Recognition: unknown
Improving LLM Code Generation via Requirement-Aware Curriculum Reinforcement Learning
Pith reviewed 2026-05-09 19:18 UTC · model grok-4.3
The pith
A requirement-aware curriculum reinforcement learning framework improves LLM code generation by automatically perceiving and optimizing requirement difficulty during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
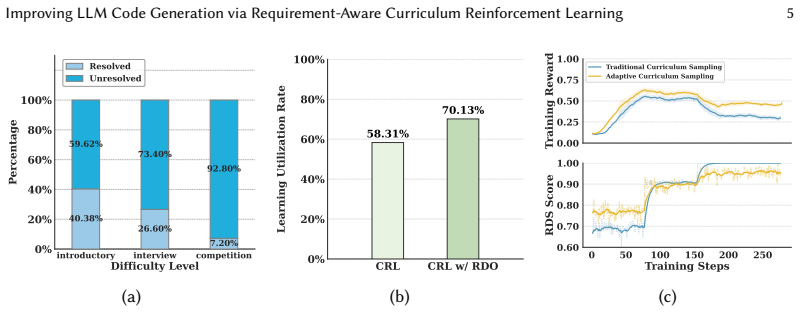
REC RL improves LLM code generation by automatically perceiving model-specific requirement difficulty, optimizing challenging requirements to improve training data utilization, and employing an adaptive curriculum sampling strategy to construct training batches with smoothly varying difficulty, resulting in average Pass@1 gains of 1.23% to 5.62% over state-of-the-art baselines across five LLMs and five benchmarks.
What carries the argument
The RECRL framework, which perceives model-specific requirement difficulty, optimizes challenging requirements, and applies adaptive curriculum sampling to build training batches.
If this is right
- Better utilization of challenging requirements during training produces higher rates of correct code generation on standard benchmarks.
- The method delivers gains across multiple state-of-the-art LLMs and benchmarks without requiring model-specific redesigns.
- Adaptive curriculum sampling creates training batches whose difficulty rises smoothly rather than abruptly.
- Optimization of hard requirements directly addresses underutilization problems in prior curriculum reinforcement learning approaches.
Where Pith is reading between the lines
- The same difficulty perception and optimization steps could apply to training LLMs on other generation tasks where input complexity varies, such as mathematical proofs or natural language to structured output.
- Models trained with RECRL might show stronger generalization when later deployed on real-world programming tasks drawn from actual software projects rather than curated benchmarks.
- The framework could be combined with other training signals such as human feedback to produce additive improvements in code quality.
- Future experiments on larger base models would show whether the relative gains remain consistent or grow with model scale.
Load-bearing premise
That automatically perceiving model-specific requirement difficulty, optimizing the challenging requirements, and using adaptive sampling will produce reliable gains without introducing new biases or degrading performance on requirements outside the training distribution.
What would settle it
Testing the method on a fresh code generation benchmark outside the five used in the experiments and finding no Pass@1 improvement or a drop relative to the baselines would falsify the central effectiveness claim.
Figures

read the original abstract
Code generation, which aims to automatically generate source code from given programming requirements, has the potential to substantially improve software development efficiency. With the rapid advancement of large language models (LLMs), LLM-based code generation has attracted widespread attention from both academia and industry. However, as programming requirements become increasingly complex, existing LLMs still exhibit notable performance limitations. To address this challenge, recent studies have proposed training-based curriculum reinforcement learning (CRL) strategies to improve LLM code generation performance. Despite their effectiveness, existing CRL approaches suffer from several limitations, including misaligned requirement difficulty perception, the absence of requirement difficulty optimization, and suboptimal curriculum sampling strategies. In CRL-based code generation, programming requirements serve as the sole input to the model, making their quality and difficulty critical to training effectiveness. Motivated by insights from software requirements engineering, we propose RECRL, a novel requirement-aware curriculum reinforcement learning framework for enhancing LLM-based code generation. RECRL automatically perceives model-specific requirement difficulty, optimizes challenging requirements to improve training data utilization, and employs an adaptive curriculum sampling strategy to construct training batches with smoothly varying difficulty. Extensive experiments on five state-of-the-art LLMs across five widely-used code generation benchmarks by comparing with five state-of-the-art baselines, demonstrate the significant effectiveness of RECRL. For example, RECRL achieves an average Pass@1 improvement of 1.23%-5.62% over all state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RECRL, a requirement-aware curriculum reinforcement learning framework for LLM-based code generation. It identifies limitations in prior CRL methods (misaligned difficulty perception, lack of requirement optimization, suboptimal sampling) and introduces automatic model-specific difficulty perception, optimization of challenging requirements, and adaptive curriculum sampling to construct training batches. Experiments across five LLMs and five code-generation benchmarks report average Pass@1 gains of 1.23%-5.62% over five state-of-the-art baselines.
Significance. If the empirical improvements hold under rigorous controls, RECRL would offer a practical advance in training LLMs for code generation by leveraging requirements-engineering principles to improve data utilization and handle complex requirements more effectively. The framework's emphasis on model-specific difficulty and smooth curriculum progression could influence future RL fine-tuning strategies in software engineering applications.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The central claim of reliable, generalizable gains rests on the reported Pass@1 improvements, yet the manuscript supplies no statistical significance tests, confidence intervals, number of random seeds/runs, or details on baseline re-implementations and data splits. Without these, the 1.23%-5.62% average cannot be verified as load-bearing evidence for the method's superiority.
- [Method and Experimental Setup] Method and Experimental Setup: Training batches are constructed from the identical five benchmarks used for final evaluation. This creates a risk that the adaptive curriculum and difficulty optimization simply overfit to benchmark artifacts rather than demonstrating independent requirement-aware effects; an out-of-distribution or held-out benchmark test is required to support the claim that gains arise from the proposed requirement-engineering components.
minor comments (2)
- [Abstract] Abstract: The improvement range 1.23%-5.62% is stated without per-LLM or per-benchmark breakdowns, making it difficult to identify where RECRL provides the largest benefit.
- [Related Work] Related Work: Prior CRL approaches are summarized at a high level; explicit comparison tables or equations contrasting the proposed difficulty perception and sampling against the cited baselines would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating the revisions we will incorporate to improve the manuscript's rigor and clarity.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The central claim of reliable, generalizable gains rests on the reported Pass@1 improvements, yet the manuscript supplies no statistical significance tests, confidence intervals, number of random seeds/runs, or details on baseline re-implementations and data splits. Without these, the 1.23%-5.62% average cannot be verified as load-bearing evidence for the method's superiority.
Authors: We agree that these details are necessary for verifying the empirical claims. The original submission omitted them due to space constraints. In the revised manuscript, we will add: statistical significance tests (paired t-tests with p-values) on the Pass@1 differences, 95% confidence intervals for all reported scores, the number of random seeds (we used 5 seeds with results averaged), and expanded details on baseline re-implementations (including hyperparameters and code availability) plus exact data splits. These additions will directly support the reported gains. revision: yes
-
Referee: [Method and Experimental Setup] Method and Experimental Setup: Training batches are constructed from the identical five benchmarks used for final evaluation. This creates a risk that the adaptive curriculum and difficulty optimization simply overfit to benchmark artifacts rather than demonstrating independent requirement-aware effects; an out-of-distribution or held-out benchmark test is required to support the claim that gains arise from the proposed requirement-engineering components.
Authors: This concern is valid and highlights a potential limitation in demonstrating generalization. Our setup follows standard code-generation practices by applying the curriculum only to training portions of each benchmark while evaluating on official held-out test sets. However, to strengthen the claim, the revision will explicitly detail these splits and include results from at least one additional out-of-distribution benchmark (e.g., a new dataset not used during training) in the main text or appendix. This will better isolate the contribution of the requirement-aware components. revision: partial
Circularity Check
No circularity in derivation chain; empirical claims rest on external benchmarks and baselines
full rationale
The paper describes an empirical RL framework (REC RL) that perceives requirement difficulty, optimizes challenging cases, and applies adaptive curriculum sampling, then reports Pass@1 gains versus baselines on five standard code-generation benchmarks. No equations, first-principles derivations, or parameter-fitting steps are present that reduce by construction to the inputs or to self-citations. The central results are experimental comparisons against independent baselines; training-batch construction from benchmark requirements does not create a definitional loop or fitted-input prediction because evaluation uses held-out test cases and the method is not claimed to derive new quantities from its own fitted values. Self-citations, if any, are not load-bearing for the reported improvements. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Everton Lima Aleixo, Juan G Colonna, Marco Cristo, and Everlandio Fernandes. 2024. Catastrophic Forgetting in Deep Learning: A Comprehensive Taxonomy.Journal of the Brazilian Computer Society30, 1 (2024), 175–211
2024
-
[2]
Anonymous. 2025. RERCL: Anonymous Code Repository. https://anonymous.4open.science/r/RERCL-9BD6
2025
-
[3]
Anthropic. 2024. The Claude 3 Model Family: Opus, Sonnet, Haiku. https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf Accessed: 2026-01-29
2024
-
[5]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program synthesis with large language models.arXiv preprint arXiv:2108.07732 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Carlos Miguel Patiño, Edward Beeching, Aymeric Roucher, Aksel Joonas Reedi, Quentin Gallouédec, Kashif Rasul, Nathan Habib, Clémentine Fourrier, Hynek Kydlicek, Guilherme Penedo, Hugo Larcher, Mathieu Morlon, Vaibhav Srivastav, Joshua Lochner, Xuan-Son Nguyen, Colin Raffel, Lean...
2025
-
[7]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. InProceedings of the 26th annual international conference on machine learning. 41–48
2009
-
[8]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [9]
- [10]
- [11]
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196(2024)
work page internal anchor Pith review arXiv 2024
-
[14]
1977.Elements of Software Science (Operating and programming systems series)
Maurice H Halstead. 1977.Elements of Software Science (Operating and programming systems series). Elsevier Science Inc
1977
- [15]
-
[16]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 , Vol. 1, No. 1, Article . Publication date: May 2026. 20 Chen and Yang (2021)
work page internal anchor Pith review arXiv 2021
-
[17]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt
-
[18]
Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874(2021)
work page internal anchor Pith review arXiv 2021
-
[19]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. 2023. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations
2023
-
[20]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[21]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al
-
[22]
Lora: Low-rank adaptation of large language models.ICLR1, 2 (2022), 3
2022
-
[23]
Siming Huang, Tianhao Cheng, Jason Klein Liu, Weidi Xu, Jiaran Hao, Liuyihan Song, Yang Xu, Jian Yang, Jiaheng Liu, Chenchen Zhang, et al. 2025. Opencoder: The open cookbook for top-tier code large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 33167–33193
2025
-
[24]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review arXiv 2024
-
[26]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology(2024)
2024
-
[27]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-planning code generation with large language models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 1–30
2024
-
[28]
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. 2022. Coderl: Mastering code generation through pretrained models and deep reinforcement learning.Advances in Neural Information Processing Systems35 (2022), 21314–21328
2022
-
[29]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in Neural Information Processing Systems36 (2023), 21558–21572
2023
-
[32]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=UnUwSIgK5W
2024
-
[33]
Lezhi Ma, Shangqing Liu, Yi Li, Xiaofei Xie, and Lei Bu. 2025. SpecGen: Automated Generation of Formal Program Specifications via Large Language Models. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 16–28
2025
-
[34]
Thomas J McCabe. 1976. A complexity measure.IEEE Transactions on software Engineering4 (1976), 308–320
1976
-
[35]
Marwa Naïr, Kamel Yamani, Lynda Lhadj, and Riyadh Baghdadi. 2024. Curriculum learning for small code language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop). 390–401
2024
-
[36]
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E Taylor, and Peter Stone. 2020. Curriculum learning for reinforcement learning domains: A framework and survey.Journal of Machine Learning Research21, 181 (2020), 1–50
2020
-
[37]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems35 (2022), 27730–27744
2022
- [38]
-
[39]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2025. Asleep at the keyboard? assessing the security of github copilot’s code contributions.Commun. ACM68, 2 (2025), 96–105. , Vol. 1, No. 1, Article . Publication date: May 2026. Improving LLM Code Generation via Requirement-Aware Curriculum Reinforcement Learning 21
2025
-
[40]
Ruchir Puri, David Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. 2021. CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks. InAnnual Conference on Neural Information Processing Systems
2021
- [41]
-
[42]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review arXiv 2023
-
[43]
Hitesh Sagtani, Rishabh Mehrotra, and Beyang Liu. 2025. Improving fim code completions via context & curriculum based learning. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 801–810
2025
-
[44]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems. 1279–1297
2025
- [46]
-
[47]
Ian Sommerville. 2011. Software engineering 9th Edition.ISBN-10137035152 (2011), 18
2011
-
[48]
Zhihong Sun, Chen Lyu, Bolun Li, Yao Wan, Hongyu Zhang, Ge Li, and Zhi Jin. 2024. Enhancing Code Generation Performance of Smaller Models by Distilling the Reasoning Ability of LLMs. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 5878–5895
2024
-
[49]
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks.Advances in neural information processing systems27 (2014)
2014
-
[50]
Zhao Tian and Junjie Chen. 2026. Aligning Requirement for Large Language Model’s Code Generation. In2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE)
2026
-
[51]
Zhao Tian, Junjie Chen, and Xiangyu Zhang. 2025. Fixing Large Language Models’ Specification Misunderstanding for Better Code Generation. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 645–645
2025
- [52]
-
[53]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[54]
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I Wang. 2025. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449(2025)
work page internal anchor Pith review arXiv 2025
-
[55]
1963.Critical values and probability levels for the Wilcoxon rank sum test and the Wilcoxon signed rank test
Frank Wilcoxon, SK Katti, Roberta A Wilcox, et al. 1963.Critical values and probability levels for the Wilcoxon rank sum test and the Wilcoxon signed rank test. Vol. 1. American Cyanamid Pearl River, NY
1963
-
[56]
Zhiheng Xi, Wenxiang Chen, Boyang Hong, Senjie Jin, Rui Zheng, Wei He, Yiwen Ding, Shichun Liu, Xin Guo, Junzhe Wang, et al. 2024. Training Large Language Models for Reasoning through Reverse Curriculum Reinforcement Learning. InInternational Conference on Machine Learning. PMLR, 54030–54048
2024
-
[57]
Guang Yang, Yu Zhou, Xiang Chen, Xiangyu Zhang, Terry Yue Zhuo, and Taolue Chen. 2024. Chain-of-thought in neural code generation: From and for lightweight language models.IEEE Transactions on Software Engineering(2024)
2024
-
[58]
Pengcheng Yin and Graham Neubig. 2017. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 440–450
2017
-
[59]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen
-
[60]
InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2471–2484
2023
- [61]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.