Recognition: unknown
Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation
Pith reviewed 2026-05-09 19:47 UTC · model grok-4.3
The pith
Ψ-RAG builds an adaptable hierarchical abstract tree and retrieval agent to handle cross-document multi-hop questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ψ-RAG constructs a hierarchical abstract tree index through an iterative merging and collapse process that adapts to data distributions without a priori assumptions. This index is paired with a multi-granular retrieval agent that interacts with the knowledge base using reorganized queries and an agent-powered hybrid retriever. The combination resolves structural isolation between documents and coarse abstraction that obscures fine-grained information. On cross-document multi-hop QA benchmarks, the framework reports average F1 scores 25.9 percent higher than RAPTOR and 7.4 percent higher than HippoRAG 2 while supporting tasks from token-level answering to document-level summarization.
What carries the argument
The hierarchical abstract tree index created by iterative merging and collapse, together with the multi-granular retrieval agent that uses reorganized queries and hybrid retrieval.
If this is right
- The framework scales tree-based RAG to multi-hop questions that draw facts from separate documents.
- It supplies retrieval at multiple granularities for both question answering and summarization.
- Explicit cross-document links and finer abstraction levels reduce errors from isolated or overly general indexes.
- The agent-driven query reorganization and hybrid retrieval improve accuracy without manual clustering parameter tuning.
Where Pith is reading between the lines
- The adaptive tree construction may reduce reliance on distribution-specific preprocessing steps common in other RAG pipelines.
- Components such as the hybrid retriever could be tested as drop-in additions to non-tree retrieval systems that currently struggle with multi-document queries.
Load-bearing premise
The iterative merging and collapse process adapts to any data distribution without prior assumptions, and the retrieval agent reliably creates cross-document connections while preserving fine details.
What would settle it
Replacing the iterative merging and collapse with standard k-means clustering on the same cross-document multi-hop QA benchmarks and checking whether the F1 gains over RAPTOR disappear.
Figures










read the original abstract
Retrieval-augmented generation (RAG) enhances large language models with external knowledge, and tree-based RAG organizes documents into hierarchical indexes to support queries at multiple granularities. However, existing Tree-RAG methods designed for single-document retrieval face critical challenges in scaling to cross-document multi-hop questions: (1) poor distribution adaptability, where $k$-means clustering introduces noise due to rigid distribution assumptions; (2) structural isolation, as tree indexes lack explicit cross-document connections; and (3) coarse abstraction, which obscures fine-grained details. To address these limitations, we propose $\Psi$-RAG, a tree-RAG framework with two key components. First, a hierarchical abstract tree index built through an iterative "merging and collapse" process that adapts to data distributions without a priori assumption. Second, a multi-granular retrieval agent that intelligently interacts with the knowledge base with reorganized queries and an agent-powered hybrid retriever. $\Psi$-RAG supports diverse tasks from token-level question answering to document-level summarization. On cross-document multi-hop QA benchmarks, it outperforms RAPTOR by 25.9% and HippoRAG 2 by 7.4% in average F1 score. Code is available at https://github.com/Newiz430/Psi-RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ψ-RAG, a tree-based RAG framework for cross-document multi-hop tasks. It proposes a hierarchical abstract tree index built via an iterative merging-and-collapse process claimed to adapt to data distributions without a priori assumptions, paired with a multi-granular retrieval agent that employs reorganized queries and an agent-powered hybrid retriever. The work reports average F1 gains of 25.9% over RAPTOR and 7.4% over HippoRAG 2 on cross-document multi-hop QA benchmarks and states that the approach supports tasks ranging from token-level QA to document-level summarization. Open-source code is provided.
Significance. If the performance gains are reproducible and the claimed distribution adaptability holds, the framework could advance tree-structured RAG methods for complex multi-document reasoning by mitigating issues of structural isolation and coarse abstraction. The public code release is a clear strength that supports verification and community follow-up.
major comments (2)
- [Abstract / Hierarchical abstract tree construction] Abstract and the section describing the hierarchical abstract tree index: the central claim that the iterative merging-and-collapse process 'adapts to data distributions without a priori assumption' is load-bearing for attributing the reported F1 gains to general methodological superiority rather than benchmark-specific tuning. Any concrete realization requires explicit choices for similarity metric, merge/collapse thresholds, and stopping criteria; these constitute design decisions that can embed distribution biases, and the manuscript must demonstrate (via pseudocode, parameter analysis, or ablation) that they are fully data-driven rather than fixed a priori.
- [Experimental results] The section reporting experimental results: the headline performance numbers (25.9% over RAPTOR, 7.4% over HippoRAG 2 in average F1) are presented without accompanying details on benchmark datasets, baseline implementations, statistical significance tests, variance across runs, or controls for confounds such as query hop count or document length distribution. This omission prevents evaluation of whether the gains are robust or attributable to the proposed components.
minor comments (2)
- The abstract would be strengthened by naming the specific cross-document multi-hop QA benchmarks used, allowing readers to immediately contextualize the F1 improvements.
- Notation for the proposed framework (Ψ-RAG) and its components should be introduced consistently and defined at first use in the main text.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive feedback. We have carefully considered the major comments and provide point-by-point responses below, along with our plans for revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract / Hierarchical abstract tree construction] Abstract and the section describing the hierarchical abstract tree index: the central claim that the iterative merging-and-collapse process 'adapts to data distributions without a priori assumption' is load-bearing for attributing the reported F1 gains to general methodological superiority rather than benchmark-specific tuning. Any concrete realization requires explicit choices for similarity metric, merge/collapse thresholds, and stopping criteria; these constitute design decisions that can embed distribution biases, and the manuscript must demonstrate (via pseudocode, parameter analysis, or ablation) that they are fully data-driven rather than fixed a priori.
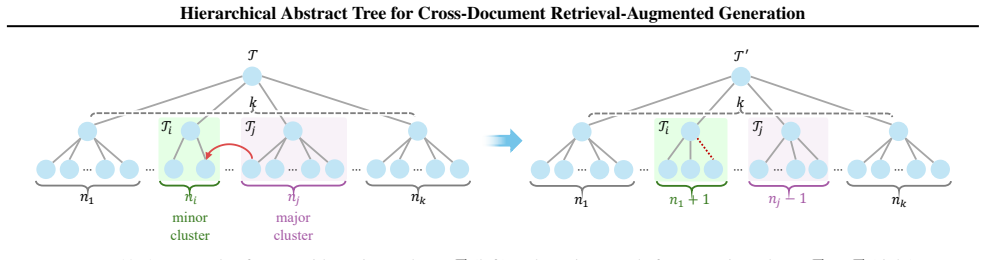
Authors: We appreciate the referee's point on the importance of clarifying the 'without a priori assumption' claim. The iterative merging-and-collapse process differs from methods like k-means by not requiring a predefined number of clusters or levels; instead, it dynamically merges nodes based on pairwise similarities and collapses subtrees when they reach sufficient abstraction, with the structure emerging from the data. However, we recognize that concrete implementations involve choices such as the similarity function (e.g., cosine similarity on embeddings) and thresholds. In the revised version, we will provide detailed pseudocode, specify the exact parameters used, and include ablations showing performance stability across reasonable threshold ranges on multiple datasets to support the adaptability claim. revision: yes
-
Referee: [Experimental results] The section reporting experimental results: the headline performance numbers (25.9% over RAPTOR, 7.4% over HippoRAG 2 in average F1) are presented without accompanying details on benchmark datasets, baseline implementations, statistical significance tests, variance across runs, or controls for confounds such as query hop count or document length distribution. This omission prevents evaluation of whether the gains are robust or attributable to the proposed components.
Authors: We thank the referee for highlighting the need for more comprehensive experimental reporting. While the manuscript provides an overview of the benchmarks and baselines, we agree that additional details are warranted. In the revision, we will expand the experimental results section to include: full descriptions of the benchmark datasets with statistics on document counts, lengths, and hop distributions; implementation details or references for all baselines; statistical significance testing (e.g., p-values from t-tests); variance measures (standard deviations over 5 runs); and controls/analyses for potential confounds such as query complexity and document length. This will allow better assessment of the robustness of the reported gains. revision: yes
Circularity Check
No circularity in derivation chain; method and results are independent constructions
full rationale
The paper proposes Ψ-RAG with a hierarchical abstract tree via iterative merging/collapse (claimed to adapt without a priori assumptions) and a multi-granular retrieval agent. These are presented as novel algorithmic components whose performance is then measured empirically on cross-document QA benchmarks (25.9% over RAPTOR, 7.4% over HippoRAG 2). No equations, predictions, or first-principles results are shown that reduce by construction to the inputs, fitted parameters, or self-citations. The 'without a priori assumption' phrasing is a descriptive claim about the algorithm's design, not a self-referential definition or renaming of results. The derivation chain is self-contained against external benchmarks with no load-bearing self-citation or tautological steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative merging and collapse process adapts to data distributions without a priori assumption
invented entities (2)
-
Hierarchical abstract tree index
no independent evidence
-
Multi-granular retrieval agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G., Liu, L., Qi, P., Chen, X., Wang, W
Arivazhagan, M. G., Liu, L., Qi, P., Chen, X., Wang, W. Y ., and Huang, Z. Hybrid hierarchical retrieval for open- domain question answering. InFindings of the Asso- ciation for Computational Linguistics: ACL 2023, pp. 10680–10689,
2023
-
[2]
Dense X Retrieval: What retrieval granularity should we use? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp
Chen, T., Wang, H., Chen, S., Yu, W., Ma, K., Zhao, X., Zhang, H., and Yu, D. Dense X Retrieval: What retrieval granularity should we use? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 15159–15177,
2024
-
[3]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al- Dahle, A., Letman, A., Mathur, A., Yang, A., Fan, A., et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R. O., and Larson, J. From local to global: A graph RAG ap- proach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review arXiv
-
[6]
T -RAG: Lessons from the LLM trenches,
Fatehkia, M., Lucas, J. K., and Chawla, S. T-RAG: lessons from the LLM trenches.arXiv preprint arXiv:2402.07483,
-
[7]
LightRAG: Simple and fast retrieval-augmented generation
Guo, Z., Xia, L., Yu, Y ., Ao, T., and Huang, C. LightRAG: Simple and fast retrieval-augmented generation. InFind- ings of the Association for Computational Linguistics: EMNLP 2025,
2025
- [8]
-
[9]
Retrieval-augmented generation with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
Huang, H., Huang, Y ., Yang, J., Pan, Z., Chen, Y ., Ma, K., Chen, H., and Cheng, J. Retrieval-augmented gen- eration with hierarchical knowledge.arXiv preprint arXiv:2503.10150,
-
[10]
Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram ´e, A., Rivi `ere, M., et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Dense passage retrieval for open-domain question answering
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781,
2020
-
[12]
11 Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation Li, C., Liu, Z., Xiao, S., and Shao, Y . Making large language models a better foundation for dense retrieval.arXiv preprint arXiv:2312.15503,
-
[13]
Simple is effective: The roles of graphs and large language models in knowledge-graph- based retrieval-augmented generation
Li, M., Miao, S., and Li, P. Simple is effective: The roles of graphs and large language models in knowledge-graph- based retrieval-augmented generation. InProceedings of the 13th International Conference on Learning Represen- tations, 2025a. Li, X., Bai, Y ., Jin, B., Zhu, F., Pan, L., and Cao, Y . Long context vs. RAG: Strategies for processing long doc...
2025
-
[14]
com/jerryjliu/llama_index
URL https://github. com/jerryjliu/llama_index. Liu, Y ., Hashimoto, K., Zhou, Y ., Yavuz, S., Xiong, C., and Yu, P. S. Dense hierarchical retrieval for open-domain question answering. InFindings of the Association for Computational Linguistics: EMNLP 2021, pp. 188–200,
2021
- [15]
-
[16]
V ., Modani, N., Chhaya, N., Karanam, S., and Shekhar, S
Nair, I., Garimella, A., Srinivasan, B. V ., Modani, N., Chhaya, N., Karanam, S., and Shekhar, S. A neural CRF-based hierarchical approach for linear text segmen- tation. InFindings of the Association for Computational Linguistics: EACL 2023, pp. 883–893,
2023
-
[17]
TreeRAG: Unleashing the power of hierarchical storage for enhanced knowledge retrieval in long documents
Tao, W., Xing, X., Chen, Y ., Huang, L., and Xu, X. TreeRAG: Unleashing the power of hierarchical storage for enhanced knowledge retrieval in long documents. In Findings of the Association for Computational Linguis- tics: ACL 2025, pp. 356–371,
2025
-
[18]
ArchRAG: Attributed Community-based Hierarchical Retrieval-Augmented Generation
Wang, S., Fang, Y ., Zhou, Y ., Liu, X., and Ma, Y . ArchRAG: Attributed community-based hierarchi- cal retrieval-augmented generation.arXiv preprint arXiv:2502.09891,
work page internal anchor Pith review arXiv
-
[19]
When more is less: Understanding chain-of-thought length in LLMs
Wu, Y ., Wang, Y ., Ye, Z., Du, T., Jegelka, S., and Wang, Y . When more is less: Understanding chain-of-thought length in LLMs. InICLR 2025 Workshop on Reasoning and Planning for Large Language Models,
2025
-
[20]
Yilin Xiao, Junnan Dong, Chuang Zhou, Su Dong, Qian wen Zhang, Di Yin, Xing Sun, and Xiao Huang
Xiao, Y ., Dong, J., Zhou, C., Dong, S., Zhang, Q.-w., Yin, D., Sun, X., and Huang, X. GraphRAG-Bench: Challenging domain-specific reasoning for evaluating graph retrieval-augmented generation.arXiv preprint arXiv:2506.02404,
-
[21]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[22]
Zhang, H., Feng, T., and You, J. Graph of records: Boosting retrieval augmented generation for long-context summa- rization with graphs. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 23780–23799, 2025a. Zhang, X., Chen, Y ., Hu, S., Xu, Z., Chen, J., Hao, M., Han, X., Thai, Z., Wang,...
-
[23]
QM- Sum: A new benchmark for query-based multi-domain meeting summarization
Zhong, M., Yin, D., Yu, T., Zaidi, A., Mutuma, M., Jha, R., Hassan, A., Celikyilmaz, A., Liu, Y ., Qiu, X., et al. QM- Sum: A new benchmark for query-based multi-domain meeting summarization. InProceedings of the 2021 Con- ference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, pp. 5905–5921,
2021
-
[24]
16 B.2 Proof of Theorem 4.3
13 Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation Appendix Contents A Algorithms ofΨ-RAG 15 B Theoretical Proofs 16 B.1 Proof of Theorem 4.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 B.2 Proof of Theorem 4.3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2012
-
[25]
The subsequent conclusions demonstrate that this assumption does not affect our conclusion of Ψ-RAG’s property
by considering a computable scenario where the distance d= 1 for all pairs of chunks. The subsequent conclusions demonstrate that this assumption does not affect our conclusion of Ψ-RAG’s property. To analyze the non-uniformity preference ofΨ-RAG, Lemma B.3 quantifies the increment in Dasgupta’s cost introduced by node collapse. Lemma B.3(Increment of Das...
1996
-
[26]
Summary:
to be equal to the maximum hop count of user questions: 2 for HotpotQA and 2Wiki, 4 for MuSiQue and MultiHop-RAG. For single-hop datasets (NQ and PopQA), though, we allow one extra retrieval attempt for possible query reorganization. For summarization datasets, we perform single retrieval. The k value is determined by the size of documents: top-20 for QMS...
1913
-
[27]
It owns and operates over 30 hotels and two cruise ships
The Oberoi Group, founded in 1934, is a luxury hotel company based in Delhi. It owns and operates over 30 hotels and two cruise ships. It was founded by Mohan Singh Oberoi, who started India’s second-largest hotel company. The Ritz-Carlton Jakarta is a skyscraper hotel in Indonesia, opened in
1934
-
[28]
‘,’.join(list of keywords)
It consists of two towers, one for the hotel and one for apartments, and is located near the JW Marriott Hotel. 5https://ollama.com/ 23 Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation LLM Prompt forὑ1Keyword Abstract ========================{System Instruction}======================== As an advanced document summarization assi...
1913
-
[29]
I feel sorry for Onana,
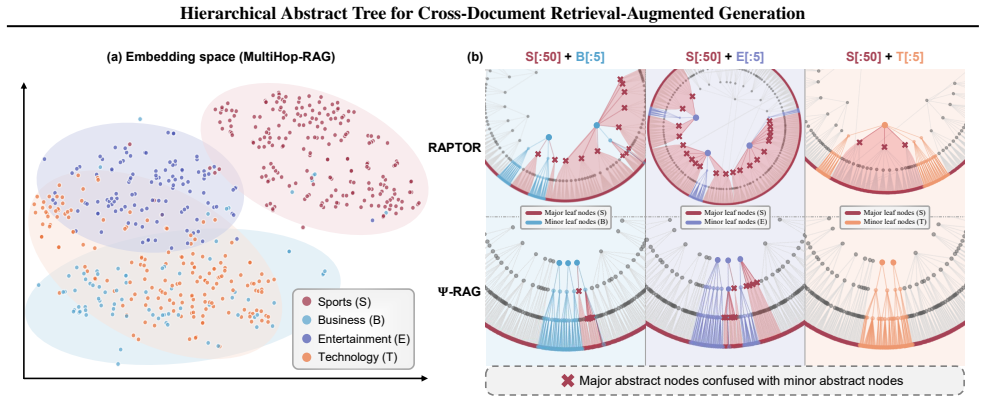
Ψ-RAG/file-alt 1st layer Various sports teams face outcomes: Inter Miami eliminated, Italy and Australia in Davis Cup final, Rangers lead Diamondbacks 3-1, Lions beat Packers, 49ers defeat Cowboys, Vikings lose to Broncos and Bears, amidst other results and controversies including Mattel’s inaccurate Cherokee Barbie. The Crown’s final season covers Prince...
1997
-
[30]
Liza Minnelli
<answer>Pont de l’Alma✓ 26 Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation the retriever, leading it to irrelevant chunks. In contrast, sparse retrieval can provide straightforward facts about David Gest by simply searching for documents with the keyword. As a result, the retrieved chunk leads to the final answer “Liza Minnell...
2024
-
[31]
David” that are unrelated to the target “David Gest
The results indicate that on multi-hop datasets, the first extra retriever call yields the greatest performance gain, while subsequent attempts contribute minimal or even negative improvement. Each retrieval attempt introduces a relatively constant time overhead, and longer reasoning 27 Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Gen...
2025
-
[32]
Query Hop Discriminator Our evaluation utilizes the maximum hop count of each dataset for the maximum number of iterative retrieval timeimax
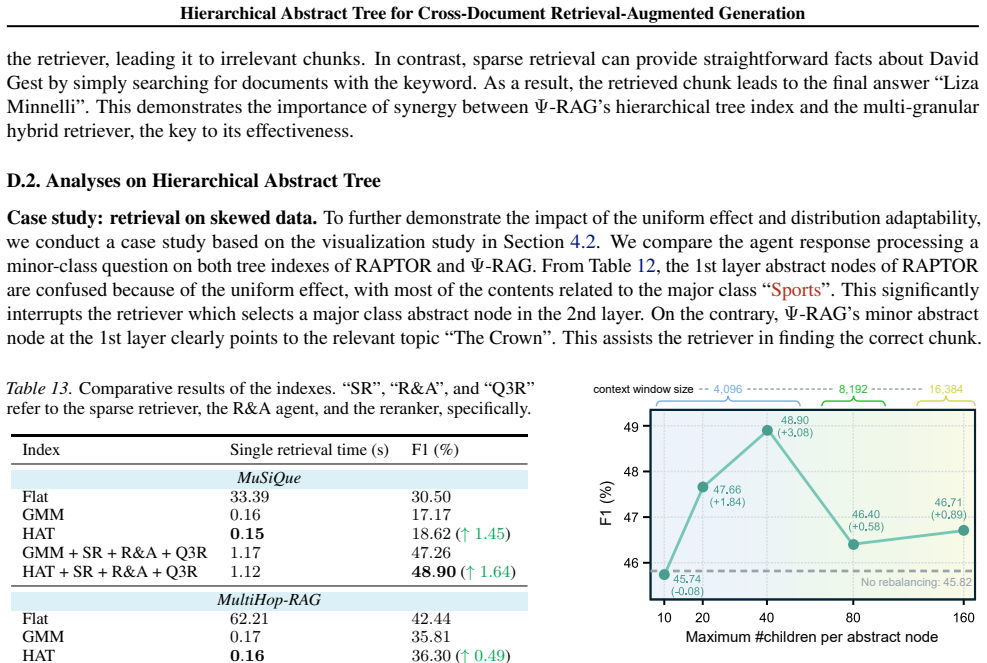
+ HNSW Embedding time (s)1,229 10,208 Similarity ranking time (s)304.84 55.99(5.44×)0.89(342.5×) 168.027.87(21.35×) Similarity matrix memory13.16GB 10.55MB(1,277×)2.45MB(5,483×) 88.17MB2.15MB(41.01×) Similarity ranking memory65.81GB 656.7MB(102.6×)37.89MB(1,778×) 1.34GB34.10MB(40.24×) Tree indexing time (s)15,996 13,957(1.15×)848(18.86×) ∼280,0002,261(∼12...
2020
-
[33]
They are fast and suitable for token-level detailed search but less capable of capturing deep semantic meanings
retrieve documents where keywords from the user question appear more often in the corpus. They are fast and suitable for token-level detailed search but less capable of capturing deep semantic meanings. (2)Dense vector retrieval (Karpukhin et al., 2020): this approach utilizes powerful language embedding models (Khattab & Zaharia, 2020; Izacard et al., 20...
2020
-
[34]
They often build a unified index for an entire corpus using named entity recognition and extraction methods like the Open Information Extraction (OpenIE) (Banko et al., 2007)
can capture semantic relationships between document chunks or entities. They often build a unified index for an entire corpus using named entity recognition and extraction methods like the Open Information Extraction (OpenIE) (Banko et al., 2007). Cross-document multi-hop associations are then captured by walking from node to node (Jim´enez Guti´errez et ...
2007
-
[35]
However, traditional algorithms offer limited generalization
and bottom-up hierarchical clustering (Florek et al., 1951; Sokal & Michener, 1958; Jardine & van Rijsbergen, 1971). However, traditional algorithms offer limited generalization. Most existing dense vector-based Tree-RAG methods (Liu et al., 2021; Liu, 2022; Jin et al., 2025b; Zhao et al., 2025; Fatehkia et al., 2024; Tao et al.,
1951
-
[36]
To our knowledge, the only corpus-level Tree-RAG is LATTICE (Gupta et al., 2025), which performs beam search retrieval using an LLM-evaluated path relevance score
further adapts Tree-RAG to the long-term LLM memory scenario, but both of them are limited to the passage-level indexes and the single-document retrieval setting. To our knowledge, the only corpus-level Tree-RAG is LATTICE (Gupta et al., 2025), which performs beam search retrieval using an LLM-evaluated path relevance score. However, there are no discussi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.