Recognition: unknown
EASE: Federated Multimodal Unlearning via Entanglement-Aware Anchor Closure
Pith reviewed 2026-05-09 18:26 UTC · model grok-4.3
The pith
EASE achieves effective federated multimodal unlearning by closing three residual anchors of forgotten knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that forgotten alignments in federated multimodal contrastive unlearning persist through three residual anchors arising from bilinear cross-modal coupling, principal-angle subspace entanglement, and continued federated updates. EASE closes all three anchor channels through bilateral displacement of visual and language branches, Cosine-Sine decomposition of client-update subspaces to isolate forget-exclusive directions, and a direction-selective Forget Lock that bounds residual drift, leading to unlearning results that match the retrain reference closely on forget and retain metrics.
What carries the argument
The Anchor Principle, which posits that forgotten alignments persist through three residual anchors, implemented via the EASE framework's combination of bilateral displacement, Cosine-Sine decomposition, and direction-selective Forget Lock.
If this is right
- Client unlearning can be performed effectively in multimodal federated settings without degrading retain performance significantly.
- Bilateral displacement closes the cross-modal reconstruction channel mediated by bilinear coupling.
- Cosine-Sine decomposition separates forget-exclusive update directions from shared retain support.
- The Forget Lock prevents continued drift from residual entangled updates in subsequent rounds.
- Overall superiority is shown across multiple datasets and unlearning scenarios with near-retrain accuracy.
Where Pith is reading between the lines
- Similar anchor-closure strategies might apply to other forms of entangled learning beyond contrastive multimodal models.
- Implementing EASE could make data removal requests more feasible in privacy-sensitive federated applications.
- Testing on larger-scale or different modality combinations could reveal if the three anchors are universal.
- Reducing the need for retraining saves significant computation in distributed systems.
Load-bearing premise
The three residual anchors are the primary mechanisms that hinder unlearning, and the proposed closures fully address them without introducing new entanglements or degrading performance on retained data.
What would settle it
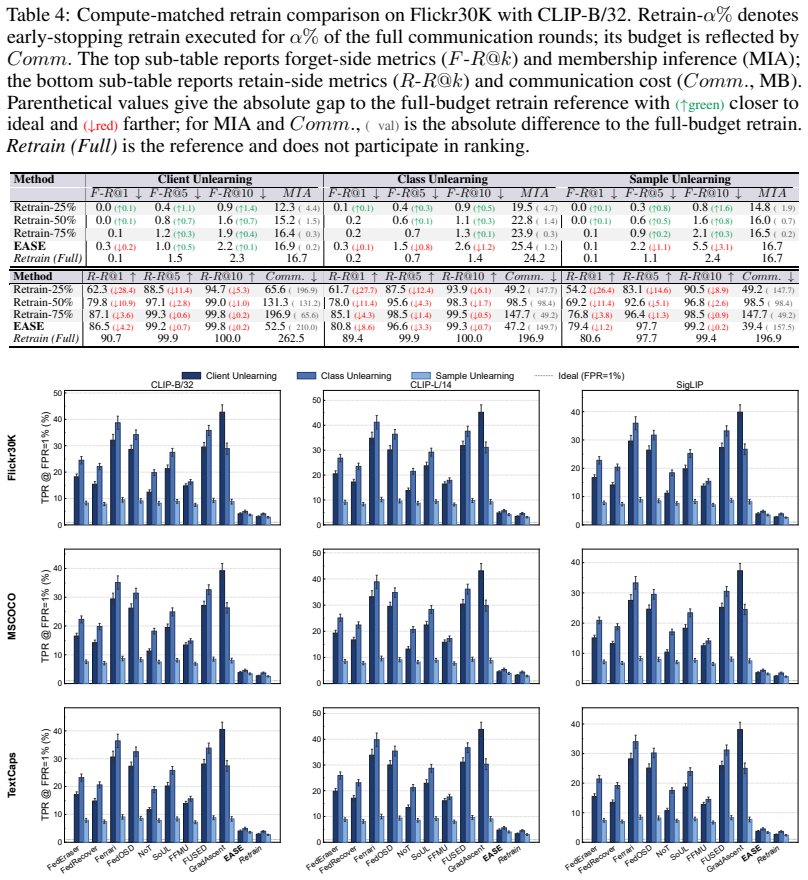
Running the client unlearning experiment on Flickr30K using CLIP-B/32 and checking if the R@1 scores for forget and retain sets stay within 0.2 and 4.2 points of the full retrain baseline.
Figures









read the original abstract
Federated Multimodal Learning (FML) trains multimodal models across decentralized clients while keeping their image-text pairs private. However, joint embedding training entangles forgotten knowledge across both modalities and client gradient subspaces, hindering federated unlearning. Previous federated unlearning approaches neither sever the cross-modal reconstruction channel mediated by bilinear coupling nor separate forget-exclusive update directions from those shared with retained clients. We identify an Anchor Principle for federated multimodal contrastive unlearning: forgotten alignments persist through three residual anchors arising from bilinear cross-modal coupling, principal-angle subspace entanglement, and continued federated updates. At the modality level, we show that bilateral displacement of both visual and language branches closes the cross-modal reconstruction channel. Correspondingly, our method addresses subspace entanglement through Cosine--Sine decomposition of client-update subspaces, isolating forget-exclusive directions from retain support. Moreover, we propose a direction-selective Forget Lock that bounds residual drift across rounds. Combining these strategies, we present EASE, an Entanglement-Aware Subspace Excision framework that closes all three anchor channels under a unified design. EASE demonstrates consistent superiority across multiple datasets and unlearning scenarios, for instance, matching the retrain reference to within 0.2 and 4.2 R@1 points on the forget and retain sides under client unlearning on Flickr30K with CLIP-B/32.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EASE, an Entanglement-Aware Subspace Excision framework for federated multimodal unlearning. It defines an Anchor Principle identifying three residual anchors that persist forgotten alignments: bilinear cross-modal coupling, principal-angle subspace entanglement between client-update subspaces, and continued federated updates. The method closes these via bilateral displacement of visual and language branches, Cosine-Sine decomposition to isolate forget-exclusive directions from retain support, and a direction-selective Forget Lock to bound residual drift. Experiments claim consistent superiority, including matching retrain reference performance to within 0.2 R@1 (forget) and 4.2 R@1 (retain) under client unlearning on Flickr30K with CLIP-B/32.
Significance. If the central claims hold, the work offers a structured approach to multimodal unlearning in federated settings, addressing entanglement issues not handled by prior federated unlearning methods. The explicit identification of the three anchors and their targeted closures provides a conceptual contribution that could extend to other contrastive or multimodal federated scenarios. Credit is due for the empirical demonstration of near-retrain performance under the reported conditions and for grounding the design in modality-level and subspace-level mechanisms.
major comments (2)
- [§4.2] §4.2 (Cosine-Sine decomposition of client-update subspaces): The isolation of forget-exclusive directions assumes that principal angles between forget and retain update subspaces permit clean separation without overlap. Given shared semantic content in multimodal pairs (e.g., Flickr30K), non-orthogonal angles are likely; this risks incomplete forget removal or unintended retain degradation, directly undermining the reported 0.2/4.2 R@1 match to retrain.
- [Experimental evaluation] Experimental evaluation (Flickr30K client-unlearning results): The claim that the three closures fully eliminate the anchors without new entanglements requires explicit ablation isolating each component's contribution and verification that subspace angles remain separable post-decomposition; without this, the no-degradation assumption on retain performance cannot be assessed as load-bearing for the superiority claim.
minor comments (3)
- [Abstract] Abstract: The statement of 'consistent superiority across multiple datasets and unlearning scenarios' would benefit from a brief quantitative summary table or additional R@1 numbers for at least one other dataset to support the generalization claim.
- [Introduction] Notation: The term 'Anchor Principle' is introduced without a formal definition or numbered statement; adding a boxed definition or equation would improve clarity for readers.
- [Figures] Figure clarity: Ensure that any subspace visualization (e.g., principal angles before/after Cosine-Sine) includes axis labels and legends indicating forget vs. retain directions for direct comparison to the textual claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the assumptions in the Cosine-Sine decomposition and the experimental evaluation. We address each major comment point by point below, providing clarifications grounded in the manuscript's formulation and outlining targeted revisions where appropriate.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Cosine-Sine decomposition of client-update subspaces): The isolation of forget-exclusive directions assumes that principal angles between forget and retain update subspaces permit clean separation without overlap. Given shared semantic content in multimodal pairs (e.g., Flickr30K), non-orthogonal angles are likely; this risks incomplete forget removal or unintended retain degradation, directly undermining the reported 0.2/4.2 R@1 match to retrain.
Authors: We agree that shared semantic content in multimodal datasets such as Flickr30K typically yields non-orthogonal principal angles between forget and retain client-update subspaces. The Cosine-Sine decomposition in §4.2 is explicitly constructed to accommodate this: it decomposes the concatenated client-update matrix via the SVD of the cross-subspace correlation, extracting the sine and cosine terms of the principal angles to isolate the component of the forget subspace that lies in the orthogonal complement of the retain support. This selective projection excises only the forget-exclusive directions while preserving the retain-aligned components, without requiring perfect orthogonality. The reported near-retrain performance (0.2 R@1 on forget, 4.2 R@1 on retain) under client unlearning with CLIP-B/32 on Flickr30K provides empirical evidence that residual overlap does not materially impair the outcome. To strengthen the presentation, we will add a brief analysis of observed principal angles in the experiments and a short robustness discussion in the revised §4.2. revision: partial
-
Referee: [Experimental evaluation] Experimental evaluation (Flickr30K client-unlearning results): The claim that the three closures fully eliminate the anchors without new entanglements requires explicit ablation isolating each component's contribution and verification that subspace angles remain separable post-decomposition; without this, the no-degradation assumption on retain performance cannot be assessed as load-bearing for the superiority claim.
Authors: We concur that explicit component-wise ablations and post-decomposition angle verification would make the contribution of each anchor closure more transparent and would allow direct assessment of whether new entanglements arise. The current manuscript reports overall superiority against baselines and close parity with the retrain reference, but does not isolate the bilateral displacement, Cosine-Sine decomposition, and Forget Lock individually nor tabulate angle separability metrics before and after each step. We will incorporate these ablations (including per-component R@1 deltas on forget/retain sets and principal-angle histograms) into the revised experimental section, thereby confirming that the observed retain performance is attributable to the targeted closures rather than incidental factors. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper identifies an 'Anchor Principle' for federated multimodal contrastive unlearning and proposes three closures (bilateral displacement, Cosine-Sine decomposition of client-update subspaces, and direction-selective Forget Lock) under the EASE framework. No equations, derivations, or parameter-fitting steps are visible in the provided text that reduce by construction to the inputs (e.g., no self-definitional anchors, no fitted parameters renamed as predictions, and no load-bearing self-citations). The central claims rest on empirical matching to a retrain reference (0.2/4.2 R@1 points), which is presented as an independent validation rather than a tautological reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Memory Aware Synapses: Learning What (not) to Forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory Aware Synapses: Learning What (not) to Forget. InProceedings of the European Conference on Computer Vision, pages 144–161, 2018. doi: 10.1007/978-3-030-01219-9_9
-
[2]
One Engine to Fuzz 'em All: Generic Language Processor Testing with Semantic Validation,
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine Unlearning. InIEEE Symposium on Security and Privacy, pages 141–159, 2021. doi: 10.1109/SP40001.2021.00019
-
[3]
In: 44th IEEE Symposium on Security and Privacy, SP 2023, San Francisco, CA, USA, May 21-25, 2023
Xiaoyu Cao, Jinyuan Jia, Zaixi Zhang, and Neil Zhenqiang Gong. FedRecover: Recovering from Poisoning Attacks in Federated Learning using Historical Information. InIEEE Symposium on Security and Privacy, pages 1366–1383, 2023. doi: 10.1109/SP46215.2023.10179336
-
[4]
IEEE Symposium on Security and Privacy , year =
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership Inference Attacks From First Principles. InIEEE Symposium on Security and Privacy, pages 1897–1914, 2022. doi: 10.1109/SP46214.2022.9833649
-
[5]
Fast Federated Machine Unlearning with Nonlinear Functional Theory
Tianshi Che, Yang Zhou, Zijie Zhang, Lingjuan Lyu, Ji Liu, Da Yan, Dejing Dou, and Jun Huan. Fast Federated Machine Unlearning with Nonlinear Functional Theory. InProceedings of the International Conference on Machine Learning, 2023
2023
-
[6]
FedDAT: An Approach for Foundation Model Finetuning in Multi-Modal Heterogeneous Federated Learning
Haokun Chen, Yao Zhang, Denis Krompass, Jindong Gu, and V olker Tresp. FedDAT: An Approach for Foundation Model Finetuning in Multi-Modal Heterogeneous Federated Learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 11285– 11293, 2024. doi: 10.1609/aaai.v38i10.29007
-
[7]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv preprint arXiv:1504.00325, 2015
work page internal anchor Pith review arXiv 2015
-
[8]
A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V-Assisted Heterogeneous Vehicle Networks
Zihao Ding, Jun Huang, Qiang Duan, Cheng Zhang, Yanxiao Zhao, and Shuyang Gu. A Dual- Level Game-Theoretic Approach for Collaborative Learning in UA V-Assisted Heterogeneous Vehicle Networks. In2025 IEEE International Performance, Computing, and Communications Conference (IPCCC), pages 1–8. IEEE, 2025
2025
-
[9]
Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing
Zihao Ding, Jun Huang, and Junjian Qi. Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing. InInterna- tional Conference on Computing, Networking and Communications (ICNC), Honolulu, Hawaii, USA, February 2026. IEEE
2026
-
[10]
SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing
Zihao Ding, Beining Wu, and Jun Huang. SCALE: Sensitivity-Aware Federated Unlearning with Information Freshness Optimization for Mobile Edge Computing. InProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[11]
Orthogonal Gradient Descent for Continual Learning
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. Orthogonal Gradient Descent for Continual Learning. InProceedings of the International Conference on Artificial Intelligence and Statistics, pages 3762–3773, 2020
2020
-
[12]
Xiangshan Gao, Xingjun Ma, Jingyi Wang, Youcheng Sun, Bo Li, Shouling Ji, Peng Cheng, and Jiming Chen. VeriFi: Towards Verifiable Federated Unlearning.IEEE Transactions on Dependable and Secure Computing, 21(6):5720–5736, 2024. doi: 10.1109/TDSC.2024. 3382321
-
[13]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9304–9312, 2020. doi: 10.1109/CVPR42600. 2020.00932
-
[14]
Federated un- learning: How to efficiently erase a client in fl?
Anisa Halimi, Swanand Kadhe, Ambrish Rawat, and Nathalie Baracaldo. Federated Unlearning: How to Efficiently Erase a Client in FL? arXiv preprint arXiv:2207.05521, 2022. 10
-
[15]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In International Conference on Learning Representations, 2022
2022
-
[16]
Jun Huang, Beining Wu, Qiang Duan, Liang Dong, and Shui Yu. A Fast UA V Trajectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating.IEEE Transactions on Mobile Computing, pages 1–16, 2025. doi: 10.1109/TMC.2025.3544903
-
[17]
SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning
Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffenderfer, Bhavya Kailkhura, and Sijia Liu. SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning. InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 4276–4292, 2024. doi: 10.18653/v1/2024.emnlp-main.245
-
[18]
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Ar- jun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and Open Problems in Federated Learning.Foundations and Trends in Machine Learning, 14(1–2):1–210, 2021. doi: 10.1561/2200000083
-
[19]
Deep Visual-Semantic Alignments for Generating Image Descriptions
Andrej Karpathy and Li Fei-Fei. Deep Visual-Semantic Alignments for Generating Image Descriptions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3128–3137, 2015. doi: 10.1109/CVPR.2015.7298932
-
[20]
Syntab-llava: Enhancing multimodal table understanding with decou- pled synthesis
Yasser H. Khalil, Leo Maxime Brunswic, Soufiane Lamghari, Xu Li, Mahdi Beitollahi, and Xi Chen. NoT: Federated Unlearning via Weight Negation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25759–25769, 2025. doi: 10.1109/CVPR52734.2025.02399
-
[21]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13): 35...
-
[22]
Understanding Black-box Predictions via Influence Functions
Pang Wei Koh and Percy Liang. Understanding Black-box Predictions via Influence Functions. InProceedings of the International Conference on Machine Learning, pages 1885–1894, 2017
2017
-
[23]
Towards Un- bounded Machine Unlearning
Meghdad Kurmanji, Peter Triantafillou, Jamie Hayes, and Eleni Triantafillou. Towards Un- bounded Machine Unlearning. InAdvances in Neural Information Processing Systems, vol- ume 36, pages 1957–1987, 2023
1957
-
[24]
Cross-Modal Unlearning via Influential Neuron Path Editing in Multimodal Large Language Models
Kunhao Li, Weiwei Li, Di Wu, Lei Yang, Jun Bai, and Ju Jia. Cross-Modal Unlearning via Influential Neuron Path Editing in Multimodal Large Language Models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35589–35597, 2026. doi: 10.1609/aaai.v40i42.40870
-
[25]
IEEE Signal Processing Magazine , author =
Tian Li, Anit Kumar Sahu, Ameet Talwalkar, and Virginia Smith. Federated Learning: Chal- lenges, Methods, and Future Directions.IEEE Signal Processing Magazine, 37(3):50–60, 2020. doi: 10.1109/MSP.2020.2975749
-
[26]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, pages 740–755, 2014. doi: 10.1007/978-3-319-10602-1_48
-
[27]
FedEraser: En- abling Efficient Client-Level Data Removal from Federated Learning Models
Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. FedEraser: En- abling Efficient Client-Level Data Removal from Federated Learning Models. InIEEE/ACM International Symposium on Quality of Service, pages 1–10, 2021. doi: 10.1109/IWQOS52092. 2021.9521274
-
[28]
Hanlin Liu, Peng Xiong, Tianqing Zhu, and Philip S. Yu. Ferrari: Federated Feature Unlearning via Optimizing Feature Sensitivity. InProceedings of the International Conference on Machine Learning, 2024. 11
2024
-
[29]
Communication-Efficient Learning of Deep Networks from Decentralized Data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-Efficient Learning of Deep Networks from Decentralized Data. InProceedings of the International Conference on Artificial Intelligence and Statistics, pages 1273–1282, 2017
2017
-
[30]
A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum-Based Nano-Communication Technique
Dong Pan, Bei-Ning Wu, Yi-Liu Sun, and Yi-Peng Xu. A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum-Based Nano-Communication Technique. Sustainable Computing: Informatics and Systems, 37:100827, 2023
2023
-
[31]
Federated Unlearning with Gradient Descent and Conflict Mitigation
Zibin Pan, Zhichao Wang, Chi Li, Kaiyan Zheng, Boqi Wang, Xiaoying Tang, and Junhua Zhao. Federated Unlearning with Gradient Descent and Conflict Mitigation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 19804–19812, 2025. doi: 10.1609/aaai.v39i19.34181
-
[32]
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
Samuele Poppi, Tobia Poppi, Federico Cocchi, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models. In Proceedings of the European Conference on Computer Vision, pages 340–356, 2024. doi: 10.1007/978-3-031-73668-1_20
-
[33]
Un- learning Vision Transformers Without Retaining Data via Low-Rank Decompositions
Samuele Poppi, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Un- learning Vision Transformers Without Retaining Data via Low-Rank Decompositions. In Proceedings of the European Conference on Computer Vision, pages 147–163, 2024. doi: 10.1007/978-3-031-78122-3_10
-
[34]
Securing Smart Agriculture with Communication- Efficient Federated Unlearning
Ujjwal Pudasaini, Zihao Ding, and Jun Huang. Securing Smart Agriculture with Communication- Efficient Federated Unlearning. In2026 IEEE International Conference on High Performance Switching and Routing (HPSR), pages 1–8. IEEE, 2026
2026
-
[35]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, pages 8748–8763, 2021
2021
-
[36]
Gradient Projection Memory for Continual Learning
Gobinda Saha, Isha Garg, and Kaushik Roy. Gradient Projection Memory for Continual Learning. InInternational Conference on Learning Representations, 2021
2021
-
[37]
Membership Inference Attacks Against Machine Learning Models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership Inference Attacks Against Machine Learning Models. InIEEE Symposium on Security and Privacy, pages 3–18, 2017. doi: 10.1109/SP.2017.41
-
[38]
TextCaps: A Dataset for Image Captioning with Reading Comprehension
Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. TextCaps: A Dataset for Image Captioning with Reading Comprehension. InProceedings of the European Conference on Computer Vision, pages 742–758, 2020. doi: 10.1007/978-3-030-58536-5_44
-
[39]
On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning
Anvith Thudi, Hengrui Jia, Ilia Shumailov, and Nicolas Papernot. On the Necessity of Auditable Algorithmic Definitions for Machine Unlearning. InUSENIX Security Symposium, pages 4007–4022, 2022
2022
-
[40]
2017.The EU General Data Protection Regulation (GDPR): A Practical Guide
Paul V oigt and Axel von dem Bussche.The EU General Data Protection Regulation (GDPR): A Practical Guide. Springer International Publishing, 2017. doi: 10.1007/978-3-319-57959-7
-
[41]
Federated Unlearning via Class-Discriminative Pruning
Junxiao Wang, Song Guo, Xin Xie, and Heng Qi. Federated Unlearning via Class-Discriminative Pruning. InProceedings of the ACM Web Conference, pages 622–632, 2022. doi: 10.1145/ 3485447.3512222
-
[42]
Shipeng Wang, Xiaorong Li, Jian Sun, and Zongben Xu. Training Networks in Null Space of Feature Covariance for Continual Learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 184–193, 2021. doi: 10.1109/CVPR46437. 2021.00025
-
[43]
Lifecycle-Aware Federated Continual Learning in Mobile Autonomous Systems
Beining Wu and Jun Huang. Lifecycle-Aware Federated Continual Learning in Mobile Au- tonomous Systems. arXiv preprint arXiv:2604.20745, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Beining Wu and Wei Wu. Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning.Mathematical Problems in Engineering, 2023(1):6350647, 2023
2023
-
[45]
AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning.IEEE Access, 2023
Beining Wu, Zhengkun Cai, Wei Wu, and Xiaobin Yin. AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning.IEEE Access, 2023
2023
-
[46]
Beining Wu, Jun Huang, and Qiang Duan. Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization.IEEE Network, 40(2):184–191, 2025. doi: 10.1109/MNET.2025.3565977
-
[47]
FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning
Beining Wu, Jun Huang, and Qiang Duan. FedTD3: An Accelerated Learning Approach for UA V Trajectory Planning. InInternational Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA), pages 13–24. Springer, 2025
2025
-
[48]
Beining Wu, Jun Huang, Qiang Duan, Liang Dong, and Zhipeng Cai. Enhancing Vehicular Pla- tooning With Wireless Federated Learning: A Resource-Aware Control Framework.IEEE/ACM Transactions on Networking, pages 1–1, 2025. doi: 10.1109/TON.2025.3625084
-
[49]
Beining Wu, Zihao Ding, and Jun Huang. RELIEF: Turning Missing Modalities into Training Acceleration for Federated Learning on Heterogeneous IoT Edge. arXiv preprint arXiv:2604.04243, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Beining Wu, Zihao Ding, and Jun Huang. A Review of Continual Learning in Edge AI.IEEE Transactions on Network Science and Engineering, 13:6571–6588, 2026. doi: 10.1109/TNSE. 2026.3657652
-
[51]
Beining Wu, Jun Huang, and Shui Yu. “X of Information” Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Networked Systems.IEEE Communications Surveys & Tutorials, 28:5307–5344, 2026. doi: 10.1109/COMST.2026.3670279
-
[52]
From Alpha to Omega: Lifecycle-Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration
Beining Wu, Jun Huang, and Yanxiao Zhao. From Alpha to Omega: Lifecycle-Aware Forgetting Defense in Federated Continual Learning for Planetary Exploration. InProceedings of the IEEE International Conference on Distributed Computing Systems (ICDCS), 2026
2026
-
[53]
arXiv preprint arXiv:2201.09441 (2022)
Chen Wu, Sencun Zhu, and Prasenjit Mitra. Federated Unlearning with Knowledge Distillation. arXiv preprint arXiv:2201.09441, 2022
-
[54]
Available: https://doi.org/10.1145/3787594.3787596
Cong-Cong Xing, Zihao Ding, and Jun Huang. A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting.SIGAPP Appl. Comput. Rev., 25(4):18–34, January 2026. ISSN 1559-6915. doi: 10.1145/3787594.3787596. URL https://doi.org/10.1145/3787594.3787596
-
[55]
Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. Federated Machine Learning: Concept and Applications.ACM Transactions on Intelligent Systems and Technology, 10(2): 12:1–12:19, 2019. doi: 10.1145/3298981
-
[56]
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014. doi: 10.1162/ tacl_a_00166
2014
-
[57]
Multimodal Federated Learning via Contrastive Representation Ensemble
Qiying Yu, Yang Liu, Yimu Wang, Ke Xu, and Jingjing Liu. Multimodal Federated Learning via Contrastive Representation Ensemble. InInternational Conference on Learning Representations, 2023
2023
-
[58]
Continual Learning Through Synaptic Intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual Learning Through Synaptic Intelligence. InProceedings of the International Conference on Machine Learning, pages 3987–3995, 2017
2017
-
[59]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid Loss for Language Image Pre-Training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11941–11952, 2023. doi: 10.1109/ICCV51070.2023.01100. 13
-
[60]
Syntab-llava: Enhancing multimodal table understanding with decou- pled synthesis
Zhengyi Zhong, Weidong Bao, Ji Wang, Shuai Zhang, Jingxuan Zhou, Lingjuan Lyu, and Wei Yang Bryan Lim. Unlearning through Knowledge Overwriting: Reversible Federated Unlearning via Selective Sparse Adapter. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 30661–30670, 2025. doi: 10.1109/CVPR52734.2025.02855. 14 Ap...
-
[61]
with a uniformly bounded second-order residual. Assumption C.3(A3: Anchor residual after bilateral excision, verifiable form).After applying bilateral excision to both modalities, producing w∗ = (w∗ v, w∗ t ) with Πu,µ(w∗ µ −w n,µ) = 0 for both µ∈ {v, t} , the residual Modality Anchor signal along unique directions is bounded: for a small constantϵ anchor...
-
[62]
For any ∆µ ∈ S f expressed in the canonical basis as∆ µ =Pp i=1 αici, this equalsP i:cosφ i≤δ α2 i . (iii) Forget energy ratio: ηf(δ) =∥B ⊤ u,µGf,µ∥2 F /∥Gf,µ∥2 F is monotonically non-decreasing in δ and satisfies ηf(1)≥τ e (equality only when the truncation exactly meets the energy threshold). Proof. We work with a single modality µ throughout; the argum...
-
[63]
Then both ηf(δ) and ηr(δ) are monotonically non- decreasing in δ∈[0,1] . Moreover, for any target unlearning ratioη∗ f ∈(0, τ e], the smallest threshold achieving ηf(δ)≥η ∗ f is δ∗ = cosφ k∗, where k∗ = min{k:η f(cosφ k)≥η ∗ f } and φ1 ≤ · · · ≤φ p are the principal angles in non-decreasing order. This δ∗ simultaneously minimizes the retention damage boun...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.