippets] A few Python snippets contain hard-coded constants (e.g., random seeds, truncation thresholds) without comment; adding explanatory comments would improve reproducibility for beginners.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and for identifying two specific areas where the running example can be strengthened. Both comments are fair and point to opportunities to make the tutorial more robust for the heavy-tailed, simulation-heavy settings common in ECE/CS. We address each below and commit to targeted revisions that preserve the paper's compact, example-driven scope.
read point-by-point responses
-
Referee: Section on uncertainty estimates and the running example: the bootstrap procedure for truncated heavy-tailed job sizes is presented without explicit guidance on the minimum number of replicates or on bias-correction choices when the truncation point is close to the sample maximum; this detail is load-bearing for the claim that the workflow reliably produces defensible intervals in the very settings the example is meant to illustrate.
Authors: We agree that explicit guidance on bootstrap implementation details would improve defensibility in the truncated heavy-tailed regime. In the revision we will add a short paragraph (and accompanying code comment) recommending a minimum of 1000–2000 replicates for stable percentile intervals with heavy tails, together with a note on preferring the bias-corrected accelerated (BCa) bootstrap when the truncation point lies near the observed maximum. These additions will be placed directly in the uncertainty-estimate subsection of the running example so readers see the practical choice without lengthening the overall workflow description. revision: yes
-
Referee: Section on simulation verification and validation: the distinction between verification and validation is stated, yet the running example demonstrates only internal consistency checks and does not illustrate an external validation step against real-system traces; this omission weakens the applicability of the workflow to simulation-heavy ECE/CS studies.
Authors: The observation is correct: the current running example illustrates only internal verification (consistency and sanity checks). Because the tutorial is deliberately built around a single, self-contained simulated workload, we cannot retroactively embed a full external-validation experiment against real traces without changing the paper's structure and length. We will therefore expand the validation-check subsection with a concise, non-executable illustration that shows how one would compare simulated latency distributions to publicly available cluster traces (e.g., Google or Alibaba), including the statistical test and interpretation steps. This supplies the missing guidance for simulation-heavy work while keeping the running example intact. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper is a purely expository tutorial that assembles and illustrates established classical and distribution-free statistical methods (CLT, t-tests, bootstrap, Wilcoxon, etc.) within a standard evaluation workflow for ECE/CS experiments. It contains no derivations, fitted parameters, predictions, or novel claims that could reduce to self-defined quantities; the running example simply demonstrates application of pre-existing techniques whose correctness is external to the paper. No self-citations function as load-bearing justifications for unverified premises, and the content remains self-contained against external statistical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Central limit theorem applies to sample means under the conditions stated for the running example
- domain assumption Bootstrap and non-parametric tests are distribution-free and preferred for ECE/CS data with heavy tails
Reference graph
Works this paper leans on
-
[1]
, title =
Efron, Bradley and Tibshirani, Robert J. , title =. 1993 , isbn =
1993
-
[2]
and Lazar, Nicole A
Wasserstein, Ronald L. and Lazar, Nicole A. , title =. The American Statistician , volume =. 2016 , publisher =
2016
-
[3]
Journal of the Royal Statistical Society: Series B (Methodological) , volume =
Benjamini, Yoav and Hochberg, Yosef , title =. Journal of the Royal Statistical Society: Series B (Methodological) , volume =. 1995 , doi =
1995
-
[4]
2013 , month = nov, howpublished =
Gelman, Andrew and Loken, Eric , title =. 2013 , month = nov, howpublished =
2013
-
[5]
Deep reinforcement learning that matters
Henderson, Peter and Islam, Riashat and Bachman, Philip and Pineau, Joelle and Precup, Doina and Meger, David , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2018 , publisher =. doi:10.1609/aaai.v32i1.11694 , eprint =
- [6]
-
[7]
1991 , isbn =
Jain, Raj , title =. 1991 , isbn =
1991
-
[8]
Proceedings of the 22nd Annual ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages and Applications (OOPSLA) , pages =
Georges, Andy and Buytaert, Dries and Eeckhout, Lieven , title =. Proceedings of the 22nd Annual ACM SIGPLAN Conference on Object-Oriented Programming Systems, Languages and Applications (OOPSLA) , pages =. 2007 , publisher =
2007
-
[9]
, title =
Mytkowicz, Todd and Diwan, Amer and Hauswirth, Matthias and Sweeney, Peter F. , title =. Proceedings of the 14th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS) , pages =. 2009 , publisher =
2009
-
[10]
Statistical Comparisons of Classifiers over Multiple Data Sets , journal =
Dem. Statistical Comparisons of Classifiers over Multiple Data Sets , journal =. 2006 , url =
2006
-
[11]
, title =
Dietterich, Thomas G. , title =. Neural Computation , volume =. 1998 , doi =
1998
-
[12]
Improving Reproducibility in Machine Learning Research (A Report from the
Pineau, Joelle and Vincent-Lamarre, Philippe and Sinha, Koustuv and Larivi. Improving Reproducibility in Machine Learning Research (A Report from the. Journal of Machine Learning Research , volume =. 2021 , url =
2021
-
[13]
2015 , howpublished =
Tene, Gil , title =. 2015 , howpublished =
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.