Recognition: no theorem link
GhostServe: A Lightweight Checkpointing System in the Shadow for Fault-Tolerant LLM Serving
Pith reviewed 2026-05-15 00:34 UTC · model grok-4.3
The pith
GhostServe applies erasure coding to the KV cache in host memory for fast failure recovery in LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying erasure coding to generate parity shards for the streaming KV cache and storing those shards in host memory, GhostServe allows the inference process to resume after device failures through fast reconstruction of the lost cache state instead of costly recomputation.
What carries the argument
Erasure coding on the KV cache to produce and store parity shards in host memory for shadow protection and reconstruction.
If this is right
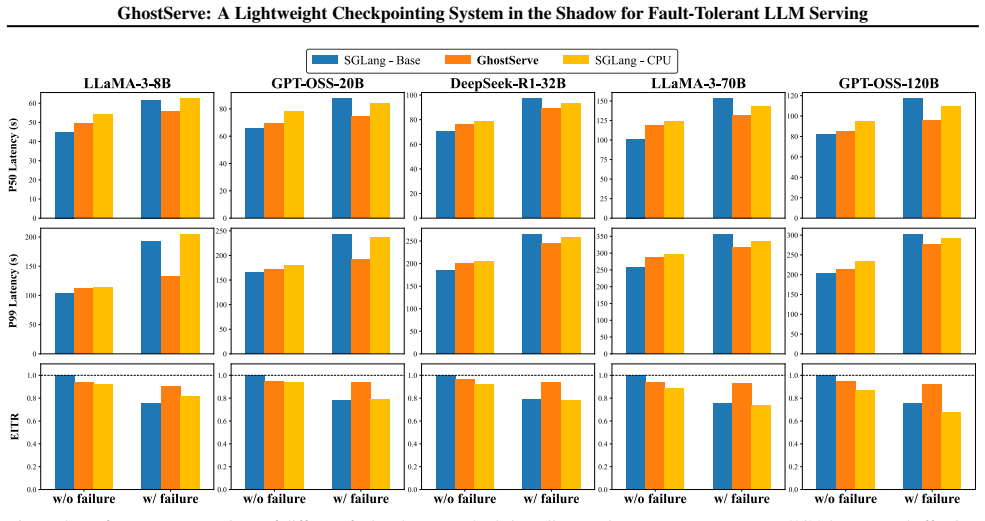
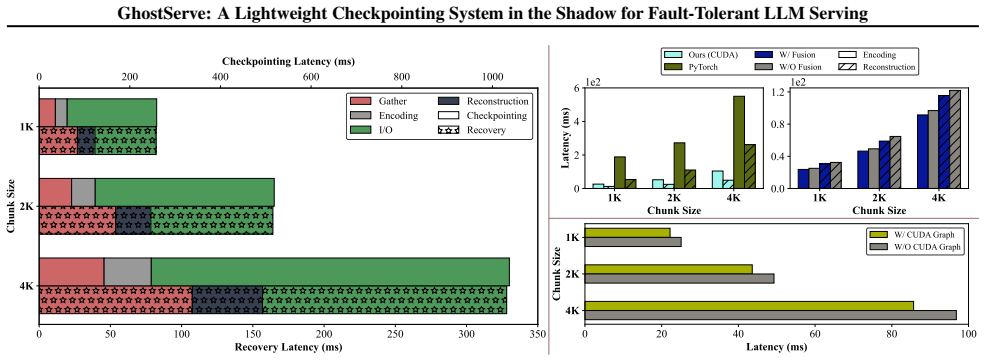
- Checkpointing latency is reduced by up to 2.7x for a single batch compared to existing methods.
- Recovery latency is reduced by 2.1x for a single batch.
- Median response latency improves by 1.2x in the presence of system failures.
- Seamless resumption of inference without full recomputation or state replication.
- Support for fault-tolerant serving of long-sequence LLM applications at lower cost.
Where Pith is reading between the lines
- Longer context windows would benefit more since KV cache growth amplifies the savings.
- The approach might extend to protecting other transient states in distributed inference.
- Combining with other fault tolerance techniques could further improve availability.
- Adoption could lower operational costs for cloud LLM providers by reducing wasted compute on failures.
Load-bearing premise
Erasure coding overhead remains small enough that cache reconstruction from host memory parities is faster than recomputing the sequence from prior state.
What would settle it
Measure the end-to-end time from failure detection to resumed inference for a long sequence using GhostServe versus a baseline that restarts computation, checking if the reconstruction path is faster.
Figures






read the original abstract
The rise of million-token, agent-based applications has placed unprecedented demands on large language model (LLM) inference services. The long-running nature of these tasks increases their susceptibility to hardware and software faults, leading to costly job failures, wasted resources, and degraded user experience. The stateful key-value (KV) cache, which grows with the sequence length, presents a central challenge as it is a critical and vulnerable component in distributed serving systems. In this work, we propose GhostServe, a novel checkpointing solution to facilitate fault-tolerant LLM serving. Specifically, GhostServe protects the streaming KV cache in the shadow by applying erasure coding to generate and store the parity shards in host memory. In the event of device failures, GhostServe enables fast reconstruction of the lost KV cache, allowing the inference process to resume seamlessly without costly full recomputation or state replication. Evaluations demonstrate that GhostServe reduces checkpointing latency by up to 2.7x and recovery latency by 2.1x for a single batch, and 1.2x median response latency compared to existing methods, in the presence of system failures, paving the way for high-availability and cost-effective LLM serving at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GhostServe, a checkpointing system for fault-tolerant LLM serving that applies erasure coding to protect the streaming KV cache by storing parity shards in host memory. Upon device failure, it reconstructs the lost cache state to resume inference without full recomputation or replication. Evaluations claim up to 2.7x lower checkpointing latency, 2.1x lower recovery latency for a single batch, and 1.2x lower median response latency versus existing methods under failures.
Significance. If the reconstruction remains faster than recomputation at scale, the work addresses a key reliability gap for long-running, million-token LLM inference services. The lightweight host-memory parity approach could reduce overhead compared to full replication while enabling seamless recovery, supporting higher availability in distributed serving systems.
major comments (2)
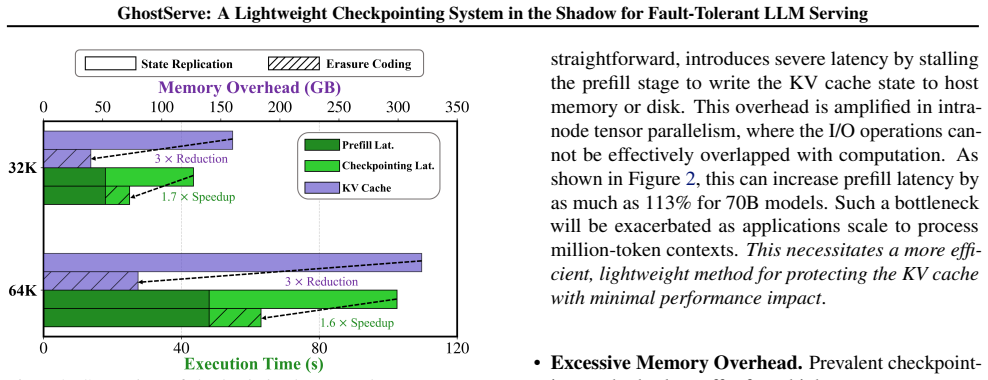
- [§5.3] §5.3 (Recovery Latency Evaluation): The 2.1x recovery improvement is shown only against other checkpointing baselines; no head-to-head timing versus full forward-pass recomputation of the KV cache is reported for sequences of 1M+ tokens, leaving the central claim that erasure-coded reconstruction avoids costly recomputation untested.
- [§4.2] §4.2 (Erasure Coding Design): The mechanism for maintaining parity shards incrementally as the KV cache appends tokens is not fully specified (e.g., per-token vs. batched updates); without quantified PCIe/host bandwidth or CPU overhead scaling with sequence length, it is unclear whether the approach remains low-overhead during normal operation for growing caches.
minor comments (2)
- Abstract and §5: The reported speedups (2.7x, 2.1x, 1.2x) should include the exact model sizes, batch configurations, and number of runs with variance to allow verification of the multipliers.
- [Figure 4] Figure 4 (or equivalent latency plots): Add error bars or confidence intervals to all bar graphs showing checkpointing and recovery times.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the paper to strengthen the presentation and evaluation where needed.
read point-by-point responses
-
Referee: [§5.3] §5.3 (Recovery Latency Evaluation): The 2.1x recovery improvement is shown only against other checkpointing baselines; no head-to-head timing versus full forward-pass recomputation of the KV cache is reported for sequences of 1M+ tokens, leaving the central claim that erasure-coded reconstruction avoids costly recomputation untested.
Authors: We agree that a direct comparison to full recomputation would provide stronger support for the central claim. In the revised manuscript we will add experiments that measure the wall-clock time required to recompute the KV cache from scratch via forward passes for sequences of 1M+ tokens and directly contrast these times with GhostServe reconstruction latency under the same hardware configuration. This will quantify the savings relative to recomputation rather than only to other checkpointing schemes. revision: yes
-
Referee: [§4.2] §4.2 (Erasure Coding Design): The mechanism for maintaining parity shards incrementally as the KV cache appends tokens is not fully specified (e.g., per-token vs. batched updates); without quantified PCIe/host bandwidth or CPU overhead scaling with sequence length, it is unclear whether the approach remains low-overhead during normal operation for growing caches.
Authors: We will expand Section 4.2 to fully specify the incremental parity-update procedure, clarifying whether parity shards are refreshed on a per-token basis or in batches and describing the exact data movement between GPU and host memory. In addition, we will include new measurements of CPU utilization and PCIe bandwidth consumption as functions of sequence length during steady-state serving, demonstrating that the overhead remains negligible even as the KV cache grows to millions of tokens. revision: yes
Circularity Check
No circularity: empirical system evaluation with no self-referential derivation
full rationale
The paper presents GhostServe as an engineering system that applies standard erasure coding to KV-cache shards stored in host memory, then measures checkpointing and recovery latencies on real hardware. No equations derive a result from itself; no parameters are fitted to a subset and then relabeled as predictions; no uniqueness theorem or ansatz is imported via self-citation to force the design. All performance numbers (2.7× checkpointing, 2.1× recovery) are direct wall-clock measurements against baselines, not algebraic identities. The central premise that reconstruction can be faster than recomputation is an empirical claim left open to falsification by the reported timings rather than a definitional tautology. Consequently the derivation chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills,
Agrawal, A., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B. S., and Ramjee, R. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills.arXiv preprint arXiv:2308.16369,
-
[2]
Agrawal, A., Qiu, H., Chen, J., Goiri, ´I., Zhang, C., Shahid, R., Ramjee, R., Tumanov, A., and Choukse, E. No request left behind: Tackling heterogeneity in long-context llm inference with medha.arXiv preprint arXiv:2409.17264,
-
[3]
K., Janakiraman, R., and Xu, L
Aguilera, M. K., Janakiraman, R., and Xu, L. Using erasure codes efficiently for storage in a distributed system. In 2005 International Conference on Dependable Systems and Networks (DSN’05), pp. 336–345. IEEE,
work page 2005
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[5]
Coppock, P. H., Zhang, B., Solomon, E. H., Kypriotis, V ., Yang, L., Sharma, B., Schatzberg, D., Mowry, T., and Skarlatos, D. Lithos: An operating system for efficient machine learning on gpus.ArXiv, abs/2504.15465,
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with better par- allelism and work partitioning.ArXiv, abs/2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Ganguly, D., Melhem, R. G., and Yang, J. An adaptive framework for oversubscription management in cpu-gpu unified memory.2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp. 1212–1217,
work page 2021
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://cloud. google.com/blog/products/compute/ introducing-trillium-6th-gen-tpus. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
He, S., Cai, W., Huang, J., and Li, A. Capacity-aware inference: Mitigating the straggler effect in mixture of experts.ArXiv, abs/2503.05066,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Training Compute-Optimal Large Language Models
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Rae, J. W., Vinyals, O., and Sifre, L. Training compute-optimal large language models.ArXiv, ab...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Demystifying cost- efficiency in llm serving over heterogeneous gpus.ArXiv, abs/2502.00722,
Jiang, Y ., Fu, F., Yao, X., He, G., Miao, X., Klimovic, A., Cui, B., Yuan, B., and Yoneki, E. Demystifying cost- efficiency in llm serving over heterogeneous gpus.ArXiv, abs/2502.00722,
-
[12]
Scaling Laws for Neural Language Models
GhostServe: A Lightweight Checkpointing System in the Shadow for Fault-Tolerant LLM Serving Kaplan, J., McCandlish, S., Henighan, T. J., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. ArXiv, abs/2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
Kokolis, A., Kuchnik, M., Hoffman, J., Kumar, A., Malani, P., Ma, F., DeVito, Z., Sengupta, S., Saladi, K., and Wu, C.-J. Revisiting reliability in large-scale machine learning research clusters.2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 1259–1274,
work page 2025
-
[14]
Understanding stragglers in large model training using what-if analysis
Lin, J., Jiang, Z., Song, Z., Zhao, S., Yu, M., Wang, Z., Wang, C., Shi, Z., Shi, X., Jia, W., Liu, Z., Wang, S., Lin, H., Liu, X., Panda, A., and Li, J. Understanding stragglers in large model training using what-if analysis. ArXiv, abs/2505.05713,
-
[15]
Ranganathan, B., Zhang, M., and Wu, K. Enhancing relia- bility in ai inference services: An empirical study on real production incidents.ArXiv, abs/2511.07424,
-
[16]
S., Narang, S., Edunov, S., Naumov, M., Tang, C., and Oldham, M
Salpekar, O., Varma, R., Yu, K., Ivanov, V ., Wang, Y ., Sharif, A., Si, M., Xu, S., Tian, F., Zheng, S., Rice, T., Garg, A., Peng, S., Siravara, S., Fu, W., de Castro, R., Gangidi, A., Obraztsov, A. S., Narang, S., Edunov, S., Naumov, M., Tang, C., and Oldham, M. Training llms with fault tolerant hsdp on 100,000 gpus.ArXiv, abs/2602.00277,
-
[17]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
GhostServe: A Lightweight Checkpointing System in the Shadow for Fault-Tolerant LLM Serving Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi- billion parameter language models using model paral- lelism.arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[18]
2024 crowdstrike-related it outages
Wikipedia. 2024 crowdstrike-related it outages. https://en.wikipedia.org/wiki/2024_ CrowdStrike-related_IT_outages,
work page 2024
-
[19]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., and Brew, J. Huggingface’s transformers: State-of-the- art natural language processing.ArXiv, abs/1910.03771,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[20]
Fast distributed inference serving for large language models,
Wu, B., Zhong, Y ., Zhang, Z., Huang, G., Liu, X., and Jin, X. Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920,
-
[21]
G., Reizenstein, J., Park, J., and Huang, J
Yang, A., Yang, J., Ibrahim, A., Xie, X., Tang, B., Sizov, G. G., Reizenstein, J., Park, J., and Huang, J. Context parallelism for scalable million-token inference.ArXiv, abs/2411.01783,
-
[22]
Ye, Z., Chen, L., Lai, R., Lin, W., Zhang, Y ., Wang, S., Chen, T., Kasikci, B., Grover, V ., Krishnamurthy, A., and Ceze, L. Flashinfer: Efficient and customizable attention engine for llm inference serving.ArXiv, abs/2501.01005,
-
[23]
Alisa: Accelerating large language model inference via sparsity-aware kv caching
Zhao, Y ., Wu, D., and Wang, J. Alisa: Accelerating large language model inference via sparsity-aware kv caching. ArXiv, abs/2403.17312,
-
[24]
Zhu, Q., Duan, J., Chen, C., Liu, S., Li, X., Feng, G., Lv, X., Cao, H., Xiao, C., Zhang, X., Lin, D., and Yang, C. Sam- pleattention: Near-lossless acceleration of long context llm inference with adaptive structured sparse attention. ArXiv, abs/2406.15486, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.