Recognition: unknown
Can Coding Agents Reproduce Findings in Computational Materials Science?
Pith reviewed 2026-05-09 19:12 UTC · model grok-4.3
The pith
LLM-based coding agents reproduce computational materials science claims at a maximum 54 percent success rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
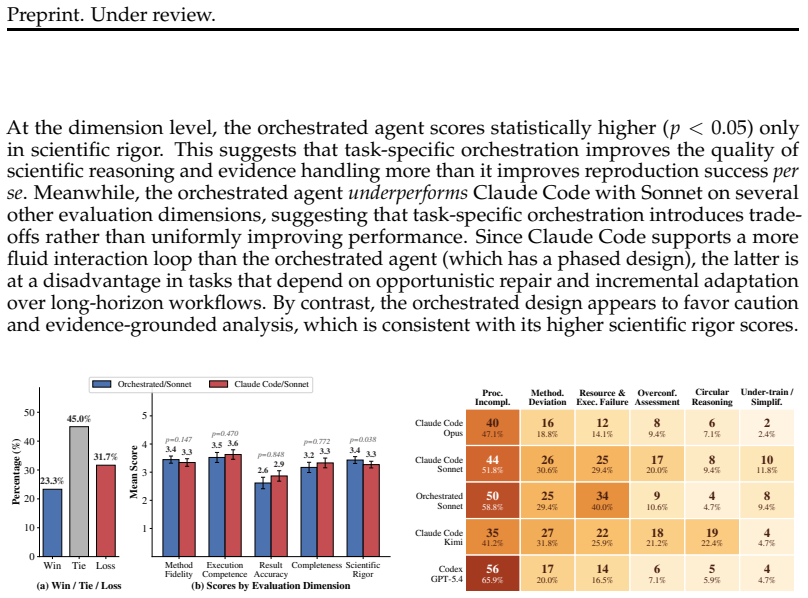
By curating claims drawn from published materials science papers with subject-matter expert input, the AutoMat benchmark shows that LLM-based coding agents reach a peak success rate of only 54.1 percent when asked to reproduce the full computational workflow and verify support for the claim, with the largest drops occurring on text-only reconstructions and the dominant failure modes being incomplete procedures, methodological deviations, and execution fragility.
What carries the argument
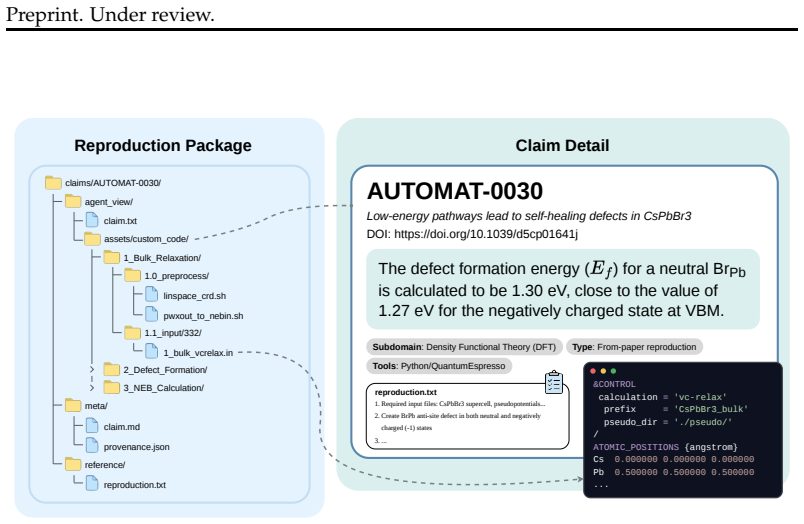
AutoMat, a benchmark that requires agents to recover underspecified computational procedures from paper text, navigate domain-specific toolchains, and determine whether generated evidence supports the original claim.
If this is right
- Agents perform worst when they must reconstruct the entire workflow from the paper text without additional context or code.
- The three main failure categories are incomplete procedures, departures from the published method, and fragile execution that crashes or produces inconsistent output.
- AutoMat functions simultaneously as a reproducibility benchmark and as a diagnostic instrument for locating specific weaknesses in agentic systems.
- Different foundation models and agent configurations produce measurably different success rates on the same set of claims.
Where Pith is reading between the lines
- Comparable benchmarks could be constructed for other computational fields to map where agent performance remains limited.
- Targeted improvements in recovering ambiguous scientific instructions and in stable execution of specialized software would likely raise success rates on tasks like these.
- Wider adoption of such benchmarks could eventually support automated checking of published computational results before or after peer review.
Load-bearing premise
The set of claims drawn from actual materials science papers and reviewed by subject experts forms a representative test of agents' ability to reproduce computational findings.
What would settle it
An experiment in which the same agents are given the original source code or supplementary scripts from the source papers and then re-evaluated on AutoMat would show whether the 54.1 percent ceiling is caused by information gaps in the benchmark or by deeper limitations in the agents themselves.
Figures



read the original abstract
Large language models are increasingly deployed as autonomous coding agents and have achieved remarkably strong performance on software engineering benchmarks. However, it is unclear whether such success transfers to computational scientific workflows, where tasks require not only strong coding ability, but also the ability to navigate complex, domain-specific procedures and to interpret results in the context of scientific claims. To address this question, we present AutoMat, a benchmark for evaluating LLM-based agents' ability to reproduce claims from computational materials science. AutoMat poses three interrelated challenges: recovering underspecified computational procedures, navigating specialized toolchains, and determining whether the resulting evidence supports a claim. By working closely with subject matter experts, we curate a set of claims from real materials science papers to test whether coding agents can recover and execute the end-to-end workflow needed to support (or undermine) such claims. We then evaluate multiple representative coding agent settings across several foundation models. Our results show that current LLM-based agents obtain low overall success rates on AutoMat, with the best-performing setting achieving a success rate of only 54.1%. Error analysis further reveals that agents perform worst when workflows must be reconstructed from paper text alone and that they fail primarily due to incomplete procedures, methodological deviations, and execution fragility. Taken together, these findings position AutoMat as both a benchmark for computational scientific reproducibility and a tool for diagnosing the current limitations of agentic systems in AI-for-science settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoMat, a benchmark for assessing LLM-based coding agents on reproducing computational materials science claims. It curates expert-validated claims from real papers, requiring agents to reconstruct underspecified workflows from text, execute them using domain toolchains, and determine if outputs support the claim. Evaluations of multiple agent configurations across foundation models yield a maximum success rate of 54.1%, with failures primarily attributed to incomplete procedure recovery, methodological deviations, and execution fragility.
Significance. If the benchmark tasks are representative and the success metric robust, the work provides a concrete empirical demonstration of current limitations in agentic systems for scientific reproducibility tasks. It contributes a reusable benchmark and diagnostic error analysis that could inform AI-for-science research, particularly in domains requiring integration of domain knowledge, underspecified procedures, and result interpretation. The multi-model, multi-setting evaluation and expert curation are strengths that enhance the study's utility as a diagnostic tool.
major comments (2)
- [Evaluation and Results] The manuscript reports no human expert performance baseline on the AutoMat tasks using the same claim set and evaluation rubric. This is load-bearing for the central claim (abstract and results) that 54.1% constitutes a 'low' success rate specifically attributable to LLM-agent limitations rather than inherent task difficulty, since recovering underspecified workflows and judging claim support from paper text alone is non-trivial even for domain experts without original code or notes.
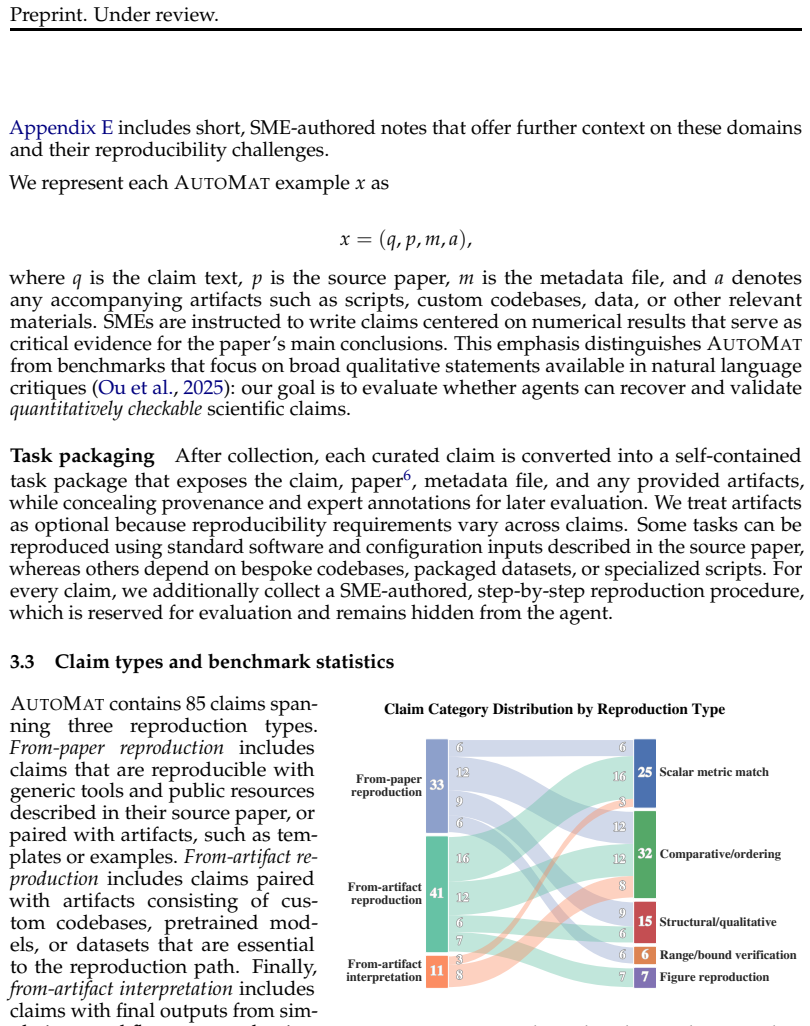
- [Benchmark Construction] §3 (Benchmark Construction): Exact criteria for claim selection, quantitative success metrics, and the operational definition of 'execution fragility' are not detailed. This limits assessment of whether the 54.1% figure and error categories are robust, as noted in the abstract's description of expert curation and multi-setting evaluations.
minor comments (2)
- [Benchmark Construction] Clarify the exact number of claims in the benchmark and the distribution across materials science sub-domains to aid reproducibility of the curation process.
- [Abstract] The abstract states 'low overall success rates' but does not define the threshold for 'low' relative to other SE or scientific benchmarks; adding a brief comparison would improve context.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point by point below, indicating where we agree and what revisions will be made.
read point-by-point responses
-
Referee: [Evaluation and Results] The manuscript reports no human expert performance baseline on the AutoMat tasks using the same claim set and evaluation rubric. This is load-bearing for the central claim (abstract and results) that 54.1% constitutes a 'low' success rate specifically attributable to LLM-agent limitations rather than inherent task difficulty, since recovering underspecified workflows and judging claim support from paper text alone is non-trivial even for domain experts without original code or notes.
Authors: We agree that a human expert baseline would strengthen interpretation of the 54.1% figure. Our expert curation validated claims and workflows but did not include a controlled human reproduction study under identical conditions. We will revise the Evaluation and Results sections to explicitly acknowledge this limitation and discuss why the observed failure modes (incomplete procedure recovery, methodological deviations) are more pronounced for agents than for trained experts. This will be a partial revision: we will add contextual discussion and error-category comparisons rather than new human experiments, as the latter would require substantial additional resources. revision: partial
-
Referee: [Benchmark Construction] §3 (Benchmark Construction): Exact criteria for claim selection, quantitative success metrics, and the operational definition of 'execution fragility' are not detailed. This limits assessment of whether the 54.1% figure and error categories are robust, as noted in the abstract's description of expert curation and multi-setting evaluations.
Authors: We thank the referee for highlighting this. We will expand §3 with precise details: claim selection requires computational workflows from peer-reviewed papers using open toolchains (e.g., VASP, LAMMPS), sufficient textual description for reconstruction, and independent validation by two experts for feasibility and scientific accuracy. Success is defined quantitatively as the agent producing outputs that match reported values within 5% or reach the same conclusion as the claim. 'Execution fragility' is operationalized as failures from environment/dependency issues, non-determinism, or toolchain inconsistencies (distinct from conceptual or procedural errors). Examples from our analysis will be added to support these definitions. revision: yes
Circularity Check
No circularity: purely empirical benchmark with external tasks
full rationale
This is an empirical evaluation paper that curates claims from real materials science papers (with expert input) and directly measures LLM agent success rates on reproducing the associated computational workflows. No mathematical derivations, equations, fitted parameters, or predictions are present. The 54.1% success rate is an observed outcome on externally sourced tasks rather than a quantity derived from or equivalent to the paper's own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked in a load-bearing way. The study is self-contained against external benchmarks, consistent with the default non-circular finding for such work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Claims extracted from published computational materials science papers, when curated with subject matter experts, constitute a representative test of agent ability to recover and execute scientific workflows.
Reference graph
Works this paper leans on
-
[1]
Physical review , volume=
Inhomogeneous electron gas , author=. Physical review , volume=. 1964 , publisher=
1964
-
[2]
Physical review , volume=
Self-consistent equations including exchange and correlation effects , author=. Physical review , volume=. 1965 , publisher=
1965
-
[3]
2022 , publisher=
Density functional theory: a practical introduction , author=. 2022 , publisher=
2022
-
[4]
Langmuir , volume=
Structural and dynamical properties of liquids in confinements: A review of molecular dynamics simulation studies , author=. Langmuir , volume=. 2022 , publisher=
2022
-
[5]
International Conference on Machine Learning , pages=
PaperBench: Evaluating AI’s Ability to Replicate AI Research , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[6]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Matter-of-Fact: A benchmark for verifying the feasibility of literature-supported claims in materials science , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[7]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
CodeScientist: End-to-end semi-automated scientific discovery with code-based experimentation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[8]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
REPRO-Bench: Can Agentic AI Systems Assess the Reproducibility of Social Science Research? , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[9]
Transactions on Machine Learning Research , year=
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark , author=. Transactions on Machine Learning Research , year=
-
[10]
arXiv preprint arXiv:2505.10852 , year=
MatTools: Benchmarking large language models for materials science tools , author=. arXiv preprint arXiv:2505.10852 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
SciCode: A research coding benchmark curated by scientists , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Computational Materials Science , volume=
Python Materials Genomics (pymatgen): A robust, open-source python library for materials analysis , author=. Computational Materials Science , volume=. 2013 , publisher=
2013
-
[13]
arXiv preprint arXiv:2602.16733 , year=
Scaling reproducibility: An AI-assisted workflow for large-scale reanalysis , author=. arXiv preprint arXiv:2602.16733 , year=
-
[14]
arXiv preprint arXiv:2502.00902 , year=
More Rigorous Software Engineering Would Improve Reproducibility in Machine Learning Research , author=. arXiv preprint arXiv:2502.00902 , year=
-
[15]
2026 , howpublished =
2026
-
[16]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[17]
2024 , journal=
A survey on llm-based code generation for low-resource and domain-specific programming languages , author=. 2024 , journal=
2024
-
[18]
SciReplicate-Bench: Benchmarking
Yanzheng Xiang and Hanqi Yan and Shuyin Ouyang and Lin Gui and Yulan He , booktitle=. SciReplicate-Bench: Benchmarking. 2025 , url=
2025
-
[19]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Stackeval: Benchmarking llms in coding assistance , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
Journal of Systems and Software , volume=
Characterising reproducibility debt in scientific software: A systematic literature review , author=. Journal of Systems and Software , volume=. 2025 , publisher=
2025
-
[24]
Computer Science Review , volume=
Reproducibility, Replicability and Repeatability: A survey of reproducible research with a focus on high performance computing , author=. Computer Science Review , volume=. 2024 , publisher=
2024
-
[25]
Digital Discovery , volume=
Reproducibility in materials informatics: lessons from ‘A general-purpose machine learning framework for predicting properties of inorganic materials’ , author=. Digital Discovery , volume=. 2024 , publisher=
2024
-
[26]
Science , volume=
Reproducibility in density functional theory calculations of solids , author=. Science , volume=. 2016 , publisher=
2016
-
[27]
npj Computational Materials , volume=
The mastery of details in the workflow of materials machine learning , author=. npj Computational Materials , volume=. 2024 , publisher=
2024
-
[28]
Workshop on job scheduling strategies for parallel processing , pages=
Slurm: Simple linux utility for resource management , author=. Workshop on job scheduling strategies for parallel processing , pages=. 2003 , organization=
2003
-
[29]
Journal of physics: Condensed matter , volume=
QUANTUM ESPRESSO: a modular and open-source software project for quantum simulations of materials , author=. Journal of physics: Condensed matter , volume=
-
[30]
PloS one , volume=
Singularity: Scientific containers for mobility of compute , author=. PloS one , volume=. 2017 , publisher=
2017
-
[31]
Computer physics communications , volume=
LAMMPS-a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales , author=. Computer physics communications , volume=. 2022 , publisher=
2022
-
[32]
Modelling and simulation in materials science and engineering , volume=
Visualization and analysis of atomistic simulation data with OVITO--the Open Visualization Tool , author=. Modelling and simulation in materials science and engineering , volume=
-
[33]
Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H
Xingyao Wang and Boxuan Li and Yufan Song and Frank F. Xu and Xiangru Tang and Mingchen Zhuge and Jiayi Pan and Yueqi Song and Bowen Li and Jaskirat Singh and Hoang H. Tran and Fuqiang Li and Ren Ma and Mingzhang Zheng and Bill Qian and Yanjun Shao and Niklas Muennighoff and Yizhe Zhang and Binyuan Hui and Junyang Lin and Robert Brennan and Hao Peng and H...
2025
-
[34]
Philosophical Transactions of the Royal Society A , volume=
Learning from reproducing computational results: introducing three principles and the Reproduction Package , author=. Philosophical Transactions of the Royal Society A , volume=. 2021 , publisher=
2021
-
[35]
npj Computational Materials , volume=
Automated optimization and uncertainty quantification of convergence parameters in plane wave density functional theory calculations , author=. npj Computational Materials , volume=. 2024 , publisher=
2024
-
[36]
Digital Discovery , volume=
A reproducibility study of atomistic line graph neural networks for materials property prediction , author=. Digital Discovery , volume=. 2024 , publisher=
2024
-
[37]
arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review arXiv
-
[38]
Physical review letters , volume=
Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties , author=. Physical review letters , volume=. 2018 , publisher=
2018
-
[39]
Chemical Engineering Journal , volume=
From prediction to synthesis: DFT-active learning-guided design of multimetallic catalysts for hydrogen evolution , author=. Chemical Engineering Journal , volume=. 2025 , publisher=
2025
-
[40]
Computational Materials Science , volume=
Temperature-dependent discovery of BCC refractory multi-principal element alloys: Integrating deep learning and CALPHAD calculations , author=. Computational Materials Science , volume=. 2025 , publisher=
2025
-
[41]
Materials & Design , pages=
Machine learning surrogates for CALPHAD inputs in mean-field precipitation modelling of IN738LC , author=. Materials & Design , pages=. 2026 , publisher=
2026
-
[42]
Computational Materials Science , volume=
Machine learning interatomic potentials for monolayer hexagonal boron nitride: Thermal transport and defect effects via deep potential molecular dynamics , author=. Computational Materials Science , volume=. 2026 , publisher=
2026
-
[43]
Physical review letters , volume=
Deep potential molecular dynamics: a scalable model with the accuracy of quantum mechanics , author=. Physical review letters , volume=. 2018 , publisher=
2018
-
[44]
Results in Engineering , volume=
The role of machine learning for insight into the material behavior of lattices: a surrogate model based on data from finite element simulation , author=. Results in Engineering , volume=. 2024 , publisher=
2024
-
[45]
npj Computational Materials , volume=
An interpretable deep learning approach for designing nanoporous silicon nitride membranes with tunable mechanical properties , author=. npj Computational Materials , volume=. 2023 , publisher=
2023
-
[46]
npj Computational Materials , volume=
Machine learning surrogate for 3D phase-field modeling of ferroelectric tip-induced electrical switching , author=. npj Computational Materials , volume=. 2024 , publisher=
2024
-
[47]
Materials Characterization , volume=
Prediction of hardness or yield strength for ODS steels based on machine learning , author=. Materials Characterization , volume=. 2024 , publisher=
2024
-
[48]
Introducing Claude Sonnet 4.6 , year =
-
[49]
Introducing Claude Opus 4.6 , year =
-
[50]
Introducing GPT-5.4 , year =
-
[51]
, author=
Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. , author=. Psychological bulletin , volume=. 1968 , publisher=
1968
- [52]
-
[53]
CLAIMCHECK : How Grounded are LLM Critiques of Scientific Papers?
Ou, Jiefu and Walden, William and Sanders, Kate and Jiang, Zhengping and Sun, Kaiser and Cheng, Jeffrey and Jurayj, William and Wanner, Miriam and Liang, Shaobo and Morgan, Candice and Han, Seunghoon and Wang, Weiqi and May, Chandler and Recknor, Hannah and Khashabi, Daniel and Van Durme, Benjamin. CLAIMCHECK : How Grounded are LLM Critiques of Scientific...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.